(一)梳理JML语言的理论基础、应用工具链情况
梳理JML语言的理论基础
在JML官网上,是这样定义JML的。
Java建模语言(JML)是一种行为接口规范语言,可用于指定Java模块的行为 。它结合了Eiffel的契约方法设计 和Larch系列接口规范语言的基于模型的规范方法 ,以及细化演算一些元素 。
基础语法梳理
https://blog.csdn.net/piaopu0120/article/details/89527175
链接为我根据预习资料和第一次上课内容进行的JML语法整理,内容较多,仍放在另一个博客里。
2.应用工具链
- Open JML:OpenJML是Java程序的程序验证工具,允许检查Java Modeling Language中注释的程序的规范;
- JML SMT Solver:OpenJML的主流SMT Solver;
- JML Unit:单元测试工具;
- JMLdoc:JML规范的javadoc(jmldoc)增强版本;
- jmlc:断言检查编译器。
(二)部署JMLUnitNG/JMLUnit,针对Graph接口的实现自动生成测试用例, 并结合规格对生成的测试用例和数据进行简要分析
这个东西玄之又玄,成功的运行除了环境搭好外,还需要保证代码和逻辑的双重匹配。总之,感谢郑文帝对我的帮助。
以下是针对MyGraph接口生成的测试用例:
Failed: racEnabled() Passed: constructor MyGraph() Passed: <<MyGraph@4ca8195f>>.addPath(null) Passed: <<MyGraph@490d6c15>>.containsEdge(-2147483648, -2147483648) Passed: <<MyGraph@449b2d27>>.containsEdge(0, -2147483648) Passed: <<MyGraph@5479e3f>>.containsEdge(2147483647, -2147483648) Passed: <<MyGraph@27082746>>.containsEdge(-2147483648, 0) Passed: <<MyGraph@66133adc>>.containsEdge(0, 0) Passed: <<MyGraph@7bfcd12c>>.containsEdge(2147483647, 0) Passed: <<MyGraph@42f30e0a>>.containsEdge(-2147483648, 2147483647) Passed: <<MyGraph@24273305>>.containsEdge(0, 2147483647) Passed: <<MyGraph@5b1d2887>>.containsEdge(2147483647, 2147483647) Passed: <<MyGraph@46f5f779>>.containsNode(-2147483648) Passed: <<MyGraph@1c2c22f3>>.containsNode(0) Passed: <<MyGraph@33e5ccce>>.containsNode(2147483647) Passed: <<MyGraph@5a42bbf4>>.containsPathId(-2147483648) Passed: <<MyGraph@270421f5>>.containsPathId(0) Passed: <<MyGraph@52d455b8>>.containsPathId(2147483647) Passed: <<MyGraph@4f4a7090>>.containsPath(null) Passed: <<MyGraph@18ef96>>.getDistinctNodeCount() Failed: <<MyGraph@6f79caec>>.getPathById(-2147483648) Failed: <<MyGraph@67117f44>>.getPathById(0) Failed: <<MyGraph@5d3411d>>.getPathById(2147483647) Failed: <<MyGraph@2471cca7>>.getPathId(null) Passed: <<MyGraph@5fe5c6f>>.getShortestPathLength(-2147483648, -2147483648) Passed: <<MyGraph@6979e8cb>>.getShortestPathLength(0, -2147483648) Passed: <<MyGraph@763d9750>>.getShortestPathLength(2147483647, -2147483648) Passed: <<MyGraph@5c0369c4>>.getShortestPathLength(-2147483648, 0) Passed: <<MyGraph@2be94b0f>>.getShortestPathLength(0, 0) Passed: <<MyGraph@d70c109>>.getShortestPathLength(2147483647, 0) Passed: <<MyGraph@17ed40e0>>.getShortestPathLength(-2147483648, 2147483647) Passed: <<MyGraph@50675690>>.getShortestPathLength(0, 2147483647) Passed: <<MyGraph@31b7dea0>>.getShortestPathLength(2147483647, 2147483647) Passed: <<MyGraph@3ac42916>>.isConnected(-2147483648, -2147483648) Passed: <<MyGraph@47d384ee>>.isConnected(0, -2147483648) Passed: <<MyGraph@2d6a9952>>.isConnected(2147483647, -2147483648) Passed: <<MyGraph@22a71081>>.isConnected(-2147483648, 0) Passed: <<MyGraph@3930015a>>.isConnected(0, 0) Passed: <<MyGraph@629f0666>>.isConnected(2147483647, 0) Passed: <<MyGraph@1bc6a36e>>.isConnected(-2147483648, 2147483647) Passed: <<MyGraph@1ff8b8f>>.isConnected(0, 2147483647) Passed: <<MyGraph@387c703b>>.isConnected(2147483647, 2147483647) Failed: <<MyGraph@224aed64>>.removePathById(-2147483648) Failed: <<MyGraph@c39f790>>.removePathById(0) Failed: <<MyGraph@71e7a66b>>.removePathById(2147483647) Failed: <<MyGraph@2ac1fdc4>>.removePath(null) Passed: <<MyGraph@5f150435>>.size() =============================================== Command line suite Total tests run: 47, Failures: 9, Skips: 0 ===============================================
测试用例分析:
对于int类型的数据,生成的大多数是0,边界的正负数据;
对于object类型的数据,生成的大多是null。
对于参数是object类型的数据,应该就是挺难解决的。因为自动测试样例不太好生成满足要求的新对象。但是对于int类型全是边界数据,我有点难以理解。
(三)按照作业梳理自己的架构设计,并特别分析迭代中对架构的重构
1.第九次作业
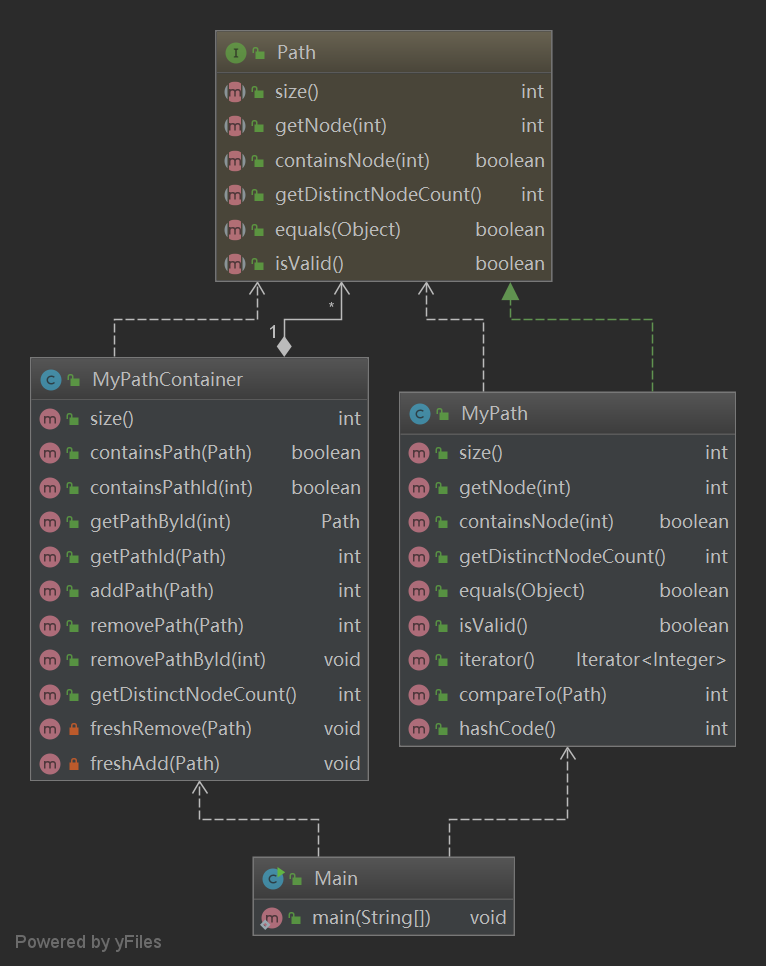
没有做太多架构上的设计,仅完成了目标函数的补充。在细节方面的小优化是用hashset进行去重保存节点;用hashmap实现id和Path的双重查找。
2.第十次作业

依然没有做架构上的设计,新的图没有选择继承之前图,导致MyGraph很冗杂。主要实现了对于每一个Path的每一个小邻边的访存;修改了add和remove,完善功能;为求最短路,进行了floyd的初始化和实现。
3.第十一次作业
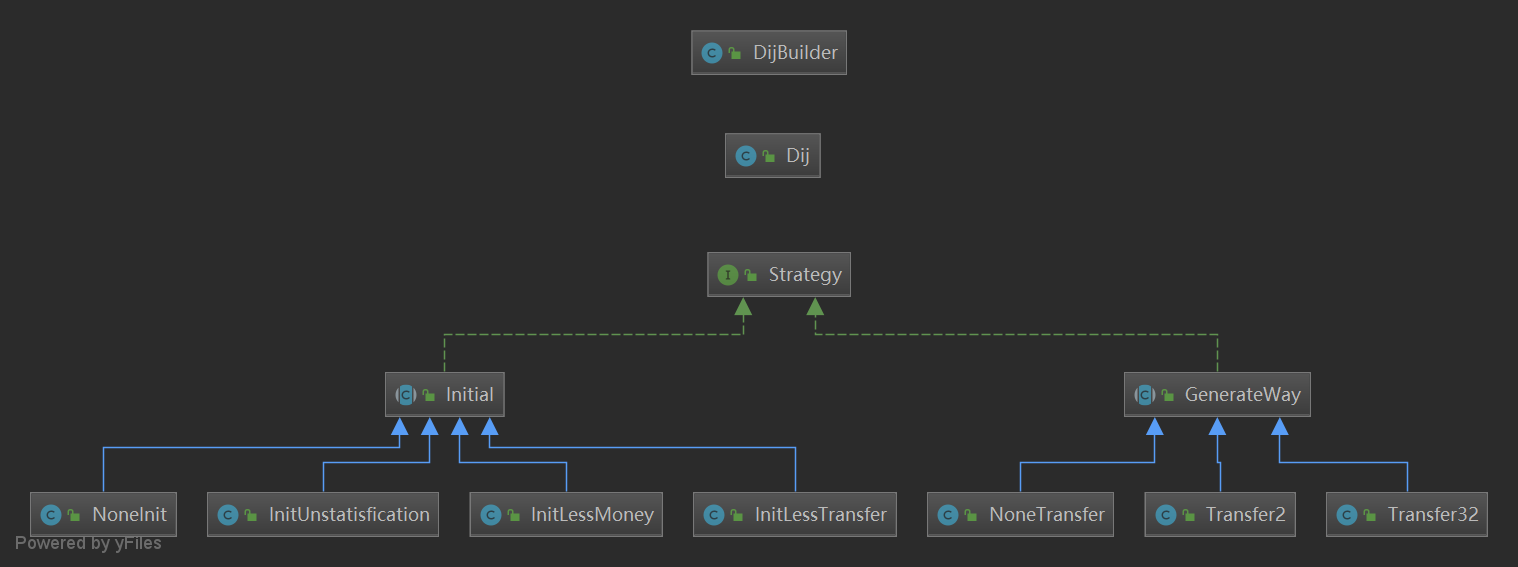

第三次作业因为有四个相似的图,所以进行了架构上的优化。
虽然之前有考虑过指导书推荐的组合模式+工厂模式的架构,但当时主观觉得组合模式的树形结构不太好运用到这次的题(实际上是我建模的主体不对)。所以考虑了建造者模式。
建造者模式(Builder Pattern)
使用多个简单的对象一步一步构建成一个复杂的对象。
主要解决在软件系统中,有时候面临着"一个复杂对象"的创建工作,其通常由各个部分的子对象用一定的算法构成;由于需求的变化,这个复杂对象的各个部分经常面临着剧烈的变化,但是将它们组合在一起的算法却相对稳定。
用大白话讲就是生成一个套餐。
我生成了一个floyd套餐builder和一个dij套餐builder,这两个builder可以生成各种各样的套餐。
分析:
①把问题分成由floyd算法求解更优和dijkstra算法求解更优的两类
②把floyd和dijkstra的初始化与实现拆分成小块。
③将小块进行重新组合,实现builder。
顶层组合实现举例:
1 public Dij lessTransfer() { 2 if (transDij == null) { 3 transDij = new Dij(); 4 transDij.addStratege(new InitLessTransfer()); 5 transDij.addStratege(new NoneTransfer()); 6 } 7 return transDij; 8 } 9 10 public Dij lessCost() { 11 if (costDij == null) { 12 costDij = new Dij(); 13 costDij.addStratege(new InitLessMoney()); 14 costDij.addStratege(new Transfer2()); 15 } 16 return costDij; 17 } 18 19 public Dij lessUnplefation() { 20 if (unpleDij == null) { 21 unpleDij = new Dij(); 22 unpleDij.addStratege(new InitUnstatisfication()); 23 unpleDij.addStratege(new Transfer32()); 24 } 25 return unpleDij; 26 }
调用builder实例:
1 if (unpleFlag) { 2 // 省略初始化代码 3 // 如果没有缓存,调用builder1 4 unpleDij = DijBuilder.getBuilder().lessUnplefation(); 5 } else { 6 if (alreadyUnple.contains(fromNodeId)) { 7 // 省略结果返回代码 8 } 9 // 如果有缓存,调用builder2 10 unpleDij = DijBuilder.getBuilder().noneunpleDij(); 11 } 12 // 省略更新缓存代码 13 // 启动builder,得到结果 14 unpleDij.runDij(fromNodeId, unpleGraph, unpleExist, distict, 15 unpleNodeSort, buddy, pidMap, pathInformation); 16 }
下面是builder的具体实现:

以不满意度为例
DijBuilder
1 public class DijBuilder { 2 private Dij unpleDij = null; 3 private Dij noneunpleDij = null; 4 5 private static DijBuilder builder = new DijBuilder(); 6 7 private DijBuilder() { 8 } 9 10 public static DijBuilder getBuilder() { 11 return builder; 12 } 13 14 public Dij lessUnplefation() { 15 if (unpleDij == null) { 16 unpleDij = new Dij(); 17 unpleDij.addStratege(new InitUnstatisfication()); 18 unpleDij.addStratege(new Transfer32()); 19 } 20 return unpleDij; 21 } 22 23 public Dij noneunpleDij() { 24 if (noneunpleDij == null) { 25 noneunpleDij = new Dij(); 26 noneunpleDij.addStratege(new NoneInit()); 27 noneunpleDij.addStratege(new Transfer32()); 28 } 29 return noneunpleDij; 30 } 31 32 }
Dij
public class Dij { private List<Strategy> strategies = new ArrayList<>(); public void addStratege(Strategy s) { strategies.add(s); } public void runDij(int v0, int[][] distanceGraph, boolean[][] exist, HashSet<Integer> distict, HashMap<Integer, Integer> nodeSort, HashMap<String, Integer> buddy, HashMap<Path, Integer> pidMap, PathMap[] pathInformation) { Strategy initMethod = strategies.get(0); initMethod.process(0, distanceGraph, exist, distict, nodeSort, buddy, pidMap, pathInformation); Strategy calMethod = strategies.get(1); calMethod.process(nodeSort.get(v0), distanceGraph, exist, distict, nodeSort, buddy, pidMap, pathInformation); } }
Strategy接口
1 public interface Strategy { 2 void process(int v0, int[][] distanceGraph, boolean[][] exist, 3 HashSet<Integer> distict, 4 HashMap<Integer, Integer> nodeSort, 5 HashMap<String, Integer> buddy, 6 HashMap<Path, Integer> pidMap, PathMap[] pathInformation); 7 }
GenerateWay抽象类实现Strategy接口,Initial抽象类类似
1 public abstract class GenerateWay implements Strategy { 2 3 public abstract void process(int v0, int[][] distanceGraph, 4 boolean[][] exist, 5 HashSet<Integer> distict, 6 HashMap<Integer, Integer> nodeSort, 7 HashMap<String, Integer> buddy, 8 HashMap<Path, Integer> pidMap, 9 PathMap[] pathInformation); 10 }
Transfer32类继承抽象类GenerateWay
1 public class Transfer32 extends GenerateWay { 2 3 public void process(int v0, int[][] distanceGraph, boolean[][] exist, 4 HashSet<Integer> distict, 5 HashMap<Integer, Integer> nodeSort, 6 HashMap<String, Integer> buddy, 7 HashMap<Path, Integer> pidMap, 8 PathMap[] pathInformation) { 9 StaticFun.dij(v0, distict.size(), 32, distanceGraph, exist); 10 } 11 }
这样的方法使得在顶层实现不同的floyd或者dij的算法非常容易,可以实现n*m种任意的组合,并且不需要改动任何的底层代码。
但在实现的过程中也会遇到一些困难:
1. 统一接口导致传参过多;
2. 没有办法在顶层进一步封装,使得顶层代码重复变多。
(四)按照作业分析代码实现的bug和修复情况
1. 第九次作业
第九次作业被检测出来了一个bug,compareTO用了一种错误的方法,当时为了少些几行所以是通过差值判断的。这直接导致了溢出时判断错误。修复的时候把它修改成了大小比较。
2. 第十次作业
在判断最短路的时候忘记了两个相同点的情况,修复的时候把这个条件加上了。
3. 第十一次作业
感谢莫策同学的数据生成器,经过很多数据的互拍让bug数减到最小。
总结
这些bug很不值得,他、它们都是很基础很容易用测试用例覆盖的问题。但这两次作业我都没怎么用心测试程序,导致了这两个bug的出现。第十一次作业我汲取了之前的教训,进行了大量的测试使得最后一次作业在强测互测都没有发现bug。以后一定谨记,在每一次测试之前优先考虑边界问题和特殊数据。
(五)阐述对规格撰写和理解上的心得体会
- 这几次作业中,在课上我们有机会写规格,课下我们主要是通过阅读规格。但是实际上,我在课下补充一个方法时,会不根据规格来撰写代码,只是会根据规格来作为debug的一层手段。我记得在第一次作业我准备按照规格来写代码的时候,发现使用的架构和数据结构与规格表述的不太适配。
- 在后期阅读规格的时候,比如像计算容器类的不同节点个数或者最少换乘数路径这样的题目,用语言来描述很简单,但是它的逻辑用规格来书写就非常困难。写规格的感觉对于我来说特别像写离散数学证明题,需要用非常完备的逻辑来完善我们所想表达的。
- 一个正确的规格有助于减少歧义,规格对于方法目的的说明非常有效,因为它是贴合数据代码的,挺像伪代码对于一个问题的说明功效。
- 规格描述了数据的变与不变,忽略了中间过程的实现,是结果指向的。
后话:
这个单元的学习让我觉得挺迷的,因为JML的资料很少,对我来说环境安装和实际使用的可行性很低。虽然有同学能够很好的使用,但是有些时候这种成功不是所有人都能复刻的,迎接我们的可能还是一大堆不明所以的报错。这个单元的编程经历还是带给我了一些收获:
1.架构上的设计
这个单元对于架构上的设计思考得很多,每一个单元写优化的时候最先考虑的是优化架构。这个单元涉及到的图的访存还蛮复杂的,因为一直避免疯狂嵌套hashmap,所以想了很多办法。总的来说收获很多吧。
2.规范性
规格带给我的体验不是很多,但是能够从规格感受到代码规范的重要性。而且相较于前几次从头开始写,这几次主要是补充方法,由于父类接口的限制使写代码的时候要更好的设计。
这个单元的第一次作业也是我第一次翻车,会好好反思的。