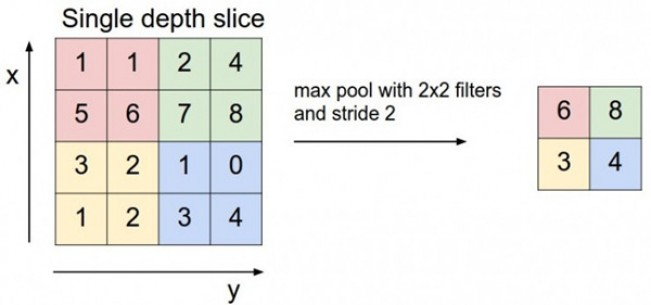
利用CNN卷积神经网络进行训练时,进行完卷积运算,还需要接着进行Max pooling池化操作,目的是在尽量不丢失图像特征前期下,对图像进行downsampling。
首先看下max pooling的具体操作:整个图片被不重叠的分割成若干个同样大小的小块(pooling size)。每个小块内只取最大的数字,再舍弃其他节点后,保持原有的平面结构得出 output。
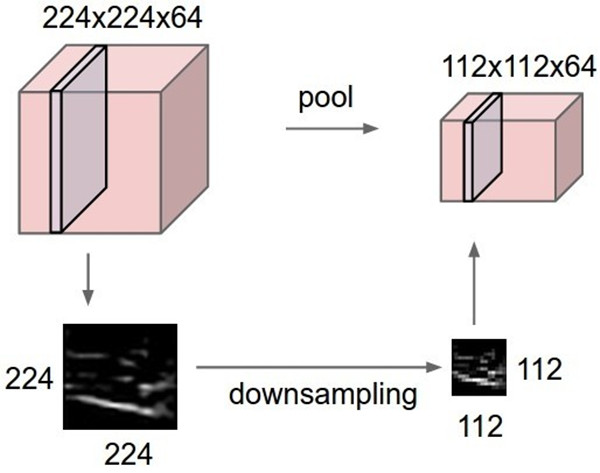
相应的,对于多个feature map,操作如下,原本64张224X224的图像,经过Max Pooling后,变成了64张112X112的图像,从而实现了downsampling的目的。
为什么可以这样?这里利用到一个特性:平移不变性(translation invariant),结论的公式证明还无从考证,不过从下面的实例可以侧面证明这点:
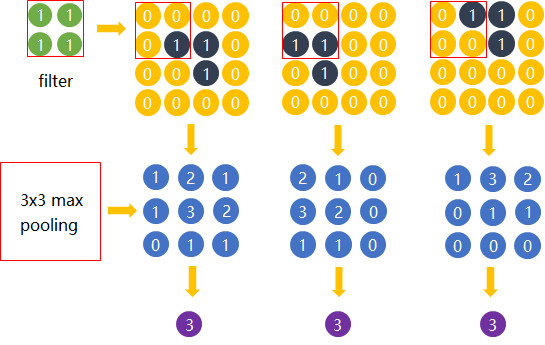
右上角为3副横折位置不一样的图像,分别同左上角的卷积核进行运算,然后再进行3X3大小池化操作以后,我们发现最后都能得到相同的识别结果。还有人更通俗理解卷积后再进行池化运算得到相同的结果,就好比牛逼的球队分到不同的组得到获得相同的比赛结果一样。
除了Max Pooling,还有一些其它的池化操作,例如:SUM pooling、AVE pooling、MOP pooling、CROW pooling和RMAC pooling等,这里不再进行介绍,见末尾参考文章链接。
下面利用tensorflow模块的max_pool函数,实现Max pooling操作:
# 导入tensorflow库 import tensorflow as tf # 定义2个行为4,列为4,通道为1的数据集 batches = 2 height = 4 width = 4 channes = 1 dataset = tf.Variable( [ [ [[1.0],[2.0],[5.0],[6.0]], [[3.0],[4.0],[7.0],[8.0]], [[9.0],[10.0],[13.0],[14.0]], [[11.0],[12.0],[15.0],[16.0]] ], [ [[17.0],[18.0],[21.0],[22.0]], [[19.0],[20.0],[23.0],[24.0]], [[25.0],[26.0],[29.0],[30.0]], [[27.0],[28.0],[31.0],[32.0]] ] ]) # 定义Max pooling操作运算,重点理解下ksize和strides两个参数的含义: # ksize表示不同维度Max pooling的大小,由于batches和channels两个维度不需要进行Max pooling,所以为1 # strides表示下个Max pooling位置的跳跃大小,同理,由于batches和channels两个维度不需要进行Max pooling,所以为1 X = tf.placeholder(dtype="float",shape=[None,height,width,channes]) data_max_pool = tf.nn.max_pool(value=X,ksize=[1,2,2,1],strides=[1,2,2,1],padding="VALID") # 开始进行tensorflow计算图运算 with tf.Session() as sess: sess.run(tf.global_variables_initializer()) input = sess.run(dataset) output = sess.run(data_max_pool,feed_dict = {X:input}) print(input) print("===============================") print(output) # 输入: # [ # [ # [[ 1.] [ 2.] [ 5.] [ 6.]] # [[ 3.] [ 4.] [ 7.] [ 8.]] # [[ 9.] [10.] [13.] [14.]] # [[11.] [12.] [15.] [16.]] # ] # # [ # [[17.] [18.] [21.] [22.]] # [[19.] [20.] [23.] [24.]] # [[25.] [26.] [29.] [30.]] # [[27.] [28.] [31.] [32.]] # ] # ] # # =============================== # 输出: # [ # [ # [[ 4.] [ 8.]] # [[12.] [16.]] # ] # [ # [[20.] [24.]] # [[28.] [32.]] # ] # ]
参考文章:CNN中的maxpool到底是什么原理?