官网(包含文档)
http://sqoop.apache.org/
http://sqoop.apache.org/docs/1.4.7/SqoopUserGuide.html
基础操作网站
没有配置hcatalog,介绍hcatalog
https://blog.csdn.net/ancony_/article/details/79903705
也没有配置accumulo,介绍
安装:https://www.cnblogs.com/shoufengwei/p/8627436.html
介绍:https://blog.csdn.net/u011596455/article/details/73732504
一、Sqoop 简介
Apache Sqoop(TM)是一种旨在有效地在 Apache Hadoop 和诸如关系数据库等结构化数据存
储之间传输大量数据的工具。
Sqoop 于 2012 年 3 月孵化出来,现在是一个顶级的 Apache 项目。
最新的稳定版本是 1.4.7。Sqoop2 的最新版本是 1.99.7。请注意,1.99.7 与 1.4.7 不兼容,且
没有特征不完整,它并不打算用于生产部署。
二、Sqoop 原理
将导入或导出命令翻译成 mapreduce 程序来实现。
sqoop 是 apache 旗下一款“Hadoop 和关系数据库服务器之间传送数据”的工具。
核心的功能有两个:
导入、迁入
导出、迁出
导入数据:MySQL,Oracle 导入数据到 Hadoop 的 HDFS、HIVE、HBASE 等数据存储系统
导出数据:从 Hadoop 的文件系统中导出数据到关系数据库 mysql 等 Sqoop 的本质还是一
个命令行工具,和 HDFS,Hive 相比,并没有什么高深的理论。
sqoop:
工具:本质就是迁移数据, 迁移的方式:就是把sqoop的迁移命令转换成MR程序
hive
工具,本质就是执行计算,依赖于HDFS存储数据,把SQL转换成MR程序
在翻译出的 mapreduce 中主要是对 inputformat 和 outputformat 进行定制。

三、Sqoop 安装
安装 Sqoop 的前提是已经具备 Java 和 Hadoop 的环境。
3.1、下载并解压
1) 最新版下载地址:http://mirrors.hust.edu.cn/apache/sqoop/1.4.7/
http://mirror.bit.edu.cn/apache/sqoop/1.4.7/
2) 上传安装包 sqoop-1.4.7.bin__hadoop-2.6.0.tar.gz 到虚拟机中,如我的上传目录是:
/home/hadoop_home/sqoop-1.4.7
3) 解压 sqoop 安装包到指定目录,如:
$ tar -zxf sqoop-1.4.7.bin__hadoop-2.6.0.tar.gz -C /home/hadoop_home/
3.2、修改配置文件
Sqoop 的配置文件与大多数大数据框架类似,在 sqoop 根目录下的 conf 目录中。
1) 重命名配置文件
$ mv sqoop-env-template.sh sqoop-env.sh
$ mv sqoop-site-template.xml sqoop-site.xml
2) 修改配置文件
sqoop-env.sh
export HADOOP_COMMON_HOME=/home/hadoop/hadoop_home
export HADOOP_MAPRED_HOME=/home/hadoop/hadoop_home
export HIVE_HOME=/home/hadoop/hadoop_home/apache-hive-2.3.4-bin
export ZOOKEEPER_HOME=/home/hadoop/hadoop_home/zookeeper-3.4.9
export ZOOCFGDIR=/home/hadoop/hadoop_home/zookeeper-3.4.9
3.3、拷贝 JDBC 驱动
拷贝 jdbc 驱动到 sqoop 的 lib 目录下,如:
$ cp -a mysql-connector-java-5.1.47-bin.jar ~/hadoop_home /sqoop-1.4.7.bin__hadoop-2.6.0/lib/
3.4、验证 Sqoop
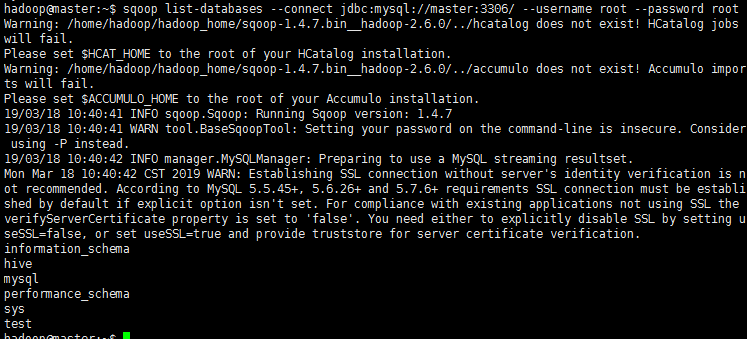
我们可以通过某一个 command 来验证 sqoop 配置是否正确:

执行测试mysql
sqoop list-databases --connect jdbc:mysql://master:3306/ --username root --password root
会报错
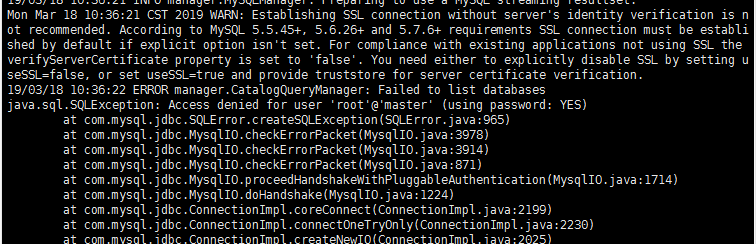
然后执行下面的配置权限
配置权限
mysql> GRANT ALL ON *.* TO 'root'@'%' IDENTIFIED BY 'root';
mysql> FLUSH PRIVILEGES;
刷新:/etc/init.d/mysql restart
再次执行即可
进入以下界面
cd /etc/mysql/mysql.conf.d
然后
vi vi mysqld.cnf

把最下面的bind-address =127.0.0.1
注释掉就好(sqoop用到)
Sqoop 的简单使用案例
4.1、导入数据

3) 导入数据
(1)全部导入
$ bin/sqoop import

sqoop import --connect jdbc:mysql://master:3306/company --username root --password root --table staff --target-dir /user/company --delete-target-dir --num-mappers 1 --fields-terminated-by " "
(2)查询导入
sqoop import --connect jdbc:mysql://master:3306/company --username root --password root --target-dir /user/company --delete-target-dir --num-mappers 1 --fields-terminated-by " " --query 'select name,sex from staff where id <=1 and $CONDITIONS;'
尖叫提示:must contain '$CONDITIONS' in WHERE clause.
尖叫提示:如果 query 后使用的是单引号,则$CONDITIONS 前必须加转义符,防止 shell
识别为自己的变量。
尖叫提示:--query 选项,不能同时与--table 选项使用
将hdfs上数据导入到mysql里
mysql -u root -p root
首先进入库
use company;
然后清空表
truncate staff;(只清空,不删除表,保留表结构)
查询一下
select * from staff;
退出quit;
导出:sqoop export --connect jdbc:mysql://master:3306/company --username root --password root --table staff --export-dir /user/company --num-mappers 1 --fields-terminated-by " "
进入数据库再查询即可
(3)导入指定列
sqoop import --connect jdbc:mysql://master:3306/company --username root --password root --table staff --target-dir /user/company --delete-target-dir --num-mappers 1 --fields-terminated-by " " --columns id,sex
尖叫提示:columns 中如果涉及到多列,用逗号分隔,分隔时不要添加空格
(4)使用 sqoop 关键字筛选查询导入数据
sqoop import --connect jdbc:mysql://master:3306/company --username root --password root --table staff --target-dir /user/company --delete-target-dir --num-mappers 1 --fields-terminated-by " " --where "id=1"
尖叫提示:在 Sqoop 中可以使用 sqoop import -D property.name=property.value 这样的方式加
入执行任务的参数,多个参数用空格隔开。
(5)sqoop增量导入HDFS:
sqoop import --connect jdbc:mysql://master:3306/company --username root --password root --table staff --target-dir /user/company --delete-target-dir --num-mappers 1 --fields-terminated-by " " --incremental append --check-column id
4.1.2mysql转入hive
(
hive 里面的lib下的hive-exec-**.jar 放到sqoop 的lib 下可以解决以下问题
cp ../../hive2/lib/hive-exec-2.3.3.jar ./
)
(先转入到hdfs再转入hive,所用到的hdfs上面的目录,只是个临时目录)
sqoop import --connect jdbc:mysql://master:3306/company --username root --password root --table staff --hive-import --num-mappers 1 --fields-terminated-by " " --target-dir /user/hive/warehouse/staff
登陆hive,可以看到表已经导入了:
清空Mysql的dept表,将hive的数据导入。
sqoop export --connect jdbc:mysql://master:3306/company --username root --password root --table staff -m 1 --export-dir /hive/warehouse/staff --input-fields-terminated-by ' '
$ bin/sqoop import
--connect jdbc:mysql://master:3306/company
--username root
--password 111111
--table staff
--num-mappers 1
--hive-import
--fields-terminated-by " "
--hive-overwrite
--hive-table staff_hive
或者
sqoop import --connect jdbc:mysql://master:3306/company --username root --
password 111111 --table staff --hive-import -m 1 --fields-terminated-by " " --hive-overwrite --create-hive-table --delete-target-dir --hive-database company --hive-table staff
Sqoop导入mysql表中的数据到hive,出现如下错误:
ERROR hive.HiveConfig: Could not load org.apache.hadoop.hive.conf.HiveConf.
Make sure HIVE_CONF_DIR is set correctly.
原因:缺少了hive-common-2.3.3.jar包,在hive的lib目录下,拷贝到sqoop的lib目录
下即可。或者hive-exec-2.3.2.jar
尖叫提示:该过程分为两步,第一步将数据导入到 HDFS,第二步将导入到 HDFS 的数据迁
移到 Hive 仓库
尖叫提示:第一步默认的临时目录是/user/hadoop/表名,执行成功自动删除
4.2、导出数据
在 Sqoop 中,“导出”概念指:从大数据集群(HDFS,HIVE,HBASE)向非大数据集群
(RDBMS)中传输数据,叫做:导出,即使用 export 关键字。
4.2.1、HIVE/HDFS 到 RDBMS
$ bin/sqoop export
--connect jdbc:mysql://master:3306/company
--username root
--password root
--table staff
--num-mappers 1
--export-dir /user/hive/warehouse/staff_hive
--input-fields-terminated-by " "
尖叫提示:Mysql 中如果表不存在,不会自动创建
4.4 RDBM到HBASE
sqoop import --connect jdbc:mysql://master:3306/company --
username root --password root --table staff --hbase-table
hbase_tohdfs_bulk --column-family info --hbase-create-table --
hbase-row-key id --hbase-bulkload
4.3、脚本打包
使用 opt 格式的文件打包 sqoop 命令,然后执行
1) 创建一个.opt 文件
$ mkdir opt
$ touch opt/job_HDFS2RDBMS.opt
2) 编写 sqoop 脚本
$ vi opt/job_HDFS2RDBMS.opt
export
--connect
jdbc:mysql://master:3306/company
--username
root
--password
111111
--table
staff
--num-mappers
1
--export-dir
/user/hive/warehouse/staff_hive
--input-fields-terminated-by
" "
上述每写一个就换行写入
3)执行该脚本
$ bin/sqoop --options-file opt/job_HDFS2RDBMS.opt
网上搜索的执行hbase和mysql转换
Mysql与Hbase之间:
启动hbase(start-hbase.sh)
输入hbase shell进入到 hbase命令行:
sqoop import --connect jdbc:mysql://master:3306/sqoop --username root --password 12345 --table 'dept' --hbase-create-table --hbase-table hbase_dept --column-family col_family --hbase-row-key id
创建hbase表:create 'hbase_dept','col_family'
有与版本不兼容问题,导入失败了。可以将mysql数据导入到hdfs,在从hdfs导入hbase
五、Sqoop 一些常用命令及参数
5.1、常用命令列举
这里给大家列出来了一部分 Sqoop 操作时的常用参数,以供参考,需要深入学习的可以参
看对应类的源代码。
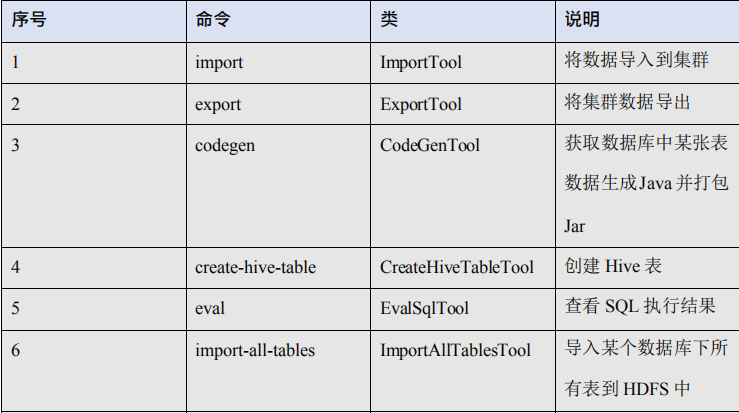
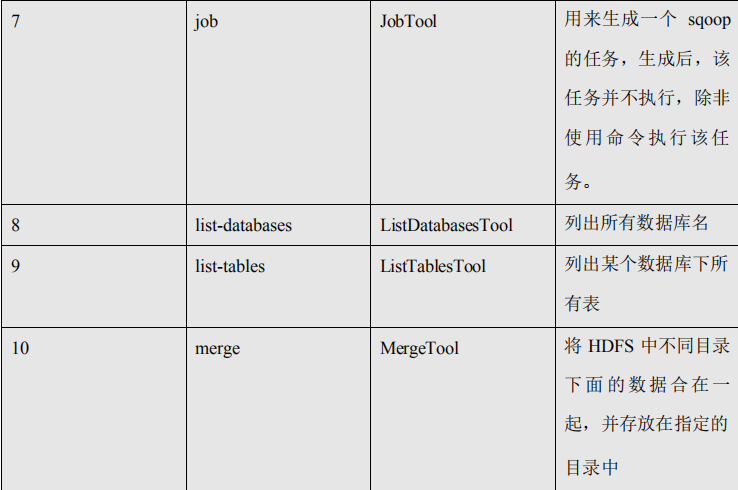


5.2、命令&参数详解
刚才列举了一些 Sqoop 的常用命令,对于不同的命令,有不同的参数,让我们来一一列举
说明。 首先来我们来介绍一下公用的参数,所谓公用参数,就是大多数命令都支持的参数
。
5.2.1、公用参数:数据库连接

5.2.2、公用参数:import
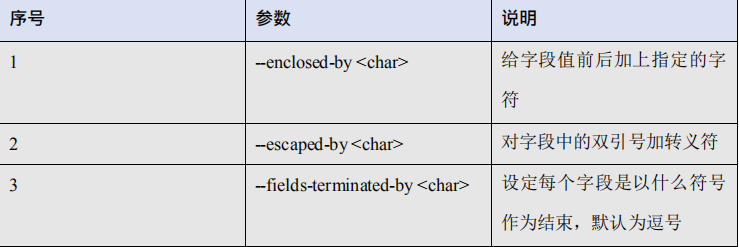
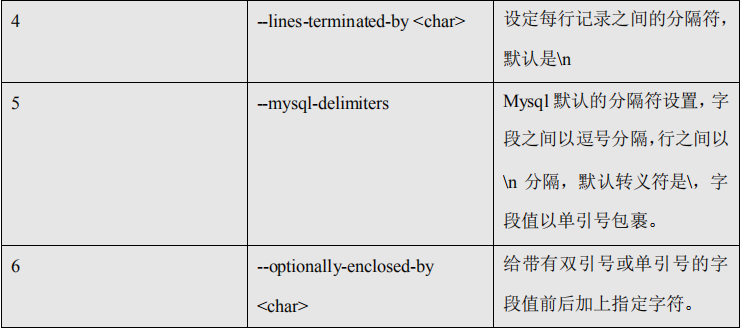
5.2.3、公用参数:export
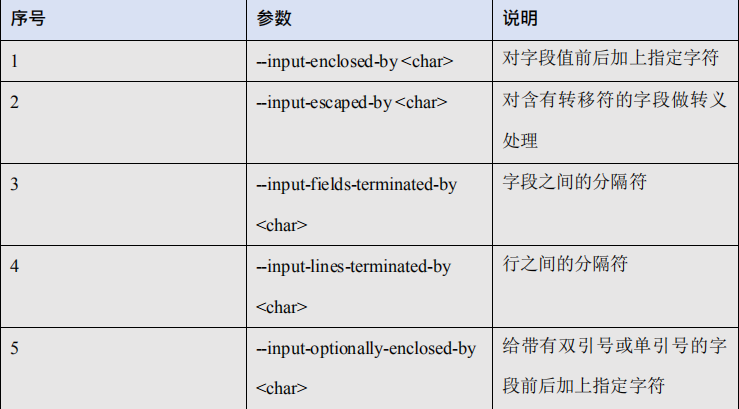
5.2.4、公用参数:hive

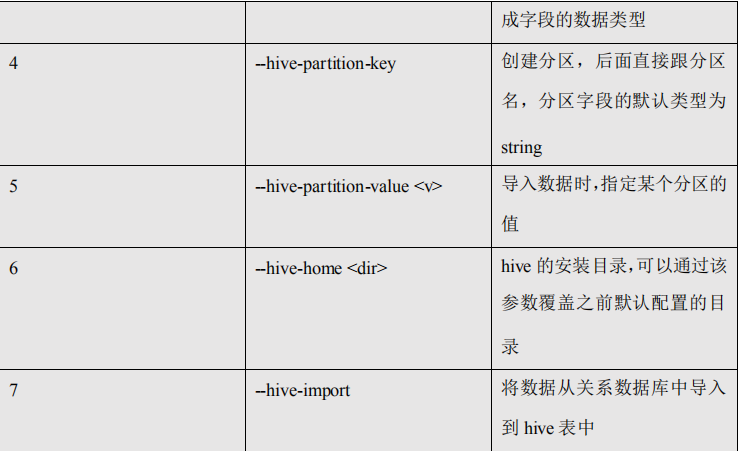
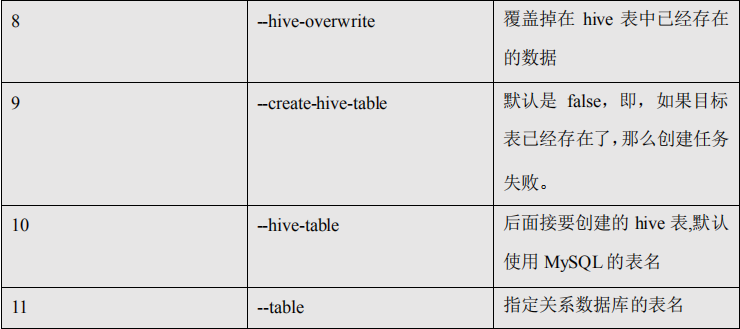
公用参数介绍完之后,我们来按照命令介绍命令对应的特有参数。
5.2.5、命令&参数:import
将关系型数据库中的数据导入到 HDFS(包括 Hive,HBase)中,如果导入的是 Hive,那么
当 Hive 中没有对应表时,则自动创建。
1) 命令:
如:导入数据到 hive 中
$ bin/sqoop import
--connect jdbc:mysql://master:3306/company
--username root
--password 111111
--table staff
--hive-import
如:增量导入数据到 hive 中,mode=append
append 导入:
$ bin/sqoop import
--connect jdbc:mysql://master:3306/company
--username root
--password 111111
--table staff
--num-mappers 1
--fields-terminated-by " "
--target-dir /user/hive/warehouse/staff_hive
--check-column id
--incremental append
--last-value 3
尖叫提示:append 不能与--hive-等参数同时使用(Append mode for hive imports is not yet
supported. Please remove the parameter --append-mode)
如:增量导入数据到 hdfs 中,mode=lastmodified
先在 mysql 中建表并插入几条数据:
mysql> create table company.staff_timestamp(id int(4), name varchar(255), sex varchar(255),
last_modified timestamp DEFAULT CURRENT_TIMESTAMP ON UPDATE
CURRENT_TIMESTAMP);
mysql> insert into company.staff_timestamp (id, name, sex) values(1, 'AAA', 'female');
mysql> insert into company.staff_timestamp (id, name, sex) values(2, 'BBB', 'female');
先导入一部分数据:
$ bin/sqoop import
--connect jdbc:mysql://master:3306/company
--username root
--password 111111
--table staff_timestamp
--delete-target-dir
--m 1
再增量导入一部分数据:
mysql> insert into company.staff_timestamp (id, name, sex) values(3, 'CCC', 'female');
$ bin/sqoop import
--connect jdbc:mysql://master:3306/company
--username root
--password 111111
--table staff_timestamp
--check-column last_modified
--incremental lastmodified
--last-value "2017-09-28 22:20:38"
--m 1
--append
尖叫提示:使用 lastmodified 方式导入数据要指定增量数据是要--append(追加)还是要
--merge-key(合并)
尖叫提示:last-value 指定的值是会包含于增量导入的数据中
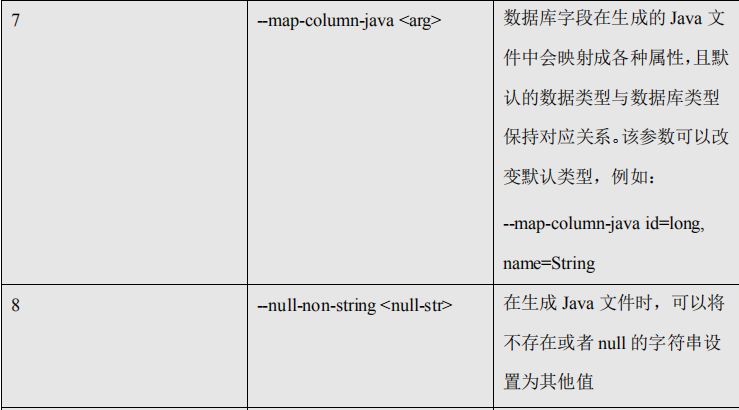
2) 参数:
序号 参数 说明

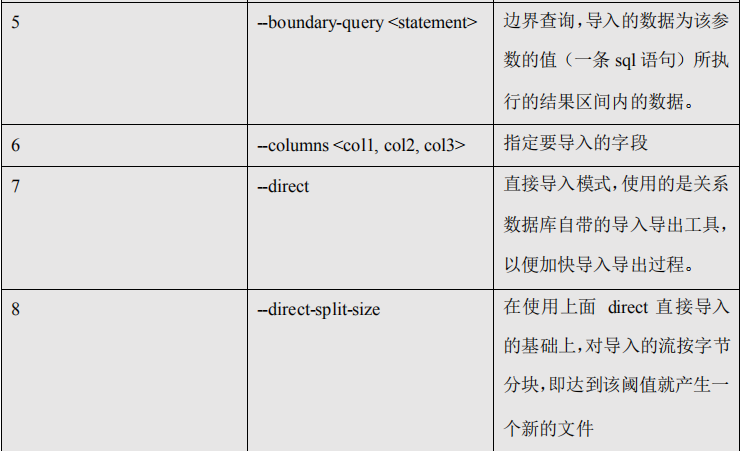


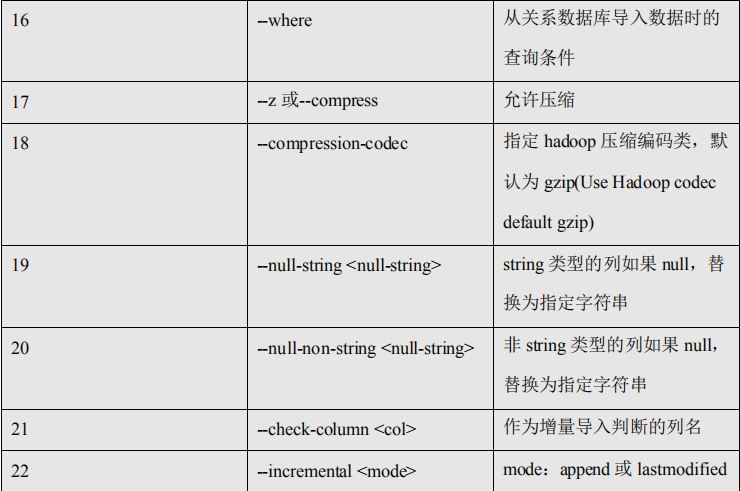

5.2.6、命令&参数:export
从 HDFS(包括 Hive 和 HBase)中奖数据导出到关系型数据库中。
1) 命令: 如:
$ bin/sqoop export
--connect jdbc:mysql://master:3306/company
--username root
--password 111111
--table staff
--export-dir /user/company
--input-fields-terminated-by " "
--num-mappers 1
2) 参数:



5.2.7、命令&参数:codegen
将关系型数据库中的表映射为一个 Java 类,在该类中有各列对应的各个字段。 如
$ bin/sqoop codegen
--connect jdbc:mysql://master:3306/company
--username root
--password 111111
--table staff
--bindir /home/admin/Desktop/staff
--class-name Staff
--fields-terminated-by " "

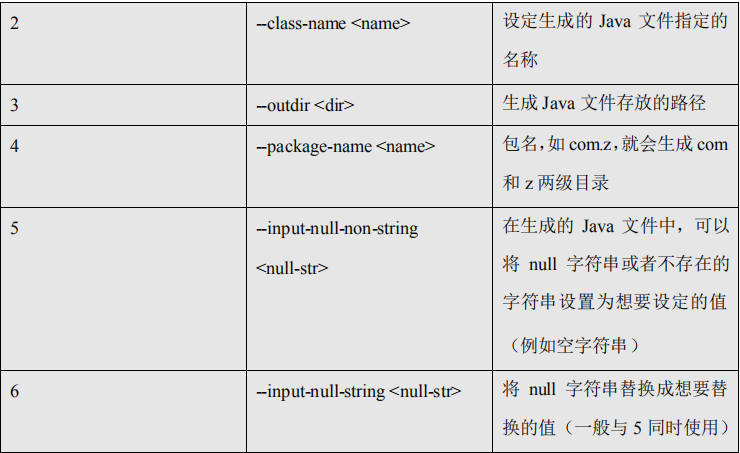

5.2.8、命令&参数:create-hive-table
生成与关系数据库表结构对应的 hive 表结构。
命令:
如:
$ bin/sqoop create-hive-table
--connect jdbc:mysql://master:3306/company
--username root
--password 123456
--table staff
--hive-table hive_staff

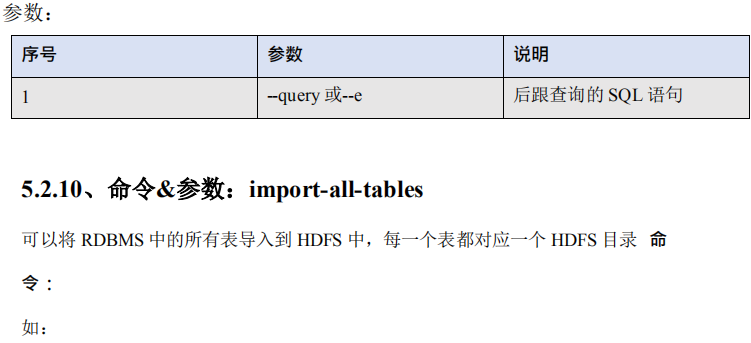
5.2.9、命令&参数:eval
可以快速的使用 SQL 语句对关系型数据库进行操作,经常用于在 import 数据之前,了解一
下 SQL 语句是否正确,数据是否正常,并可以将结果显示在控制台。
命令:
如:
$ bin/sqoop eval
--connect jdbc:mysql://master:3306/company
--username root
--password 123456
--query "SELECT * FROM staff"
$ bin/sqoop import-all-tables
--connect jdbc:mysql://master:3306/company
--username root
--password 123456
--warehouse-dir /all_tables


5.2.11、命令&参数:job
用来生成一个 sqoop 任务,生成后不会立即执行,需要手动执行。
命令:
如:
$ bin/sqoop job
--create myjob -- import-all-tables
--connect jdbc:mysql://master:3306/company
--username root
--password 123456
$ bin/sqoop job
--list
$ bin/sqoop job
--exec myjob
尖叫提示:注意 import-all-tables 和它左边的--之间有一个空格
尖叫提示:如果需要连接 metastore,则--meta-connect jdbc:hsqldb:hsql://master:16000/sqoop
参数:


<property>
<name>sqoop.metastore.client.record.password</name>
<value>true</value>
<description>If true, allow saved passwords in the metastore.</description>
</property>
5.2.12、命令&参数:list-databases
命令: 如
:
$ bin/sqoop list-databases
--connect jdbc:mysql://master:3306/
--username root
--password 123456
参数:与公用参数一样
5.2.13、命令&参数:list-tables
命令: 如
:
$ bin/sqoop list-tables
--connect jdbc:mysql://master:3306/company
--username root
--password 123456
参数:与公用参数一样
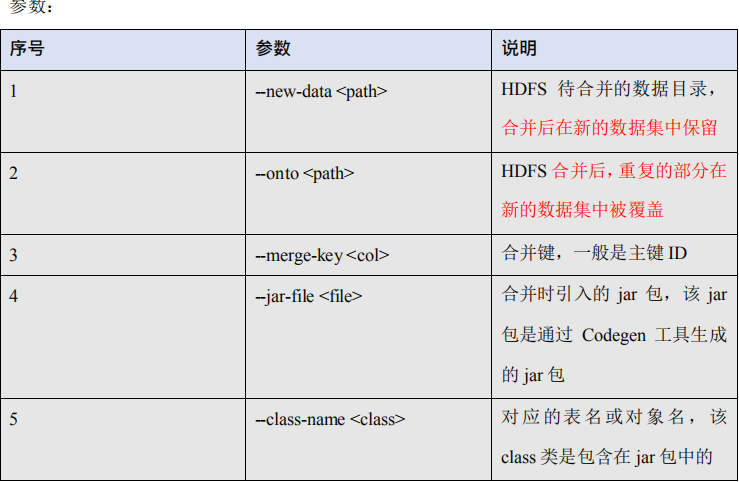
5.2.14、命令&参数:merge
将 HDFS 中不同目录下面的数据合并在一起并放入指定目录中
数据环境:

尖叫提示:上边数据的列之间的分隔符应该为 ,行与行之间的分割符为
,如果直接复制,
请检查之。
命令: 如
:
创建 JavaBean:
$ bin/sqoop codegen
--connect jdbc:mysql://master:3306/company
--username root
--password 123456
--table staff
--bindir /home/admin/Desktop/staff
--class-name Staff
--fields-terminated-by " "
开始合并:
$ bin/sqoop merge
--new-data /test/new/
--onto /test/old/
--target-dir /test/merged
--jar-file /home/admin/Desktop/staff/Staff.jar
--class-name Staff
--merge-key id
结果


5.2.15、命令&参数:metastore
记录了 Sqoop job 的元数据信息,如果不启动该服务,那么默认 job 元数据的存储目录为
~/.sqoop,可在 sqoop-site.xml 中修改。 命令
:
如:启动 sqoop 的 metastore 服务
$ bin/sqoop metastore
