爬虫的定义
向网站发起请求,获取资源后分析并提取 有用数据 (我们的爬虫程序只提取网页代码中对我们有用的数据)
爬虫的基本流程

1、发起请求 使用 http 库向目标站点发起请求,即发送一个 Request Request 包含:请求头、请求体等 注:selenium 也是经常用到的模块,可以解析 html 页面 2、获取响应内容 如果服务器能正常响应,则会得到一个 Response Response 包含:html,json,图片,视频等 3、解析内容 解析 html 数据:正则表达式,第三方解析库如 Beautifulsoup,pyquery 等 解析 json 数据:json 模块 解析二进制数据:以 b 模式写入文件 4、保存数据 保存在数据库: MySQL, mongoDB, redis等 或者文件中
官网链接:
下载安装:pip3 install requests
Requests
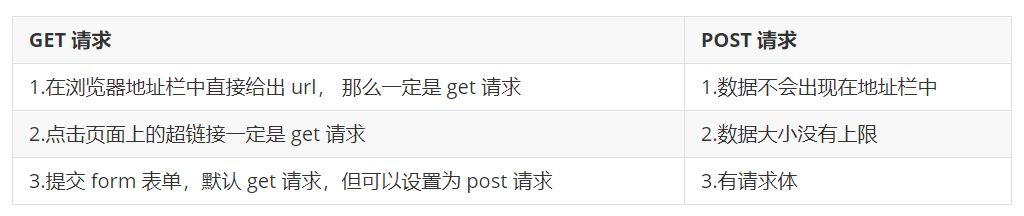
1:发送 GET 和 POST 请求(常用)
使用 request 发送 get 和 post 请求,访问的数据都会拼接成这种形式:k1=xxx&k2=yyy&k3=zzz
post 请求的参数存放在请求体中(可以用浏览器查看,存放于 form-data 中)
get 请求的参数直接 放在 url 后面,可以直接查看到
2:请求头
User-Agent:绝大多数网站需要设置 User-Agent;缺失的话可能会将你当作非法用户
在请求头内将自己伪装成浏览器,否则百度不会正常返回页面内容
Cookies:用来保存登录信息
Referer:访问当前链接的上一层链接(校验作用),用来判断请求来源
Host: 不一定需要
import requests response = requests.get/post(url, headers, cookie, params/data, stream) ''' url:要访问的路径 headers:请求时候的请求头,一般要携带 User-Agent, Referer 等参数 cookie:每次请求的 token 值,本质是包含在 headers 内,但为了方便,可以单独书写 params:get 请求所携带的参数,会自动往要访问的 url 后面进行拼接(会暴露在浏览器的地址栏中) data:post 请求所携带的参数 stream:访问视频资源较大时,设置参数为 True,可以一点一点获取资源,默认为 False ... '''
HTTP 默认的请求方式是 get 请求:
get 请求没有请求体,数据必须在1k之内,并且数据会暴露在浏览器的地址栏中
requests.post() 用法与 requests.get() 一致
GET 和 POST 的区别:
requests.post(url='xxxxxxxx', data={'xxx':'yyy'}) # 没有指定请求头, 默认的请求头:application/x-www-form-urlencoed # 如果我们自定义请求头是 application/json,并且用 data 传值, 则服务端取不到值 requests.post(url='xxx', data={'pwd':1}, headers={'content-type':'application/json'}) requests.post(url='xxx',json={'pwd':1}) # 默认的请求头:application/json
响应相关
response.encoding = # 默认编码为ISO-8859-1(如若请求来的内容有中文,需要指定一下编码格式) response.status_code # 相应状态码 response.text # 响应的内容文本 response.content # 响应的二进制数据:如图片,视频等资源 response.headers # 响应头信息 response.cookies # 相应回来的cookies response.cookies.get_dict() # 获取cookies信息,值为字典形式 response.cookies.items() response.url # 响应回来的url response.history # 发送响应到接收响应经过的所有url response.close() # 关闭响应 ...
响应状态
200:成功
301:跳转
403:权限不足
502:服务器错误
解析 json
import requests import json response=requests.get('http://httpbin.org/get') res1 = json.loads(response.text) # 太麻烦 res2 = response.json() # 直接获取 json 数据 print(res1 == res2) # 结果为 True
例子:爬取校花网视频
import requests import re import time import hashlib def get_page(url): print('GET %s' % url) try: response = requests.get(url) if response.status_code == 200: return response.content except Exception: pass def parse_index(res): obj = re.compile('class="items.*?<a href="(.*?)"', re.S) detail_urls = obj.findall(res.decode('gbk')) for detail_url in detail_urls: if not detail_url.startswith('http'): detail_url = 'http://www.xiaohuar.com' + detail_url yield detail_url def parse_detail(res): obj = re.compile('id="media".*?src="(.*?)"', re.S) res = obj.findall(res.decode('gbk')) if len(res) > 0: movie_url = res[0] return movie_url def save(movie_url): response = requests.get(movie_url, stream=False) if response.status_code == 200: m = hashlib.md5() m.update(('%s%s.mp4' % (movie_url, time.time())).encode('utf-8')) filename = m.hexdigest() with open(r'./movies/%s.mp4' % filename, 'wb') as f: f.write(response.content) f.flush() def main(): index_url = 'http://www.xiaohuar.com/list-3-{0}.html' for i in range(5): print('*' * 50, i) # 爬取主页面 index_page = get_page(index_url.format(i, )) # 解析主页面,拿到视频所在的地址列表 detail_urls = parse_index(index_page) # 循环爬取视频页 for detail_url in detail_urls: # 爬取视频页 detail_page = get_page(detail_url) # 拿到视频的url movie_url = parse_detail(detail_page) if movie_url: # 保存视频 save(movie_url) if __name__ == '__main__': main() # 并发爬取 from concurrent.futures import ThreadPoolExecutor import queue import requests import re import time import hashlib from threading import current_thread p = ThreadPoolExecutor(50) def get_page(url): print('%s GET %s' % (current_thread().getName(), url)) try: response = requests.get(url) if response.status_code == 200: return response.content except Exception as e: print(e) def parse_index(res): print('%s parse index ' % current_thread().getName()) res = res.result() obj = re.compile('class="items.*?<a href="(.*?)"', re.S) detail_urls = obj.findall(res.decode('gbk')) for detail_url in detail_urls: if not detail_url.startswith('http'): detail_url = 'http://www.xiaohuar.com' + detail_url p.submit(get_page, detail_url).add_done_callback(parse_detail) def parse_detail(res): print('%s parse detail ' % current_thread().getName()) res = res.result() obj = re.compile('id="media".*?src="(.*?)"', re.S) res = obj.findall(res.decode('gbk')) if len(res) > 0: movie_url = res[0] print('MOVIE_URL: ', movie_url) with open('db.txt', 'a') as f: f.write('%s ' % movie_url) # save(movie_url) p.submit(save, movie_url) print('%s下载任务已经提交' % movie_url) def save(movie_url): print('%s SAVE: %s' % (current_thread().getName(), movie_url)) try: response = requests.get(movie_url, stream=False) if response.status_code == 200: m = hashlib.md5() m.update(('%s%s.mp4' % (movie_url, time.time())).encode('utf-8')) filename = m.hexdigest() with open(r'./movies/%s.mp4' % filename, 'wb') as f: f.write(response.content) f.flush() except Exception as e: print(e) def main(): index_url = 'http://www.xiaohuar.com/list-3-{0}.html' for i in range(5): p.submit(get_page, index_url.format(i, )).add_done_callback(parse_index) if __name__ == '__main__': main()
高级用法
''' 很多网站都是 https,但是不用证书也可以访问,大多数情况都是可以携带也可以不携带证书 知乎百度等都是可带可不带 有硬性要求的,则必须带,比如对于定向的用户,拿到证书后才有权限访问某个特定网站 ''' # 如果是 ssl 请求,首先检验证书是否合法;不合法则报错,程序终止 import requests response = requests.get('https://www.12306.cn') # 改进1: import requests response = requests.get('https://www.12306.cn', verify=False) print(response.status_code) # 不验证证书,报警告,返回200 # 改进2: import requests from requests.packages import urllib3 urllib3.disable_warnings() # 关闭警告 respone=requests.get('https://www.12306.cn',verify=False) print(respone.status_code) # 200 # 改进3:加上证书 import requests respone=requests.get('https://www.12306.cn', cert=('/path/server.crt', '/path/key')) print(respone.status_code)
使用代理
官网链接: http://docs.python-requests.org/en/master/user/advanced/#proxies
# 代理设置:先发送请求给代理,然后由代理帮忙发送(封ip是常见的事情) import requests proxies={'http':'http://egon:123@localhost:9743', # 随机从代理池取出一个IP发送请求 # 带用户名密码的代理,@符号前是用户名与密码 'http':'http://localhost:9743', 'https':'https://localhost:9743'} respone=requests.get('https://www.12306.cn', proxies=proxies) print(respone.status_code) # 支持socks代理,安装:pip install requests[socks] import requests proxies = {'http': 'socks5://user:pass@host:port', 'https': 'socks5://user:pass@host:port'} respone=requests.get('https://www.12306.cn', proxies=proxies) print(respone.status_code)
超时设置
# 两种超时:float or tuple # timeout=0.1 代表接收数据的超时时间 # timeout=(0.1, 0.2) 0.1代表链接超时 0.2代表接收数据的超时时间 import requests respone=requests.get('https://www.baidu.com', timeout=0.0001)
异常处理
import requests from requests.exceptions import * # 可以查看requests.exceptions 获取异常类型 try: r = requests.get('http://www.baidu.com', timeout=0.00001) except ReadTimeout: print('===:') except ConnectionError: # 网络不通 print('-----') except Timeout: print('aaaaa') except RequestException: print('Error')
上传文件
import requests files = {'file': open('a.jpg', 'rb')} response = requests.post('http://httpbiin.org/post', files=files) print(respone.status_code)