刷了一篇“Measures of distance between samples: non-Euclidean”,顺手写个笔记
×××××××××××××××××××××××××啦啦啦今天浑身都痛简直萌萌哒××××××××××××××××××××××××××××××××××××
衡量距离的东西,我们称为metric,那么两个点a和b之间的距离应该满足这些条件(朝老师提过!!好爱她)

但是有的时候第三条会很难满足,因为它们并不是距离,而是一种dissimilarity
Bray-Curtis dissimilarity: 衡量样本之间的差异
下面是栗子!!!大栗子!!!!
样本数据:
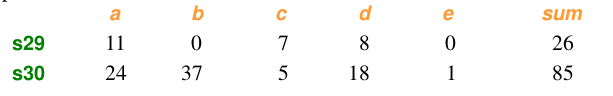
计算:
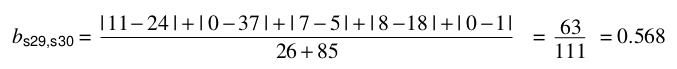
也就是这个公式:

如果说我们计算了30个样本两两之间的BC-dissimilarity,可以发现(3)被违背了。
一般会把它写成百分比,那么Bray-Curtis index = 100 - Bray-Curtis dissimilarity
Bray-Curtis dissimilarity versus chi-square distance
首先,chi-square distance是啥:


很难说到底哪个更好。
BC的好处是:直观(0就是相同,1就是不同),但违反三角不等式;
chi-square的好处是:true metric(0是指相对丰度identical,最大值与数据有关)
如果都用relative count,那么两者相似;如果使用raw count,size(数值大小)相差大时,很不同。
比如下面的例子,当样本之间的差异不够大时,卡方反映的不够准确。

L1 distance (city-block)
Lp distance,J是维度数。L2就是欧式距离。

Dissimilarity measures for presence–absence data(dichotomous,二叉的)

Jaccard index:co-presence/(sum - co-absence)
比如A和B,有sp1,sp2,sp5和sp10是co-presence的,sp6和sp7是co-absence的,sp3sp4sp8sp9是mis-match,
所以应为4/(10-2)=0.5
dissimilarity = 1 - Jaccard index
注意:co-absence也是一种match,但是很多时候我们不关心那些,所以才用Jaccard index来衡量相似度
correlation coefficient


Distances for heterogeneous data(异构数据,比如下面这种连续和离散混合的)

Gower’s generalized coefficient of dissimilarity(将连续和离散的数据标准化)
1)计算各类别的均值与标准差。Region可以把几个可能的值列出来,用01序列来表示。类似下图

2) 标准化
连续值是减去均值再除以标准差,离散值标准化后再乘系数1/√2 = 0.7071(补偿0/1编码)

3)计算距离,如L1,L2等。总=连续的+离散的
另一种处理方法:
先对每组数据计算distance/dissimilarity,然后再把这些东西按加权平均。
下面是有三种不同数据的情况。权重可以根据自己的需要调整。
