环境准备
1 python + requests + BeautifulSoup
页面准备
主页面:
http://www.netbian.com/dongman/
图片伪地址:
http://www.netbian.com/desk/22371.htm
图片真实地址:
http://img.netbian.com/file/2019/1221/36eb674ba0633d185da078804a3638e6.jpg
步骤
1 导入库
import requests
from bs4 import BeautifulSoup
import re
2 更改请求头
ua = "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:72.0) Gecko/20100101 Firefox/72.0"
# "Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:16.0) Gecko/20100101 Firefox/16.0",
# "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.11 (KHTML, like Gecko) Chrome/23.0.1271.64 Safari/537.11",
# "Mozilla/5.0 (X11; U; Linux x86_64; zh-CN; rv:1.9.2.10) Gecko/20100922 Ubuntu/10.10 (maverick) Firefox/3.6.10",
# "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36",
# "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:72.0) Gecko/20100101 Firefox/72.0",
# "Mozilla/5.0(Windows NT 10.0; Win64; x64) AppleWebKit / 537.36(KHTML, like Gecko) Chrome/74.0.3729.131 Safari/537.36"
3 获取主页面的内容
response = requests.get(url, headers={'User-Agent': ua})
html = response.text
soup = BeautifulSoup(html, 'html.parser')
4 我们要的是main里的list中的li标签中的a标签的href,而不是a标签里的img标签的src,若时获取img里的地址其大小为 800*450
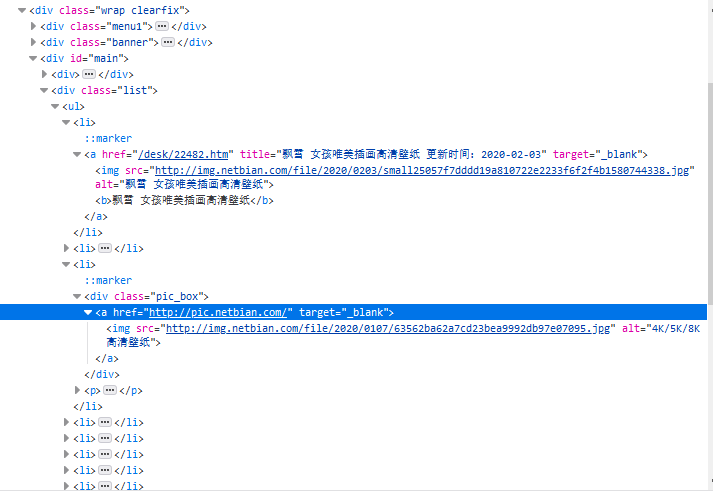
list = soup.find(name='div', attrs='list')
for li in list.find_all('li'):
# print(img.attrs['src'])
for a in li.children:
if a.name == 'a':
src = 'http://www.netbian.com' + a.attrs['href']
5 截取连接里的数字作为图片的名称(这里可以自己想怎么弄就怎么弄)
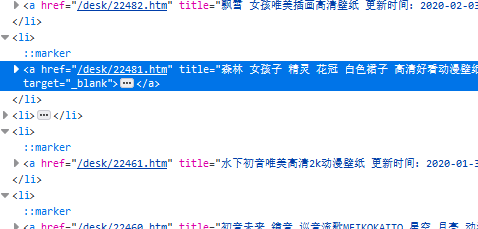
n = re.search(r'd+', a.attrs['href'])[0] # 这里是d+,而不是d{5},是为了避免万一只出现4个数字,则会报错
6 到达真实图片地址
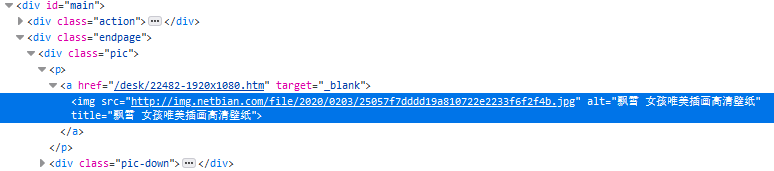
res = requests.get(src, headers={'User-Agent': ua})
s = BeautifulSoup(res.text, 'html.parser')
p = s.find(name='p')
# print(p)
img = p.img.attrs['src']
# print(img)
# 判断地址是否为空
if not img:
continue
7 下载
with requests.get(img, headers={'User-Agent': ua}) as resp:
# print(resp.status_code)
resp.raise_for_status()
resp.encoding = res.apparent_encoding
# 将图片内容写入
with open('E://paper//{}.jpg'.format(n), 'wb') as f:
f.write(resp.content)
f.close()
8 若要下载所有的图片

# 页数循环
for i in range(1, 139):
if i == 1:
url = 'http://www.netbian.com/dongman/index.htm'
else:
url = 'http://www.netbian.com/dongman/index_{}.htm'.format(i)
# print(url)
9 结果

注:
若会Xpath的话,用Xpath会比BeautifulSoup要简单点,我自己是懒得改过去了。