1. 海王评论数据爬取前分析
海王上映了,然后口碑炸了,对咱来说,多了一个可爬可分析的电影,美哉~
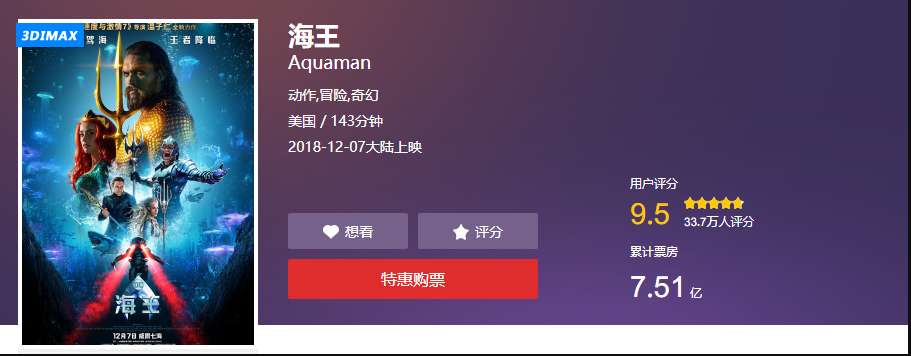
摘录一个评论
零点场刚看完,温导的电影一直很不错,无论是速7,电锯惊魂还是招魂都很棒。打斗和音效方面没话说非常棒,特别震撼。总之,DC扳回一分( ̄▽ ̄)。比正义联盟好的不止一点半点(我个人感觉)。还有艾梅伯希尔德是真的漂亮,温导选的人都很棒。
真的第一次看到这么牛逼的电影 转场特效都吊炸天
2. 海王案例开始爬取数据
数据爬取的依旧是猫眼的评论,这部分内容咱们用把牛刀,scrapy爬取,一般情况下,用一下requests就好了
抓取地址、交流群:1029344413 分享视频资料
http://m.maoyan.com/mmdb/comments/movie/249342.json?_v_=yes&offset=15&startTime=2018-12-11%2009%3A58%3A43
关键参数
url:http://m.maoyan.com/mmdb/comments/movie/249342.json offset:15 startTime:起始时间
scrapy 爬取猫眼代码特别简单,我分开几个py文件即可。Haiwang.py
import scrapy import json from haiwang.items import HaiwangItem class HaiwangSpider(scrapy.Spider): name = 'Haiwang' allowed_domains = ['m.maoyan.com'] start_urls = ['http://m.maoyan.com/mmdb/comments/movie/249342.json?_v_=yes&offset=0&startTime=0'] def parse(self, response): print(response.url) body_data = response.body_as_unicode() js_data = json.loads(body_data) item = HaiwangItem() for info in js_data["cmts"]: item["nickName"] = info["nickName"] item["cityName"] = info["cityName"] if "cityName" in info else "" item["content"] = info["content"] item["score"] = info["score"] item["startTime"] = info["startTime"] item["approve"] = info["approve"] item["reply"] = info["reply"] item["avatarurl"] = info["avatarurl"] yield item yield scrapy.Request("http://m.maoyan.com/mmdb/comments/movie/249342.json?_v_=yes&offset=0&startTime={}".format(item["startTime"]),callback=self.parse)
setting.py
设置需要配置headers
DEFAULT_REQUEST_HEADERS = { "Referer":"http://m.maoyan.com/movie/249342/comments?_v_=yes", "User-Agent":"Mozilla/5.0 Chrome/63.0.3239.26 Mobile Safari/537.36", "X-Requested-With":"superagent" }
需要配置一些抓取条件
# Obey robots.txt rules ROBOTSTXT_OBEY = False # See also autothrottle settings and docs DOWNLOAD_DELAY = 1 # Disable cookies (enabled by default) COOKIES_ENABLED = False
开启管道
# Configure item pipelines # See https://doc.scrapy.org/en/latest/topics/item-pipeline.html ITEM_PIPELINES = { 'haiwang.pipelines.HaiwangPipeline': 300, }
items.py
获取你想要的数据
import scrapy class HaiwangItem(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() nickName = scrapy.Field() cityName = scrapy.Field() content = scrapy.Field() score = scrapy.Field() startTime = scrapy.Field() approve = scrapy.Field() reply =scrapy.Field() avatarurl = scrapy.Field()
pipelines.py
保存数据,数据存储到csv文件中
import os import csv class HaiwangPipeline(object): def __init__(self): store_file = os.path.dirname(__file__) + '/spiders/haiwang.csv' self.file = open(store_file, "a+", newline="", encoding="utf-8") self.writer = csv.writer(self.file) def process_item(self, item, spider): try: self.writer.writerow(( item["nickName"], item["cityName"], item["content"], item["approve"], item["reply"], item["startTime"], item["avatarurl"], item["score"] )) except Exception as e: print(e.args) def close_spider(self, spider): self.file.close()
begin.py
编写运行脚本
from scrapy import cmdline cmdline.execute(("scrapy crawl Haiwang").split())
搞定,等着数据来到,就可以了