
while True:
phone_num = input('please input your phone_num:')
if len(phone_num) == 11
and phone_num.isdigit()
and (phone_num.startswith('15')
or phone_num.startswith('18')
or phone_num.startswith('13')):
print('号码正确')
break
else:
print('号码错误')
python操作正则表达式要使用re模块。re模块包含的函数:findall,search,match,sub,subn,compile,split,finditer
findall和split把匹配结果放在列表里面。search,match,finditer调用group才能取到结果。
1.findall:
import re
ret = re.findall('a','eva agon yuan') #结果['a', 'a', 'a'],将后面待匹配的字符串跟‘a’匹配,把所有满足条件的结果放在列表里面。
print(ret)
ret1 = re.findall('[a-z]+','eva agon yuan') #['eva', 'agon', 'yuan']
print(ret1)
ret2 = re.findall('[a-z]*','eva agon yuan') #['eva', '', 'agon', '', 'yuan', '']#待匹配的字符串里面的空白符跟[a-z]*匹配了0次。所以结果有空白字符串。空白符可以跟*号和?号匹配0次。
print(ret2)
import re
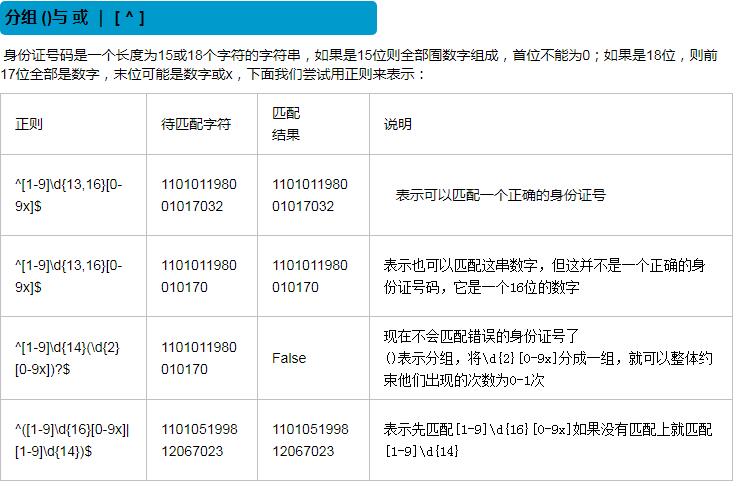
def idcheck(idc):
ret = re.findall('^[1-9]d{14}(d{2}[0-9x])?$',idc) #身份证为15位数字或18位数字或17位数字加X.
if ret:
print('匹配成功')
else:
print('匹配失败')
idcheck('111111111111111111')
2.search:
import re
ret = re.search('a','eva qgon yuqn') #从前往后,找到第一个就返回。
if ret: #如果找到,则返回的变量为True,调用group就可以拿到结果。如果没有找到,返回None。结果是a
print(ret.group()) #a
ret1 = re.search('a','ev1 qgon yuqn').group() #如果没有找到,并且没有使用if语句,就会报错。所以上面程序是常用格式。
print(ret1)
3.match: import re
ret = re.match('a','abc') #从第一个字符开始匹配。
if ret: print(ret.group()) #a
4.sub: import re
ret = re.sub('d','@','4ew 5her hsdfgh5 shsr56hserh',10) #@ew @her hsdfgh@ shsr@@hserh ,数字替换成@,重复10次。如果不输入重复次数,默认匹配任意多次。
print(ret)
5.subn: import re ret = re.subn('d','@','4ew 5her hsdfgh5 shsr56hserh') #('@ew @her hsdfgh@ shsr@@hserh', 5) ,数字替换成@,返回元组,元组第一个元素是替换的结果,第二个元素是替换的次数。
print(ret)
6.complie:把正侧编译成对象,适用于这个正侧重复使用,并且待匹配的字符串特别长的情况。
import re
obj = re.compile('d+')
ret = obj.findall('ad54646ae4g awe646gaa4eg 6a4g') #['54646', '4', '646', '4', '6', '4']
print(ret)
7.split: 分割结果是列表。
import re
ret = re.split('[ab]','fgiaklbjklae ajbag')#['fgi', 'kl', 'jkl', 'e ', 'j', '', 'g']
print(ret)
ret1 = re.split('[ab]', 'abcd') # 先按'a'分割得到''和'bcd',再对''和'bcd'分别按'b'分割
print(ret1) # ['', '', 'cd']
8.finditer:返回一个迭代器。节省内存。
import re
ret = re.finditer('d+','agejlaw54564g4e')
print([i.group() for i in ret]) #['54564', '4']
9.findall的优先级:
ret8 = re.findall('www.(baidu|laonanhai).com','www.laonanhai.com') #['laonanhai']。findall优先把组里的匹配结果返回。
print(ret8)
ret8 = re.findall('www.(?:baidu|laonanhai).com','www.laonanhai.com') #['www.laonanhai.com']。(?:)取消优先级。
print(ret8)
10.split的优先级:
ret9 = re.split('d','jg2jsa3gj') #['jg', 'jsa', 'gj'],没有保留分割的字符。
print(ret9)
ret10 = re.split('(d)','jg2jsa3gj') #['jg', '2', 'jsa', '3', 'gj'],加了组,保留分割的字符。对于某些需要保留分割字符的地方是很重要的。
print(ret10)