本文主要讲解Deep SORT论文核心内容,包括状态估计、匹配方法、级联匹配、表观模型等核心内容。
1. 简介
Simple Online and Realtime Tracking(SORT)是一个非常简单、有效、实用的多目标跟踪算法。在SORT中,仅仅通过IOU来进行匹配虽然速度非常快,但是ID switch依然非常大。
本文提出了Deep SORT算法,相比SORT,通过集成表观信息来提升SORT的表现。通过这个扩展,模型能够更好地处理目标被长时间遮挡的情况,将ID switch指标降低了45%。表观信息也就是目标对应的特征,论文中通过在大型行人重识别数据集上训练得到的深度关联度量来提取表观特征(借用了ReID领域的模型)。
2. 方法
2.1 状态估计
延续SORT算法使用8维的状态空间((u,v,r,h,dot{x},dot{y},dot{r},dot{h})),其中(u,v)代表bbox的中心点,宽高比r, 高h以及对应的在图像坐标上的相对速度。
论文使用具有等速运动和线性观测模型的标准卡尔曼滤波器,将以上8维状态作为物体状态的直接观测模型。
每一个轨迹,都计算当前帧距上次匹配成功帧的差值,代码中对应time_since_update变量。该变量在卡尔曼滤波器predict的时候递增,在轨迹和detection关联的时候重置为0。
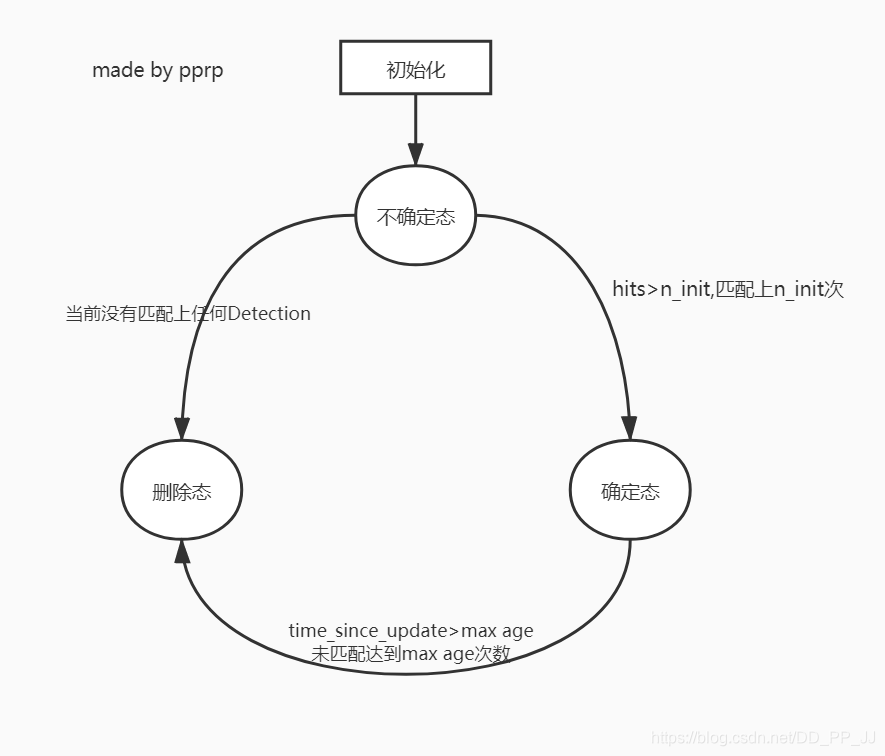
超过最大年龄(A_{max})的轨迹被认为离开图片区域,将从轨迹集合中删除,被设置为删除状态。代码中最大年龄默认值为70,是级联匹配中的循环次数。
如果detection没有和现有track匹配上的,那么将对这个detection进行初始化,转变为新的Track。新的Track初始化的时候的状态是未确定态,只有满足连续三帧都成功匹配,才能将未确定态转化为确定态。
如果处于未确定态的Track没有在n_init帧中匹配上detection,将变为删除态,从轨迹集合中删除。
2.2 匹配问题
Assignment Problem指派或者匹配问题,在这里主要是匹配轨迹Track和观测结果Detection。这种匹配问题经常是使用匈牙利算法(或者KM算法)来解决,该算法求解对象是一个代价矩阵,所以首先讨论一下如何求代价矩阵:
- 使用平方马氏距离来度量Track和Detection之间的距离,由于两者使用的是高斯分布来进行表示的,很适合使用马氏距离来度量两个分布之间的距离。马氏距离又称为协方差距离,是一种有效计算两个未知样本集相似度的方法,所以在这里度量Track和Detection的匹配程度。
(d_j)代表第j个detection,(y_i)代表第i个track,(S_i^{-1})代表d和y的协方差。
第二个公式是一个指示器,比较的是马氏距离和卡方分布的阈值,(t^{(1)})=9.4877,如果马氏距离小于该阈值,代表成功匹配。
- 使用cosine距离来度量表观特征之间的距离,reid模型抽出得到一个128维的向量,使用余弦距离来进行比对:
(r_j^Tr_k^{(i)})计算的是余弦相似度,而余弦距离=1-余弦相似度,通过cosine距离来度量track的表观特征和detection对应的表观特征,来更加准确地预测ID。SORT中仅仅用运动信息进行匹配会导致ID Switch比较严重,引入外观模型+级联匹配可以缓解这个问题。
同上,余弦距离这部分也使用了一个指示器,如果余弦距离小于(t^{(2)}),则认为匹配上。这个阈值在代码中被设置为0.2(由参数max_dist控制),这个属于超参数,在人脸识别中一般设置为0.6。
- 综合匹配度是通过运动模型和外观模型的加权得到的
其中(lambda)是一个超参数,在代码中默认为0。作者认为在摄像头有实质性移动的时候这样设置比较合适,也就是在关联矩阵中只使用外观模型进行计算。但并不是说马氏距离在Deep SORT中毫无用处,马氏距离会对外观模型得到的距离矩阵进行限制,忽视掉明显不可行的分配。
(b_{i,j})也是指示器,只有(b_{i,j}=1)的时候才会被人为初步匹配上。
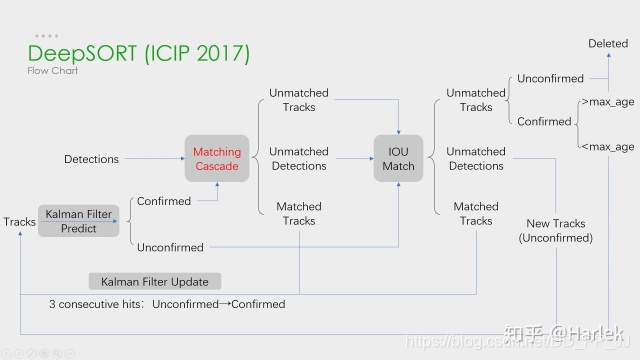
2.3 级联匹配
级联匹配是Deep SORT区别于SORT的一个核心算法,致力于解决目标被长时间遮挡的情况。为了让当前Detection匹配上当前时刻较近的Track,匹配的时候Detection优先匹配消失时间较短的Track。
当目标被长时间遮挡,之后卡尔曼滤波预测结果将增加非常大的不确定性(因为在被遮挡这段时间没有观测对象来调整,所以不确定性会增加), 状态空间内的可观察性就会大大降低。
在两个Track竞争同一个Detection的时候,消失时间更长的Track往往匹配得到的马氏距离更小, 使得Detection更可能和遮挡时间较长的Track相关联,这种情况会破坏一个Track的持续性,这也就是SORT中ID Switch太高的原因之一。
所以论文提出级联匹配:

伪代码中需要注意的是匹配顺序,优先匹配age比较小的轨迹,对应实现如下:
# 1. 分配track_indices和detection_indices
if track_indices is None:
track_indices = list(range(len(tracks)))
if detection_indices is None:
detection_indices = list(range(len(detections)))
unmatched_detections = detection_indices
matches = []
# cascade depth = max age 默认为70
for level in range(cascade_depth):
if len(unmatched_detections) == 0: # No detections left
break
track_indices_l = [
k for k in track_indices
if tracks[k].time_since_update == 1 + level
]
if len(track_indices_l) == 0: # Nothing to match at this level
continue
# 2. 级联匹配核心内容就是这个函数
matches_l, _, unmatched_detections =
min_cost_matching( # max_distance=0.2
distance_metric, max_distance, tracks, detections,
track_indices_l, unmatched_detections)
matches += matches_l
unmatched_tracks = list(set(track_indices) - set(k for k, _ in matches))
return matches, unmatched_tracks, unmatched_detections
在匹配的最后阶段还对unconfirmed和age=1的未匹配轨迹进行基于IOU的匹配(和SORT一致)。这可以缓解因为表观突变或者部分遮挡导致的较大变化。
2.4 表观特征
表观特征这部分借用了行人重识别领域的网络模型,这部分的网络是需要提前离线学习好,其功能是提取出具有区分度的特征。
论文中用的是wide residual network, 具体结构如下图所示:
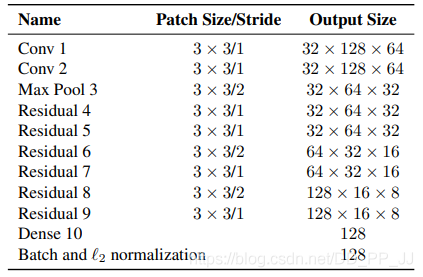
网络最后的输出是一个128维的向量用于代表该部分表观特征(一般维度越高区分度越高带来的计算量越大)。最后使用了L2归一化来将特征映射到单位超球面上,以便进一步使用余弦表观来度量相似度。
3. 实验
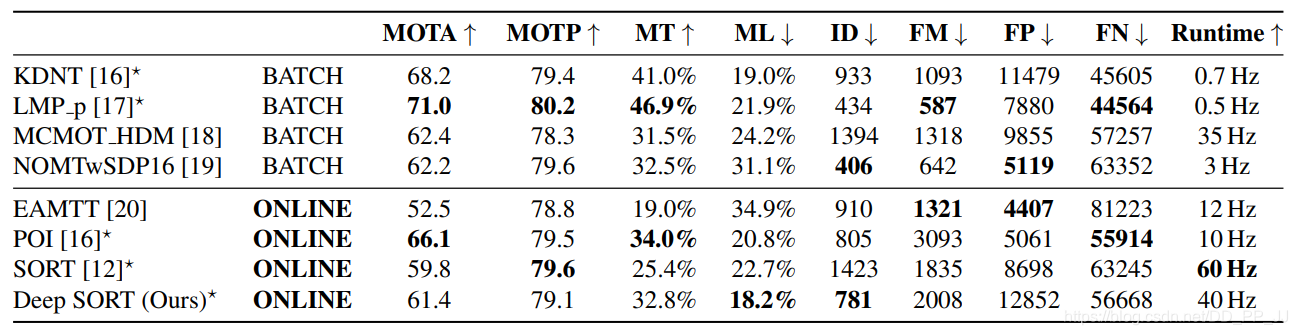
选用MOTA、MOTP、MT、ML、FN、ID swiches、FM等指标进行评估模型。
相比SORT, Deep SORT的ID Switch指标下降了45%,达到了当时的SOTA。
经过实验,发现Deep SORT的MOTA、MOTP、MT、ML、FN指标对于之前都有提升。
FP很多,主要是由于Detection和Max age过大导致的。
速度达到了20Hz,其中一半时间都花费在表观特征提取。
4. 总结
Deep SORT可以看成三部分:
- 检测: 目标检测的效果对结果影响非常非常大, 并且Recall和Precision都应该很高才可以满足要求. 据笔者测试, 如果使用yolov3作为目标检测器, 目标跟踪过程中大概60%的时间都花费在yolov3上,并且场景中的目标越多,这部分耗时也越多(NMS花费的时间).
- 表观特征: 也就是reid模型,原论文中用的是wide residual network,含有的参数量比较大,可以考虑用新的、性能更好、参数量更低的ReID模型来完成这部分工作。笔者看到好多人推荐使用OSNet,但是实际使用的效果并不是特别好。
- 关联:包括卡尔曼滤波算法和匈牙利算法。
改进空间:
最近非常多优秀的工作的思路是认为reid这部分特征提取和目标检测网络无法特征重用,所以想将这两部分融合到一块。
JDE=YOLOv3和reid融合
FairMOT=CenterNet和reid融合
最近看了CenterNet,感觉这种无需anchor来匹配的方式非常优雅,所以非常推荐FairMOT,效果非常出色,适合作为研究的baseline。
5. 参考
距离: https://blog.csdn.net/Kevin_cc98/article/details/73742037
论文地址:https://arxiv.org/pdf/1703.07402.pdf
代码地址:https://github.com/nwojke/deep_SORT
FairMOT: https://github.com/ifzhang/FairMOT