摘要:本文主要讨论一些在ETL中设计增量更新的方法和技巧。
ETL中增量更新是一个比较依赖与工具和设计方法的过程,Kettle中主要提供Insert / Update 步骤,Delete 步骤和Database Lookup步骤来支持增量更新,增量更新的设计方法也是根据应用场景来选取的,虽然本文讨论的是Kettle的实现方式,但也许对其他工具也有一些帮助。本文不可能涵盖所有的情况,欢迎大家讨论。
应用场景
增量更新按照数据种类的不同大概可以分成:
1. 只增加,不更新,
2. 只更新,不增加
3. 即增加也更新
4. 有删除,有增加,有更新
其中1,2, 3种大概都是相同的思路,使用的步骤可能略有不同,通用的方法是在原数据库增加一个时间戳,然后在转换之后的对应表保留这个时间戳,然后每次抽取数据的时候,先读取这个目标数据库表的时间戳的较大值,把这个值当作参数传给原数据库的相应表,根据这个时间戳来做限定条件来抽取数据,抽取之后同样要保留这个时间戳,并且原数据库的时间戳一定是指定默认值为sysdate当前时间(以原数据库的时间为标准),抽取之后的目标数据库的时间戳要保留原来的时间戳,而不是抽取时候的时间。
对于第一种情况,可以使用Kettle的Insert / Update 步骤,只是可以勾选Don’t perform any update选项,这个选项可以告诉Kettle你只会执行Insert步骤。
对于第二种情况可能比较用在数据出现错误然后原数据库有一些更新,相应的目标数据库也要更新,这时可能不是更新所有的数据,而是有一些限定条件的数据,你可以使用Kettle的Update步骤来只执行更新。关于如何动态的执行限定条件,可以参考前一篇文章。
第三种情况是更为常见的一种情况,使用的同样是 Kettle的Insert / Update 步骤,只是不要勾选Don’t perform any update选项。
第四种情况有些复杂,后面专门讨论。
对于第1,2,3种情况,可以参考下面的例子。
这个例子假设原数据库表为customers ,含有一个id , firstname , lastname , age字段,主键为id , 然后还加上一个默认值为sysdate的时间戳字段。转换之后的结果类似:id , firstname , lastname , age , updatedate .整个设计流程大概如下:
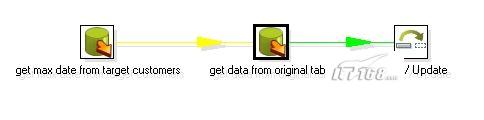
图1
其中第一个步骤的SQL大概如下模式:
Select max(updatedate) from target_customer ;
你会注意到第二个步骤和第一个步骤的连接是黄色的线,这是因为第二个table input步骤把前面一个步骤的输出当作一个参数来用,所有Kettle用黄色的线来表示,第二个table input的sql 模式大概如下:
Select field1 , field2 , field3 from customers where updatedate > ?
后面的一个问号就是表示它需要接受一个参数,你在这个table input下面需要指定replace variable in script选项和execute for each row 为选中状态,这样,Kettle就会循环执行这个sql ,执行的次数为前面参数步骤传入的数据集的大小。
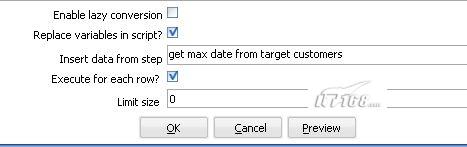
图2
关于第三个步骤执行insert / update步骤需要特别解释一下,
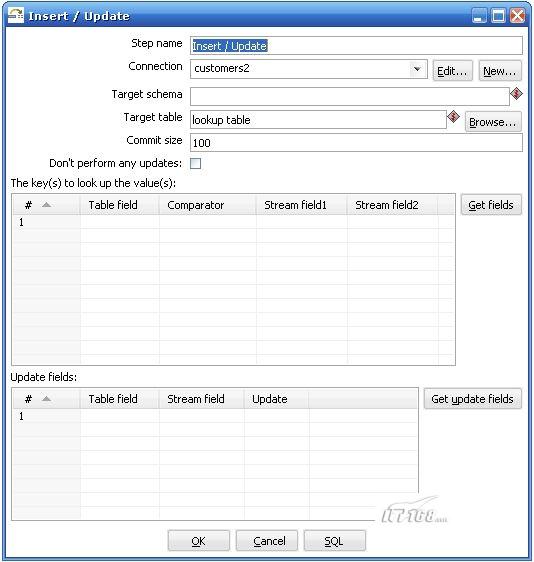
图3
Kettle执行这个步骤是需要两个数据流对比,其中一个是目标数据库,你在Target table 里面指定的,它放在The keys to look up the values(s)左边的Table field 里面的,另外一个数据流就是你在前一个步骤传进来的,它放在The keys to look up the value(s)的右边,Kettle首先用你传进来的key在数据库中查询这些记录,如果没有找到,它就插入一条记录,所有的值都跟你原来的值相同,如果根据这个key找到了这条记录,kettle会比较这两条记录,根据你指定update field来比较,如果数据完全一样,kettle就什么都不做,如果记录不完全一样,kettle就执行一个update步骤。所以首先你要确保你指定的key字段能够确定一条记录,这个时候会有两种情况:
1. 维表
2. 事实表
维表大都是通过一个主键字段来判断两条记录是否匹配,可能我们的原数据库的主键记录不一定对应目标数据库中相应的表的主键,这个时候原数据库的主键就变成了业务主键,你需要根据某种条件判断这个业务主键是否相等,想象一下如果是多个数据源的话,业务主键可能会有重复,这个时候你需要比较的是根据你自定义生成的新的实际的主键,这种主键可能是根据某种类似与sequence的生成方式生成的,
事实表在经过转换之后,进目标数据库之前往往都是通过多个外键约束来确定一条记录的,这个时候比较两条记录是否相等都是通过所有的维表的外键决定的,你在比较了记录相等或不等之后,还要自己判断是否需要添加一个新的主键给这个新记录。
上面两种情况都是针对特定的应用的,如果你的转换过程比较简单,只是一个原数据库对应一个目标数据库,业务主键跟代理主键完全相同的时候完全可以不用考虑这么多.
有删除,有增加,有更新
首先你需要判断你是否在处理一个维表,如果是一个维表的话,那么这可能是一个SCD情况,可以使用Kettle的Dimension Lookup 步骤来解决这个问题,如果你要处理的是事实表,方法就可能有所不同,它们之间的主要区别是主键的判断方式不一样。
事实表一般都数据量很大,需要先确定是否有变动的数据处在某一个明确的限定条件之下,比如时间上处在某个特定区间,或者某些字段有某种限定条件,尽量较大程度的先限定要处理的结果集,然后需要注意的是要先根据id来判断记录的状态,是不存在要插入新纪录,还是已存在要更新,还是记录不存在要删除,分别对于id的状态来进行不同的操作。
处理删除的情况使用Delete步骤,它的原理跟Insert / Update 步骤一样,只不过在找到了匹配的id之后执行的是删除操作而不是更新操作,然后处理Insert / Update操作,你可能需要重新创建一个转换过程,然后在一个Job 里面定义这两个转换之间的执行顺序。
如果你的数据变动量比较大的话,比如超过了一定的百分比,如果执行效率比较低下,可以适当考虑重新建表。
另外需要考虑的是维表的数据删除了,对应的事实表或其他依赖于此维表的表的数据如何处理,外键约束可能不太容易去掉,或者说一旦去掉了就可能再加上去了,这可能需要先处理好事实表的依赖数据,主要是看你如何应用,如果只是简单的删除事实表数据的话还比较简单,但是如果需要保留事实表相应记录,可以在维表中增加一条记录,这条记录只有一个主键,其他字段为空,当我们删除了维表数据后,事实表的数据就更新指向这条空的维表记录。
定时执行增量更新
可能有时候我们就是定时执行更新操作,比如每天或者一个星期一次,这个时候可以不需要在目标表中增加一个时间戳字段来判断ETL进行的较大时间,直接在取得原数据库的时间加上限定条件比如:
Startdate > ? and enddate < ?
或者只有一个startdate
Startdate > ? (昨天的时间或者上个星期的时间)
这个时候需要传一个参数,用get System Info步骤来取得,而且你还可以控制时间的精度,比如到天而不是到秒的时间。
当然,你也需要考虑一下如果更新失败了怎么处理,比如某一天因为某种原因没有更新,这样可能这一天的记录需要手工处理回来,如果失败的情况经常可能发生,那还是使用在目标数据库中增加一个时间字段取较大时间戳的方式比较通用,虽然它多了一个很少用的字段。
执行效率和复杂度
删除和更新都是一项比较耗费时间的操作,它们都需要不断的在数据库中查询记录,执行删除操作或更新操作,而且都是一条一条的执行,执行效率低下也是可以预见的,尽量可能的缩小原数据集大小。减少传输的数据集大小,降低ETL的复杂程度
时间戳方法的一些优点和缺点
优点: 实现方式简单,很容易就跨数据库实现了,运行起来也容易设计
缺点:浪费大量的储存空间,时间戳字段除ETL过程之外都不被使用,如果是定时运行的,某一次运行失败了,就有可能造成数据有部分丢失.
其他的增量更新办法:
增量更新的核心问题在与如何找出自上次更新以后的数据,其实大多数数据库都能够有办法捕捉这种数据的变化,比较常见的方式是数据库的增量备份和数据复制,利用数据库的管理方式来处理增量更新就是需要有比较好的数据库管理能力,大多数成熟的数据库都提供了增量备份和数据复制的方法,虽然实现上各不一样,不过由于ETL的增量更新对数据库的要求是只要数据,其他的数据库对象不关心,也不需要完全的备份和完全的stand by 数据库,所以实现方式还是比较简单的.,只要你创建一个与原表结构类似的表结构,然后创建一个三种类型的触发器,分别对应insert , update , delete操作,然后维护这个新表,在你进行ETL的过程的时候,将增量备份或者数据复制停止,然后开始读这个新表,在读完之后将这个表里面的数据删除掉就可以了,不过这种方式不太容易定时执行,需要一定的数据库特定的知识。如果你对数据的实时性要求比较高可以实现一个数据库的数据复制方案,如果对实时性的要求比较低,用增量备份会比较简单一点。
几点需要注意的地方:
1. 触发器
无论是增量备份还是数据复制,如果原表中有触发器,在备份的数据库上都不要保留触发器,因为我们需要的不是一个备份库,只是需要里面的数据,较好所有不需要的数据库对象和一些比较小的表都不用处理。
2. 逻辑一致和物理一致
数据库在数据库备份和同步上有所谓逻辑一致和物理一致的区别,简单来说就是同一个查询在备份数据库上和主数据库上得到的总的数据是一样的,但是里面每一条的数据排列方式可能不一样,只要没有明显的排序查询都可能有这种情况(包括group by , distinct , union等 ),而这可能会影响到生成主键的方式,需要注意在设计主键生成方式的时候较好考虑这一点,比如显式的增加order排序. 避免在数据出错的时候,如果需要重新读一遍数据的时候主键有问题.
总结
增量更新是ETL中一个常见任务,对于不同的应用环境可能采用不同的策略,本文不可能覆盖所有的应用场景,像是多个数据源汇到一个目标数据库,id生成策略,业务主键和代理主键不统一等等,只是希望能给出一些思路处理比较常见的情况,希望能对大家有所帮助。