1.searchAPI
ES支持两种基本方式检索
一个是通过REST request URL发送搜索参数(url+检索参数)
另一个是通过使用REST requestbody来发送他们(url+请求体)
1.1url+检索参数
GET bank/_search?q=*&sort=account_number:asc
q=*:查询所有
sort=account_number:asc:按照账号进行升序排列
查询结果--默认只返回10条(默认的分页查询)
{
"took": 57,
"timed_out": false, //是否超时
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": { //命中的记录
"total": { //总记录
"value": 548,
"relation": "eq"
},
"max_score": null,//最大得分
"hits": [
{
"_index": "bank",
"_type": "account",
"_id": "1",
"_score": null,
"_source": { //数据的实际信息
"account_number": 1,
"balance": 39225,
"firstname": "Amber",
"lastname": "Duke",
"age": 32,
"gender": "M",
"address": "880 Holmes Lane",
"employer": "Pyrami",
"email": "amberduke@pyrami.com",
"city": "Brogan",
"state": "IL"
},
"sort": [
1
]
},
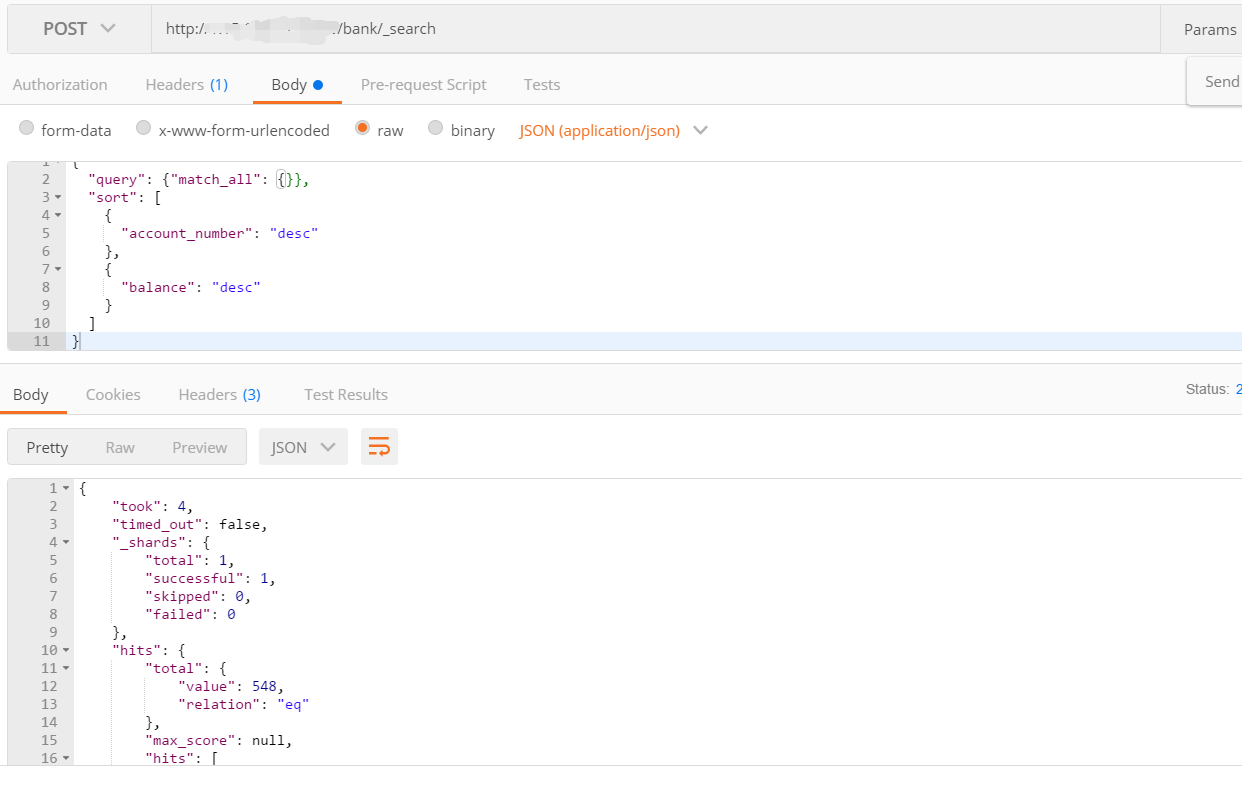
1.2url+请求体
- query:查询条件
- search:排序条件
GET bank/_search
GET bank/_search
{
"query": {"match_all": {}}, //匹配所有
"sort": [
{
"account_number": "desc"//按照账号升序
},
{
"balance": "desc" //按照越余额降序
}
]
}
- 注意:
HTTP客户端工具(POSTMAN),get请求不能携带请求体,我们变为post也是一样的我们POST一个JSON风格的查询请求到_search API。
需要了解,一旦搜索结果被返回,ElasticSearch就完成了这次请求,并且不会维护任何服务端的资源或者结果的cursor(游标)
2.query DSL语法基本使用
2.1match_all查询所有
GET bank/_search
{
"query":{
"match_all":{}
}
}
语法结构
{
QUERY_NAME:{
FIELD NAME:{
ARGUMENI:VALUE,
ARGUMENT:VALUE...
}
}
}
例:按照 balance 降序查询:
GET bank/_search
{
"query": {
"match_all": {}
},
"sort": [
{
"balance": {
"order": "desc"
}
}
]
}
简单表达形式
"balance": {
"order": "desc"
}
可以简写为:
"balance": "desc"
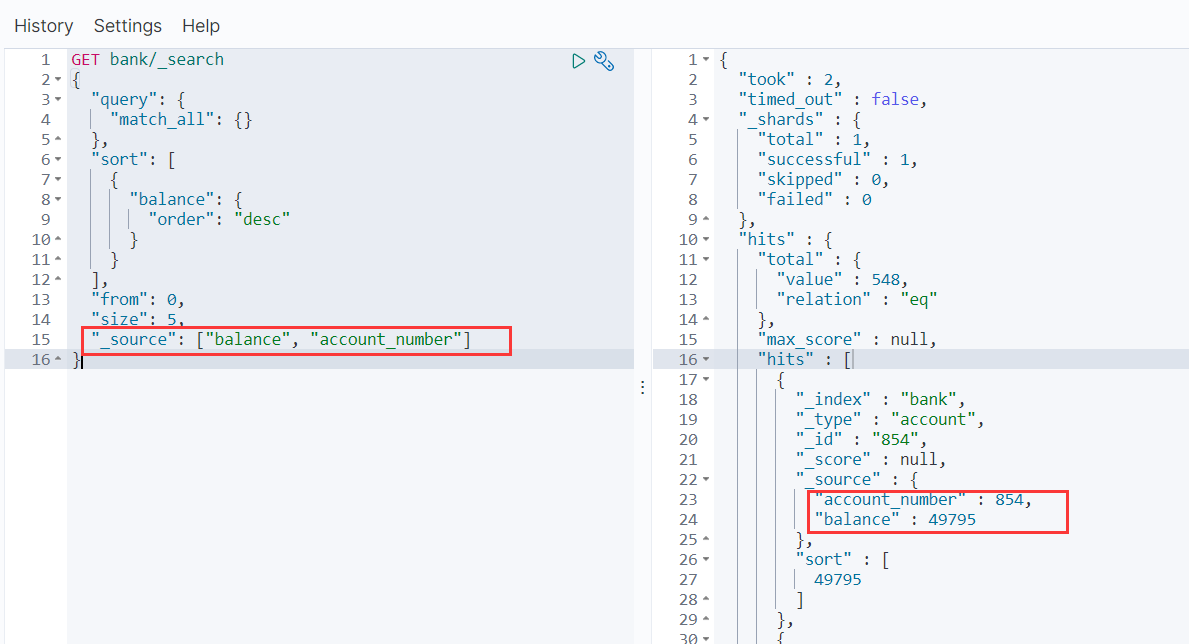
2.2from,size分页查询
GET bank/_search
{
"query": {
"match_all": {}
},
"sort": [
{
"balance": {
"order": "desc"
}
}
],
"from": 0,
"size": 5,
"_source": ["balance", "account_number"]
}
2.3_source只返回部分字段
2.4match全文检索
GET bank/_search
//查询 account_number 是 20 的所有结果:
{
"query": {
"match": {
"account_number": 20
}
}
}
- 进行模糊查询(全文检索)
按照评分进行排序,会对检索条件进行分词匹配
GET bank/_search
//查询所有 address 中包含 Kings 的数据
{
"query": {
"match": {
"address": "Kings"
}
}
}
//最终查询出address中包含mill或者road或者mill road的所有记录,并给出相关性评分
2.5match_phrase短语匹配
将要匹配的值当成一个整体单词(不分词)进行索引
GET bank/_search
//查出address中包含millroad的所有记录,并给出相关性评分
GET bank/_search
{
"query": {
"match_phrase": {
"address": "Mill Lane"
}
}
}
2.6multi_match多字段匹配
进行了分词
查询出指定字段包含mill的
GET bank/_search
//state字段或者address字段包含mill的情况
{
"query": {
"multi_match": {
"query": "mill",
"fields": ["address", "email"]
}
}
}
2.7bool复合查询
bool用来做复合查询
复合查询可以合并任何其他查询语句,包括复合语句,了解这一点是很重要的,这意味着。复合语句之间可以相互嵌套,可以表达非常复杂的逻辑
- must:必须有
- must_not:除了
- should:可有可无
GET bank/_search
{
"query": {
"bool": {
"must": [ //必须有
{
"match": {
"gender": "M"
}
},
{
"match": {
"address": "mill"
}
}
],
"must_not": [ //除了
{
"match": {
"age": "28"
}
}
],
"should": [ //可有可无
{
"match": {
"lastname": "Hines"
}
}
]
}
}
}
2.8filter结果过滤
布尔查询中的每个must、should和must not元素都称为查询子句。文档满足每个 must 或 should 子句中的标准的程度有助于文档的相关性得分。分数越高,文档就越符合您的搜索条件。默认情况下,Elasticsearch返回按这些相关性得分排序的文档。
must_not 子句中的条件被视为 filter。它影响文档是否包含在结果中,filter、must_not 都不影响文档的得分。
还可以显式指定任意过滤器,以包含或排除基于结构化数据的文档。
- 例如,查找年龄在 10 - 30 的数据
GET /bank/_search
{
"query": {
"bool": {
"must": [
{
"range": {
"age": {
"gte": 10,
"lte": 30
}
}
}
]
}
}
}
返回结果:
{
"took" : 10,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 498,
"relation" : "eq"
},
"max_score" : 1.0, //注意这里,使用must贡献了相关性得分
"hits" : [
{
"_index" : "bank",
"_type" : "account",
"_id" : "13",
"_score" : 1.0, //注意这里,使用must贡献了相关性得分
"_source" : {
"account_number" : 13,
"balance" : 32838,
"firstname" : "Nanette",
"lastname" : "Bates",
"age" : 28,
"gender" : "F",
- 我们也可以使用Filter:
GET /bank/_search
{
"query": {
"bool": {
"filter": [
{
"range": {
"age": {
"gte": 10,
"lte": 30
}
}
}
]
}
}
}
返回的结果是:
{
"took" : 2,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 498,
"relation" : "eq"
},
"max_score" : 0.0, //注意这里没有贡献相关性得分
"hits" : [
{
"_index" : "bank",
"_type" : "account",
"_id" : "13",
"_score" : 0.0, //注意这里没有贡献相关性得分
"_source" : {
"account_number" : 13,
"balance" : 32838,
"firstname" : "Nanette",
"lastname" : "Bates",
"age" : 28,
"gender" : "F",
"address" : "789 Madison Street",
"employer" : "Quility",
"email" : "nanettebates@quility.com",
"city" : "Nogal",
"state" : "VA"
2.9term查询
规定全文检索用match
非全文检索用term
用于找精确字段
返回在提供的字段中包含确切信息的文档内容。
您可以使用精确的值(例如价格,产品ID或用户名)利用 Term 查询查找文档。
GET /bank/_search
{
"query": {
"term": {
"age": 33
}
}
}
注意:
避免term对text字段使用查询。
因为es在保存text字段的时候存在数据分析的问题
默认情况下,Elasticsearch更改text字段的值作为analysis的一部分。这会使查找text字段值的精确匹配变得困难。
要搜索text字段值,请改用match查询。
{
"query":{
"match":{
"address":"789 Madison Street"
}
}
}
如何文本精确查询?
- 查询地址值必须是 435 Furman Street 的(精确匹配 keyword):
GET /bank/_search
{
"query": {
"match": {
"address.keyword": "435 Furman Street" //这个的搜索结果在改为435 Furman时不会展示
}
}
}
使用match-parse
GET /bank/_search
{
"query": {
"match_phrase": {
"address": "435 Furman Street" //这个的搜索结果在改为435 Furman时依旧会展示
}
}
}
- match_parse和keyword的区别
match_parse:只要包含"address.keyword": "435 Furman Street"即可
keyword:address要完全等于"435 Furman Street"
2.10aggregations(执行聚合)
聚合提供了从数据中分组和提取数据的能力。最简单的聚合方法大致等于 SQL GROUP BY 和 SQL 聚合函数。在 Elasticsearch 中,您有执行索返回 hits(命中结果),并且同时返回聚合结果,把一个响应中的所有hits(命中结果)隔开的能力。这是非常强大且有效的,您可以执行查询和多个聚合,并且在一次使用得到各自的(任何一个的)返回结果,使用一次简洁和简化的AP来避免网络往返。
搜索 address中包含mill的所有人的年龄分布以及平均年龄,但不显示这些人的详情。
GET /bank/_search
{
"query": {
"match": {
"address": "mill"
}
},
"aggs": { //获取聚合
"ageAgg": { //自定义的聚合名
"terms": { //获取结果的不同数据个数
"field": "age", //获取字段是age
"size": 10 //可能有很多很多可能,只获取前10种
}
},
"ageAvg":{ //自定义的聚合名
"avg": { //求平均值
"field": "age" //获取字段是age
}
}
}
}
结果:
{
"took" : 27,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 4,
"relation" : "eq"
},
"max_score" : 5.4032025,
"hits" : [
{
"_index" : "bank",
"_type" : "account",
"_id" : "970",
"_score" : 5.4032025,
"_source" : {
"account_number" : 970,
"balance" : 19648,
"firstname" : "Forbes",
"lastname" : "Wallace",
"age" : 28,
"gender" : "M",
"address" : "990 Mill Road",
"employer" : "Pheast",
"email" : "forbeswallace@pheast.com",
"city" : "Lopezo",
"state" : "AK"
}
},
{
"_index" : "bank",
"_type" : "account",
"_id" : "136",
"_score" : 5.4032025,
"_source" : {
"account_number" : 136,
"balance" : 45801,
"firstname" : "Winnie",
"lastname" : "Holland",
"age" : 38,
"gender" : "M",
"address" : "198 Mill Lane",
"employer" : "Neteria",
"email" : "winnieholland@neteria.com",
"city" : "Urie",
"state" : "IL"
}
},
{
"_index" : "bank",
"_type" : "account",
"_id" : "345",
"_score" : 5.4032025,
"_source" : {
"account_number" : 345,
"balance" : 9812,
"firstname" : "Parker",
"lastname" : "Hines",
"age" : 38,
"gender" : "M",
"address" : "715 Mill Avenue",
"employer" : "Baluba",
"email" : "parkerhines@baluba.com",
"city" : "Blackgum",
"state" : "KY"
}
},
{
"_index" : "bank",
"_type" : "account",
"_id" : "472",
"_score" : 5.4032025,
"_source" : {
"account_number" : 472,
"balance" : 25571,
"firstname" : "Lee",
"lastname" : "Long",
"age" : 32,
"gender" : "F",
"address" : "288 Mill Street",
"employer" : "Comverges",
"email" : "leelong@comverges.com",
"city" : "Movico",
"state" : "MT"
}
}
]
},
"aggregations" : {
"ageAgg" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [
{
"key" : 38,
"doc_count" : 2
},
{
"key" : 28,
"doc_count" : 1
},
{
"key" : 32,
"doc_count" : 1
}
]
},
"ageAvg" : {
"value" : 34.0
}
}
}
如果我们不希望返回数据,只需要分析结果,可以设置 size 为 0
GET /bank/_search
{
"query": {~},
"aggs": {~},
"size": 0
}
按照年龄聚合,并且请求这些年龄段的这些人的平均薪资
GET /bank/_search
{
"query": {
"match_all": {}
},
"aggs": {
"ageAgg": {
"terms": {
"field": "age",
"size": 100
},
"aggs": { //子聚合
"ageAvg": {
"avg": {
"field": "balance"
}
}
}
}
},
"size": 0
}
结果
{
"took" : 16,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1000,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
},
"aggregations" : {
"ageAgg" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [
{
"key" : 31,
"doc_count" : 61,
"ageAvg" : {
"value" : 28312.918032786885
}
},
{
"key" : 39,
"doc_count" : 60,
"ageAvg" : {
"value" : 25269.583333333332
}
},
{
"key" : 26,
"doc_count" : 59,
"ageAvg" : {
"value" : 23194.813559322032
}
},
...
案例3
查询出所有年龄分布,并且这些 年龄段中 性别为 M 的平均薪资 和 性别为 F 的平均薪资 以及 这个年龄段的总体平均薪资
GET /bank/_search
{
"query": {
"match_all": {}
},
"aggs": {
"ageAgg": {
"terms": {
"field": "age",
"size": 100
},
"aggs": {
"genderAgg":{
"terms": {
"field": "gender.keyword",
"size": 10
},
"aggs": {
"balanceAvg": {
"avg": {
"field": "balance"
}
}
}
},
"ageBlanace":{
"avg": {
"field": "balance"
}
}
}
}
},
"size": 0
}
返回结果:
{
"took" : 16,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1000,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
},
"aggregations" : {
"ageAgg" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [
{
"key" : 31,
"doc_count" : 61,
"genderAgg" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [
{
"key" : "M",
"doc_count" : 35,
"balanceAvg" : {
"value" : 29565.628571428573
}
},
{
"key" : "F",
"doc_count" : 26,
"balanceAvg" : {
"value" : 26626.576923076922
}
}
]
},
"ageBlanace" : {
"value" : 28312.918032786885
}
},
{
"key" : 39,
"doc_count" : 60,
"genderAgg" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [
{
"key" : "F",
"doc_count" : 38,
"balanceAvg" : {
"value" : 26348.684210526317
}
},
{
"key" : "M",
"doc_count" : 22,
"balanceAvg" : {
"value" : 23405.68181818182
}
}
]
},
"ageBlanace" : {
"value" : 25269.583333333332
}
},
{
"key" : 26,
"doc_count" : 59,
"genderAgg" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [
{
"key" : "M",
"doc_count" : 32,
"balanceAvg" : {
"value" : 25094.78125
}
},
{
"key" : "F",
"doc_count" : 27,
"balanceAvg" : {
"value" : 20943.0
}
}
]
},
"ageBlanace" : {
"value" : 23194.813559322032
}
},
...