这篇文章起源于项目中一个特殊的需求。由于目前的开发方式是前后端分离的,基本上是通过接口提供各个服务。
而前两天前端fe在开发中遇到了一些问题:他们在处理字符串类型的时间时会出现精度丢失的情况,所以希望后台是以时间戳的形式返回给前端。而与此同时后台的设计是这个样子的:所有的时间在数据库中均保存为varchar类型,在序列化的时候也是按String字符串去处理的。
这样一来就需要一些解决方案:
1. 所有数据库的时间字段都用timestamp替换,这个是最简单确实实现代价最高的一种方案,由于数据库表太多并且涉及多处的耦合,此方案不可行。
2. 通过fastjson序列化层去转换类型:首先想到的是能不能通过fastjson自己提供的注解方式实现,后调研之后发现,目前使用的版本并不支持;然后想到可以通过fastjson提供的序列化器重载实现String类型的拦截并做处理。但是这种方案会把所有String的字段都执行这段逻辑,并且还要通过固定的format确定哪些是日期,这里非常影响性能;最后决定添加自定义注解,在需要这种类型转换的字段上加上自定义的@StringToDate注解,然后在序列化执行的入口,给所有加了此注解的类提供继承并实现扩展的序列化器,完成自定义的序列化过程。
下面就详细说一下这个过程,一是对fastjson源码做一个解析和说明,二也是对自己的工作做一个总结。
1. 如何实现扩展
首先来看一下自定义的注解,很简单:
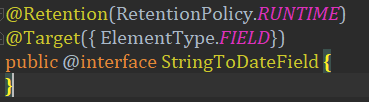
关于这个注解的用法和定义,我就不细说了,Retention指定了他的作用域,而Target说明该注解用于field字段上。
然后既然是要扩展fastjson的功能,我们就来看一下fastjson的入口,首先是WebMvcConfigurerAdapter这个类,我们可以通过继承和重写该类的方法实现MVC的配置,比如拦截器、资源处理器等。我们重写的方法是configureMessageConverters,这个是用来配置信息转化的converter:
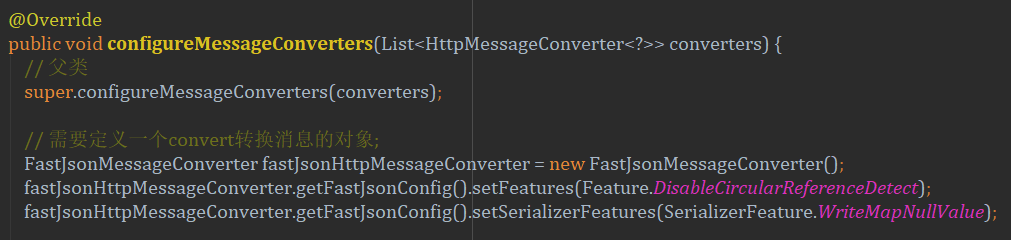
可以看到,我们通过这个方法,调用了父类,同时加入了fastJson的converter,然后我们来看看FastJsonMessageConverter这个我们自己写的类:
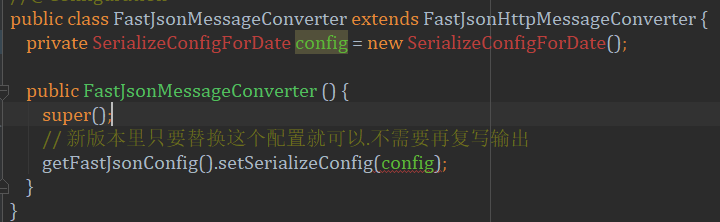
只是很简单的通过继承实现了自定义config的注入,然后再来看看我们自己写的这个config:
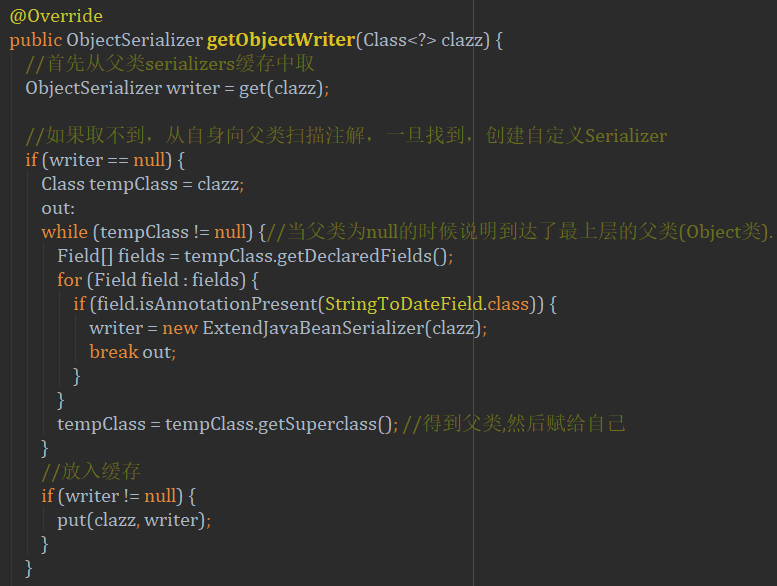
这里是最关键的地方,SerializeConfig提供一个入口方法getObjectWriter可以用来对传入的类型进行处理,并为相应的类型设置对应的Serializer序列化器。这里可以看到,我通过判断传入class的注解判断是不是要处理的类型,如果是需要转换的,就用我们写的ExtendJavaBeanSerializer去处理他。(同时可以看到,这里我做了缓存处理,每次的class在处理之后都会通过父类的put方法放入缓存,这样可以大大减少遍历和判断的次数,提高处理性能)
那现在就要看看这个ExtendJavaBeanSerializer做了什么:
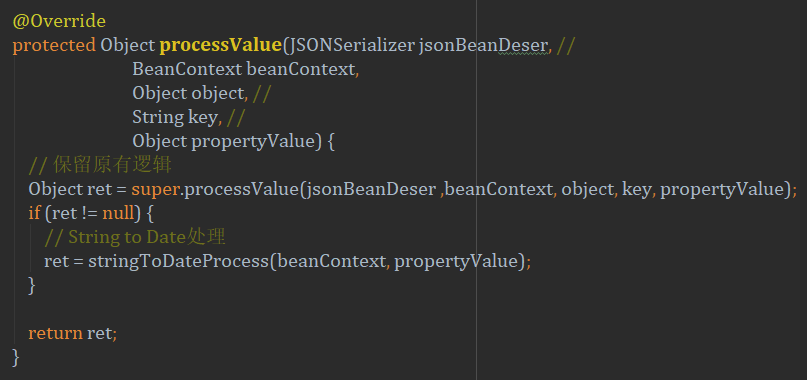
这里我们继承了JavaBeanSerializer并重写了processValue方法。这里要说个点:因为每个序列化器都有write方法,所以最开始直观的想法是重写这个方法实现扩展,但是由于write方法很长很长(有250多行),作为切入点非常不方便,然后仔细观察源码,发现其中有这么一句:
propertyValue = this.processValue(serializer, fieldSerializer.fieldContext, object, fieldInfoName,propertyValue);
这句看上去好像就是给我们处理value值的,再点进去一看,processValue居然是个protected方法。那正如意!这就是给我们做扩展的入口,最后便重写了这个方法,并在其中实现了StringToDate的转换逻辑。
2. fastjson源码思想
其实呢,到这里应该会有一个疑问,fastjson提供的预设序列化器有很多很多,看源码发现一个包下面满满都是。那么我们是如何确定要继承这个JavaBeanSerializer的呢?这就需要看fastjson的源码了,看看它究竟是怎么分配和执行这个序列化器的:
首先是SerializeConfig这个类:这个类的config中预设了大量的类型和序列化器的对应关系,他原有的getObjectWriter入口是这样的逻辑: 先判断传入类是不是config中有的,如果有直接给对应的Serializer,如果没有,又会有一堆特殊类(比如集合,异常,编码等类)的判断,而他们也有对应的Serializer。
那如果还没有(比如自己的javabean),在最后会执行一个:createJavaBeanSerializer(clazz) 的方法,在这个方法中,默认会执行createASMSerializer方法,asm查阅资料会发现是一个老外写的字节码序列化器,是序列化最底层的一个工具,很多开源序列化包都是对这个进行封装实现的。那我们要继承JavaBeanSerializer这个类并使用自己的,就说明我们不想让他执行createASMSerializer这个方法,为什么呢?
因为在createASMSerializer里面的逻辑是:当序列化对象 > 256个时,会创建可继承的JavaBeanSerializer去处理,如果<256,则不会给他任何序列化器,而是直接通过反射方式在内存中(就是生生拼出了一个序列化过程)实现对这个对象的处理。关键代码如下:
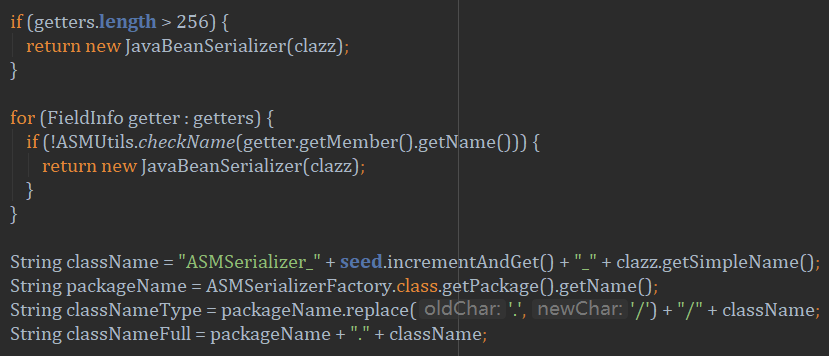
当然,下面还有很长很长的内存字节码操作的逻辑,我就不贴出了。我想这可能也是fastjson快的一个原因吧。
写到这里,关于对fastjson的扩展就差不多说完了,其实fastjson的源码中其他类中也都有自己独特的优化方式,有些还是挺有意思的。另外呢,我惊奇地发现,fastjson的作者和durid居然是一个人,这个来自阿里的wenshao还真的厉害啊。作为一个学习者,只是希望有朝一日也能写出这么漂亮的代码吧,希望自己可以不断努力!