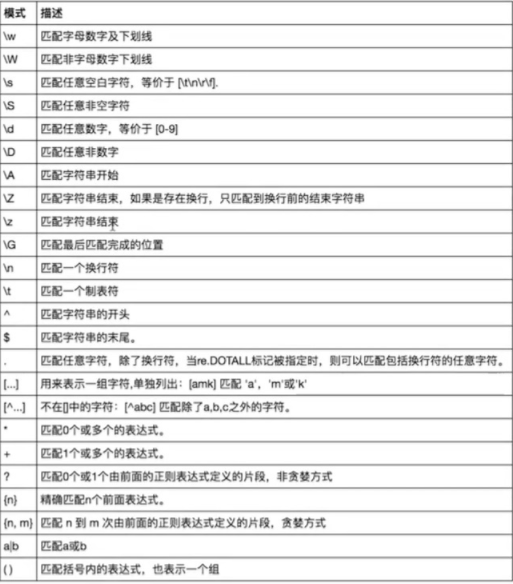
一、常用匹配模式
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import re
#贪婪匹配:从后面开始
#()只需要提取括号中的内容,顺序从外到内
line="pyrene11111pppp111 a"
# regex_str=".*(p.*p).*" #这个是贪婪模式,从后面匹配得到pp
regex_str=".*?(p.*p).*" #前面有?非贪婪模式,从前面匹配,后面是贪婪模式,后面匹配pyrene11111pppp
match_obj=re.match(regex_str,line)
if match_obj:
print(match_obj.group(1))
#?非贪婪匹配:问号放左边从左边开始匹配
line="pyrene00000000p pppp123"
regex_str=".*?(p.*?p).*"
match_obj=re.match(regex_str,line)
if match_obj:
print(match_obj.group(1))
#+的用法
line="pyrene00000000p pppp123"
regex_str=".*(p.+p).*" #这是贪婪模式,所以会从后面开始,这里+最低出现一个,所以结果为ppp
match_obj=re.match(regex_str,line)
if match_obj:
print(match_obj.group(1))
#{n},限定前面字符出现几次,{1,3}前面字符出现最低1次最多3次
line="pyrene00000000p pppssp123"
# regex_str=".*(p.{1}p).*" #由于必须出现前面的字符一次,这又是贪婪模式,所以会从后往前找,结果pp
regex_str=".*(p.{2}p).*" #这里满足,结果pssp
match_obj=re.match(regex_str,line)
if match_obj:
print(match_obj.group(1))
#|代表或者
line="pyrene123"
# regex_str="(pssp123|pyrene)"
regex_str="((pssp|pyrene)123)"
match_obj=re.match(regex_str,line)
if match_obj:
print(match_obj.group(2)) #这里值为1的时候匹配pyrene123,参数为2匹配pyrene
#[]
line="pyrene123"
regex_str="([abc]pyrene123)" #表示第一个字符为中括号中任意字符,就能够匹配到
match_obj=re.match(regex_str,line)
if match_obj:
print(match_obj.group(2))
#[] 代表区间 如果里面有.*就不表示特殊含义,^取反
line="18511391111"
# regex_str="(1[48357][0-9]{9})"#这里表示第一个字符是1,第二个字符是中括号中间的内容,第三个字符是0-9之间的树,第四个是前面的匹配9次
regex_str="(1[48357][^1]{9})"#第一个字符表示第一个是1,第二个是中括号的所有内容,第三个字符只要不是1就可以,第四个字符是前面的数字匹配9次
match_obj=re.match(regex_str,line)
if match_obj:
print(match_obj.group(1))
#s代表空格
line="你 好"
regex_str="(你s好)"
match_obj=re.match(regex_str,line)
if match_obj:
print(match_obj.group(1))
#S 表示除了空格都可以
line="你a好"
regex_str="(你S好)"
match_obj=re.match(regex_str,line)
if match_obj:
print(match_obj.group(1))
#w 作用匹配[A-Za-z0-9_],W作用相反
line="你a好"
regex_str="(你W好)"
match_obj=re.match(regex_str,line)
if match_obj:
print(match_obj.group(1))
#[u4E00-u9FA5] 提取中文
line="你a好"
regex_str=".*?([u4E00-u9FA5])" #非贪婪模式 从左开始匹配
match_obj=re.match(regex_str,line)
if match_obj:
print(match_obj.group(1))
#
line = "xxx2000年"
regex_str = ".*(d)年"#这个只获取到了0怎么获取全部呢?方法一是加?,方法二加上{4}
match_obj = re.match(regex_str, line)
if match_obj:
print(match_obj.group(1))
小练习:匹配下面的出生日期
line="xxx出生于2001年6月"
line="xxx出生于2001/6/1"
line="xxx出生于2001-6-1"
line="xxx出生于2001-06-01"
line="xxx出生于2001-06"
regex_str=".*出生于(d{4}[年/-]d{1,2}([月/-]d{1,2}|[月/-]$|$))"
match_obj=re.match(regex_str,line)
if match_obj:
print(match_obj.group(1))
re.match和re.compile()
import re
#3位数字-3到8个数字 d{3}-d{3-8}
#下面如果匹配成功就打印出来
m=re.match(r"d{3}-d{3,8}","010-222346512")
print(m.string)
#分组
m=re.match(r"(d{3})-(d{3,8})","010-1231231")
print(m.group(0)) #原始结果
print(m.group(1)) #第一个分组括号
print(m.group(2))
print(m.groups()) #把所有的组全部放到元祖里面
#匹配时分秒
t='20:15:45'
m=re.match(r'^(0[0-9]|1[0-9]|2[0-9|[0-9]):(0[0-9]|1[0-9]|2[0-9|3[0-9]|4[0-9]|5[0-9]|[0-9]):(0[0-9]|1[0-9]|2[0-9]|3[0-9]|4[0-9]|5[0-9]|[0-9])$',t) #注意这里:要去掉特殊含义,$结尾后面的引号不能有空格
print(m.groups())
#分割字符串
p=re.compile(r'd+') #compile就是把一个模式编译好,然后拿着这个模式到处匹配
print(p.split("sdaasd1321321"))