1.运行过程
WishList(Domain)-->WishListMapper(DAO)-->WishListService(Service)-->WishListController(Controller)
以上是从原型定义到mybatis的Mapper文件定义,再到提供服务,然后提供接口和结果的过程。
2.@Param参数
在定义mybatis的mapper文件或者定义基于注解的sql语句时候,使用@Param注解,如下:
@Select("SELECT id, user_id, item_id, add_price, add_time, created, updated FROM" +"user_collection_info WHERE user_id= #{userId} AND item_id= #{itemId, jdbcType=BIGINT}")
List<WishList> getWishListItemByItemId(@Param("userId") long userId, @Param("itemId") long itemId);
@Param后的字段和#{}之中的内容对应,select选择的是数据库之中的字段,后面的#{itemId}可以自由命名,只要在@Param之中对应起来就行。
3.IDEA的几个缩写
psvm=补全main函数
fori =for循环
sout =System.out.println();
4.接口,参数,请求等之间的关系
接口的请求:接口分为一般接口和分布式接口(如Dubbo接口),一般的随便调用,Dubbo接口主要是为了在分布式环境下提供服务,可以在不同的机器之间调用(RPC);返回的数据格式:调用了接口之后,返回的数据一般是json格式的,但是其中的具体内容,还需要和前端商讨,返回的数据到底是什么格式;参数的传递:在Http的Get请求下,所需要的数据可以通过URL上通过http://localhost:8080/wishlist/getMarkList?userId=2&pageSize=10&pageStart=0 ?参数1=值1&参数2=值2&...这种方式为参数赋值,我们可以通过url给controller中调用的方法的参数赋值,此时controller方法参数的名字和url之中的参数的名字要相同,否则取不到值。而对于Http的Post请求,我们是没法看到对应的页面的,传递参数的方式是一样的,需要借助工具实现,如postman来发送post请求。一个“悖论”是,我们需要的参数通过url传递,但是应该也有其他方式传递,比如我提交了注册按钮,然后,一般而言不会跳转到一个新的页面,应该是直接取到后台返回的结果,然后在本页刷新即可,也就是说,url在取得参数数据之后(这种情况是Post请求的情况,而Get请求是相对应起来的),这种情况是针对于Post请求的,可以把Post请求理解为在后端进行,不需要对应的页面即可。字段的对应关系:还有在contorller, service, mapper, url和数据库之中字段的对应关系,mappr和数据库对应,url和controller对应,其他地方没有明确的要求,定义统一和方便自己查找即可,对于时间的处理,一般不写在函数的参数请求之中,而直接在SQL中操作。
5.微服务
不能我去查找别人的,我没有权限的数据库字段,不是我的模块,对我而言,我是看不到的,我需要的数据我无法直接获取的时候,我需要调用别人提供给我的接口,一般而言,我只需要在这些数据之中找到我要的部分,然后将其组装,就可以了。简言之:不是我的,我无法直接操作底层(数据库),只能通过调用别人的提供的接口,来获取我需要的内容。
6.几个常见的术语
| 关键词 | 名称 | 术语 |
|---|---|---|
| api接口 | Service接口 | service |
| Model 接口 | model | |
| 实现类 | Mapper 接口 | dao |
| Model POJO类 | domain/model | |
| Service/Serviceimpl Service实现类 | service | |
| Controller 调用类 | controller |
7.异常处理和日志
异常处理一般在service层处理,需要处理的时候处理,返回相应的result(一般是Json格式),日志的话一般是使用logback,常量常数的话一般不是直接使用1,0这种表示,而是将其定义为常量,这样更有含义,明确。
8.数据来源
我自己管理的数据库表,只有一部分我需要的数据,但是其他的部分在别人的数据库表之中,我怎么拿到全部我想要的数据呢?一般的思路是这样的:在分布式的系统和微服务的架构下,我无法直接操作别人的数据库,无法直接通过操作别人数据库的方式来获得数据,所以只能通过别人提供的服务接口来获得数据,然后通过和我自己的一部分数据,通过一定的条件查询,拼装组合出我想要的数据。一般而言,在mybatis之中,需要定义好一个组装成的数据的Model,然后直接将数据填充到Model的对象之中去。
9.IDEA调试快捷键
| 键 | 模式 | 作用 |
|---|---|---|
| F7 | Debug | 进入断点方法之中 |
| F8 | Debug | 不进入断点,越过断点直接给出结果 |
| F9 | Debug | 恢复程序运行 |
| Alt + F8 | Debug | 弹出可输入表达式的计算框 |
| Ctrl + F8 | Debug / Common | 设置/清除断点 |
| Shift + F7 | Debug | 智能步入,会让你选择一个进入的方法 |
| Shift + F8 | Debug | 跳出,恢复程序运行,=F9 |
| Ctrl + Shift + F8 | Debug | 设置断点的进入条件 |
| Alt + Shift + F7 | Debug | 进入嵌套的方法之中 |
10.IDEA的Debug使用
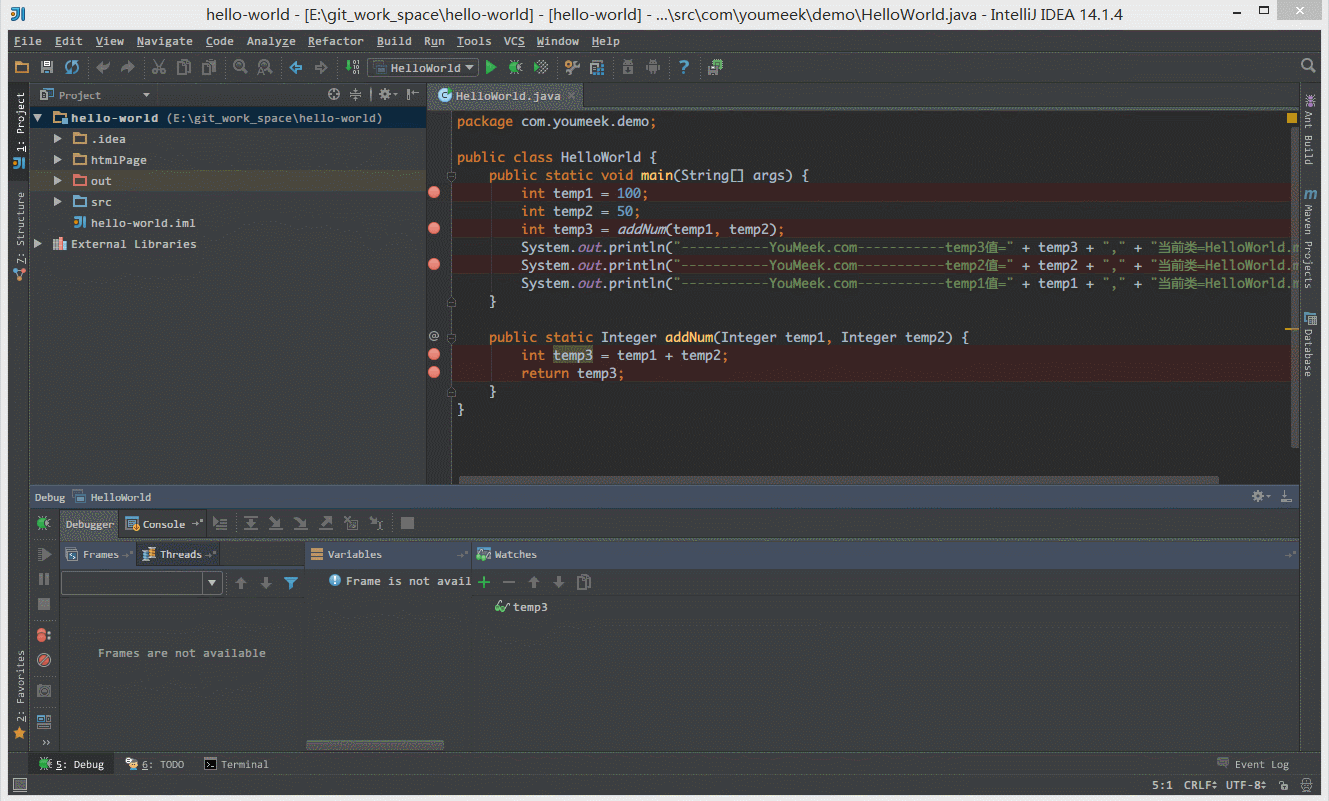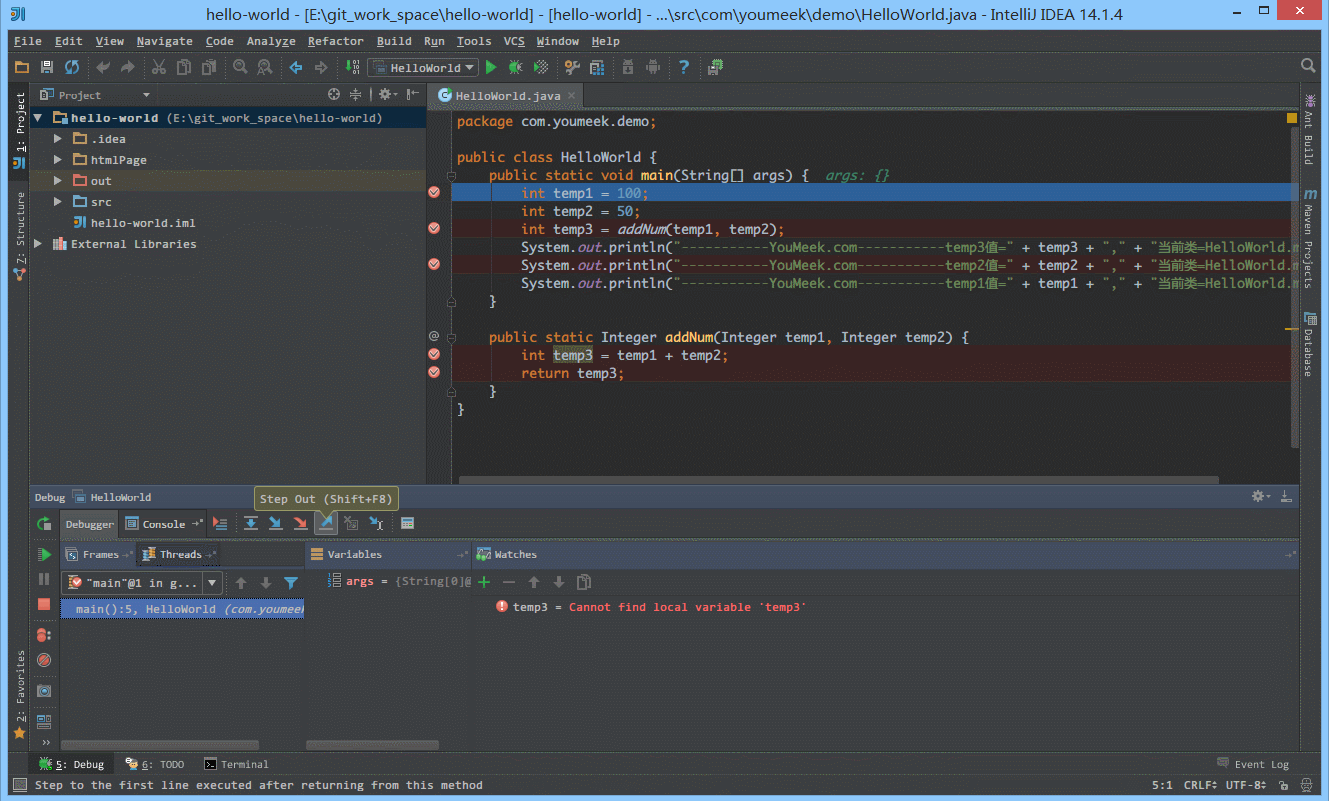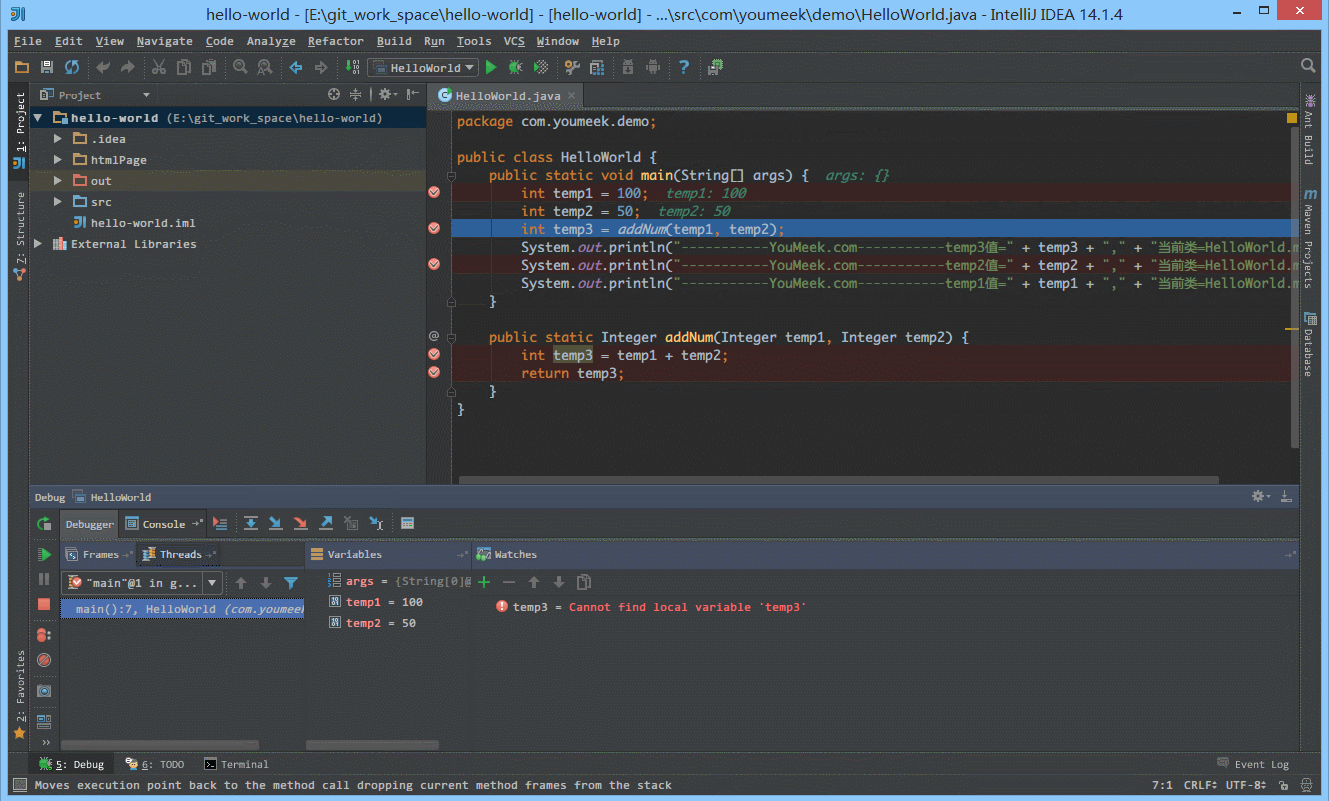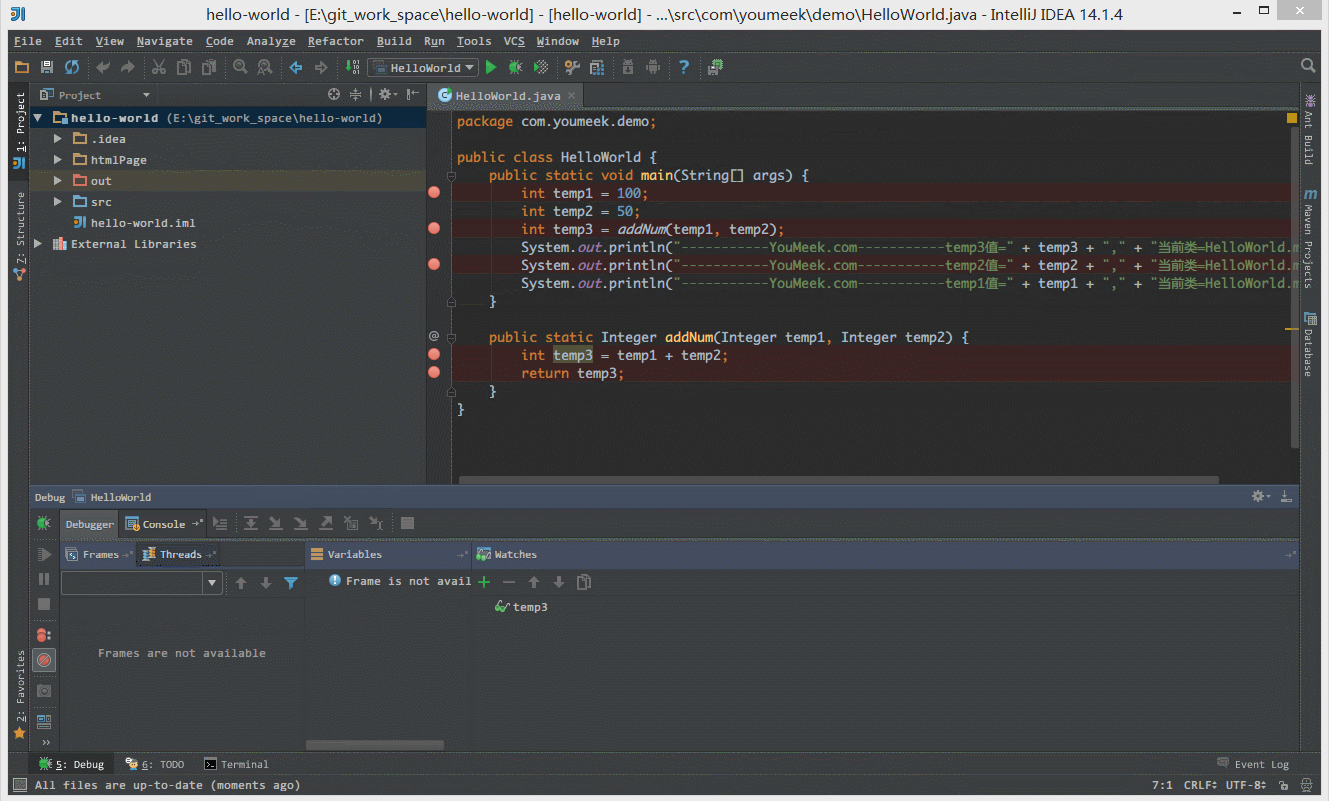
① 如下图 Gif 所示,查看所选对象的方法常用有三种方式:
- 选中对象后,使用快捷键
Alt + F8。 - 选中对象后,拖动对象到
Watches。 - 选中对象后,鼠标悬停在对象上 2 秒左右。
- 想看对象的具体内容,选中之中,使用
Ctrl + F1,查看对象具体内容。
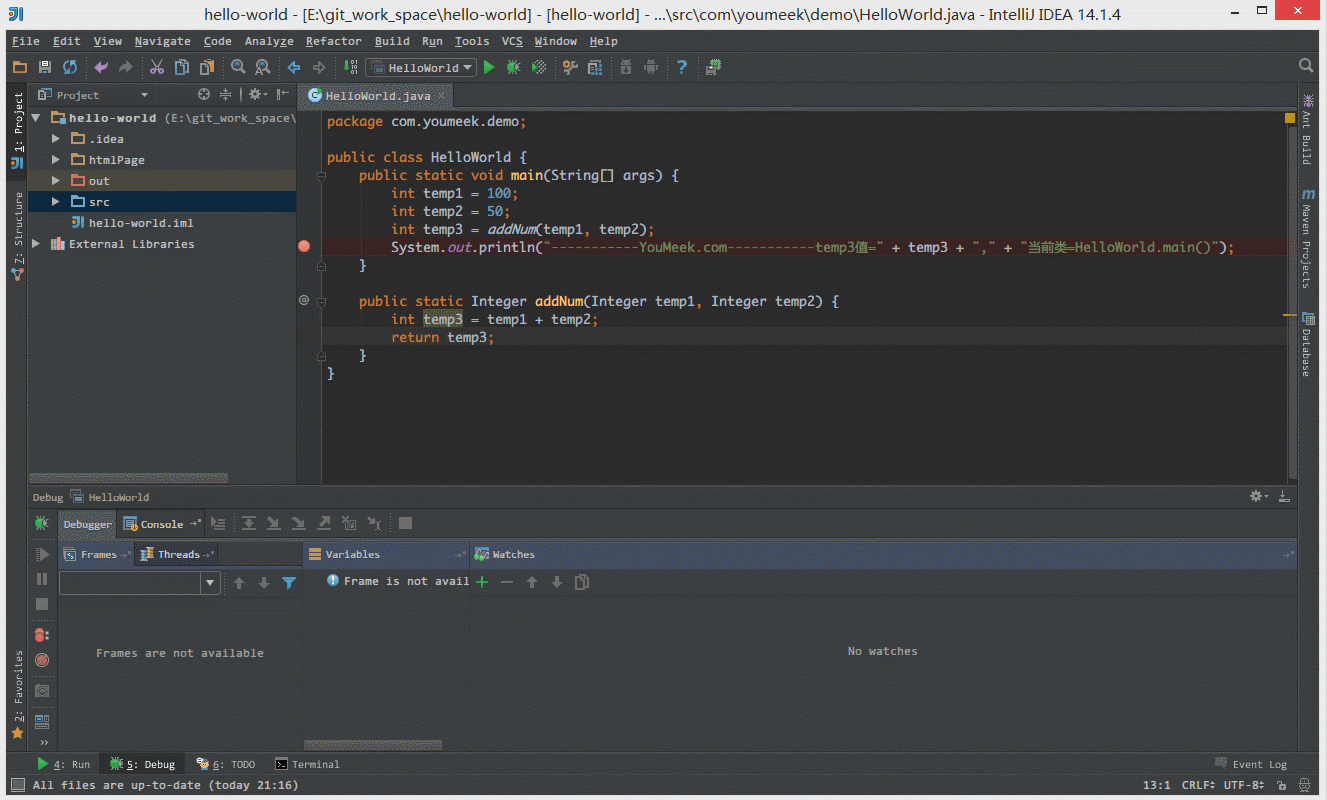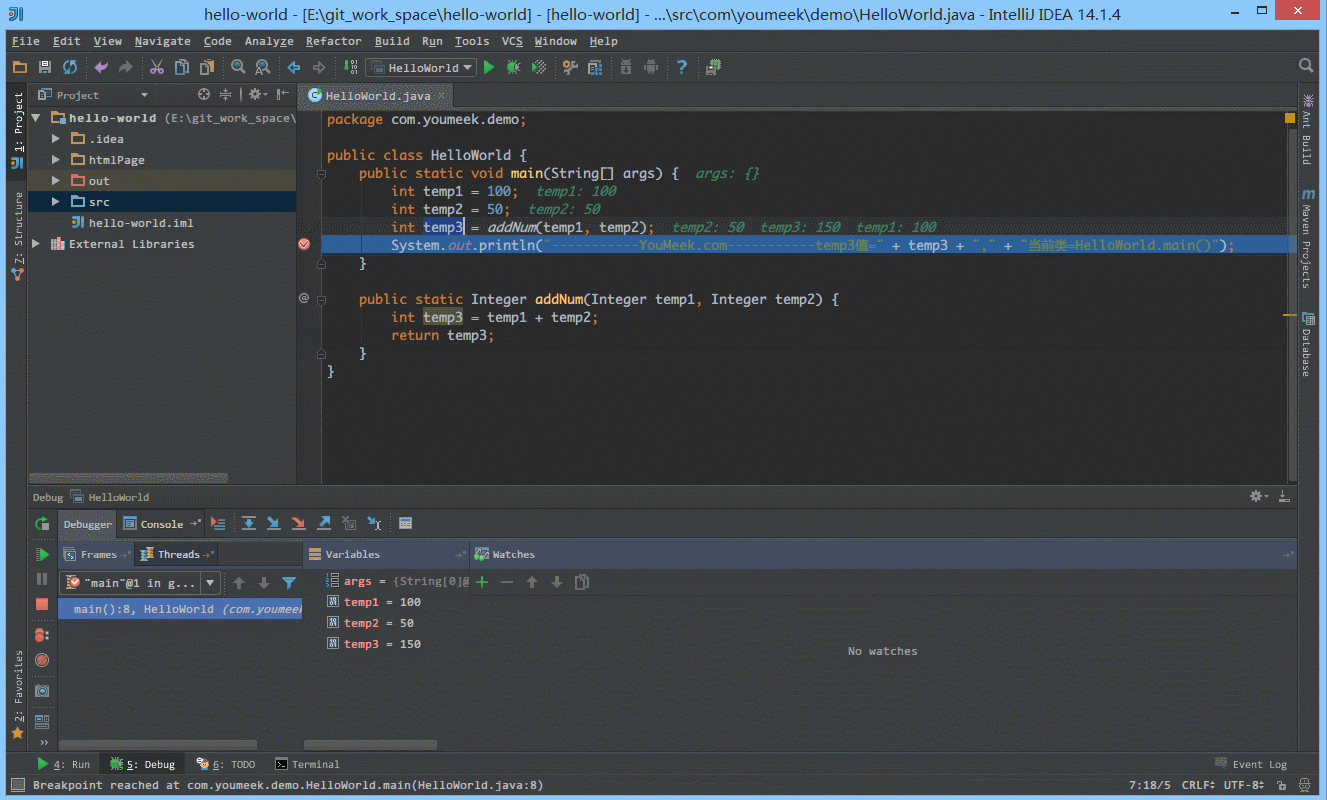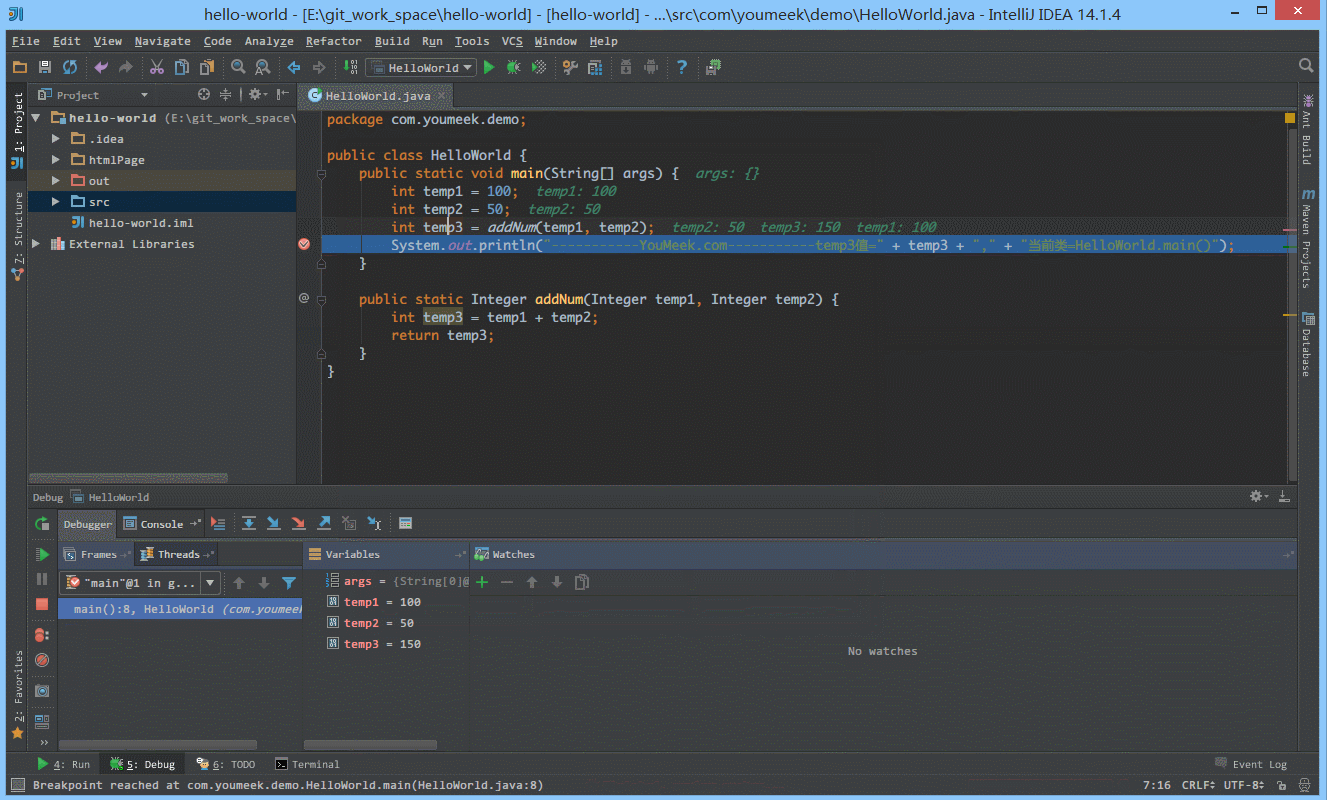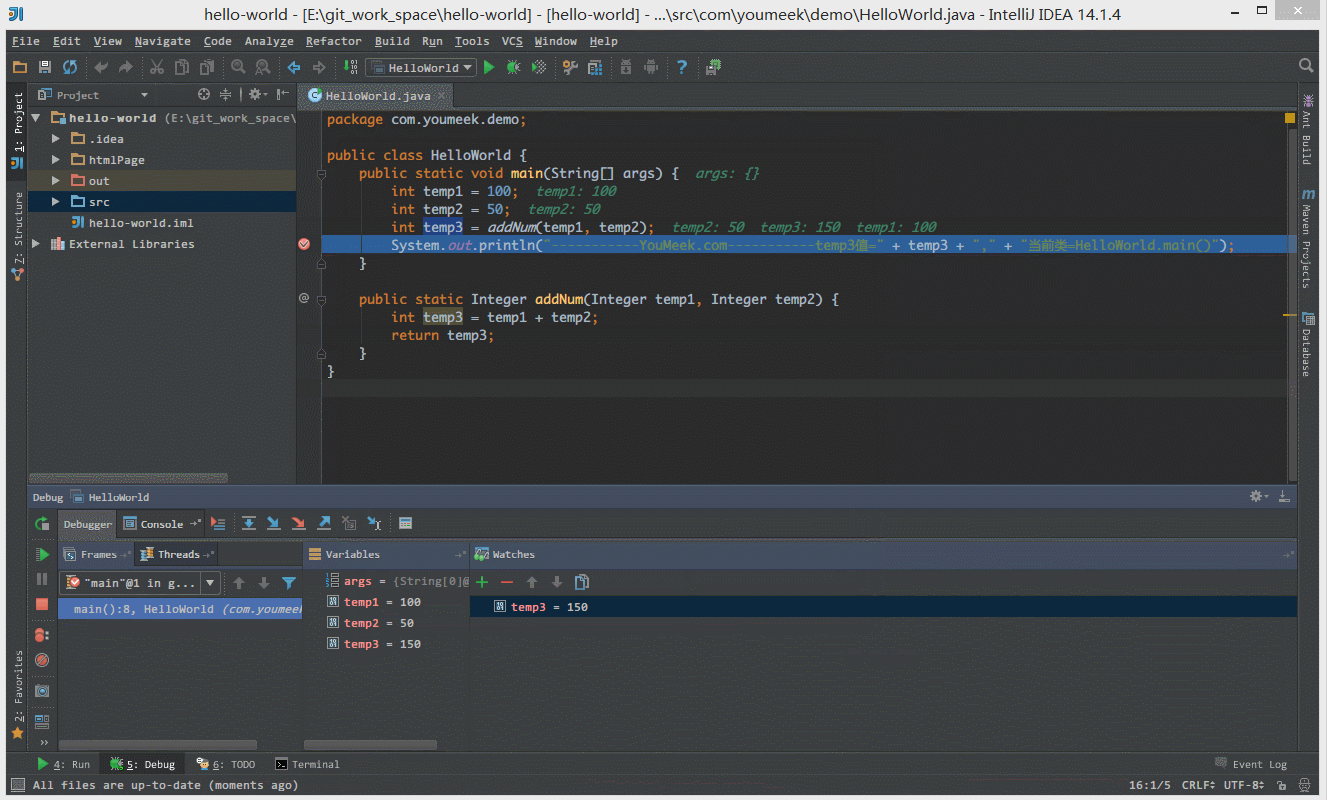

② 如下图 Gif 所示,在弹出表达式输入框中 IntelliJ IDEA 也是能帮我们智能提示。
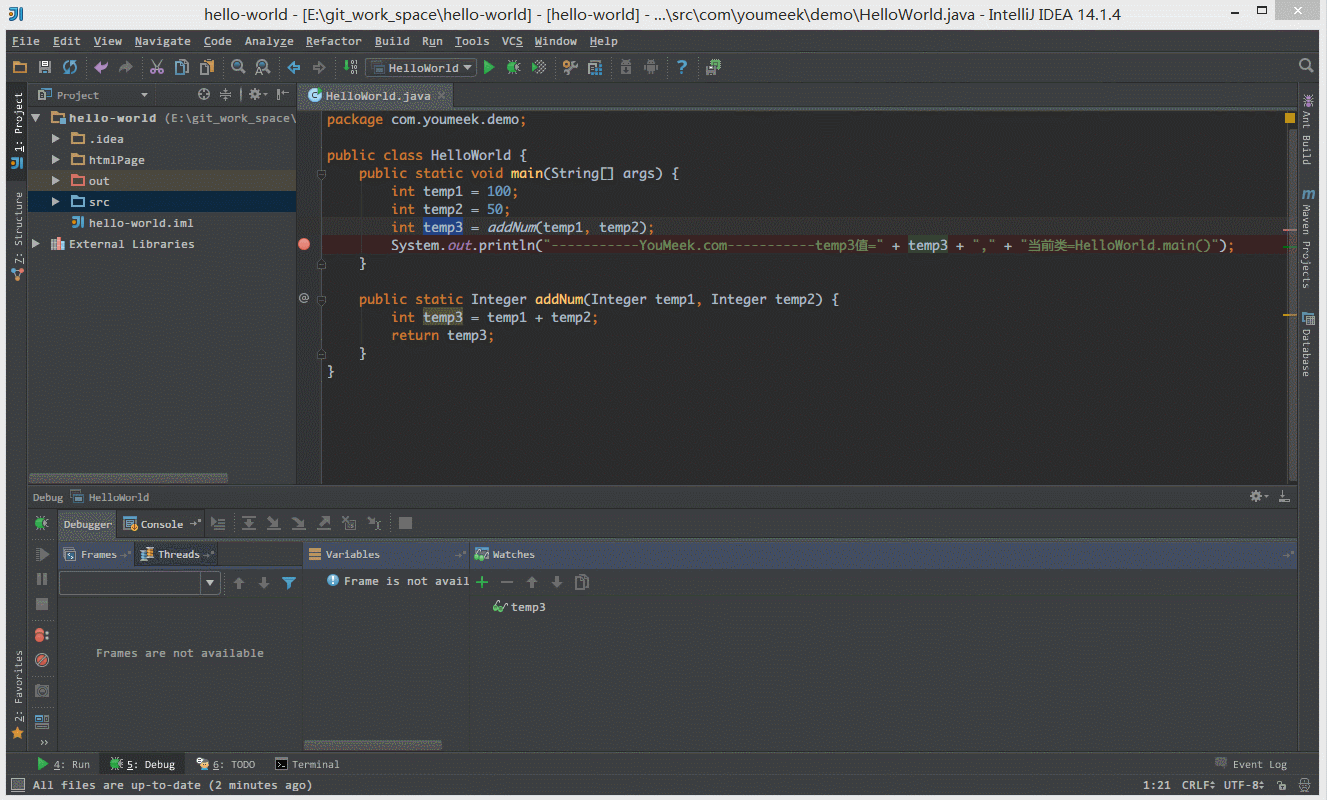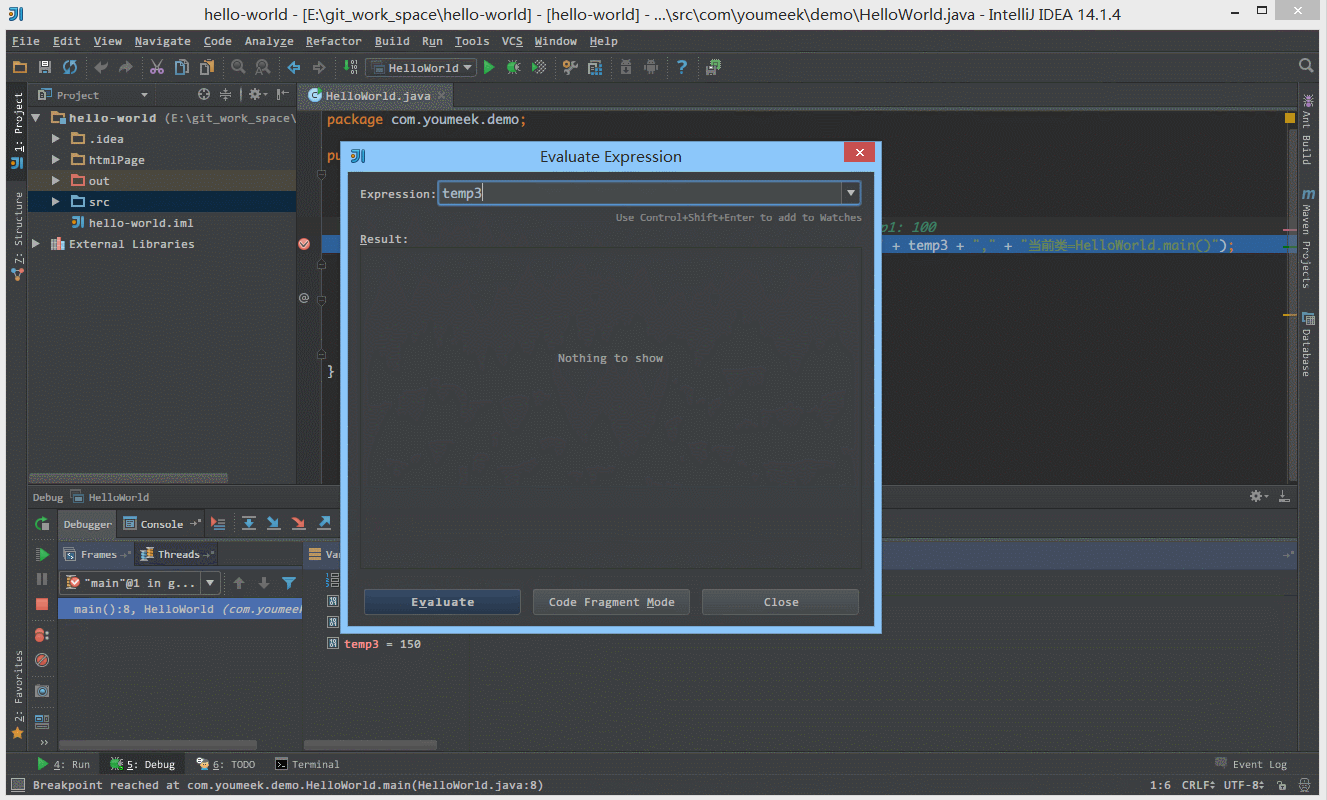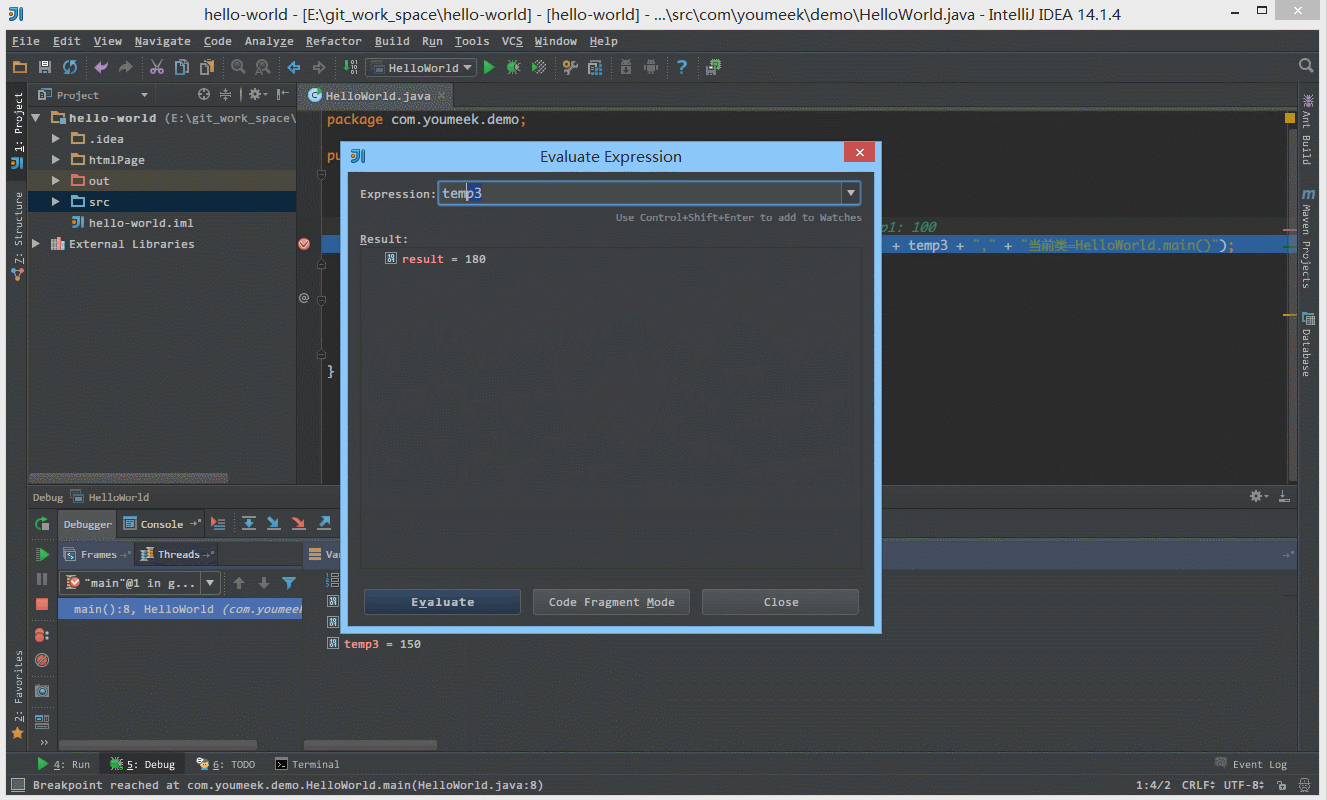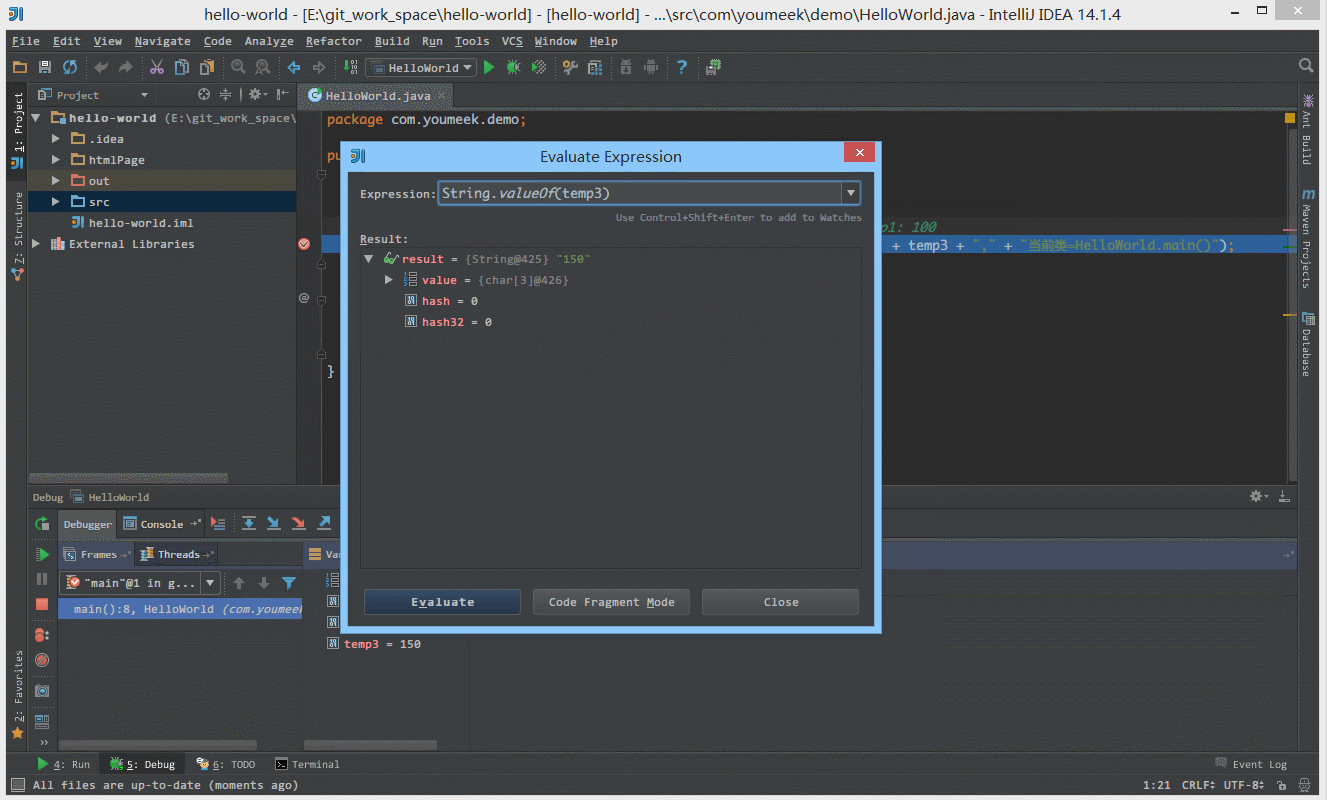
③ 如下图 Gif 所示,当我们需要过掉后面的所有断点的时候,我们不需要去掉这些断点,只需要点击左下角那个小圆点,点击小圆点之后,所有断点变成灰色,然后我们再在按快捷键 F9 即可过掉当前和后面所有的断点。
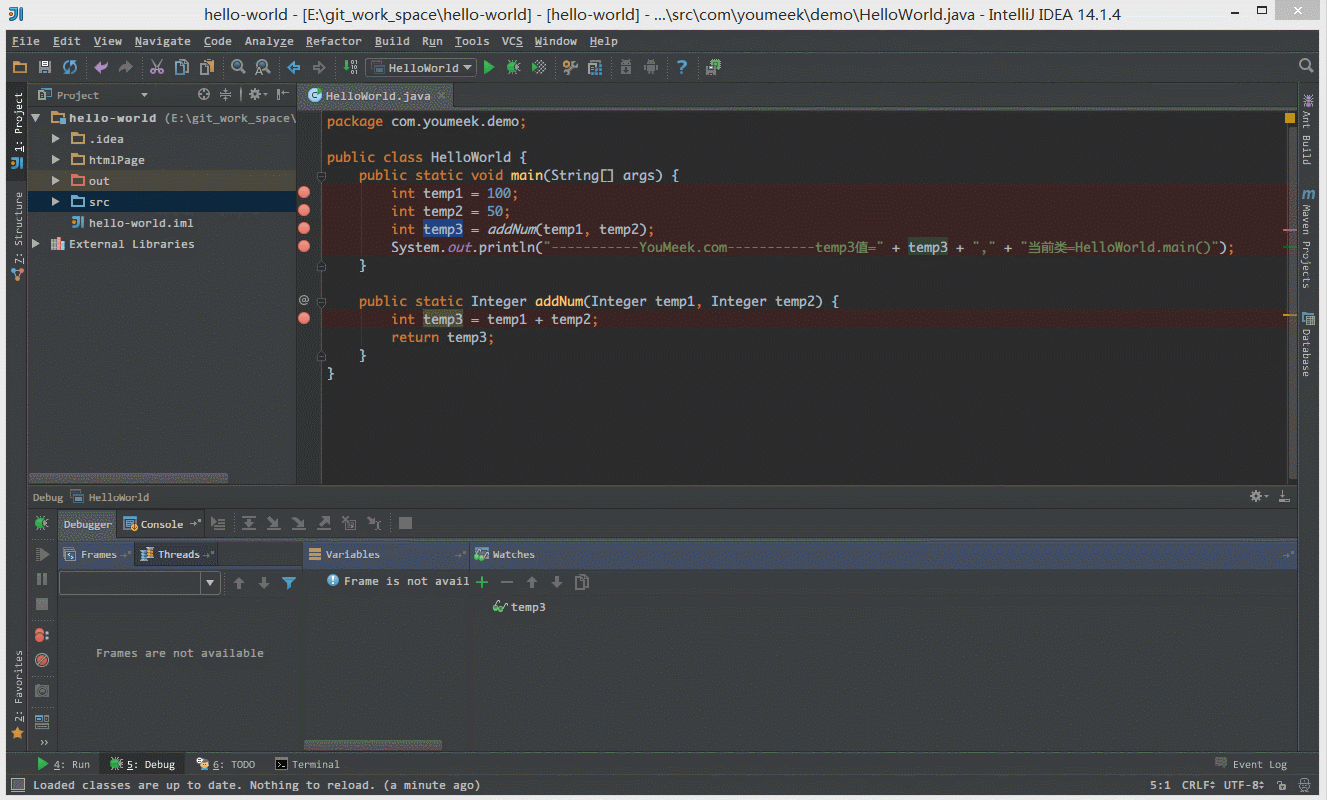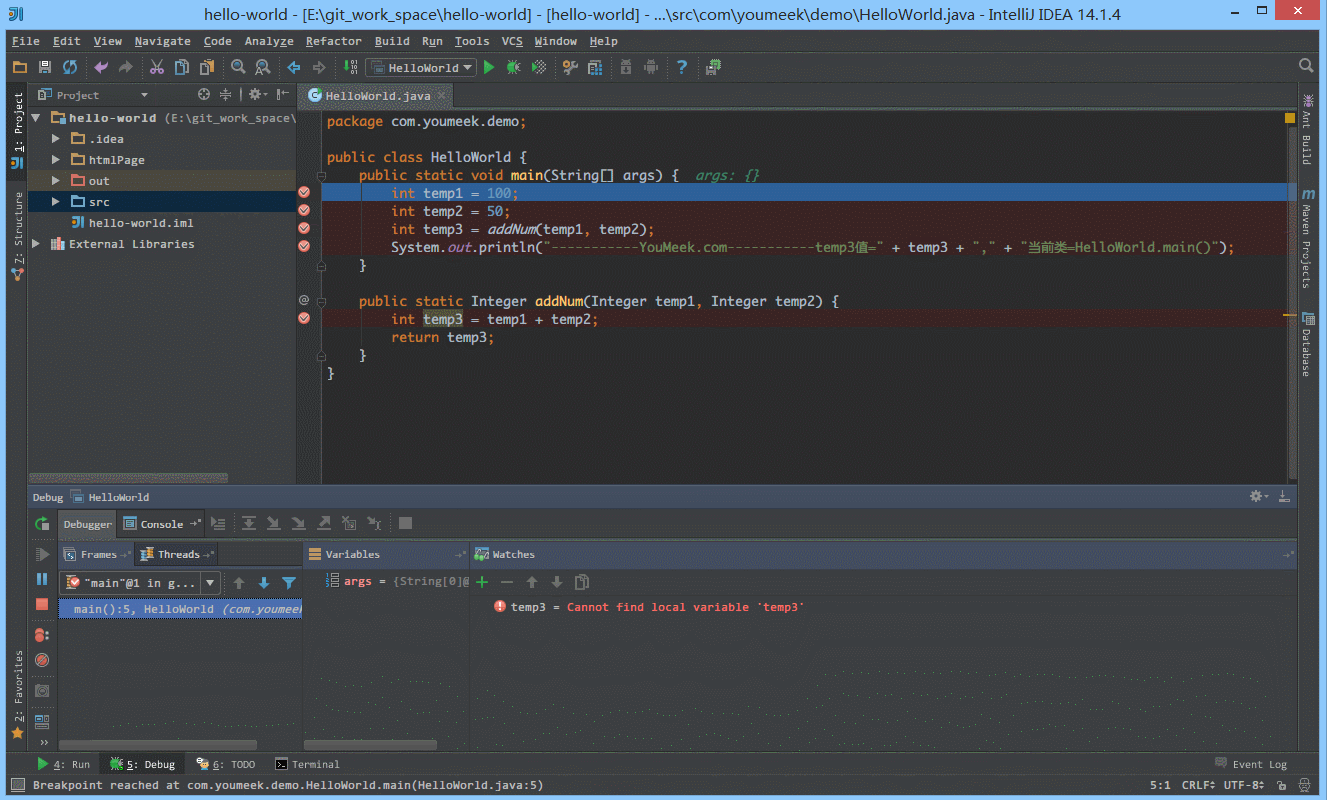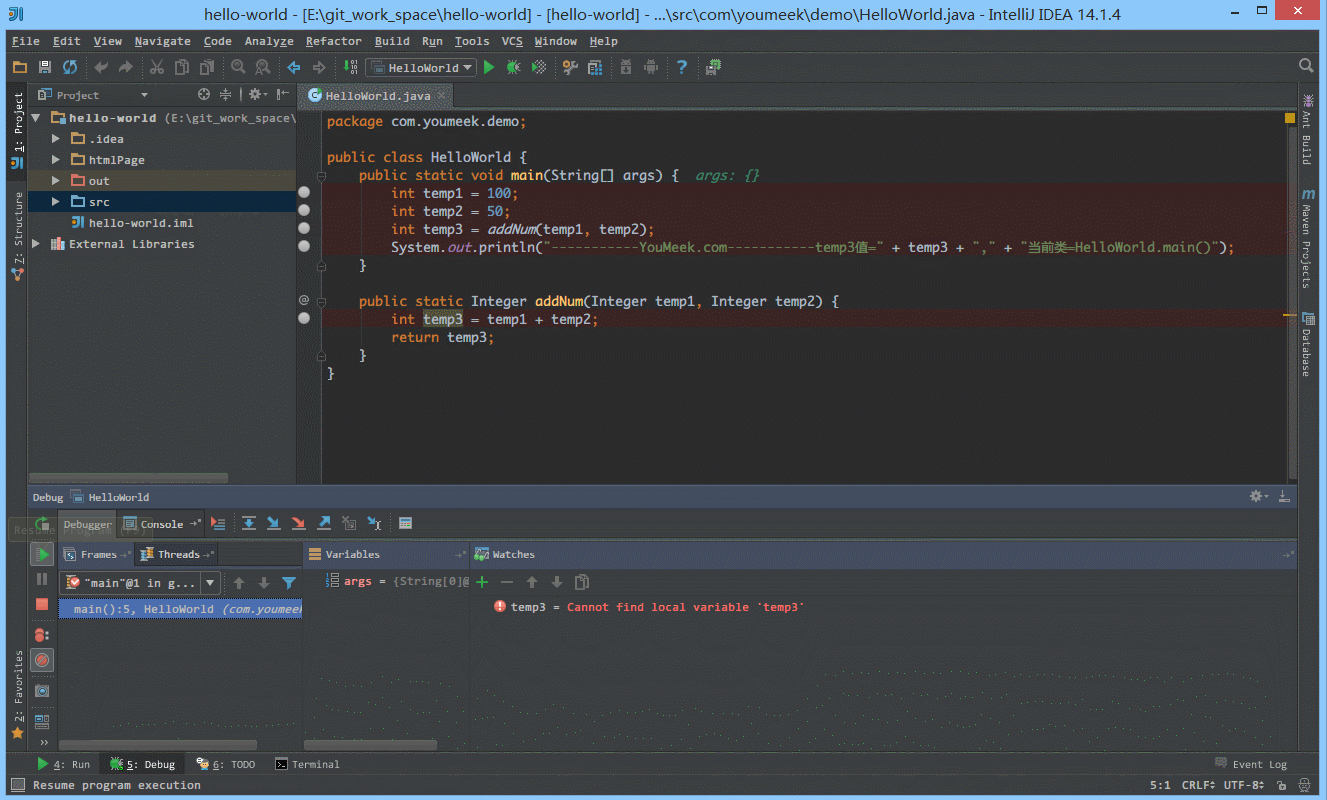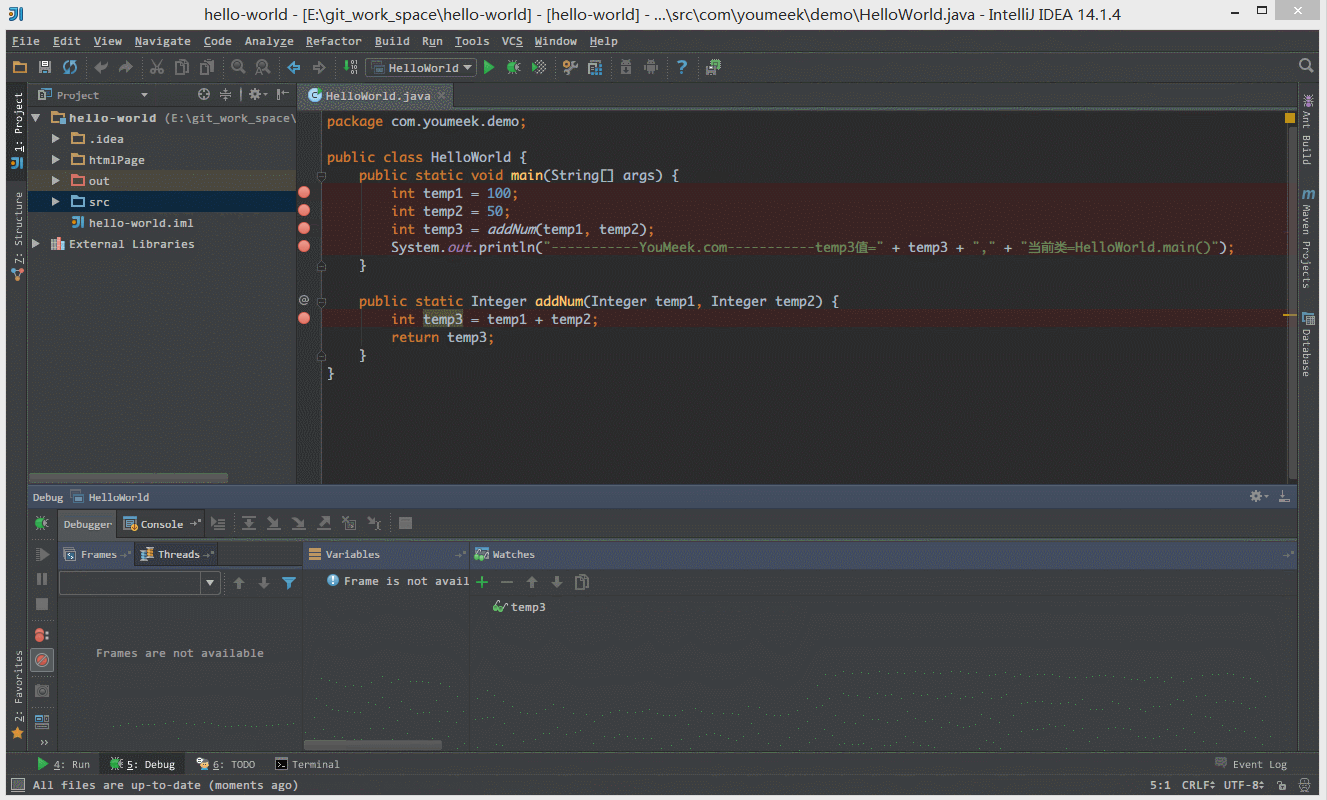
④ 如下图 Gif 所示,我们可以给断点设置进入的条件,因为变量 temp3 不等于 200 所以该断点没有被进入直接跳过。
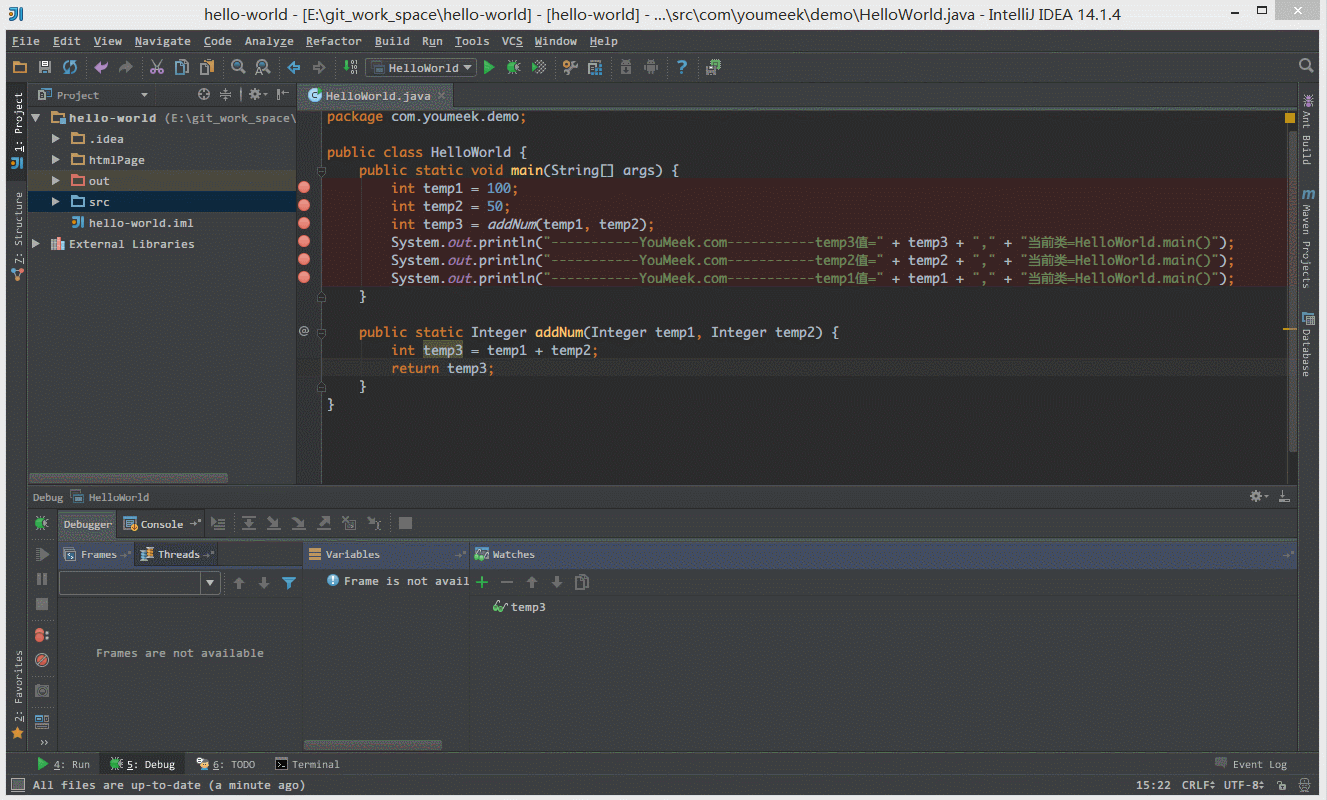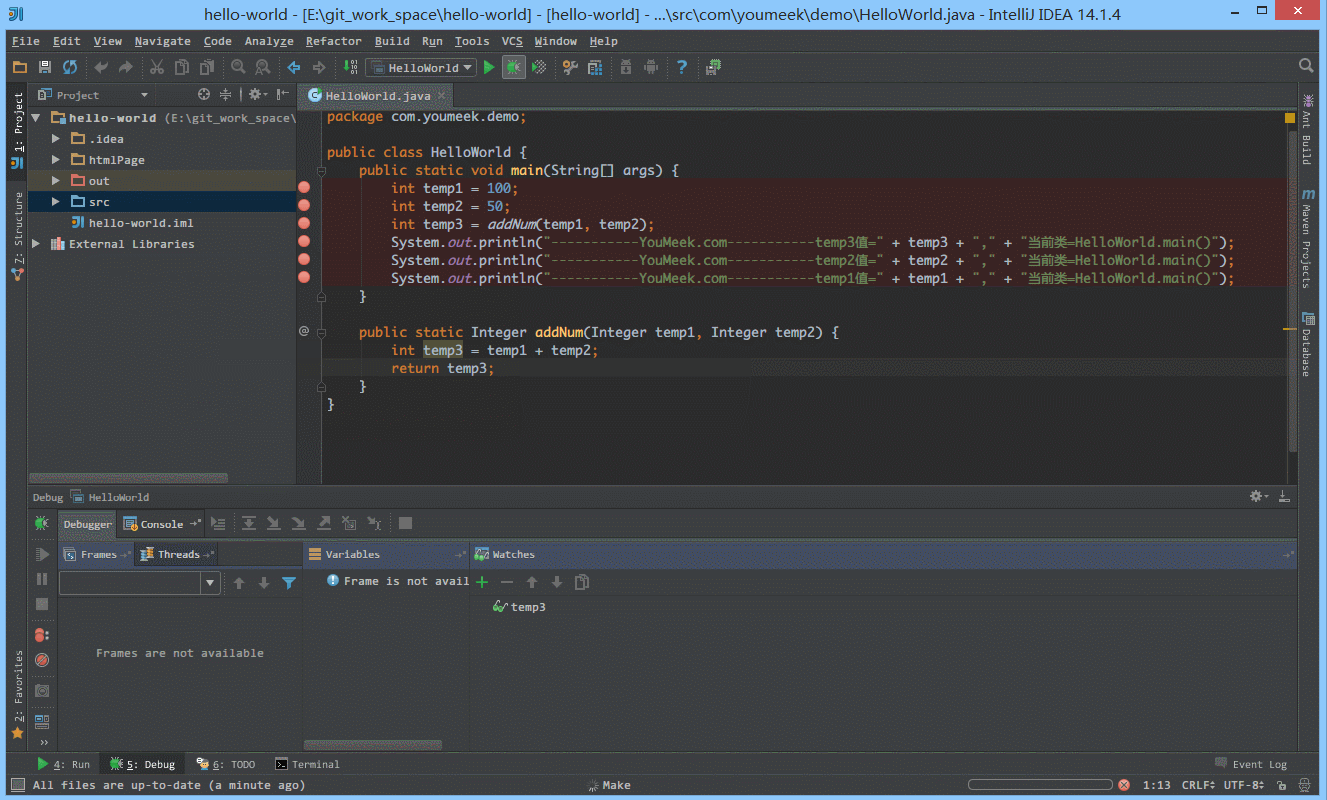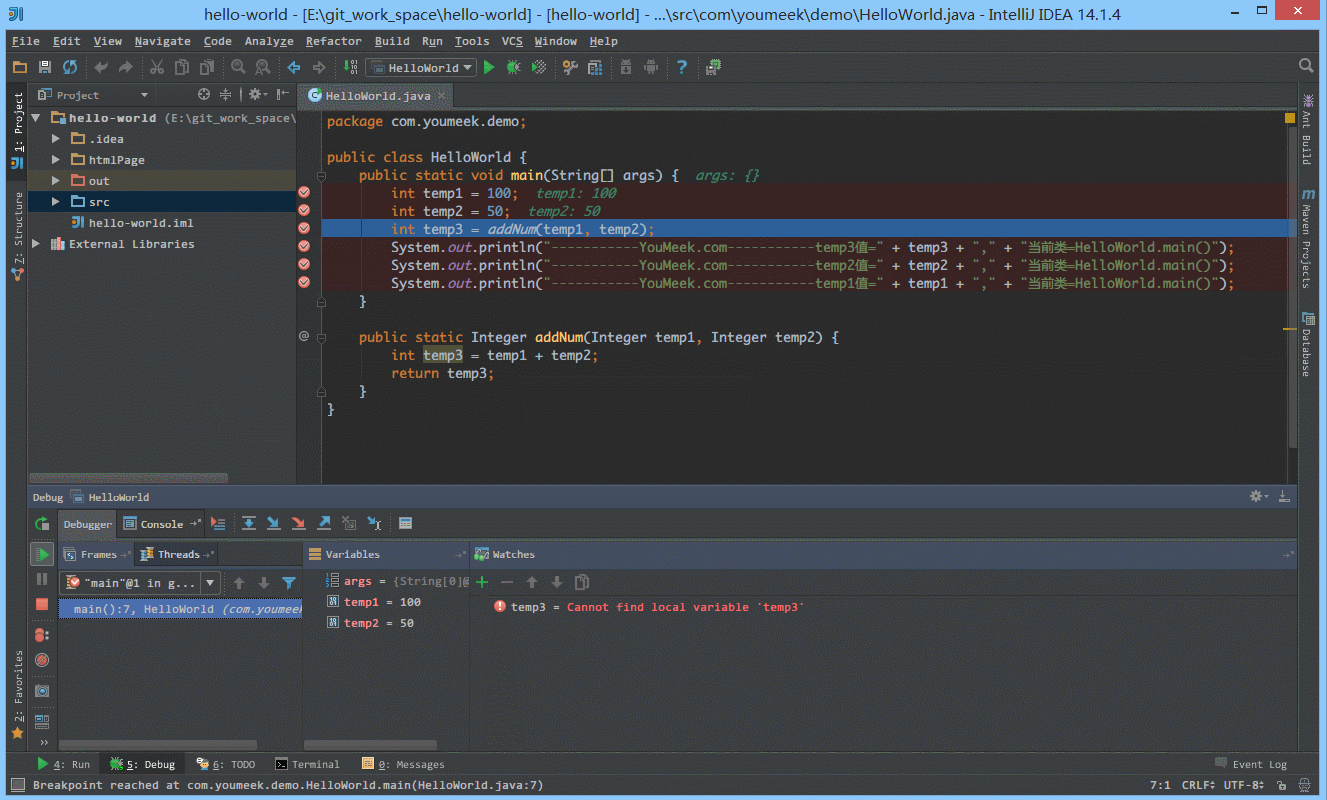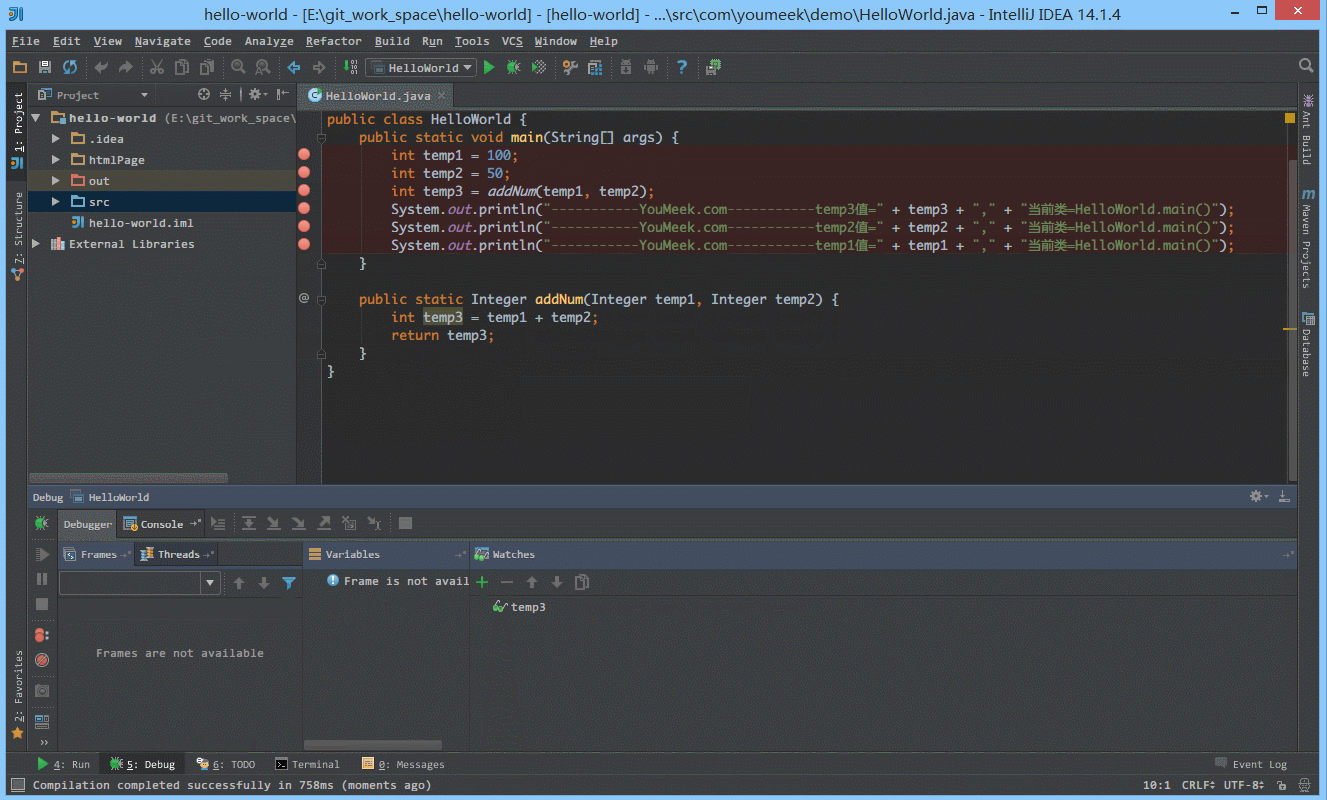
⑤ 如 下图Gif 演示,有时候当我们步入方法体之后,还想回退到方法体外,断点进入 addNum 方法后,点击 Drop Frame 按钮之后,断点重新回到方法体之外。
11.mybatis 到底要不要写一对多、一对一关联?
-
方法1
- Dao 层有一对多、一对一关联
- Service 层写业务逻辑
-
方法2
- Dao 层不写一对多、一对一关联,只提供基本的增删查改
- Service 层完成关联查询等以及写业务逻辑
方法1在效率上貌似有优势,但写 resultMap 和语句真是不开心
方法2对程序员比较友好,但效率不如方法一,而且 service 层会比较臃肿
12.日志的配置,以及其含义
1.Log4j的配置, 2.log4j的使用--IDEA创建maven项目
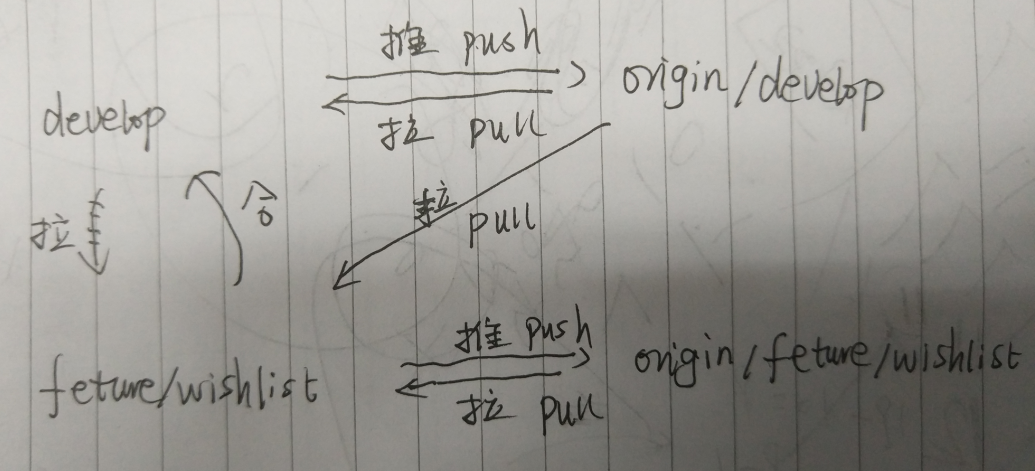
13.gitflow简单的操作
14.Spring MVC之中出现:No mapping found for HTTP request with URI
A:关于No mapping found for HTTP request with URI..., DID NOT FIND HANDLER METHOD FOR SPRINGMVC资源文件扫描不到---关于SPRING的那些坑
15.springmvc可以对前台返回json数据,也可以从前台获取JSON格式的数据, 当然,JSON格式只是最常用的一种格式,还有很多其他的格式,后台给前端返回json数据相对简单,而前台给后台发送JSON格式数据的时候,就需要注意,我们要使用AJAX来帮助(jquey的ajax)即可.此时,一定要搞清楚方向的问题,是前端发送json数据到后台,所以这个发送时从前端发给后台,就是从前端浏览器之中发起请求,在web服务器如tomcat运行的时候,后台会接收到这个请求,获得参数,然后才去相应的措施.
1.springmvc 接收json对象的两种方式 , 2.Java运用JSON实现后台与前端分工合作(代码实例) , 3. SpringMVC——对Ajax的处理(包含 JSON 类型), 4.SpringMVC @RequestBody 处理ajax请求, 5. ajax请求,fastjson报出错误:syntax error, expect {, actual error, pos 0, 6.springmvc与fastjson的整合,注解@RequestBody的使用
16.表单form简介
基本语法
<FORM ACTION="URL" METHOD="GET|POST" ENCTYPE="MIME" TARGET="...">
... ...
</FORM>
基本功能
表单在网页中主要负责的是数据采集功能,一个表单基本由三部分组成
- 表单标签:这里面包含了处理表单数据所用 CGI (Common Gateway Interface,通用网关接口)程序的 URL (Uniform Resource Location,统一资源定位符)以及数据提交到服务器的方法.
- 表单域:包含了文本框、密码框、隐藏域、多行文本框、复选框、单选框、下拉选择框和文件上传框等。
- 表单按钮:包括提交按钮、复位按钮和一般按钮;用于将数据传送到服务器上的CGI脚本或者取消输入,还可以用表单按钮来控制其他定义了处理脚本的处理工作.
两个参数
- method: post和get均可, 都可以作为提交数据的方法, 但是一般post是推送消息给服务器, get是从服务器获取数据, 这是约定形成的, 当没有明确指定method的时候, 默认的method是get.
- action: action是提交给处理的url, 意思是把表单提交到这个url处理, 没有action, action="" 或者action="?", 都是将表单数据提交到本页的意思.
1.HTML , 2.HTML 表单(form) 使用详解, 3.HTML里面form表单name,action,method,target,enctype等属性用法, 4. HTML 表单 (form) 的作用解释 , 5.SpringMVC表单标签简介
17.前端和后端的感悟
A:form之中的action,对应的不是一个获取到的地址, 而是将数据传送, 然后让其处理问题的地址, 即push! form之中的表单信息提交给Spring MVC之中RequestMapping之中的url进行处理,是的! 但是,为什么此处没有获得那边传过来的数据呢??? 其实,意思就是,应该是后端的数据绑定到了前端, 还是说前端的数据传递到了后端?---> 我想,肯定是前端的数据,传到了后端,而传值得方式,是通过前端和后端都有,但是在后端定义的数据模型,id,来完成的. 就是说,在后端定义了一个模型, key在后端定义好了, 但是value需要前端传过来, 给后端, 经过后端处理, 然后显示出来.
18.关于form标签的path和commandName
form标签之中的path,commandName(modelAttribute)的来源,path就是我需要的一个值的对应的Domain(Model,POJO)类之中的相应的字段,commandName(modelAttribute)就是在Controller之中定义的Model(ModelMap, ModelAndView)对应的Model的key。此处需要理清楚数据绑定的对象,数据绑定的方向。
19.Spring MVC前后端数据交互
A:1.Spring MVC前后端数据交互总结, 2.Spring MVC 后端获取前端提交的json格式字符串并直接转换成control方法对应的参数对象, 3.Spring MVC 传值方式总结, 4.SpringMVC前端传值到Controller与Controller中传值到View解析, 5.Spring 向页面传值以及接受页面传过来的参数的方式
20.JSP页面使用a href来跳转到另一个jsp页面
A:Spring MVC貌似不支持从一个jsp页面通过<a href="sss.jsp">的方式跳转,都要通过controller的方式访问页面
21.视图配置的时候,可以设置多个文件夹吗?可以配置多种视图后缀吗?
A: ViewResolver可以设置多个,不同的ViewResolver类型,需要设置不同的ViewResolver,比如jspViewResolver,htmlViewResolver等。至于某一种视图的多个文件夹,可以在/WEB-INF/views/之中设置,可以设置到不同级别的文件夹之中,但是这样不灵活,一般都是返回的时候,返回其父级别的文件夹名,比如之前的为/WEB-INF/views/,返回的时候使用的是return "login",比如修改为/WEB-INF/views/user之后,那就需要使用user/login来返回,写全就是:return "user/login",如果要访问其他的,新的网页,则可以使用“user/XXX”,那么就是同一视图的多个文件夹的访问方式,而不同的ViewResolver,一般时将其页面放在不同的页面之下。1. springmvc如何设置多视图器,springmvc 多个 ViewResolver , 2.SpringMVC同时支持多视图(JSP,Velocity,Freemarker等)的一种思路实现
22.Spring MVC之中form标签,jstl标签,sf标签,el表达式,各自使用在什么地方并且有什么区别?
A:JSTL的全名为:Java Server Pages Standard Tag Library。JSP标准标签库,由四个定制标记库(core、format、xml 和sql)和一对通用标记库验证器(ScriptFreeTLV 和 PermittedTaglibsTLV)组成。它实现了迭代和条件判断、数据管理格式化、XML操作以及数据库访问的功能。有了jstl标签库和el表达式,我们的 jsp中不需要<%%>的java代码,提高了程序的可读性和可维护性。
EL(Expression Language)表达式:目的是为了使JSP写起来更加简单。语法结构:${expression}; 对象:pageScope、requestScope、sessionScope、applicationScope(访问顺序:page—request—session——application)
form标签是SpringMVC的核心标签,如下的表达式中,tablib是我们给此标签库设置的名字,可以为任意不重复的名字,当然决定此标签库的还是URI,URI唯一决定此标签库,所以如下的标签库可以叫sf,也可以叫form
<%@ taglib prefix="form" uri="http://www.springframework.org/tags/form" %>
除了Spring标签,JSTL标签,还有Strutsde 标签等等。而EL表达式只是为了方便使用而存在的
区别还没有写
23.Spring MVC的模板技术有哪些?
A:模板技术有JSP, Velocity, freemarker和Thymeleaf模板,JSP开发对于MVC是破坏的,而后面三种是MVC模式的,不会在视图之中直接写java代码,而jsp会写java代码,然后编译成servlet,占用JVM的堆大小,会有GC的产生。Velocity, freemarker和Thymeleaf支持MVC开发模式,前后端分离,之间的差别不是非常大,Spring官方推荐的是Thymeleaf模板。浅谈jsp、freemarker、velocity区别
24.Spring MVC后端传给前端值,怎么传,有哪些方法?
A:
25.Spring MVC前端传给后端值,怎么传,有哪些方法?
A:
26.spring的jsp类库有哪些?<%@ taglib prefix="form" uri="http://www.springframework.org/tags/form" %>的含义和说明
A:taglib之中的prefix是一个必要的参数,这个是自己定义的,可以是任何和已有的标签缩写不重复的标签前缀,但是重点在于后面的URI,这是唯一定位一个标签库的方式。 Spring的标签,有form部分和其他部分,这个form是为了数据绑定而设置的,Spring的标签,主要是使用form,其他的标签在tags下面,用的不是很多。
27.spring的jsp类库有哪些?
A:Spring提供了两个JSP标签库,用来帮助定义SpringMVC Web的视图。其中一个标签库会用来渲染HTML表单标签,是from标签,这些标签可以绑定model中的某个属性。另外一个标签库包含了一些工具类标签,我们随时都可以非常便利地使用它们。在这两个标签库汇中,表单绑定的标签库更加有用。我们更多使用的是表单标签,表单标签所在的位置为:
<%@taglib uri="http://www.springframework.org/tags/form" prefix="form"%> ,而工具类标签为
<%@taglib uri="http://www.springframework.org/tags" prefix="sf"%>。1.SpringMVC入门之七:使用JSP作为视图, 2.Spring MVC 页面渲染( render view ), 3.SpringMVC入门之五:渲染Web视图概述。
28: spring form之中的标签,可以卸载spring:form之外吗?也就是说,能在form之外单独应用吗?
A: 是不能的,spring jsp的表单form标签之中的子元素,如<form:input>,<form:checkouboxs>等,都是需要在form标签之下才能起作用的,所以spring jsp的表单form标签之中的子元素必须要包含在form打的标签之中,在标签之外就会报错。
29.Spring MVC的默认视图解析器是什么?
A:当视图为jsp的时候,默认的视图解析器为InternalResourceViewResolver,默认的viewClass为JstlView,一般的配置为:
<bean class="org.springframework.web.servlet.view.InternalResourceViewResolver" >
<property name="prefix" value="/WEB-INF/views/" />
<property name="suffix" value=".jsp" />
<property name="viewClass" value="org.springframework.web.servlet.view.JstlView />
</bean>
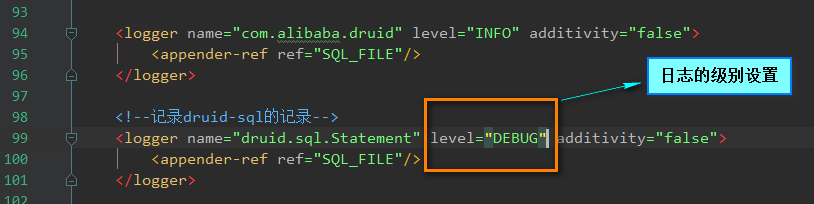
30.为什么通过mybatis执行sql语句,一开始可以成功,但是后续执行返回结果为0?
A:这主要是因为数据太小,而查询的时候无法直接显示出来数据的原因,比如,删除的时候使用id和item_id,在一开始的时候都是1,2,3这种数据,但是购物车id主键和商品的id的增长是不同步的,所以就会产生数据不同步的原因,此时的表现是,sql语句可以执行,但是返回受影响的行数结果为0。这类问题大多是由于粗心大意,把字段搞错了!解决这些问题的方法如下:
- 查看sql日志
- 调到debug状态
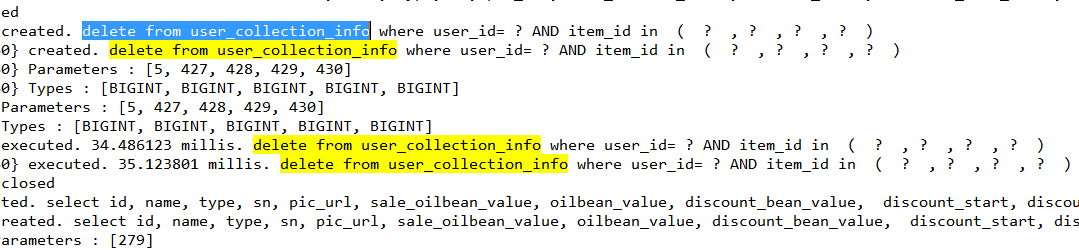
- 查看参数

- 调到debug状态
- sql参数检查
- Rap2接口声明查看
- mybatis语法测试
31.IDEA突然标红,怎么处理?
A:一般是由于缓存导致的,表现为各个类都无法识别,但是仍然可以运行,此时只需要清理缓存即可。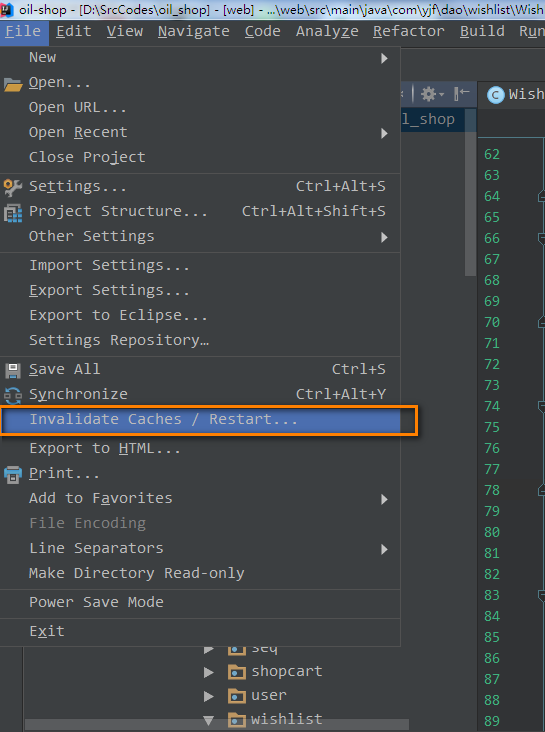
32.mybatis之中动态SQL的作用?
A:当我们使用mybatis对一张表进行的CRUD操作,如果业务简单,那么SQL语句都比较简单,如果有比较复杂的业务,我们需要写复杂的SQL语句,往往需要拼接,而拼接 SQL,稍微不注意,由于引号,空格等缺失可能都会导致错误。
那么怎么去解决这个问题呢?就需要使用mybatis的动态SQL,通过if, choose, when, otherwise, trim, where, set, foreach等标签,可组合成非常灵活的SQL语句,从而在提高 SQL 语句的准确性的同时,也大大提高了开发人员的效率。
33.@Results,@Result的作用是什么?
A:@Results, 对应<resultMap>表示的是结果映射的列表,包含了一个特别结果列如何被映射到属性或字段的详情。属性为value,@Result是@Results注解的结果数组之中的一条结果,@Results注解产生一个对应的结果数组。
34.嵌入在mybatis动态SQL语句之中的<script>,<CDATA>等标签的作用?
A:用script标签包围,然后像xml语法一样书写,很明显,在java中写xml可读性和维护性太差,尤其当SQL很长时,这样写是很痛苦的。 <script>,<CDATA>这些标签是xml之中的标签,我们一般写sql的时候不用这么写,需要注意标点,连接符等即可。写简单的SQL,结果拼接,而不是拼接SQL。
@Select("<script>" +
"SELECT id,sn,user_id,wechat_id,alipay_id,item_id,item_value,mobile," +
"oilcard_num,oilcard_name,recharge_value,bean_award_value,payment_value,status," +
"payment_time,order_time,created,updated " +
" FROM oilcard_recharge_record "+
"<where>" +
"<if test="status !=null "> and status = #{status}</if>" +
"<if test="createdStart !=null "> and created <![CDATA[ > ]]> #{createdStart}</if>" +
"<if test="createdEnd !=null "> and created <![CDATA[ < ]]> #{createdEnd}</if>" +
"</where>" +
"order by order_time desc " +
"</script>")
List<OilCardRechargeRecord> listByStatus(@Param("status") Integer status,
@Param("createdStart") Long createdStart,
@Param("createdEnd") Long createdEnd);
sql中有一些特殊的字符的话,在解析xml文件的时候会被转义,<CDATA>能避免被转义mybatis 详解(五)------动态SQL,XML CDATA,"![CDATA[","<script>"这些字符在动态sql的语句之中的作用是:**防止sql里面出现诸如"<"、"&"这种XML非法字符的情况 **,MyBatis动态SQL实现ORDER BY和LIMIT的控制?。
注意:
有时候,只使用单纯的sql语句,在使用动态语句的时候,就会出现无法正确解析SQL的情况,比如说,使用<if>语句的时候,在"<if test="topic.status != null" >status = #{topic.status},</if>"这种情况的时候就会出现问题,所以最外层需要使用<script>包起来。另外status = #{topic.status}这句,不能将#和{}分开,比如status = # {topic.status},这种就会出现错误。当if的条件只有一句的时候,后面不能加","。比如有
// 只有一个参数的时候,不能加逗号","---><if test="status !=null"> status = #{status},</if>
@Select("<script>"
+ "SELECT "
+ "id, topic_name, topic_introduce "
+ "FROM article_topic"
+ "<where>"
+ "<if test="status !=null"> status = #{status}</if>"
+ "</where>"
+ "</script>")
List<ArticleTopic> getTopicNumber(@Param("status") int status);
在插入语句之中,也可以使用动态条件,如下:
// 需要添加<script>,否则无法正确解析<if...>的内容,在insert的时候也可以使用<if...>
@Insert("<script>"
+ "INSERT INTO "
+ "article_topic (id, topic_name, topic_introduce, sort,"
+ "<if test="topicImg !=null "> topic_img,</if> "
+ "<if test="topicThumbnail !=null "> topic_thumbnail,</if> "
+ "status, created, updated)"
+ "VALUES"
+ "(#{id}, #{topicName}, #{topicIntroduce}, #{sort}, "
+ "<if test="topicImg !=null "> #{topicImg},</if> "
+ "<if test="topicThumbnail !=null "> #{topicThumbnail},</if> "
+ "#{status}, #{created}, #{updated})"
+ "</script>")
@Options(useGeneratedKeys = true, keyProperty = "id", keyColumn = "id")
long addTopic(ArticleTopic topic);
一般情况下,更新,插入的时候,需要使用到对象,在此时,我们的字段就需要带对象的名称,但是在占位符之中,不需要设置对象名,如下:
@Update("<script>"
+ "UPDATE article_topic"
+ "<set>"
+ "<if test="topic.status !=null"> status = #{topic.status},</if>"
+ "<if test="topic.updated !=null"> updated = #{topic.updated},</if>"
+ "</set>"
+ "<where>"
+ "id = #{id}"
+ "</where>"
+ "</script>")
long stickyTopic(@Param("topic") ArticleTopic topic, @Param("id") long id);
35.注解,providersql,mapper.xml等方式的异同?
A:注解,providersql,mapper.xml三种方式都是要产生对应的查询结果,注解方式更加集中,把DAO方法,SQL语句,集中在了一个Java接口之中,方便,但是每次有改动,必须要完整的改动这个接口文件。
providersql和mapper.xml方式比较相似,providersql方式,将sql语句与DAO方法的接口文件分离,使用反射,提供了sql语句的调用,DAO方法和SQL语句是分离的。
mapper.xml方式同样是分离的,但是在mapper.xml之中,我们可以定义各种resultMap,可以重复利用,利用效率比较高,但是写起来比较麻烦。
36:动态sql标签
A:MyBatis的动态SQL是基于OGNL表达式的,它可以帮助我们方便的在SQL语句中实现某些逻辑。MyBatis中用于实现动态SQL的元素主要有:if, where, set, choose(when,otherwise), trim, foreach. 我们在一般是在可能产生不确定条件的地方使用动态SQL的标签,如在where, update的set之中使用动态标签。
if是一个基本的标签,
<if test="条件"> id=#{id} </if>
也可以if+where组合,
<where>
<if test="条件1"> id=#{id} </if>
<if test="条件2"> name=#{name}</if>
</where>
update的<set> 标签,
<set>
<if test="条件1"> id=#{id} </if>
<if test="条件2"> name=#{name}</if>
</set>
有时候,我们不想用到所有的查询条件,只想选择其中的一个,查询条件有一个满足即可,使用 <choose> 标签可以解决此类问题,类似于Java的switch语句
<where>
<choose>
<when test="条件1"> id=#{id} </when>
<when test="条件2"> name=#{name} </when>
<otherwise> and age=#{sex} </otherwise>
</choose>
</where>
trim标记是一个格式化的标记,可以完成set或者是where标记的功能,在sql其中,添加了一些如分隔符,前缀后缀等的信息。可以对应更多的情况,而foreach更多的是sql之中的in情况,例如id in(id的一个查询得到的结果集合)
<select id="selectUserByListId" parameterType="com.ys.vo.UserVo" resultType="com.ys.po.User">
select * from user
<where>
<!--
collection:指定输入对象中的集合属性
item:每次遍历生成的对象
open:开始遍历时的拼接字符串
close:结束时拼接的字符串
separator:遍历对象之间需要拼接的字符串
select * from user where 1=1 and (id=1 or id=2 or id=3)
-->
<foreach collection="ids" item="id" open="and (" close=")" separator="or">
id=#{id}
</foreach>
</where>
</select>
37:Mybatis的Insert Update和Select Delete语句的注意点
A:当我们使用SQL进行insert和update的时候,在Mybatis之中,使用的是对象,而非一个一个的单独的参数,在Mapper之中,对应的参数为id和对应的对象,而delete和select的时候大多数使用的是id或者其他合适的条件。Mybatis纯注解方式
@Insert("<script>"
+ "INSERT INTO "
+ "article_topic (id, topic_name, topic_introduce, sort,"
+ "<if test="topicImg !=null "> topic_img,</if> "
+ "<if test="topicThumbnail !=null "> topic_thumbnail,</if> "
+ "status, created, updated)"
+ "VALUES"
+ "(#{id}, #{topicName}, #{topicIntroduce}, #{sort}, "
+ "<if test="topicImg !=null "> #{topicImg},</if> "
+ "<if test="topicThumbnail !=null "> #{topicThumbnail},</if> "
+ "#{status}, #{created}, #{updated})"
+ "</script>")
@Options(useGeneratedKeys = true, keyProperty = "id", keyColumn = "id")
long addTopic(ArticleTopic topic);
上面是Insert语句的情况,在addTopic方法之中,参数是ArticleTopic的对象topic,Update的情况和Insert相同,另外当我们使用SqlProvider的时候,Insert和Update的参数都写在对应的Values和Set的String参数之中,参数和占位符相对应。如下的示例,分别对应为Mapper文件和SqlProvider文件
@InsertProvider(type = ArticleCommentReviewSqlProvider.class, method = "reviewComment")
long reviewComment(@Param("commentReview") ArticleCommentReview commentReview, @Param("id") long id);
@UpdateProvider(type = ArticleCommentReviewSqlProvider.class, method = "reviewCommentAgain")
long reviewCommentAgain(@Param("commentReview") ArticleCommentReview commentReview, @Param("id") long id);
public String reviewComment(@Param("commentReview") ArticleCommentReview commentReview, @Param("id") long id) {
//insert时,cloumn和对应的参数都写在sql.VALUES()之中,参数和占位符一一对应
SQL sql = new SQL();
sql.INSERT_INTO("article_comment_review");
sql.VALUES(
"comment_id, article_id, reviewer_id, review_detail, review_time,"
+ " review_result, created, updated",
"#{commentId}, #{articleId}, #{reviewerId}, #{reviewDetail},#{reviewTime}, "
+ "#{reviewResult}, #{created}, #{updated}");
return sql.toString();
}
public String reviewCommentAgain(@Param("commentReview") ArticleCommentReview commentReview, @Param("id") long id) {
//update时,column和对应的参数都写在sql.SET之中,参数和占位符一一对应
SQL sql = new SQL();
sql.UPDATE("article_comment_review");
sql.SET("review_detail, review_result", "#{reviewDetail}, #{reviewResult}");
sql.WHERE("id= #{id}");
return sql.toString();
}
以上这是在Mapper(DAO层)之中的定义,而在Service层和Controller层,我们还是需要整个完整的参数。
38:SQL分页的问题
A:SQL的分页,我们可以使用limit关键字或者limit&offset两个关键字组合来完成分页的实现,但是使用这两个关键字的时候是有区别的。示例如下:
1️⃣:仅使用limit关键字,limit N:只返回符合条件的前N条
###### sql的数据计算是从0开始的,第1条的下标为0) #####
SELECT * FROM article_topic LIMIT 10; # 符合条件的前10条
SELECT * FROM article_topic WHERE id<100 LIMIT 10; # 符合条件的前10条,这句和上面一句的含义相同
2️⃣:使用limit关键字,limit M , N:跳过M条,返回N条,从第M条开始读取
SELECT * FROM article_topic LIMIT 2,1; # 跳过2条取出1条数据,LIMIT后面是从第2条开始读,读取1条信息,即读取第2条数据,也就是第三条
SELECT * FROM article_topic LIMIT 8,5; # 跳过8条,取出5条,从第8条开始读取
SELECT * FROM article_topic WHERE id<100 LIMIT 8,5;
3️⃣:使用limit&offset关键字,limit M offset N:跳过N条,返回M条,从第N条开始计算
SELECT * FROM article_topic LIMIT 2 OFFSET 1; # 返回2条数据,从第1条开始计算,LIMIT后面跟的是2条数据,OFFSET后面是从第1条开始读取,即读取第2,3条
SELECT * FROM article_topic LIMIT 10 OFFSET 5; # 返回10条数据,从第5条开始计算
其中第2️⃣种和第3️⃣种之间的关系是相反的,最好统一使用第三种: limit M offset N, 返回M条(跳过N条),从第N条开始计算。 sql 中 limit 与 limit,offset连用的区别 , SQL 语句的LIMIT的用法
39:sql语句定义和查询时候的一些问题
A:1️⃣:所有的字段最好不要设置成NULL,可以设置为NOT NULL,为其设置一个默认值,通过DEFAULT xxx
2️⃣:将字段定义为BIGINT,INT等数字的时候,如果其大于0,那么可以加一个UNSIGNED来修饰,这样就不会有小于0的情况,表示无符号,只有我们认为的大于0的情况存在,没有负数的存在了
3️⃣:给字段和表添加注释是一个好习惯COMMENT '创建时间',
4️⃣:在创建数据库的语句之前,最好加上DROP TABLE IF EXISTS xxx表;
5️⃣:在创建SQL的语句之中,所使用的引号都是单引号---'',而不是双引号
6️⃣:为了区别SQL语句和我们创建或者查询的字段,可以把SQL保留字,全部大写,自定义的表明,数据等小写
一个创建表的例子
# article_info
DROP TABLE IF EXISTS article_info;
CREATE TABLE article_info (
id BIGINT(20) UNSIGNED NOT NULL AUTO_INCREMENT COMMENT '主键',
topic_id BIGINT(20) UNSIGNED NOT NULL COMMENT '专题id',
user_id BIGINT(20) UNSIGNED NOT NULL COMMENT '编辑人id',
title VARCHAR(64) NOT NULL COMMENT '标题',
introduce_detail VARCHAR(64) NOT NULL DEFAULT '' COMMENT '推荐词',
author VARCHAR(64) NOT NULL COMMENT '作者',
content TEXT NOT NULL COMMENT '文章内容',
main_img VARCHAR(300) NOT NULL DEFAULT '' COMMENT '主图 url',
thumbnail_img VARCHAR(300) NOT NULL DEFAULT '' COMMENT '缩略图url',
status TINYINT(4) NOT NULL DEFAULT 0 COMMENT '状态(待审核,通过,不通过,发表,下架)',
release_time BIGINT(11) UNSIGNED NOT NULL DEFAULT 0 COMMENT '发表时间',
off_time BIGINT(11) UNSIGNED NOT NULL DEFAULT 0 COMMENT '下架时间',
sort int UNSIGNED NOT NULL DEFAULT 0 COMMENT '排序',
created BIGINT(11) UNSIGNED NOT NULL DEFAULT 0 COMMENT '创建时间',
updated BIGINT(11) UNSIGNED NOT NULL DEFAULT 0 COMMENT '更新时间',
PRIMARY KEY (id),
INDEX idx_article_info_topic_id (topic_id),
INDEX idx_article_info_user_id (user_id)
)DEFAULT CHARSET = utf8 COMMENT = '文章表';
# article_collect
DROP TABLE IF EXISTS article_collect;
CREATE TABLE article_collect (
id BIGINT(20) UNSIGNED NOT NULL AUTO_INCREMENT COMMENT ' 主键',
user_id BIGINT(20) UNSIGNED NOT NULL COMMENT '用户id',
article_id BIGINT(20) UNSIGNED NOT NULL COMMENT '文章id',
created BIGINT(20) UNSIGNED NOT NULL DEFAULT 0 COMMENT '创建时间',
updated BIGINT(20) UNSIGNED NOT NULL DEFAULT 0 COMMENT '更新时间',
PRIMARY KEY (id),
INDEX idx_article_collect_user_id(user_id),
INDEX idx_article_collect_article_id(article_id),
UNIQUE idx_union_unique(user_id,article_id)
)DEFAULT CHARSET = utf8 COMMENT = '文章收藏表';
# article_thumb
DROP TABLE IF EXISTS article_thumb;
CREATE TABLE article_thumb(
id BIGINT(20) UNSIGNED NOT NULL AUTO_INCREMENT COMMENT '主键',
user_id BIGINT(20) UNSIGNED NOT NULL COMMENT '用户id',
article_id BIGINT(20) UNSIGNED NOT NULL COMMENT '文章id',
created BIGINT(11) UNSIGNED DEFAULT 0 COMMENT '创建时间',
updated BIGINT(11) UNSIGNED DEFAULT 0 COMMENT '更新时间',
PRIMARY KEY (id),
INDEX idx_article_thumb_user_id(user_id),
INDEX idx_article_thumb_article_id(article_id)
) DEFAULT CHARSET =utf8 COMMENT = '文章点赞表';
# article_area
DROP TABLE IF EXISTS article_area;
CREATE TABLE article_area (
id BIGINT(20) UNSIGNED NOT NULL AUTO_INCREMENT COMMENT '主键',
area_id BIGINT(20) UNSIGNED NOT NULL COMMENT '地区id',
article_id BIGINT(20) UNSIGNED NOT NULL COMMENT '文章id',
created BIGINT(11) UNSIGNED NOT NULL DEFAULT 0 COMMENT '创建时间',
updated BIGINT(11) UNSIGNED NOT NULL DEFAULT 0 COMMENT '更新时间',
PRIMARY KEY (id),
INDEX idx_article_area_article_id(article_id),
INDEX idx_article_area_area_id(area_id)
)DEFAULT CHARSET =utf8 COMMENT ='文章地区表';
# article_review
DROP TABLE IF EXISTS article_review;
CREATE TABLE article_review(
id BIGINT(20) UNSIGNED NOT NULL AUTO_INCREMENT COMMENT '主键',
article_id BIGINT(20) UNSIGNED NOT NULL COMMENT '文章id',
reviewer_id BIGINT(20) UNSIGNED NOT NULL COMMENT '审核人id',
review_detail VARCHAR(200) NOT NULL DEFAULT '' COMMENT '审核说明',
review_time BIGINT(11) UNSIGNED NOT NULL DEFAULT 0 COMMENT '审核时间',
review_result TINYINT(4) UNSIGNED NOT NULL COMMENT '审核结果',
created BIGINT(11) UNSIGNED NOT NULL DEFAULT 0 COMMENT '创建时间',
updated BIGINT(11) UNSIGNED NOT NULL DEFAULT 0 COMMENT '更新时间',
PRIMARY KEY (id),
INDEX idx_article_area_article_id(article_id)
)DEFAULT CHARSET =utf8 COMMENT ='文章审核表';
# article_topic
DROP TABLE IF EXISTS article_topic;
CREATE TABLE article_topic(
id BIGINT(20) UNSIGNED NOT NULL AUTO_INCREMENT COMMENT '主键',
topic_name VARCHAR(50) NOT NULL COMMENT '专题名',
topic_introduce VARCHAR(200) NOT NULL DEFAULT '' COMMENT '专题简介',
sort int UNSIGNED NOT NULL DEFAULT 0 COMMENT '专题排序',
topic_img VARCHAR(300) NOT NULL DEFAULT '' COMMENT '专题主图片',
topic_thumbnail VARCHAR(300) NOT NULL DEFAULT '' COMMENT '专题缩略图',
status TINYINT(4) NOT NULL COMMENT '专题状态',
created BIGINT(11) UNSIGNED NOT NULL DEFAULT 0 COMMENT '创建时间',
updated BIGINT(11) UNSIGNED NOT NULL DEFAULT 0 COMMENT '更新时间',
PRIMARY KEY (id)
)DEFAULT CHARSET =utf8 COMMENT ='文章主题表';
# article_comment
DROP TABLE IF EXISTS article_comment;
CREATE TABLE article_comment(
id BIGINT(20) UNSIGNED NOT NULL AUTO_INCREMENT COMMENT '主键',
article_id BIGINT(20) UNSIGNED NOT NULL COMMENT '文章id',
user_id BIGINT(20) UNSIGNED NOT NULL COMMENT '用户id',
comment_content VARCHAR(140) NOT NULL COMMENT '评论内容',
sort int NOT NULL DEFAULT 0 COMMENT '排序',
status TINYINT(4) NOT NULL COMMENT '状态(提交,审核通过,不通过',
created BIGINT(11) UNSIGNED NOT NULL DEFAULT 0 COMMENT '创建时间',
updated BIGINT(11) UNSIGNED NOT NULL DEFAULT 0 COMMENT '更新时间',
PRIMARY KEY (id),
INDEX idx_article_comment_article_id(article_id),
INDEX idx_article_comment_user_id(user_id)
)DEFAULT CHARSET =utf8 COMMENT ='文章评论表';
# article_comment_thumb
DROP TABLE IF EXISTS article_comment_thumb;
CREATE TABLE article_comment_thumb(
id BIGINT(20) UNSIGNED NOT NULL AUTO_INCREMENT COMMENT '主键',
comment_id BIGINT(20) UNSIGNED NOT NULL COMMENT '评论id',
user_id BIGINT(20) UNSIGNED NOT NULL COMMENT '用户id',
created BIGINT(11) UNSIGNED NOT NULL DEFAULT 0 COMMENT '创建时间',
updated BIGINT(11) UNSIGNED NOT NULL DEFAULT 0 COMMENT '更新时间',
PRIMARY KEY (id),
INDEX idx_article_comment_thumb_user_id(user_id),
INDEX idx_article_comment_thumb_comment_id(comment_id)
)DEFAULT CHARSET =utf8 COMMENT ='文章评论点赞表';
# article_comment_review
DROP TABLE IF EXISTS article_comment_review;
CREATE TABLE article_comment_review(
id BIGINT(20) UNSIGNED NOT NULL AUTO_INCREMENT COMMENT '主键',
comment_id BIGINT(20) UNSIGNED NOT NULL COMMENT '评论id',
article_id BIGINT(20) UNSIGNED NOT NULL COMMENT '文章id',
reviewer_id BIGINT(20) UNSIGNED NOT NULL COMMENT '审核人id',
review_detail VARCHAR(200) NOT NULL DEFAULT '' COMMENT '审核说明',
review_time BIGINT(11) NOT NULL DEFAULT 0 COMMENT '审核时间',
review_result TINYINT(4) NOT NULL COMMENT '审核结果',
created BIGINT(11) UNSIGNED NOT NULL DEFAULT 0 COMMENT '创建时间',
updated BIGINT(11) UNSIGNED NOT NULL DEFAULT 0 COMMENT '更新时间',
PRIMARY KEY (id),
INDEX idx_article_comment_review_reviewer_id(reviewer_id)
)DEFAULT CHARSET =utf8 COMMENT ='文章评论审核表';
39:MySQL字段的疑惑
A:mysql之中的bigint长度为8个字节,int为4个字节,tinyint为1个字节,不同类型的int决定了存储的占用的字节数量,而经常使用的tinyint(M):M默认为4,SMALLINT(M):M默认为6,MEDIUMINT(M):M默认为9,INT(M):M默认为11,BIGINT(M):M默认为20。**M表示最大显示宽度,建表若设置了zerofill(0填充),会在数字前面补充0 **。
他山之石:
不是我们有这种限制,所有的建表都要加上这个限制 这个含义和入参检查是一样的,不是可以保存多大的值就保存多大的值,要从逻辑入手,性别就1位,身份证就17位,手机号就11位。
40:MVC模式在何处进行数据校验
A:一般java web的项目分为domain, dao, service, controller等层,数据的校验和参数传递集中在controller和service两个地方,具有较大的可选性,有两种方式,1️⃣一种是在service之中获取基本数据,取得需要的基本数据,在controller层之中进行数据合法性的校验,然后在此处,将所有的数据统一处理,打包成需要的格式,传送给前端;2️⃣第二种是在service层之中将所有的数据都验证,整合,将其传送给controller层,controller只是做一个url转发的层。这两种方式在实际上都是可以的,但是由于第2️⃣种方式要讲数据多传送一次,而在service层之中整个合法性校验,数据的整合,然后又传送给controller层,这样操作比较浪费,所以第1️⃣种方式好,service层提供基本的数据,在controller层之中校验,组装数据,转发请求等。
41:Java EE需要掌握的技术
- [ ] Spring(core/ mvc/boot)
- [ ] mybatis(hibernate)
- [ ] nosql(redis/mongodb)
- [ ] RabbitMQ
- [ ] RPC(Dubbo)
- [ ] Zookeeper
- [ ] 配置工具(maven/Apollo)
- [ ] linux(命令行操作)
42:intellij idea 运行 tomcat,无法进入断点的问题解决方法
A:这是因为JMX port被占用而出现的问题,解决方法,1️⃣:重启机器,2️⃣:使用netstat -aon|findstr 1099 找出来1099端口占用的进程,然后通过taskkill -f -pid 3756 杀掉进程,重新运行,即可。其实和无法启动tomcat服务器的原因是一样的。启动tomcat时jmx port被占用,intellij idea 运行 tomcat,无法进入断点的问题解决方法

43:RPC与RMI的介绍
A:RPC(Remote Procedure Call Protocol)远程过程调用协议,通过网络从远程计算机上请求调用某种服务。RMI是远程方法调用(Remote Method Invocation)。能够让在客户端Java虚拟机上的对象像调用本地对象一样调用服务端java 虚拟机中的对象上的方法。 RMI中是通过在客户端的Stub对象作为远程接口进行远程方法的调用。每个远程方法都具有方法签名。如果一个方法在服务器上执行,但是没有相匹配的签名被添加到这个远程接口(stub)上,那么这个新方法就不能被RMI客户方所调用。 RPC中是通过网络服务协议向远程主机发送请求,请求包含了一个参数集和一个文本值,通常形成“classname.methodname(参数集)”的形式。RPC远程主机就去搜索与之相匹配的类和方法,找到后就执行方法并把结果编码,通过网络协议发回。 RMI只用于Java;RPC是网络服务协议,与操作系统和语言无关。
44:Spring配置多个数据源,如何使用?
A:Spring配置多个数据源的时候,启用他需要使用包扫描,意思就是在特定的包下面使用某一个特定的数据源,在这个包下的操作,就是用这些对应的数据源。注意:需要单独把相关的dao创建一个包,放在原先的dao下面会被覆盖,从而导致无法取到数据源的连接。另外,需要在工程的配置文件之中添加上多个数据源的连接基本信息,方可操作。
@Configuration
@ConfigurationProperties(prefix = "redpacket.datasource")
@MapperScan(basePackages = "com.yjf.redpacketdao", sqlSessionFactoryRef = "redpacketSession")
@EnableTransactionManagement
public class RedPacketDataConfiguration {
//单独把相关的dao创建一个包,放在原先的dao下面会被覆盖,原先的包为com.yjf.dao
private static final String DATA_SOURCE = "redpacket_ds";
@Value("${redpacket.datasource.mapUnderscoreToCamelCase}")
private Boolean mapUnderscoreToCamelCase;
@Bean("redpacketSession")
public SqlSessionFactory getSqlSessionFactory(@Qualifier(DATA_SOURCE) DataSource ds) throws Exception {
SqlSessionFactoryBean bean = new SqlSessionFactoryBean();
bean.setDataSource(ds);
org.apache.ibatis.session.Configuration configuration = new org.apache.ibatis.session.Configuration();
configuration.setMapUnderscoreToCamelCase(mapUnderscoreToCamelCase);
bean.setConfiguration(configuration);
return bean.getObject();
}
@Bean(name = DATA_SOURCE)
@ConfigurationProperties(prefix = "redpacket.datasource")
public DataSource dataSourceRedpacket() {
return DruidDataSourceBuilder.create().build();
}
@Bean
public DataSourceTransactionManager redPacketTransactionManager(@Qualifier(DATA_SOURCE) DataSource ds) {
return new DataSourceTransactionManager(ds);
}
}
45:把sql的嵌套查询拆开,应该怎么做?
A:在开发之中,SQL层(Mapper层的查询),可能经常会遇到多个sql嵌套查询的情况,这样的时候,很容易出现Mapper层的耦合,处理这些耦合,就需要把复杂嵌套的sql语句拆分成单独的简单的sql,然后在service层之中处理等否,关联等关系,这样可以有效减少SQL语句的耦合,让复杂的SQL变得清晰简单。
46:写Mybatis的Mapper文件时候,sql的注意问题?
A:有时候,写Mapper文件的时候,有时候会有把sql语句都写在一起,在写<script>包裹起来的语句,在每一行的sql语句后面,最好后面留一个空格,防止SQL语句拼接连在一起,出现问题。
@Select("<script>"
+ "SELECT "
+ "id, create_date, ali_user_id, balance, identity_number, is_enabled, is_locked, mobile, name, "
+ "phone, wx_open_id, member_rank, sinopec_station, real_name, area, "
+ "FROM member "
+ "WHERE is_enabled = 1 and is_locked = 0 "
+ "</script>")
List<Member> getMemberList();
@Select("<script>"
+ "SELECT "
+ "id, create_date, ali_user_id, balance, identity_number, is_enabled, is_locked, mobile, name, "
+ "phone, wx_open_id, member_rank, sinopec_station, real_name, area, "
+ "FROM member "
+ "WHERE id= #{id}"
+ "</script>")
Member getUserById(@Param("id") Long id);
47:需要的数据是从多个表之中获取,该如何处理?
A:首先我们通过查询语句,将需要的信息,提取出来,此时我们得到了多种信息,然后接下来,我们可以创建一个新的domain,里面的字段刚好是所需信息的全部字段,然后使用Mapper查询出来我们要的信息后,在Service层将信息组合,整合出来我们想要的信息,比如,Student表和Book表,student(id, name, age, gender, grade, class, school),book(id, book_name, book_price, book_author, book_detail, book_time, book_type)。如果我们想知道学生喜欢的书籍的类型和出版时间,那么可以新建新的domain,student_book(id, name, age, gender, book_name, book_detail, book_time, book_type),将其组合成一个新的domain, 这样处理将会方便很多。
ref:
1.IDEA 图标介绍。 缓存和索引介绍、清理方法和Debug使用, 2.使用 mybatis 到底要不要写一对多、一对一关联, 3.Log4j的配置, 4.log4j的使用--IDEA创建maven项目, 5.mybatis 详解(五)------动态SQL, 6.MyBatis——动态SQL讲解, 7.MyBatis注解Annotation介绍及Demo, 8.spring boot(8)-mybatis三种动态sql, 9.mybatis @Select注解中如何拼写动态sql, 10.MySQL bigint(20)是什么意思?, 11.详解mysql int类型的长度值问题, 12.Java RMI与RPC的区别, 13.Mybatis纯注解方式, 14. sql 中 limit 与 limit,offset连用的区别 , 15.SQL 语句的LIMIT的用法