数据的高级操作 - 查询数据
- 基本语法:
select + 字段列表/* + from + 表名 + [where 条件]; - 完整语法:
select + [select 选项] + 字段列表[字段别名]/* + from + 数据源 + [where 条件] + [1] + [2] + [3];[1] = [group by 子句][2] = [order by 子句][3] = [limit 子句]
SELECT 选项
select选项,即select对查出来的结果的处理方式。
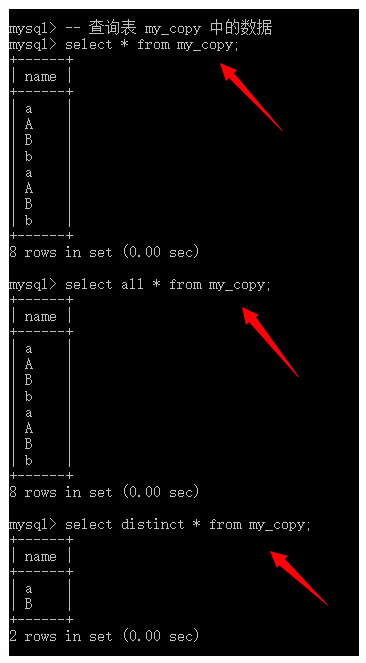
all:默认,保留所有的查询结果;distinct:去重,将查出来的结果中所有字段都相同的记录去除。
执行如下 SQL 语句,进行测试:
-- 查询表 my_copy 中的数据
select * from my_copy;
select all * from my_copy;
select distinct * from my_copy;
字段别名
字段别名,即当数据进行查询的时候,有时候字段的名字并不一定满足需求(特别地,在多表查询的时候,很可能会有同名字段),这时就需要对字段进行重命名、取别名。
- 基本语法:
字段名 + [as] + 别名;
执行如下 SQL 语句,进行测试:
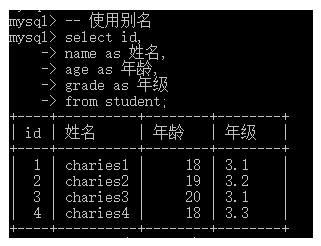
-- 使用别名
select id,
name as 姓名,
age as 年龄,
grade as 年级
from student;
数据源
数据源,即数据的来源,关系型数据库的数据源都是数据表,本质上只要保证数据类似二维表,最终就可以作为数据源。
数据源分为 3 种,分别为:单表数据源,多表数据源和查询语句。
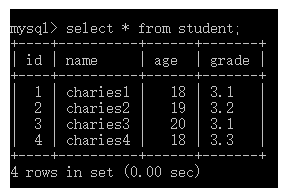
第 1 种:单表数据源
- 基本语法:
select * from + 表名;
第 2 种:多表数据源
- 基本语法:
select * from + 表名1,表名2...;
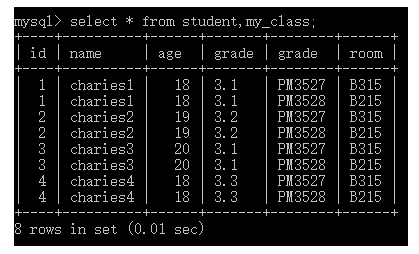
如上图所示,使用多表数据源时默认从一张表中取出一条记录去另外一张表中匹配所有记录,而且全部保留,比较浪费资源,应该尽量避免。
第 3 种:查询语句(子查询)
- 基本语法:
select * from + (select * from + 表名) + [as] + 别名;
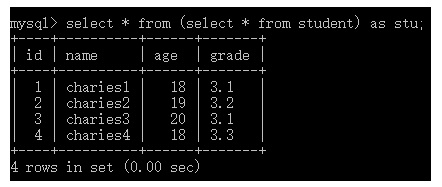
如上图所示,数据的来源是一条查询语句,而查询语句的结果是一张二维表。
where子句
where字句:用来判断数据和筛选数据,返回的结果为0或者1,其中0代表false,1代表true,where是唯一一个直接从磁盘获取数据的时候就开始判断的条件,从磁盘中读取一条数据,就开始进行where判断,如果判断的结果为真,则保持,反之,不保存。
判断条件:
- 比较运算符:
>、<、>=、<=、<>、=、like、between and、in和not in; - 逻辑运算符:
&&、||、和!.
执行如下 SQL 语句,进行测试:
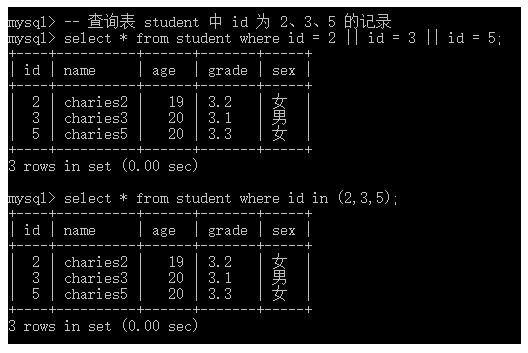
-- 查询表 student 中 id 为 2、3、5 的记录
select * from student where id = 2 || id = 3 || id = 5;
select * from student where id in (2,3,5);
-- 查询表 student 中 id 在 2 和 5 之间的记录
select * from student where id between 2 and 5;

如上图所示,咱们会发现:在使用between and的时候,其选择的区间为闭区间,即包含端点值。此外,and前面的数值必须大于等于and后面的数值,否则会出现空判断,例如:

group by子句
group by子句:根据表中的某个字段进行分组,即将含有相同字段值的记录放在一组,不同的放在不同组。
- 基本语法:
group by + 字段名;
执行如下 SQL 语句,进行测试:
-- 将表 student 中的数据按字段 sex 进行分组
select * from student group by sex;

观察上图,咱们会发现:表student在分组过后,数据“丢失”!实际上并非如此,产生这样现象原因为:group by分组的目的是为了(按分组字段)统计数据,并不是为了单纯的进行分组而分组。为了方便统计数据,SQL 提供了一系列的统计函数,例如:
cout():统计分组后,每组的总记录数;max():统计每组中的最大值;min():统计每组中的最小值;avg():统计每组中的平均值;sum():统计每组中的数据总和。
执行如下 SQL 语句,进行测试:
-- 将表 student 中的数据按字段 sex 进行分组,并进行统计
select sex,count(*),max(age),min(age),avg(age),sum(age) from student group by sex;
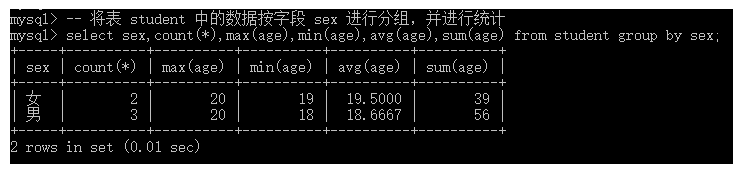
其中,count()函数里面可以使用两种参数,分别为:*表示统计组内全部记录的数量;字段名表示统计对应字段的非null(如果某条记录中该字段的值为null,则不统计)记录的总数。此外,使用group by进行分组之后,展示的记录会根据分组的字段值进行排序,默认为升序。当然,也可以人为的设置升序和降序。
- 基本语法:
group by + 字段名 + [asc/desc];
执行如下 SQL 语句,进行测试:
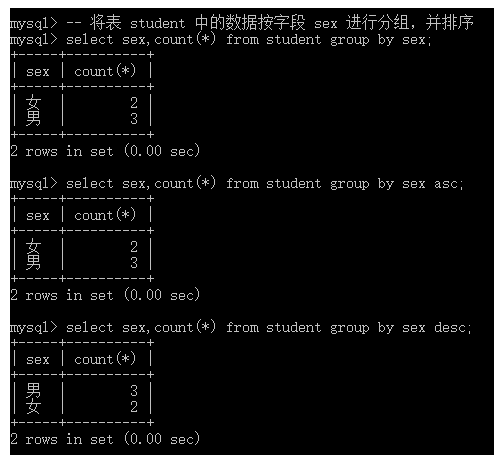
-- 将表 student 中的数据按字段 sex 进行分组,并排序
select sex,count(*) from student group by sex;
select sex,count(*) from student group by sex asc;
select sex,count(*) from student group by sex desc;
通过观察上面数个分组示例,细心的同学会发现:咱们在之前的示例中,都是用单字段进行分组。实际上,咱们也可以使用多字段分组,即:先根据一个字段进行分组,然后对分组后的结果再次按照其他字段(前提是分组后的结果中包含此字段)进行分组。
执行如下 SQL 语句,进行测试:
-- 将表 student 中的数据先按字段 grade 进行分组,再按字段 sex 进行分组
select *,count(*) from student group by grade,sex;

在这里,函数group_concat(字段名)可以对分组的结果中的某个字段值进行字符串连接,即保留该组某个字段的所有值。例如:
-- 将表 student 中的数据按字段 sex进行分组,并保留字段 name 的值
select sex,age,count(*),group_concat(name) from student group by sex;

此外,简单介绍回溯统计的概念:利用with rollup关键字(书写在 SQL 语句末尾),可以在每次分组过后,根据当前分组的字段进行统计,并向上一级分组进行汇报。例如:
-- 将表 student 中的数据按字段 sex进行分组,并进行回溯统计
select sex,count(*) from student group by sex with rollup;

观察上图,咱们会发现:在进行回溯统计的时候,会将分组字段置空。
having子句
having字句:与where子句一样,都是进行条件判断的,但是where是针对磁盘数据进行判断,数据进入内存之后,会进行分组操作,分组结果就需要having来处理。思考可知,having能做where能做的几乎所有事情,但是where却不能做having能做的很多事情。
第 1 点:分组统计的结果或者说统计函数只有having能够使用
执行如下 SQL 语句,进行测试:
-- 求出表 student 中所有班级人数大于等于 2 的班级
select grade,count(*) from student group by grade having count(*) >= 2;
select grade,count(*) from student where count(*) >= 2 group by grade;

如上图所示,显然having子句可以对统计函数得到的结果进行筛选,但是where却不能。
第 2 点:having能够使用字段别名,where则不能
执行如下 SQL 语句,进行测试:
-- 求出表 student 中所有班级人数大于等于 2 的班级
select grade,count(*) as total from student group by grade having total >= 2;
select grade,count(*) as total from student where total >= 2 group by grade;

如上图所示,显然咱们的结论得到了验证。究其原因,where是从磁盘读取数据,而磁盘中数据的名字只能是字段名,别名是数据(字段)进入到内存后才产生的。值得注意的是,在上述 SQL 语句中咱们使用了字段别名,这在无意中就优化了 SQL 并提高了效率,因为少了一次统计函数的计算。
order by子句
order by子句:根据某个字段进行升序或者降序排序,依赖校对集。
- 基本语法:
order by + [asc/desc];
其中,asc为升序,为默认值;desc为降序。
执行如下 SQL 语句,进行测试:
-- 将表 student 中的数据按年龄 age 进行排序
select * from student order by age;

此外,咱们可以进行「多字段排序」,即先根据某个字段进行排序,然后在排序后的结果中,再根据某个字段进行排序。
执行如下 SQL 语句,进行测试:
-- 将表 student 中的数据先按年龄 age 升序排序,再按班级 grade 降序排序
select * from student order by age,grade desc;

limit子句
limit子句:是一种限制结果的语句,通常来限制结果的数量。
- 基本语法:
limit + [offset] + length;
其中,offset为起始值;length为长度。
第 1 种:只用来限制长度(数据量)
执行如下 SQL 语句,进行测试:
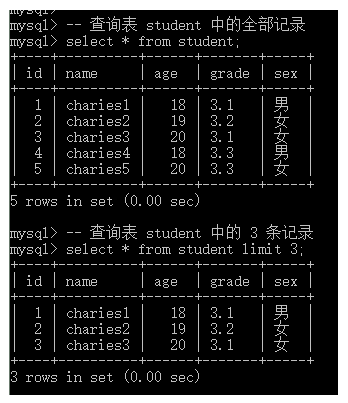
-- 查询表 student 中的全部记录
select * from student;
-- 查询表 student 中的 3 条记录
select * from student limit 3;
第 2 种:限制起始值,限制长度(数据量)
执行如下 SQL 语句,进行测试:
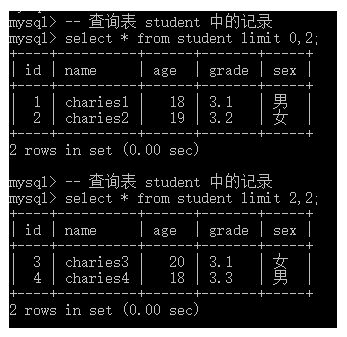
-- 查询表 student 中的记录
select * from student limit 0,2;
-- 查询表 student 中的记录
select * from student limit 2,2;
第 3 种:主要用来实现数据的分页,目的是为用户节省时间,提高服务器的响应效率,减少资源的浪费
大致设计:
- 对于用户来讲,可以通过点击页码按钮,如
1、2、3等来进行选择; - 对于服务器来讲,可以根据用户选择的页码来获取不同的数据。
其中,
length:表示每页的数据量,基本不变;offset:表示每页的起始值,公式为offset=(页码-1)*length.
提示:符号[]括起来的内容,表示可选项;符号+,则表示连接的意思。