regexp_substr函数 [String]
使用正则表达式从字符串中抽取子串。
1. 语法:
regexp_substr( expression,
regular-expression
[, start-offset [ , occurrence-number [, escape-expression ] ] ] );
regexp_substr( expression, regular-expression, start-offset, end-offset);
2.参数:
expression 被搜索的字符串。
regular-expression 尝试匹配的模式,字符截取正则表达式。
start-offset 开始搜索时相对于 expression 的偏移。start-offset 以正整数表示,表示从字符串的左端数的字符数。缺省值为 1(字符串的起点)。
occurrence-number 当 expression 中有多个匹配项时,指定一个整数来表示要定位第几个出现的匹配项。例如,3 表示查找第三个出现的匹配项。缺省值为 1。
escape-expression regular-expression 所使用的转义字符。缺省为反斜线字符 ()。
end-offset 获取expression 被指定字符截取后的第几个。
如:regexp_substr(‘aaa,bbb,ccc,ddd,eee’,’[^,]+’,1,3)
返回结果: ‘ccc’,即“aaa,bbb,ccc,ddd,eee”被”,”截取后的第三个子字符串。
3. 返回值:
VARCHAR
4. 注释:
如果未找到 regular-expression,则 REGEXP_SUBSTR 返回 NULL。
如果指定了 start-offset,该偏移量会指定要匹配的表达式的开始处。特别地,^ 与从 start-offset 处开始的表达式的开头相匹配。
5. 示例:
a).从字符串中截取某一部分内容
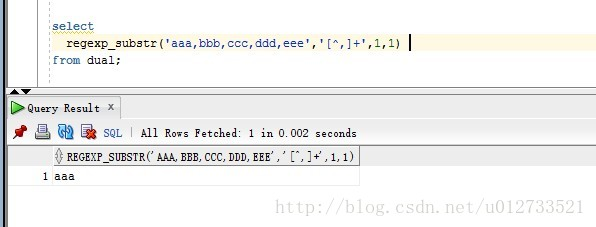
---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------

b) 截取数据表中制定字符的前的内容,下面结果截取的是该字段种“(”字符前面的内容:
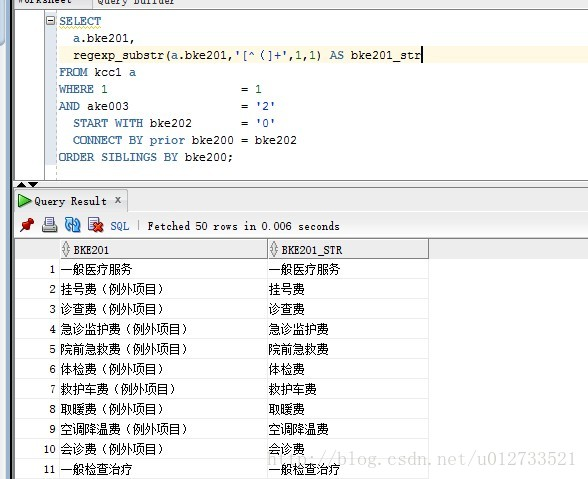
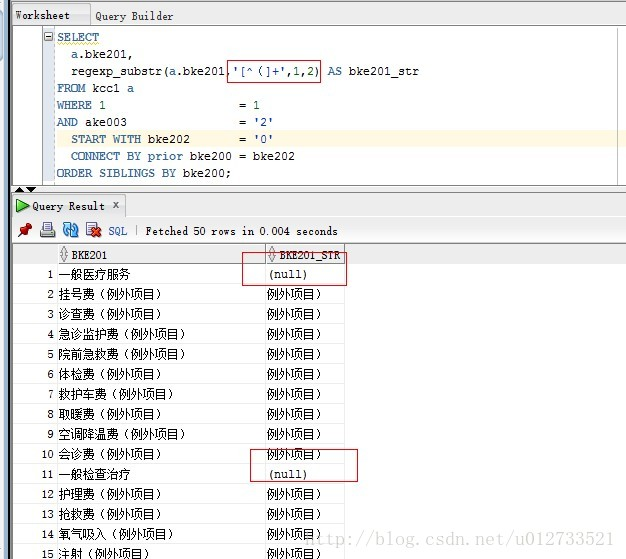
根据正则表达式和设置的start-offset和end-offset没有找到匹配的子字符串,
则返回结果为null。
转自:https://blog.csdn.net/u012733521/article/details/53895441