数据库是极其重要的R语言数据导入源数据之地,读入包有sqldf、RODBC等。跟SQL server相连有RODBC,跟mySQL链接的有RMySQL。但是在R里面,回传文本会出现截断的情况,这一情况可把我弄得有点手足无措。
一、数据库读入——RODBC包
CRAN 里面的包 RODBC 提供了 ODBC的访问接口:
odbcConnect 或 odbcDriverConnect (在Windows图形化界面下,可以通过对话框选择数据库) 可以打开一个连接,返回一个用于随后数据库访问的控制(handle)。 打印一个连接会给出ODBC连接的一些细节,而调用 odbcGetInfo 会给出客户端和服务器的一些细节信息。
在一个连接中的表的细节信息可以通过函数 sqlTables 获得。
函数 sqlSave 会把 R 数据框复制到一个数据库的表中, 而函数 sqlFetch 会把一个数据库中的表拷贝到 一个 R 的数据框中。
通过sqlQuery进行查询,返回的结果是 R 的数据框。(sqlCopy把一个 查询传给数据库,返回结果在数据库中以表的方式保存。) 一种比较好的控制方式是首先调用 odbcQuery, 然后 用 sqlGetResults 取得结果。后者可用于一个循环中 每次获得有限行,就如函数 sqlFetchMore 的功能。
连接可以通过调用函数 close 或 odbcClose 来关闭。 没有 R 对象对应或不在 R 会话后面的连接也可以调用这两个函数来关闭, 但会有警告信息。
[plain] view plain copy
在CODE上查看代码片派生到我的代码片
#安装RODBC包
install.packages("RODBC")
library(RODBC)
mycon<-odbcConnect("mydsn",uid="user",pwd="rply")
#通过一个数据源名称(mydsn)和用户名(user)以及密码(rply,如果没有设置,可以直接忽略)打开了一个ODBC数据库连接
data(USArrests)
#将R自带的“USArrests”表写进数据库里
sqlSave(mycon,USArrests,rownames="state",addPK=TRUE)
#将数据流保存,这时打开SQL Server就可以看到新建的USArrests表了
rm(USArrests)
#清除USArrests变量
sqlFetch(mycon, "USArrests" ,rownames="state")
#输出USArrests表中的内容
sqlQuery(mycon,"select * from USArrests")
#对USArrests表执行了SQL语句select,并将结果输出
sqlDrop(channel,"USArrests")
#删除USArrests表
close(mycon)
#关闭连接
本段来自R语言︱文件读入、读出一些方法罗列(批量xlsx文件、数据库、文本txt、文件夹)
1、sqlSave函数
sqlSave(channel, dat, tablename = NULL, append = FALSE,
rownames = TRUE, colnames = FALSE, verbose = FALSE,
safer = TRUE, addPK = FALSE, typeInfo, varTypes,
fast = TRUE, test = FALSE, nastring = NULL)
其中这个函数的使用还是很讲究的,参数的认识很重要。
append代表是否追加,默认不追加,如果一张已经有数据的表,就可以用append追加新的数据,需要同样的column,一般开个这个就行。
rownames,可以是逻辑值,也可以是字符型。
colnames,列名;
verbose,默认为FALSE,是否发送语句到R界面,如果TRUE,那么每条上传数据就会出现在命令栏目致之中。
addPK,是否将rownames指定为主键。
2、sqlUpdate函数
sqlUpdate(channel, dat, tablename = NULL, index = NULL,
verbose = FALSE, test = FALSE, nastring = NULL,
fast = TRUE)
更新已经存在的表格,需要包括已经存在的列。
——————————————————————————————————————————————
二、sqldf包
本包的学习来自CDA DSC课程,L2-R语言第四讲内容,由常老师主讲。与RODBC的区别在于,前面是直接调用数据库SQL中的数据;而该包是在R语言环境中,执行SQL搜索语言。
组合使用:RODBC从数据库读入环境,sqldf进行搜索(适合SQL大神)。
其他函数的类似功能可以看:R语言数据集合并、数据增减
1、SQL基本特点
SQL语句语句特点:先全局选择,再局部选择
Select * from sale where year=2010 and ...
where后面可以接很多,有比较运算符,算数运算符,逻辑运算符。
比较运算符号:=(等于,不是双引号);!=(不等于);>,<,>=,<=
算数运算符:*,/,+,-
逻辑运算符:&&(and,与), ||(or,或) ,!(,not非)
2、数据筛选与排序
数据筛选可以有subset函数,排序有order/sort函数
#选择表中指定列*/
sqldf("select year,market,sale,profit from sale")
#选择满足条件的行*/
sqldf("select * from sale where year=2012 and market='东'")
#语句特点,先抽取全局数据,然后再执行局部选择
#字符单引号,切记
#对行进行排序*/
sqldf("select year,market,sale,profit
from sale
order by year")
数据筛选:sqldf可以执行选择表中指定指标、满足条件的行(注意:抽取满足条件的行的字符时,字符型需要用单引号),语法结构是:
select 指标名称 from 数据集 where 某指标=条件
排序order:按照某变量排序,语法结构:
select 指标名称(或全部)from 数据集 order by 指标名称
3、数据合并——纵向连接
数据合并的方法很多,基本函数包中有merge、cbind/rbind,以及一些专业的包plyr、dplyr、data.table等
rbind/cbind对数据合并的要求比较严格:合并的变量名必须一致;数据等长;指标顺序必须一致。
sqldf就不会这么苛刻,并参照了一些集合查询的方法(关于基础包的集合查询可参考:R语言︱集合运算)。
(1)并——union
UNION3<-sqldf("select * from one union select * from two")
#合并后去重,rbind是合并后不去重
UNION_all<-sqldf("select * from one union all select * from two")
#all可以支持,合并后不去重
rbind/cbind是将数据一股脑子全部帖在一起,只合并不去重;sqldf则可以自行选择,语法结构:
select * from 数据集1 union (all) select * from 数据集2
其中的all代表不去重,一起加进来。
(2)差(except)、交(Intersect)
#EXCEPT_差集
#不存在all
EXCEPT<-sqldf("select * from one EXCEPT select * from two")
#INTERSECT——交集
INTERSECT<-sqldf("select * from one INTERSECT select * from two")
差集就是找两个数据集的不同的数据,而且是数据集1中,去掉重复的数值;并集则是两个数据集的重合(去重可以用)之处。
4、数据合并——横向连接
横向连接有三种类型:交叉连接(笛卡尔乘积,大乱炖所有数据重新排列组合合并起来,一般在实验设计涉及全排列的时候可以很好地使用)、内连接(筛选匹配到的数据)、外连接。
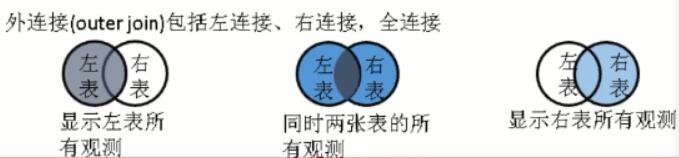
其中,sqldf 中的右连接、全连接已经失效,一般情况下会大多选择左联结。
(1)内连接——匹配到完全一致的
> inner1<- merge(table1, table2, by = "id", all = F);inner1 #筛选相同id,F为只连接匹配到的,T为没有匹配到的赋值NA
id a b
1 3 c e
> inner2<-inner_join(table1, table2, by = "id");inner2 #与merge完全一致
id a b
1 3 c e
> inner3<-sqldf("select * from table1 as a inner join table2 as b on a.id=b.id");inner3 #内连接
id a id b
1 3 c 3 e
> inner4<-sqldf("select * from table1 as a,table2 as b where a.id=b.id");inner4 #笛卡尔积
id a id b
1 3 c 3 e
匹配到完全一致、相同的,基础包merge=dplyr的inner_join=sqldf包中的inner join。当然输出结果中,sqldf中会蹦出来两个id,可以进行删除。
其中sql包中的Inner join语法结构为:
select * from 数据集1 as a inner join 数据集2 as b on a.指标名称=b.指标名称
(2)左连接——最有效,以数据集1为准,匹配到的+为匹配到的
> left1<- merge(table1, table2, by = "id", all.x = TRUE);left1 #按照id连接所有信息包括进去
id a b
1 1 a <NA>
2 2 b <NA>
3 3 c e
> left2<-left_join(table1, table2, by = "id");left2
id a b
1 1 a <NA>
2 2 b <NA>
3 3 c e
> left3<-sqldf("select * from table1 as a left join table2 as b on a.id=b.id");left3
id a id b
1 1 a NA <NA>
2 2 b NA <NA>
3 3 c 3 e
基础包中的merge,当all=F就是内连接,all=T就是全连接,all.x=T就是左联结,all.y=T就是右连接(merge函数首选all=T,全连接);dplyr中的left_join也可以实现merge,all=T效果
sqldf中的语法结构:
select * from 数据集1 as a left join 数据集2as b on a.指标名称=b.指标名称
4、数据去重
#删除重复的行*/
sqldf("select DISTINCT year from sale")
解读:distinct跟unique去重功能差不多,语法特点:
select DISTINCT 指标名称 from 数据集
——————————————————————————————————————————————————————
应用一:R语言中文本回传SQL出现截断(truncated )现象,怎么办?
R语言中用sqlSave函数,把文本回传的时候回出现这样的问题,文本超过255个字符的会出现截断truncated现象,因为回传到SQL之后,规定的字符数即为varchar(255),所以会出现截断现象。
如果出现这样的截断现象该如何解决呢?
解决办法一:修改SQL Server的字符
先创建一个表,然后把那个字符型格式修改为varchar(4000),或者其他格式,不能修改成max,会报错,造成Rstudio崩溃。当然,也可以先sqlSave一个版本过去(就几条内容),然后修改一下格式之后,继续append追加内容进行。
SQL Server 2008中在修改数据类型的时候,会报错,一直保存不了,需要按照以下的内容设置一下:
选择菜单 工具-〉选项-〉表设计器(Designers)-〉表设计器和数据库设计器table and database designers。然后去掉“ 阻止保存要求重新创建表的更改”(prevent saving changes that require table re-creation)前面的勾。重新启动MSSQL SERVER 2008可以解决该问题。 (来源博客:http://franciswmf.iteye.com/blog/1962550)
但是笔者在尝试该办法的时候,总是修改之后就卡死,所以无奈选择第二条路。
解决办法二:从R中导出然后导入SQL Server
笔者尝试过,导出csv/txt但是直接用SQL Server内嵌工具,“SQL Server Import and export Wizard”对于csv/txt导入都十分麻烦,导入出现很多问题。
所以最后是用csv-转excel-用上述工具导入。
问题一:R语言中,用write.csv时候,用office打开,多出了很多行?
如果文本字符长度很大,那么就会出现内容串到下面一行的情况,譬如10行的内容,可能变成了15行。好像office默认单个单元格的字符一般不超过2500字符,超过就会给到下一行。
所以笔者在导入5W条数据时候,多出了很多行,于是只能手动删除。
如果用txt格式导出,用Notepad++打开是好的,但是用excel打开又多出来不少行,所以用excel打开是用代价的。
但是由于excel是最好的导入SQL的格式,于是不得不手工删除,同时牺牲一部分的内容。
问题二:如何使用SQL Server Import and export Wizard?
1、choose a Data Source界面(注意勾选,在第一个数据行中显示列名称)
2、Data Source中,有Flat File Source 栏目,就是用来做csv、txt格式的;还有一个excel选项是专门针对excel
3、导入数据界面,你需要输入服务器名称,已经相应的数据库名称;
4、选择源表和源视图,你可以通过”目标“栏目新建,也可以导入已经有的表格,当然第一次导入,笔者推荐直接导入新表,注意看检查一下下面的一个栏目”编辑映射“
5、运行语句。
其中,如果你是第二次导入已经有的表,那么在第四步,”编辑映射“时,就需要看清楚是否与已有的数据列表一一对应。
同时,如果第二次导入的表有表头名称,只要第一步勾选列名称,也是没有关系的,导入后不算入数据之中。
主要教程来源于:http://www.xlgps.com/article/61446.html
问题三:通过SQL代码导入
相关内容可参考博客:
http://www.it165.net/database/html/201310/4632.html
http://www.cnblogs.com/wangshenhe/archive/2013/04/27/3047092.html
——————————————————————————————————————————————————————
贴张dplyr包的用法


---------------------
作者:悟乙己
来源:CSDN
原文:https://blog.csdn.net/sinat_26917383/article/details/51601539
版权声明:本文为博主原创文章,转载请附上博文链接!