1. Dropout
如果模型参数过多,而训练样本过少,容易陷入过拟合。过拟合的表现主要是:在训练数据集上loss比较小,准确率比较高,但是在测试数据上loss比较大,准确率比较低。Dropout可以比较有效地缓解模型的过拟合问题,起到正则化的作用。
Dropout,中文是随机失活,是一个简单又机器有效的正则化方法,可以和L1正则化、L2正则化和最大范数约束等方法互为补充。
在训练过程中,Dropout的实现是让神经元以超参数 (p) 的概率停止工作或者激活被置为0,
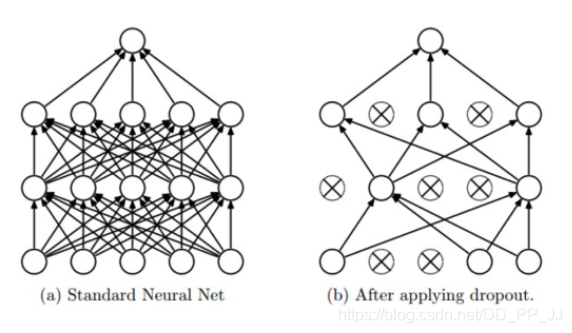
在训练过程中,Dropout会随机失活,可以被认为是对完整的神经网络的一些子集进行训练,每次基于输入数据只更新子网络的参数。

在测试过程中,不进行随机失活,而是将Dropout的参数p乘以输出。
再来看Dropout论文中涉及到的一些实验:
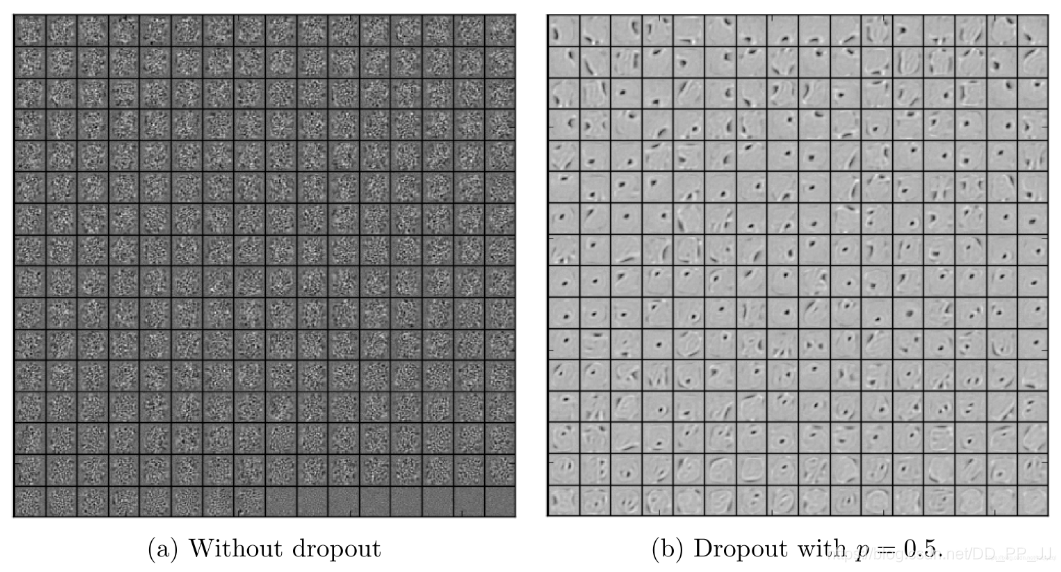
上图是作者在MNIST数据集上进行的Dropout实验,可以看到Dropout可以破坏隐藏层单元之间的协同适应性,使得在使用Dropout后的神经网络提取的特征更加明确,增加了模型的泛化能力。
另外可以从神经元之间的关系来解释Dropout,使用Dropout能够随机让一些神经元临时不参与计算,这样的条件下可以减少神经元之间的依赖,权值的更新不再依赖固有关系的隐含节点的共同作用,这样会迫使网络去学习更加鲁棒的特征。
再看一组实验,在隐藏层神经元数目不变的情况下,调节参数p,观察对训练集和测试集上效果的影响。
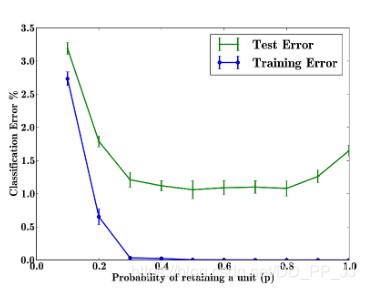
以上实验是对MNIST数据集进行的实验,随着p的增加, 测试误差先降后升,p在[0.4, 0.8]之间的时候效果最好,通常p默认值会被设为0.5。
还有一组实验是通过调整数据集判断Dropout对模型的影响:
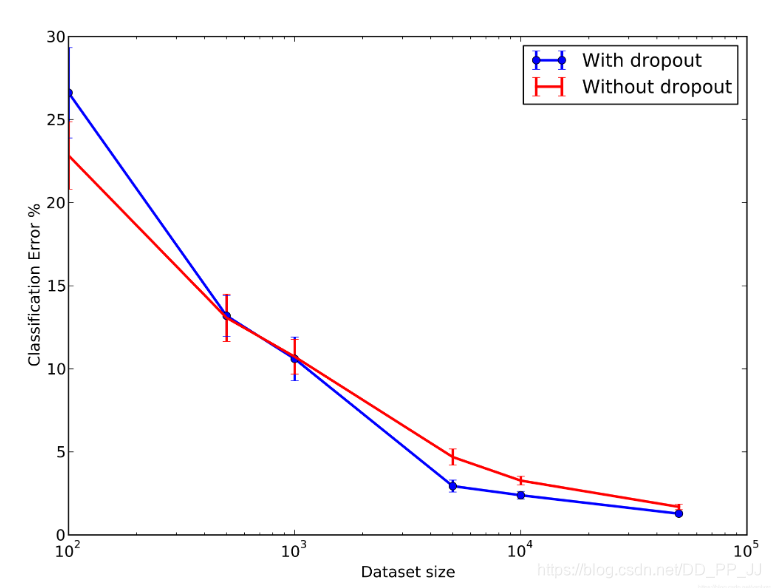
在数据量比较少的时候,Dropout并没有给模型带来性能上的提升,但是在数据量变大的时候,Dropout则会带来比较明显的提升,这说明Dropout有一定正则化的作用,可以防止模型过拟合。
在pytorch中对应的Dropout实现如下:
>>> m = nn.Dropout(p=0.2)
>>> input = torch.randn(20, 16)
>>> output = m(input)
torch.nn.Dropout(p=0.5, inplace=False)
- p – probability of an element to be zeroed. Default: 0.5
- inplace – If set to
True, will do this operation in-place. Default:False
对input没有任何要求,也就是说Linear可以,卷积层也可以。
2. Spatial Dropout
普通的Dropout会将部分元素失活,而Spatial Dropout则是随机将部分区域失失活, 这部分参考参考文献中的【2】,简单理解就是通道随机失活。一般很少用普通的Dropout来处理卷积层,这样效果往往不会很理想,原因可能是卷积层的激活是空间上关联的,使用Dropout以后信息仍然能够通过卷积网络传输。而Spatial Dropout直接随机选取feature map中的channel进行dropout,可以让channel之间减少互相的依赖关系。
在pytorch中对应Spatial Dropout实现如下:
torch.nn.Dropout2d(p=0.5, inplace=False)
- p (python:float**, optional) – probability of an element to be zero-ed.
- inplace (bool**, optional) – If set to
True, will do this operation in-place
对输入输出有一定要求:
- input shape: (N, C, H, W)
- output shape: (N, C, H, W)
>>> m = nn.Dropout2d(p=0.2)
>>> input = torch.randn(20, 16, 32, 32)
>>> output = m(input)
此外对3D feature map中也有对应的torch.nn.Dropout3d函数,和以上使用方法除输入输出为(N, C, D, H, W)以外,其他均相同。
3. Stochastic Depth
在DenseNet之前提出,随机将ResNet中的一部分Res Block失活,实际操作和Dropout也很类似。在训练的过程中任意丢失一些Block, 在测试的过程中使用所有的block。使用这种方式, 在训练时使用较浅的深度(随机在resnet的基础上跳过一些层),在测试时使用较深的深度,较少训练时间,提高训练性能,最终在四个数据集上都超过了ResNet原有的性能(cifar-10, cifar-100, SVHN, imageNet)
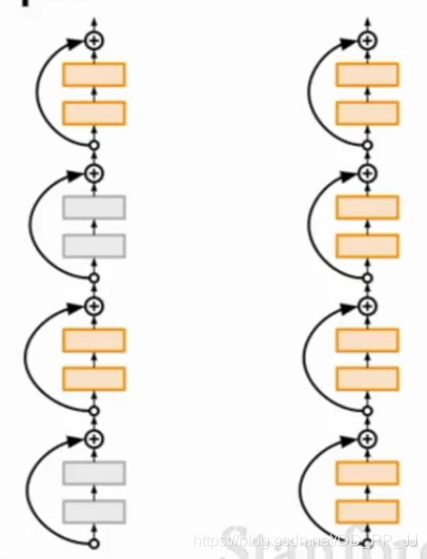
详解请看卷积神经网络学习路线(十一)| Stochastic Depth(随机深度网络)
4. DropBlock
一句话概括就是: 在每个feature map上按spatial块随机设置失活。
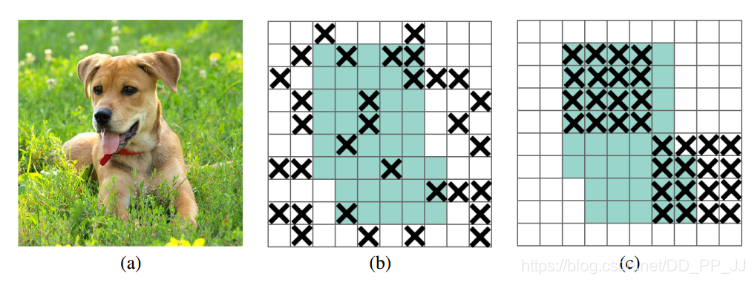
Dropout对卷积层的效果没那么好(见图(b))。文章认为是由于每个feature map中的点都对应一个感受野范围,仅仅对单个像素位置进行Dropout并不能降低feature map学习的特征范围,网络依然可以通过失活位置相邻元素学习对应的语义信息。所以作者提出一块一块的失活(见图(c)), 这种操作就是DropBlock.
DropBlock有三个重要的参数:
- block size控制block的大小
- γ 控制有多少个channel要进行DropBlock
- keep prob类别Dropout中的p,以一定的概率失活
经过实验,可以证明block size控制大小最好在7x7, keep prob在整个训练过程中从1逐渐衰减到指定阈值比较好。
5. Cutout
Cutout和DropBlock非常相似,也是一个非常简单的正则化手段,下图是论文中对CIFAR10数据集进行的处理,移除输入图片中的一块连续区域。

此外作者也针对移除块的大小影响进行了实验,如下图:
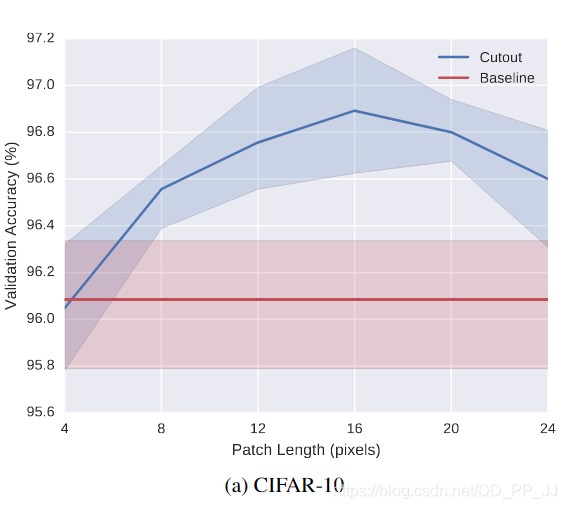
可以看出,对CIFAR-10数据集来说,随着patch length的增加,准确率是先升后降。
可见在使用了Cutout后可以提高神经网络的鲁棒性和整体性能,并且这种方法还可以和其他正则化方法配合使用。不过如何选取合适的Patch和数据集有非常强的相关关系,如果想用Cutout进行实验,需要针对Patch Length做一些实验。
扩展:最新出的一篇Attentive CutMix中的有一个图很吸引人。作者知乎亲自答: https://zhuanlan.zhihu.com/p/122296738

Attentive CutMix具体做法如下如所示: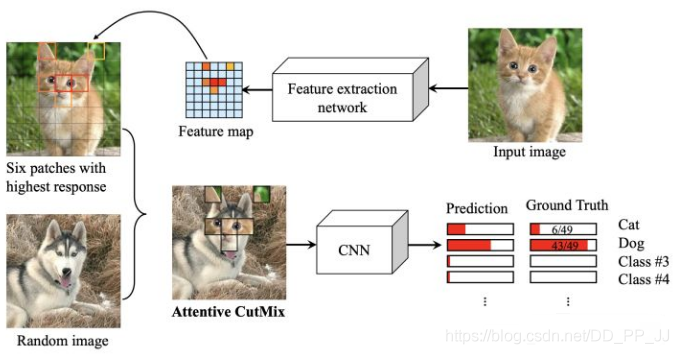
将原图划分为7x7的格子,然后通过一个小的网络得到热图,然后计算49个格子中top N个置信度最高的格子, 从输入图片中将这些网格对应的区域裁剪下来,覆盖到另一张待融合的图片上,用于训练神经网络。Ground Truth 的Label 也会根据融合的图片的类别和剪切的区域的大小比例而相应修改。至于上图猫和狗面部的重合应该是一个巧合。
6. DropConnect
DropConnect也是Dropout的衍生品,两者相似处在于都是对全连接层进行处理(DropConnect只能用于全连接层而Dropout可以用于全连接层和卷积层),两者主要差别在于:
-
Dropout是对激活的activation进行处理,将一些激活随机失活,从而让神经元学到更加独立的特征,增加了网络的鲁棒性。
-
DropConnect则是对链接矩阵的处理,具体对比可以看下图。
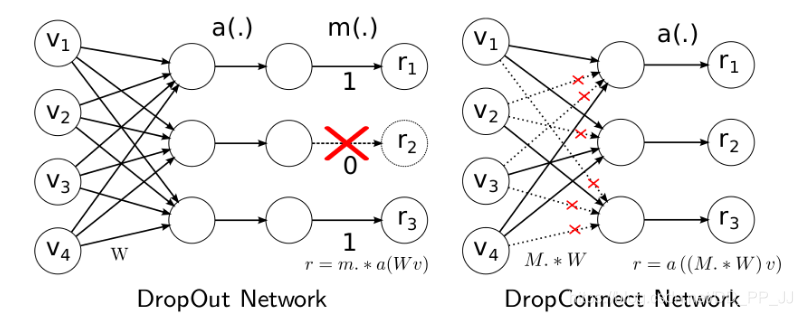
DropConnect训练的时候和Dropout很相似,是随机采样一个矩阵M作为Mask 矩阵(值为0或者1),然后施加到W上。
7. 总结
本文属于一篇的科普文,其中有很多细节、公式还需要去论文中仔细品读。
在CS231N课程中,讲到Dropout的时候引申出来了非常多的这种类似的思想,其核心就是减少神经元互相的依赖,从而提升模型鲁棒性。和Dropout的改进非常相似的有Batch Normalization的一系列改进(这部分启发自知乎@mileistone):
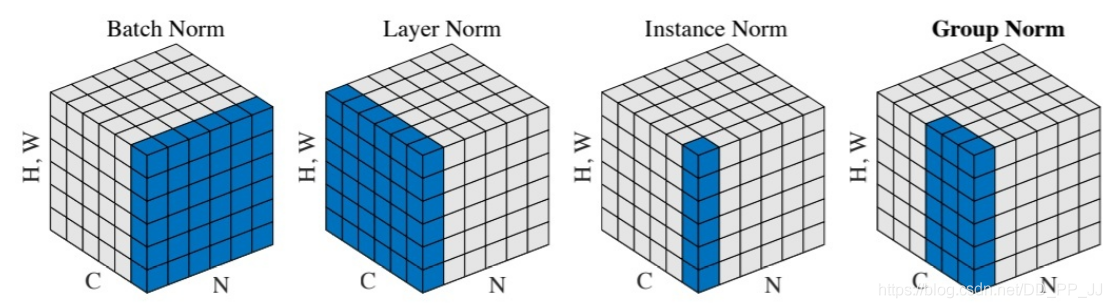
一个feature map的shape为[N, C, H, W]
- Batch Norm是从NHW三个维度进行归一化
- Layer Norm是从CHW三个维度进行归一化
- Instance Norm是从HW两个维度进行归一化
- Group Nrom是从(C_{part}HW)上做归一化,将C分为几个独立的部分。
与之类似的Drop系列操作(shape=[N, C, H, W]):
- Dropout是将NCHW中所有的特征进行随机失活,以像素为单位。
- Spatial Dropout是随机将CHW的特征进行随机失活,以channel为单位。
- DropBlock是随机将(C[HW]_{part})的特征进行随机失活,以HW中一部分为单位。
- Stochastic Depth是随机跳过一个Res Block, 单位更大。
8. 参考文献
【1】 Dropout: A simple way to prevent neural networks from overfitting
【2】 Efficient object localization using convolutional networks.
【3】 Deep networks with stochastic depth.
【4】 DropBlock: A regularization method for convolutional networks.
【5】 Improved regularization of convolutional neural networks with cutout
【6】 Regularization of Neural Network using DropConnect
【7】Attentive CutMix: https://arxiv.org/pdf/2003.13048.pdf