前言: 这是CV中的Attention机制专栏的第一篇博客,并没有挑选实现起来最简单的SENet作为例子,而是使用了CBAM作为第一个讲解的模块,这是由于其使用的广泛性以及易于集成。目前cv领域借鉴了nlp领域的attention机制以后生产出了很多有用的基于attention机制的论文,attention机制也是在2019年论文中非常火。这篇cbam虽然是在2018年提出的,但是其影响力比较深远,在很多领域都用到了该模块,所以一起来看一下这个模块有什么独到之处,并学着实现它。
1. 什么是注意力机制?
注意力机制(Attention Mechanism)是机器学习中的一种数据处理方法,广泛应用在自然语言处理、图像识别及语音识别等各种不同类型的机器学习任务中。
通俗来讲:注意力机制就是希望网络能够自动学出来图片或者文字序列中的需要注意的地方。比如人眼在看一幅画的时候,不会将注意力平等地分配给画中的所有像素,而是将更多注意力分配给人们关注的地方。
从实现的角度来讲:注意力机制通过神经网络的操作生成一个掩码mask, mask上的值一个打分,评价当前需要关注的点的评分。
注意力机制可以分为:
- 通道注意力机制:对通道生成掩码mask,进行打分,代表是senet, Channel Attention Module
- 空间注意力机制:对空间进行掩码的生成,进行打分,代表是Spatial Attention Module
- 混合域注意力机制:同时对通道注意力和空间注意力进行评价打分,代表的有BAM, CBAM
2. 怎么实现CBAM?(pytorch为例)
CBAM arxiv link: https://arxiv.org/pdf/1807.06521.pdf
CBAM全称是Convolutional Block Attention Module, 是在ECCV2018上发表的注意力机制代表作之一。本人在打比赛的时候遇见过有人使用过该模块取得了第一名的好成绩,证明了其有效性。
在该论文中,作者研究了网络架构中的注意力,注意力不仅要告诉我们重点关注哪里,还要提高关注点的表示。 目标是通过使用注意机制来增加表现力,关注重要特征并抑制不必要的特征。为了强调空间和通道这两个维度上的有意义特征,作者依次应用通道和空间注意模块,来分别在通道和空间维度上学习关注什么、在哪里关注。此外,通过了解要强调或抑制的信息也有助于网络内的信息流动。
主要网络架构也很简单,一个是通道注意力模块,另一个是空间注意力模块,CBAM就是先后集成了通道注意力模块和空间注意力模块。
2.1 通道注意力机制
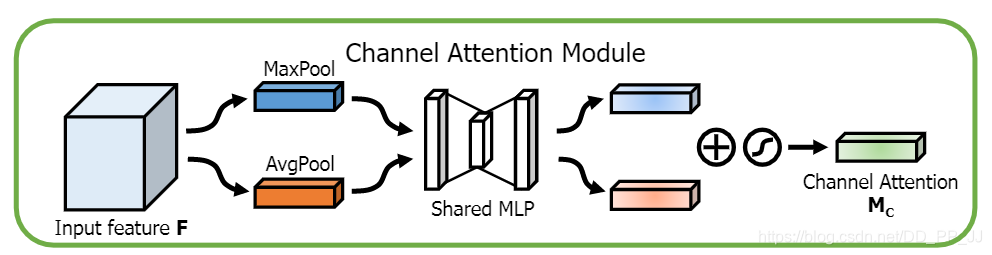
通道注意力机制按照上图进行实现:
class ChannelAttention(nn.Module):
def __init__(self, in_planes, rotio=16):
super(ChannelAttention, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.max_pool = nn.AdaptiveMaxPool2d(1)
self.sharedMLP = nn.Sequential(
nn.Conv2d(in_planes, in_planes // ratio, 1, bias=False), nn.ReLU(),
nn.Conv2d(in_planes // rotio, in_planes, 1, bias=False))
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avgout = self.sharedMLP(self.avg_pool(x))
maxout = self.sharedMLP(self.max_pool(x))
return self.sigmoid(avgout + maxout)
2.2 空间注意力机制
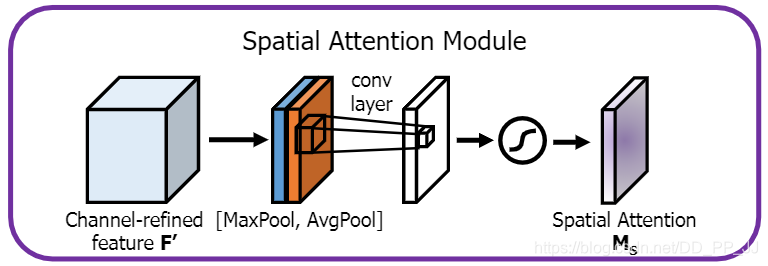
空间注意力机制按照上图进行实现:
class SpatialAttention(nn.Module):
def __init__(self, kernel_size=7):
super(SpatialAttention, self).__init__()
assert kernel_size in (3,7), "kernel size must be 3 or 7"
padding = 3 if kernel_size == 7 else 1
self.conv = nn.Conv2d(2,1,kernel_size, padding=padding, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avgout = torch.mean(x, dim=1, keepdim=True)
maxout, _ = torch.max(x, dim=1, keepdim=True)
x = torch.cat([avgout, maxout], dim=1)
x = self.conv(x)
return self.sigmoid(x)
2.3 Convolutional bottleneck attention module
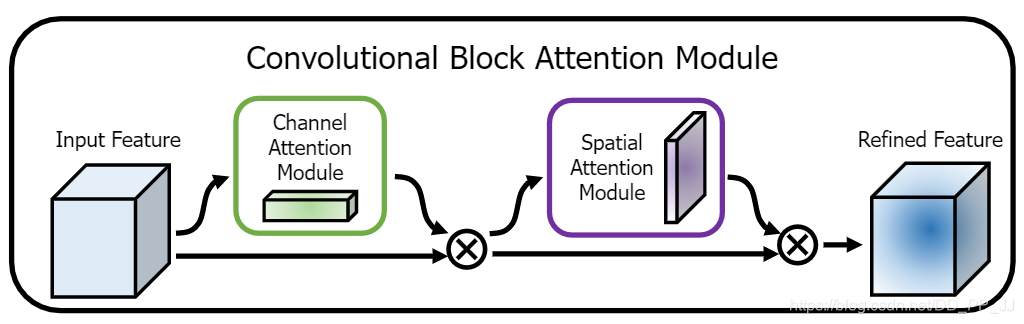
class BasicBlock(nn.Module):
expansion = 1
def __init__(self, inplanes, planes, stride=1, downsample=None):
super(BasicBlock, self).__init__()
self.conv1 = conv3x3(inplanes, planes, stride)
self.bn1 = nn.BatchNorm2d(planes)
self.relu = nn.ReLU(inplace=True)
self.conv2 = conv3x3(planes, planes)
self.bn2 = nn.BatchNorm2d(planes)
self.ca = ChannelAttention(planes)
self.sa = SpatialAttention()
self.downsample = downsample
self.stride = stride
def forward(self, x):
residual = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.ca(out) * out # 广播机制
out = self.sa(out) * out # 广播机制
if self.downsample is not None:
residual = self.downsample(x)
out += residual
out = self.relu(out)
return out
为何要先使用通道注意力机制然后再使用空间注意力机制?使用顺序使用这两个模块还是并行的使用两个模块?其实是作者已经做过了相关实验,并且证明了先试用通道然后再使用空间注意力机制这样的组合效果比较好,这也是CBAM的通用组合模式。
3. 在什么情况下可以使用?
提出CBAM的作者主要对分类网络和目标检测网络进行了实验,证明了CBAM模块确实是有效的。
以ResNet为例,论文中提供了改造的示意图,如下图所示:
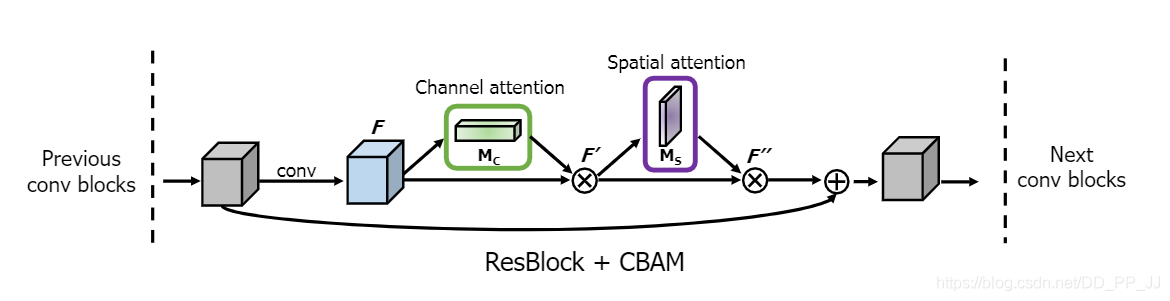
也就是在ResNet中的每个block中添加了CBAM模块,训练数据来自benchmark ImageNet-1K。检测使用的是Faster R-CNN, Backbone选择的ResNet34,ResNet50, WideResNet18, ResNeXt50等,还跟SE等进行了对比。
消融实验:消融实验一般是控制变量,最能看出模型变好起作用的部分在那里。分为三个部分:
- 如何更有效地计算channel attention?
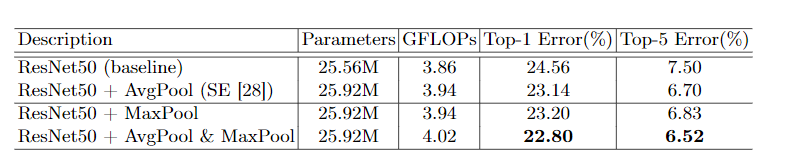
可以看出来,使用avgpool和maxpool可以更好的降低错误率,大概有1-2%的提升,这个组合就是dual pooling,能提供更加精细的信息,有利于提升模型的表现。
- 如何更有效地计算spatial attention?
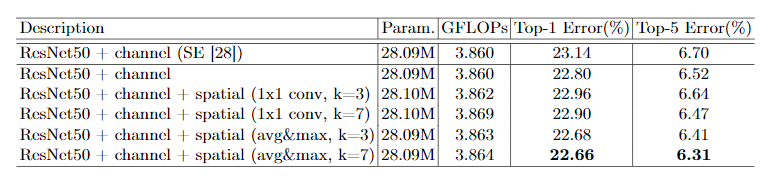
这里的空间注意力机制参数也是有avg, max组成,另外还有一个卷积的参数kernel_size(k), 通过以上实验,可以看出,当前使用通道的平均和通道的最大化,并且设置kernel size=7是最好的。
- 如何组织这两个部分?
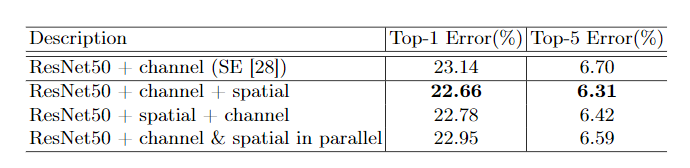
可以看出,这里与SENet中的SE模块也进行了比较,这里使用CBAM也是超出了SE的表现。除此以外,还进行了顺序和并行的测试,发现,先channel attention然后spatial attention效果最好,所以也是最终的CBAM模块的组成。
在MSCOCO数据及使用了ResNet50,ResNet101为backbone, Faster RCNN为检测器的模型进行目标检测,如下图所示:

在VOC2007数据集中采用了StairNet进行了测试,如下图所示:
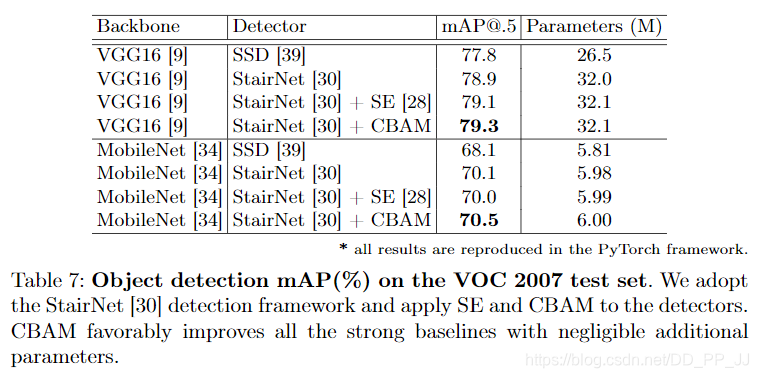
貌似没有找到目标检测部分的代码,CBAM的作用在于对信息进行精细化分配和处理,所以猜测是在backbone的分类器之前添加的CBAM模块,欢迎有研究的小伙伴赐教。