【GiantPandaCV导语】调研分类方法的时候师姐推荐的一篇paper,其核心是训练的时候使用小分辨率,测试的时候使用大分辨率(训练分辨率的1.15倍),能够有效提升验证精度。
Motivation
ImageNet数据集分类模型通常采用的数据增强方式会导致训练时和测试时的模型看到的目标尺寸出现差异。即训练分辨率的降低可以一定程度上提高测试阶段的精度。
举个例子:

图一:原先的ImageNet训练方法
上图代表训练阶段图片处理流程:训练阶段主要通过随即选择一块矩形区域,然后resize到224固定大小,这样训练得到的尺度可能是上图右侧对应的。
下图代表测试阶段图片处理流程:图片直接resize到固定范围256x256, 然后从中间crop一个224x224大小的图片。
通过上图就可以看出,训练过程中模型看到的图片与测试的时候看到的分类区域 (Region of Classification)是不一样的:训练过程看到的目标更大,测试过程看到的目标更小 。这可能导致训练过程学到的分布并不能非常好的应用到测试过程中,本文致力于解决这个问题。
根据以上简单的观察提出了一种策略,使得模型在训练和测试过程中使用不同的分辨率 ,然后在高分辨率上进行微调 。
方法简单但效果惊人:可以将ResNet50从77.1%提升至79.8%!
Fixing Resolution方法
简单表述实现方案(不关心原理的看到这里就可以了):
-
缩小训练过程的分辨率,变为原分辨率/1.15,进行普通的训练过程。 以下图为例训练分辨率为128。
-
测试过程使用更大分辨率的图片进行测试。以下图为例测试分辨率为384。
-
想进一步提高准确率,可以固定FC层的参数并在高分辨率384下进行微调少量epoch。
训练过程采用的增强:
transforms.RandomResizedCrop(224, scale=(0.08, 1.0), ratio=(0.75, 1.33)),
transforms.RandomHorizontalFlip()
测试过程采用的增强:
transforms.Resize(256)
transforms.CenterCrop(224)
以上就是操作方法,那么不看推导,仅凭直觉,为何这种想法能work呢?
-
训练集增强使用随机Crop,如果crop的分辨率比较高,就如图一所示,训练过程中看到的马目标更大。测试过程中采用CenterCrop,如果保持相同分辨率,图片中马的目标就比较小。
-
从感受野的角度理解,假如我们想要分类马,那么模型的感受野会自动调整,转向训练集中比较大的目标。测试的过程中遇到更小的目标,可能并不会识别的很好。(最优的情况是理论感受野=目标大小)
-
如图二所示,本文提出训练过程中使用小分辨率,提升测试过程的分辨率,这个时候可以看出这两匹马的大小是差不多大的。
-
总体的直觉是:
-
训练使用更小分辨率,模型在训练过程中看到的RoC与原先相比会变小。
-
测试使用更大的分辨率,模型在测试过程中看到的RoC与原先相比会大。
-
正好和Motivation中的 训练过程看到的目标更大,测试过程看到的目标更小 的观察相反,从而保证了训练和测试过程的RoC尽可能一致。
-

图二:本文提出的数据增强方法
可以看出整个过程可以通过推导得到,论文中也进行了推导,具体内容可以查看原论文,这里只给出最终结论:在使用默认RandomResizedCrop参数情况下,即scale=(0.08, 1.0), ratio=(0.75, 1.33),放大倍数应该为:
举例:以ImageNet中数据增强为例:测试过程分辨率应为训练过程分辨率的=$1 / (0.7\times \frac{256}{224}) = 1.25
$倍。
增大的分辨率倍数确定好了之后,为了更有效提升测试精度,可以选择调整spatial pooling之后的数据分布,即对FC层进行微调,令模型更加适应新的分辨率。
实验部分
在ImageNet数据集上使用224进行训练,然后再各种分辨率上进行测试:

可以发现:随着验证集分辨率的增加,准确率先增后降
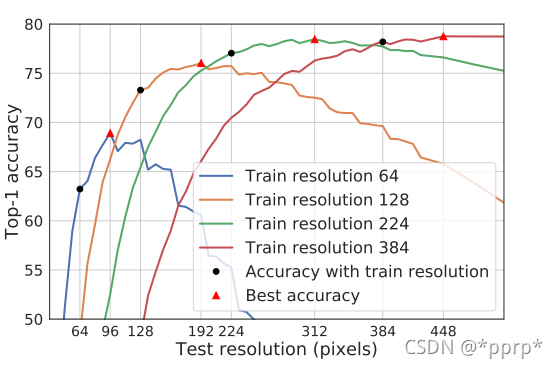
上图展示了训练分辨率、测试分辨率对精度的影响。可以明显发现,黑色点是低于红色三角的,验证了本文的观点:训练过程中分辨率应低于测试过程分辨率。
与SOTA方法的比较:

PS: paddleClas中也对论文中方法进行了实现,详见:https://github.com/PaddlePaddle/PaddleClas
参考文献
https://arxiv.org/abs/2003.08237
[https://www.cnblogs.com/shuimuqingyang/p/14337918.html](https://www.cnblogs.com/shuimuqingyang/p/14337918.html#:~:text=FixRes是Facebook在19年提出的一个应用于图像分类的简单优化策略,论文名是Fixing the train-test,resolution discrepancy,在这篇论文中作者发现了在ImageNet数据集上的分类模型中常采用的数据增强会导致训练和测试时的物体分辨率(resolution)不一致,继而提出FixRes策略来改善这个问题: 常规训练后再采用更大的分辨率对模型的classifier或最后的几层layers进行finetune 。)