当SQL数据库日志文件已满,或者日志很大,怎么办
当SQL数据库日志文件已满,或者日志很大,就需要压缩日志及数据库文件:
1.清空日志
DUMP TRANSACTION 库名 WITH NO_LOG
2.截断事务日志:
BACKUP LOG 数据库名 WITH NO_LOG
3.收缩数据库文件(如果不压缩,数据库的文件不会减小
企业管理器--右键你要压缩的数据库--所有任务--收缩数据库--收缩文件
--选择日志文件--在收缩方式里选择收缩至XXM,这里会给出一个允许收缩到的最小M数,直接输入这个数,确定就可以了
--选择数据文件--在收缩方式里选择收缩至XXM,这里会给出一个允许收缩到的最小M数,直接输入这个数,确定就可以了
也可以用SQL语句来完成
--收缩数据库
DBCC SHRINKDATABASE(客户资料)
--收缩指定数据文件,1是文件号,可以通过这个语句查询到:select * from sysfiles
DBCC SHRINKFILE(1)
4.为了最大化的缩小日志文件(如果是sql 7.0,这步只能在查询分析器中进行)
a.分离数据库:
企业管理器--服务器--数据库--右键--分离数据库
b.在我的电脑中删除LOG文件
c.附加数据库:
企业管理器--服务器--数据库--右键--附加数据库
此法将生成新的LOG,大小只有500多K
或用代码:
下面的示例分离 pubs,然后将 pubs 中的一个文件附加到当前服务器。
a.分离
E X E C sp_detach_db @dbname = "pubs"
b.删除日志文件
c.再附加
E X E C sp_attach_single_file_db @dbname = "pubs",
@physname = "c:Program FilesMicrosoft SQL ServerMSSQLDatapubs.mdf"
5.为了以后能自动收缩,做如下设置:
企业管理器--服务器--右键数据库--属性--选项--选择"自动收缩"
--SQL语句设置方式:
E X E C sp_dboption "数据库名", "autoshrink", "TRUE"
6.如果想以后不让它日志增长得太大
企业管理器--服务器--右键数据库--属性--事务日志
--将文件增长限制为xM(x是你允许的最大数据文件大小)
--SQL语句的设置方式:
alter database 数据库名 modify file(name=逻辑文件名,maxsize=20)
特别注意:
请按步骤进行,未进行前面的步骤,请不要做后面的步骤
否则可能损坏你的数据库.
一般不建议做第4,6两步
第4步不安全,有可能损坏数据库或丢失数据
第6步如果日志达到上限,则以后的数据库处理会失败,在清理日志后才能恢复.
SQL Server 如何设置数据库的默认初始大小和自动增长大小
sqlserver2008日志已满解决方法,SQL Server 如何设置数据库的默认初始大小和自动增长大小
1、数据库右键属性-选项-恢复模式-下拉选择简单-最后点击确定

2、右键数据库-任务-收缩-文件类型-下拉选择日志-收缩操作-在释放未使用…(默认收缩到1MB)-最后点击确定

3、最后别忘了回到第一步骤把恢复模式改为完整!
我们在SQL Server中新建数据库的时候,可以选择数据库文件及日志文件的初始大小、自动增长大小和最大大小,如下图所示:

可以通过设置更改数据库初始大小、自动增长大小和最大大小:

但是其实在SQL Server中新建数据库时,数据库的初始大小、自动增长大小和最大大小的默认值,是可以在model这个系统数据库上预设的。
比如现在我们将model系统数据库的初始大小设置为50MB,数据库文件增量设置为90MB,数据库文件最大大小设置为1024MB,如下图所示:


然后现在我们再在SQL Server中新建一个数据库:

然后我们可以看到新建数据库的初始大小默认为50MB,数据库文件增量默认为90MB,数据库文件最大大小默认为1024MB,和系统数据库model的文件设置完全相同。

所以这就是model这个系统数据库的作用,它实际上是SQL Server中新建数据库的一个模板,SQL Server中新建的数据库会套用model这个系统数据库上的设置作为默认值。所以我们可以在model系统数据库上设置文件初始大小、文件增量和文件最大大小,从而作为新建数据库的预设默认值。
是否使用恢复模式设置为“完整”还是“简单”
1. 如果不是特别重要的库(关系到钱), 一般不推荐恢复模式设置为“完整”,而如果你设置恢复模式为“简单”,基本不会发生日志过大 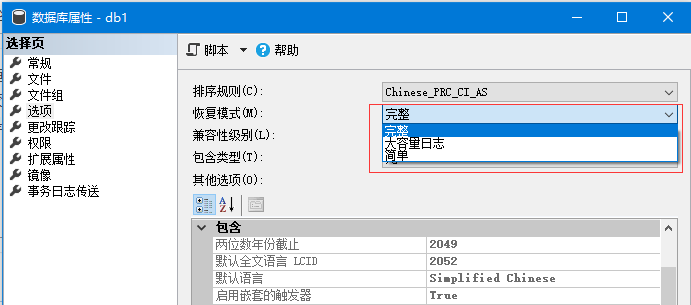 2. 如果你设置为了完整模式,整个数据库的大小超过 1GB 的库,简易一点判断的话, 一般日志文件的大小超过 数据文件 的一半, 就应该查看为什么会日志过大?
2. 如果你设置为了完整模式,整个数据库的大小超过 1GB 的库,简易一点判断的话, 一般日志文件的大小超过 数据文件 的一半, 就应该查看为什么会日志过大?
-
SELECT d.name AS dbName,d.log_reuse_wait_desc
-
FROM sys.databases AS d WHERE d.name NOT IN ('master','model','msdb','tempdb')
查看了 日志不能复用的原因, 就得采取相关的措施去解决。 当然, 你采取了完整模式, 你就得定期去备份日志, 收缩日志, 这是必备的功底。哪怕没有任何的异常, 你不这样处理, 日志一样会变得非常大。
-
use [dbName]
-
declare @bakfile nvarchar(100)--@bakfile备份文件名
-
set @bakfile='d:database_baklog_bak_'+convert(nvarchar(8),getdate(),112)+'.log'
-
BACKUP LOG [dbName] TO DISK= @bakfile WITH RETAINDAYS= 1,COMPRESSION --dbName为数据库名
-
-
dbcc shrinkfile(dbName_log,100) --dbName_log为数据库文件逻辑名称,100为希望日志收缩到的MB数
日志不能重用有多种可能, 就不一一展开了, 但你能做好上面的, 一般情况下不必操那么多的心了。