大二下实训课结业作业,想着就爬个工作信息,原本是要用python的,后面想想就用java试试看,
java就自学了一个月左右,想要锻炼一下自己面向对象的思想等等的,
然后网上转了一圈,拉钩什么的是动态生成的网页,51job是静态网页,比较方便,就决定爬51job了。
参考https://blog.csdn.net/qq_42982169/article/details/83155040,改了许多地方,方便模块化,加了保存的功能
前提:
创建Maven Project方便包管理
使用httpclient 3.1以及jsoup1.8.3作为爬取网页和筛选信息的包,这两个版本用的人多。
mysql-connect-java 8.0.13用来将数据导入数据库,支持mysql8.0+
分析使用,tablesaw(可选,会用的就行)
“大数据+上海”以此URL为例子,只要是类似的URL都可行
https://search.51job.com/list/020000,000000,0000,00,9,99,%25E5%25A4%25A7%25E6%2595%25B0%25E6%258D%25AE,2,1.html?lang=c&stype=&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&providesalary=99&lonlat=0%2C0&radius=-1&ord_field=0&confirmdate=9&fromType=&dibiaoid=0&address=&line=&specialarea=00&from=&welfare=
先设计了个大概的功能,修改了好几版,最后觉得这样思路比较清晰,以JobBean容器作为所有功能的媒介
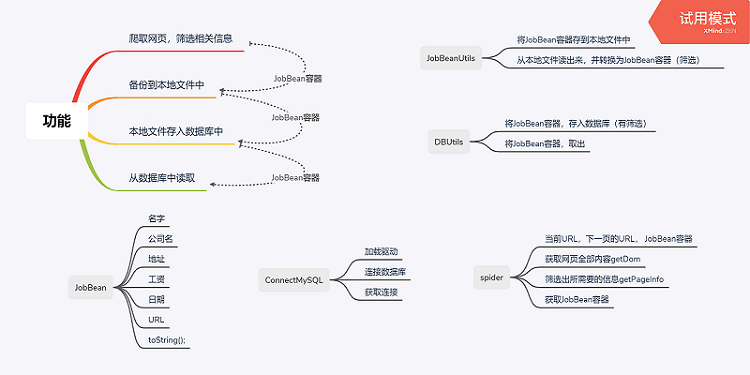
先完成爬取网页,以及保存到本地
创建JobBean对象
public class JobBean { private String jobName; private String company; private String address; private String salary; private String date; private String jobURL; public JobBean(String jobName, String company, String address, String salary, String date, String jobURL) { this.jobName = jobName; this.company = company; this.address = address; this.salary = salary; this.date = date; this.jobURL = jobURL; } @Override public String toString() { return "jobName=" + jobName + ", company=" + company + ", address=" + address + ", salary=" + salary + ", date=" + date + ", jobURL=" + jobURL; } public String getJobName() { return jobName; } public void setJobName(String jobName) { this.jobName = jobName; } public String getCompany() { return company; } public void setCompany(String company) { this.company = company; } public String getAddress() { return address; } public void setAddress(String address) { this.address = address; } public String getSalary() { return salary; } public void setSalary(String salary) { this.salary = salary; } public String getDate() { return date; } public void setDate(String date) { this.date = date; } public String getJobURL() { return jobURL; } public void setJobURL(String jobURL) { this.jobURL = jobURL; } }
然后写一个用于保存容器的工具类,这样在任何阶段都可以保存容器
import java.io.*; import java.util.*; /**实现 * 1。将JobBean容器存入本地 * 2.从本地文件读入文件为JobBean容器(有筛选) * @author PowerZZJ * */ public class JobBeanUtils { /**保存JobBean到本地功能实现 * @param job */ public static void saveJobBean(JobBean job) { try(BufferedWriter bw = new BufferedWriter( new FileWriter("JobInfo.txt",true))){ String jobInfo = job.toString(); bw.write(jobInfo); bw.newLine(); bw.flush(); }catch(Exception e) { System.out.println("保存JobBean失败"); e.printStackTrace(); } } /**保存JobBean容器到本地功能实现 * @param jobBeanList JobBean容器 */ public static void saveJobBeanList(List<JobBean> jobBeanList) { System.out.println("正在备份容器到本地"); for(JobBean jobBean : jobBeanList) { saveJobBean(jobBean); } System.out.println("备份完成,一共"+jobBeanList.size()+"条信息"); } /**从本地文件读入文件为JobBean容器(有筛选) * @return jobBean容器 */ public static List<JobBean> loadJobBeanList(){ List<JobBean> jobBeanList = new ArrayList<>(); try(BufferedReader br = new BufferedReader( new FileReader("JobInfo.txt"))){ String str = null; while((str=br.readLine())!=null) { //筛选,有些公司名字带有","不规范,直接跳过 try { String[] datas = str.split(","); String jobName = datas[0].substring(8); String company = datas[1].substring(9); String address = datas[2].substring(9); String salary = datas[3].substring(8); String date = datas[4].substring(6); String jobURL = datas[5].substring(8); //筛选,全部都不为空,工资是个区间,URL以https开头,才建立JobBean if (jobName.equals("") || company.equals("") || address.equals("") || salary.equals("") || !(salary.contains("-"))|| date.equals("") || !(jobURL.startsWith("http"))) continue; JobBean jobBean = new JobBean(jobName, company, address, salary, date, jobURL); //放入容器 jobBeanList.add(jobBean); }catch(Exception e) { System.out.println("本地读取筛选:有问题需要跳过的数据行:"+str); continue; } } System.out.println("读取完成,一共读取"+jobBeanList.size()+"条信息"); return jobBeanList; }catch(Exception e) { System.out.println("读取JobBean失败"); e.printStackTrace(); } return jobBeanList; } }
接着就是关键的爬取了
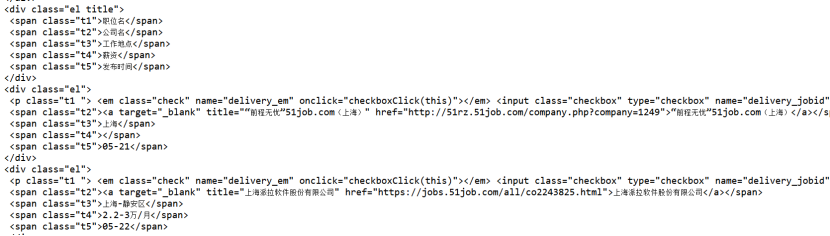
标签是el 里面是需要的信息,以及第一个el出来的是总体信息,一会需要去除。
各自里面都有t1,t2,t3,t4,t5标签,按照顺序一个个取出来就好。
再查看"下一页"元素,在bk标签下,这里要注意,有两个bk,第一个bk是上一页,第二个bk才是下一页,
之前我爬取进入死循环了。。。。

最后一个spider功能把爬取信息以及迭代下一页全部都放在一起
import java.net.URL; import java.util.ArrayList; import java.util.List; import org.jsoup.Jsoup; import org.jsoup.nodes.Document; import org.jsoup.nodes.Element; import org.jsoup.select.Elements; /**爬取网页信息 * @author PowerZZJ * */ public class Spider { //记录爬到第几页 private static int pageCount = 1; private String strURL; private String nextPageURL; private Document document;//网页全部信息 private List<JobBean> jobBeanList; public Spider(String strURL) { this.strURL = strURL; nextPageURL = strURL;//下一页URL初始化为当前,方便遍历 jobBeanList = new ArrayList<JobBean>(); } /**获取网页全部信息 * @param 网址 * @return 网页全部信息 */ public Document getDom(String strURL) { try { URL url = new URL(strURL); //解析,并设置超时 document = Jsoup.parse(url, 4000); return document; }catch(Exception e) { System.out.println("getDom失败"); e.printStackTrace(); } return null; } /**筛选当前网页信息,转成JobBean对象,存入容器 * @param document 网页全部信息 */ public void getPageInfo(Document document) { //通过CSS选择器用#resultList .el获取el标签信息 Elements elements = document.select("#resultList .el"); //总体信息删去 elements.remove(0); //筛选信息 for(Element element: elements) { Elements elementsSpan = element.select("span"); String jobURL = elementsSpan.select("a").attr("href"); String jobName = elementsSpan.get(0).select("a").attr("title"); String company = elementsSpan.get(1).select("a").attr("title"); String address = elementsSpan.get(2).text(); String salary = elementsSpan.get(3).text(); String date = elementsSpan.get(4).text(); //建立JobBean对象 JobBean jobBean = new JobBean(jobName, company, address, salary, date, jobURL); //放入容器 jobBeanList.add(jobBean); } } /**获取下一页的URL * @param document 网页全部信息 * @return 有,则返回URL */ public String getNextPageURL(Document document) { try { Elements elements = document.select(".bk"); //第二个bk才是下一页 Element element = elements.get(1); nextPageURL = element.select("a").attr("href"); if(nextPageURL != null) { System.out.println("---------"+(pageCount++)+"--------"); return nextPageURL; } }catch(Exception e) { System.out.println("获取下一页URL失败"); e.printStackTrace(); } return null; } /**开始爬取 * */ public void spider() { while(!nextPageURL.equals("")) { //获取全部信息 document = getDom(nextPageURL); //把相关信息加入容器 getPageInfo(document); //查找下一页的URL nextPageURL = getNextPageURL(document); } } //获取JobBean容器 public List<JobBean> getJobBeanList() { return jobBeanList; } }
然后测试一下爬取与保存功能
import java.util.ArrayList; import java.util.List; public class Test1 { public static void main(String[] args) { List<JobBean> jobBeanList = new ArrayList<>(); //大数据+上海 String strURL = "https://search.51job.com/list/020000,000000,0000,00,9,99,%25E5%25A4%25A7%25E6%2595%25B0%25E6%258D%25AE,2,1.html?lang=c&stype=1&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&lonlat=0%2C0&radius=-1&ord_field=0&confirmdate=9&fromType=&dibiaoid=0&address=&line=&specialarea=00&from=&welfare="; //测试Spider以及保存 Spider spider = new Spider(strURL); spider.spider(); //获取爬取后的JobBean容器 jobBeanList = spider.getJobBeanList(); //调用JobBean工具类保存JobBeanList到本地 JobBeanUtils.saveJobBeanList(jobBeanList); //调用JobBean工具类从本地筛选并读取,得到JobBeanList jobBeanList = JobBeanUtils.loadJobBeanList(); } }
然后本地就有了JobInfo.txt

然后就是把JobBean容器放到MySQL中了,我的数据库名字是51job,表名字是jobInfo,所有属性都是字符串,emmm就字符串吧

import java.sql.Connection; import java.sql.DriverManager; import java.sql.SQLException; public class ConnectMySQL { //数据库信息 private static final String DBaddress = "jdbc:mysql://localhost/51job?serverTimezone=UTC"; private static final String userName = "root"; private static final String password = "Woshishabi2813"; private Connection conn; //加载驱动,连接数据库 public ConnectMySQL() { LoadDriver(); //连接数据库 try { conn = DriverManager.getConnection(DBaddress, userName, password); } catch (SQLException e) { System.out.println("数据库连接失败"); } } //加载驱动 private void LoadDriver() { try { Class.forName("com.mysql.cj.jdbc.Driver"); System.out.println("加载驱动成功"); } catch (Exception e) { System.out.println("驱动加载失败"); } } //获取连接 public Connection getConn() { return conn; } }
接着就是数据相关操作的工具类的编写了。
import java.sql.Connection; import java.sql.PreparedStatement; import java.sql.ResultSet; import java.util.ArrayList; import java.util.List; public class DBUtils { /**将JobBean容器存入数据库(有筛选) * @param conn 数据库的连接 * @param jobBeanList jobBean容器 */ public static void insert(Connection conn, List<JobBean> jobBeanList) { System.out.println("正在插入数据"); PreparedStatement ps; for(JobBean j: jobBeanList) { //命令生成 String command = String.format("insert into jobInfo values('%s','%s','%s','%s','%s','%s')", j.getJobName(), j.getCompany(), j.getAddress(), j.getSalary(), j.getDate(), j.getJobURL()); try { ps = conn.prepareStatement(command); ps.executeUpdate(); } catch (Exception e) { System.out.println("存入数据库筛选有误信息:"+j.getJobName()); } } System.out.println("插入数据完成"); } /**将JobBean容器,取出 * @param conn 数据库的连接 * @return jobBean容器 */ public static List<JobBean> select(Connection conn){ PreparedStatement ps; ResultSet rs; List<JobBean> jobBeanList = new ArrayList<JobBean>(); String command = "select * from jobInfo"; try { ps = conn.prepareStatement(command); rs = ps.executeQuery(); int col = rs.getMetaData().getColumnCount(); while(rs.next()) { JobBean jobBean = new JobBean(rs.getString(1), rs.getString(2), rs.getString(3), rs.getString(4), rs.getString(5), rs.getString(6)); jobBeanList.add(jobBean); } return jobBeanList; } catch (Exception e) { System.out.println("数据库查询失败"); } return null; } }
然后测试一下
import java.sql.Connection; import java.util.ArrayList; import java.util.List; public class Test2 { public static void main(String[] args) { List<JobBean> jobBeanList = new ArrayList<>(); jobBeanList = JobBeanUtils.loadJobBeanList(); //数据库测试 ConnectMySQL cm = new ConnectMySQL(); Connection conn = cm.getConn(); //插入测试 DBUtils.insert(conn, jobBeanList); //select测试 jobBeanList = DBUtils.select(conn); for(JobBean j: jobBeanList) { System.out.println(j); } } }
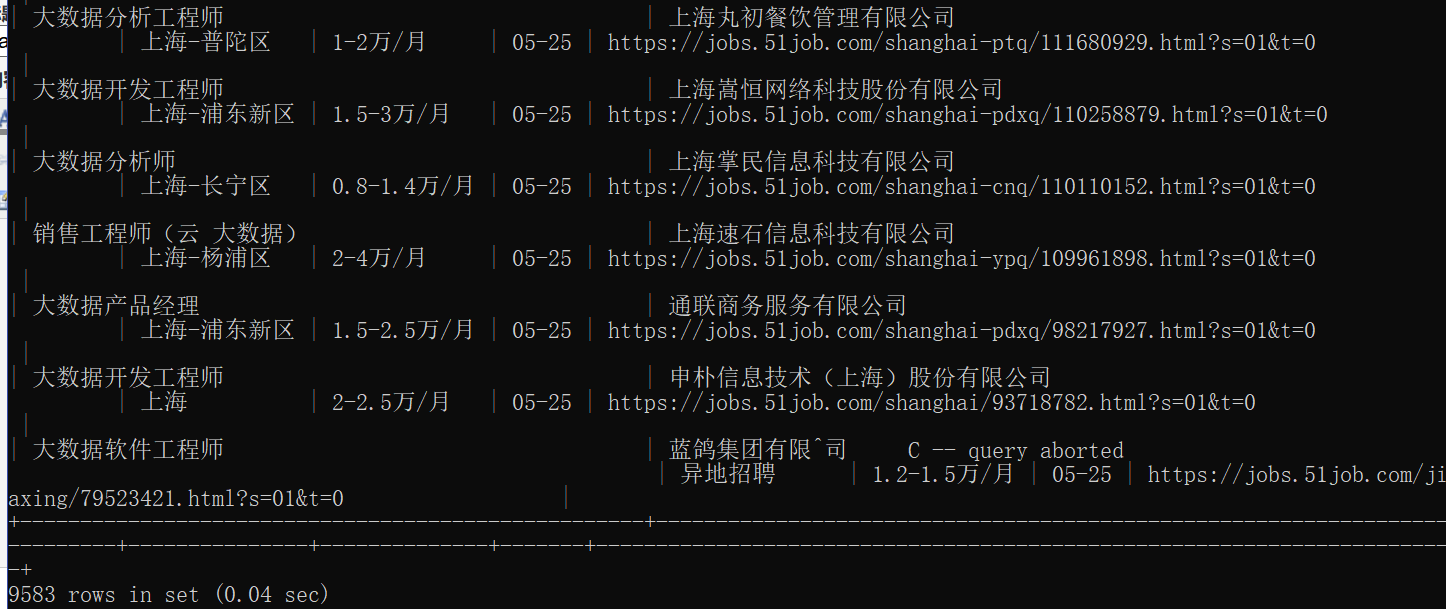

上面的图可以看到虽然是“大数据+上海”,但是依旧有运维工程师上面不相关的,后面会进行过滤处理。这里就先存入数据库中
先来个功能的整体测试,删除JobInfo.txt,重建数据库
import java.sql.Connection; import java.util.ArrayList; import java.util.List; public class TestMain { public static void main(String[] args) { List<JobBean> jobBeanList = new ArrayList<>(); //大数据+上海 String strURL = "https://search.51job.com/list/020000,000000,0000,00,9,99,%25E5%25A4%25A7%25E6%2595%25B0%25E6%258D%25AE,2,1.html?lang=c&stype=1&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&lonlat=0%2C0&radius=-1&ord_field=0&confirmdate=9&fromType=&dibiaoid=0&address=&line=&specialarea=00&from=&welfare="; // //Java+上海 // String strURL = "https://search.51job.com/list/020000,000000,0000,00,9,99,java,2,1.html?lang=c&stype=&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&providesalary=99&lonlat=0%2C0&radius=-1&ord_field=0&confirmdate=9&fromType=&dibiaoid=0&address=&line=&specialarea=00&from=&welfare="; //所有功能测试 //爬取的对象 Spider jobSpider = new Spider(strURL); jobSpider.spider(); //爬取完的JobBeanList jobBeanList = jobSpider.getJobBeanList(); //调用JobBean工具类保存JobBeanList到本地 JobBeanUtils.saveJobBeanList(jobBeanList); //调用JobBean工具类从本地筛选并读取,得到JobBeanList jobBeanList = JobBeanUtils.loadJobBeanList(); //连接数据库,并获取连接 ConnectMySQL cm = new ConnectMySQL(); Connection conn = cm.getConn(); //调用数据库工具类将JobBean容器存入数据库 DBUtils.insert(conn, jobBeanList); // //调用数据库工具类查询数据库信息,并返回一个JobBeanList // jobBeanList = DBUtils.select(conn); // // for(JobBean j: jobBeanList) { // System.out.println(j); // } } }
这些功能都是能独立使用的,不是一定要这样一路写下来。
接下来就是进行数据库的读取,进行简单的过滤,然后进行分析了
先上思维导图
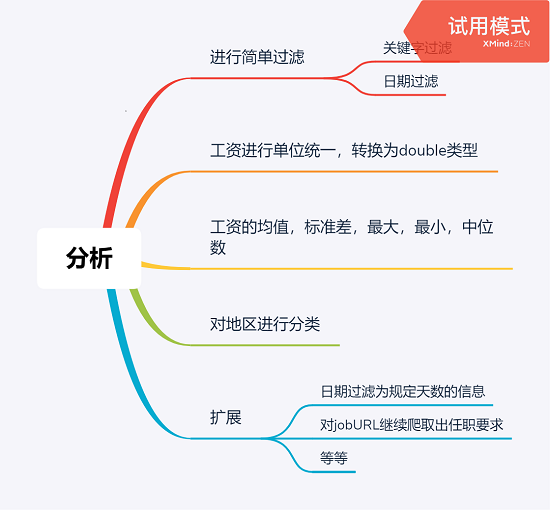
首先是过滤关键字和日期
import java.util.ArrayList; import java.util.Calendar; import java.util.List;public class BaseFilter { private List<JobBean> jobBeanList; //foreach遍历不可以remove,Iterator有锁 //用新的保存要删除的,然后removeAll private List<JobBean> removeList; public BaseFilter(List<JobBean> jobBeanList) { this.jobBeanList = new ArrayList<JobBean>(); removeList = new ArrayList<JobBean>(); //引用同一个对象,getJobBeanList有没有都一样 this.jobBeanList = jobBeanList; printNum(); } //打印JobBean容器中的数量 public void printNum() { System.out.println("现在一共"+jobBeanList.size()+"条数据"); } /**筛选职位名字 * @param containJobName 关键字保留 */ public void filterJobName(String containJobName) { for(JobBean j: jobBeanList) { if(!j.getJobName().contains(containJobName)) { removeList.add(j); } } jobBeanList.removeAll(removeList); removeList.clear(); printNum(); } /**筛选日期,要当天发布的 * @param */ public void filterDate() { Calendar now=Calendar.getInstance(); int nowMonth = now.get(Calendar.MONTH)+1; int nowDay = now.get(Calendar.DATE); for(JobBean j: jobBeanList) { String[] date = j.getDate().split("-"); int jobMonth = Integer.valueOf(date[0]); int jobDay = Integer.valueOf(date[1]); if(!(jobMonth==nowMonth && jobDay==nowDay)) { removeList.add(j); } } jobBeanList.removeAll(removeList); removeList.clear(); printNum(); } public List<JobBean> getJobBeanList(){ return jobBeanList; } }
测试一下过滤的效果
import java.sql.Connection; import java.util.ArrayList; import java.util.List; public class Test3 { public static void main(String[] args) { List<JobBean> jobBeanList = new ArrayList<>(); //数据库读取jobBean容器 ConnectMySQL cm = new ConnectMySQL(); Connection conn = cm.getConn(); jobBeanList = DBUtils.select(conn); BaseFilter bf = new BaseFilter(jobBeanList); //过滤时间 bf.filterDate(); //过滤关键字 bf.filterJobName("数据"); bf.filterJobName("分析"); for(JobBean j: jobBeanList) { System.out.println(j); } } }

到这里基本是统一的功能,后面的分析就要按照不同职业,或者不同需求而定了,不过基本差不多,
这里分析的就是“大数据+上海”下的相关信息了,为了数据量大一点,关键字带有"数据"就行,有247条信息
用到了tablesaw的包,这个我看有人推荐,结果中间遇到问题都基本百度不到,只有官方文档,反复看了,而且这个还不能单独画出图,
还要别的依赖包,所以我就做个表格吧。。。可视化什么的已经不想研究了(我为什么不用python啊。。。)
分析也就没有什么面向对象需要写的了,基本就是一个main里面一路写下去了。具体用法可以看官方文档,就当看个结果了解一下
工资统一为万/月
import static tech.tablesaw.aggregate.AggregateFunctions.*; import java.sql.Connection; import java.util.ArrayList; import java.util.List; import tech.tablesaw.api.*; public class Analayze { public static void main(String[] args) { List<JobBean> jobBeanList = new ArrayList<>(); ConnectMySQL cm = new ConnectMySQL(); Connection conn = cm.getConn(); jobBeanList = DBUtils.select(conn); BaseFilter bf = new BaseFilter(jobBeanList); bf.filterDate(); bf.filterJobName("数据"); int nums = jobBeanList.size(); //分析 //按照工资排序 String[] jobNames = new String[nums]; String[] companys = new String[nums]; String[] addresss = new String[nums]; double[] salarys = new double[nums]; String[] jobURLs = new String[nums]; for(int i=0; i<nums; i++) { JobBean j = jobBeanList.get(i); String jobName = j.getJobName(); String company = j.getCompany(); //地址提出区名字 String address; if(j.getAddress().contains("-")) { address = j.getAddress().split("-")[1]; }else{ address = j.getAddress(); } //工资统一单位 String sSalary = j.getSalary(); double dSalary; if(sSalary.contains("万/月")) { dSalary = Double.valueOf(sSalary.split("-")[0]); }else if(sSalary.contains("千/月")) { dSalary = Double.valueOf(sSalary.split("-")[0])/10; dSalary = (double) Math.round(dSalary * 100) / 100; }else if(sSalary.contains("万/年")) { dSalary = Double.valueOf(sSalary.split("-")[0])/12; dSalary = (double) Math.round(dSalary * 100) / 100; }else { dSalary = 0; System.out.println("工资转换失败"); continue; } String jobURL = j.getJobURL(); jobNames[i] = jobName; companys[i] = company; addresss[i] = address; salarys[i] = dSalary; jobURLs[i] = jobURL; } Table jobInfo = Table.create("Job Info") .addColumns( StringColumn.create("jobName", jobNames), StringColumn.create("company", companys), StringColumn.create("address", addresss), DoubleColumn.create("salary", salarys), StringColumn.create("jobURL", jobURLs) ); // System.out.println("全上海信息"); // System.out.println(salaryInfo(jobInfo)); List<Table> addressJobInfo = new ArrayList<>(); //按照地区划分 Table ShanghaiJobInfo = chooseByAddress(jobInfo, "上海"); Table jingAnJobInfo = chooseByAddress(jobInfo, "静安区"); Table puDongJobInfo = chooseByAddress(jobInfo, "浦东新区"); Table changNingJobInfo = chooseByAddress(jobInfo, "长宁区"); Table minHangJobInfo = chooseByAddress(jobInfo, "闵行区"); Table xuHuiJobInfo = chooseByAddress(jobInfo, "徐汇区"); //人数太少 // Table songJiangJobInfo = chooseByAddress(jobInfo, "松江区"); // Table yangPuJobInfo = chooseByAddress(jobInfo, "杨浦区"); // Table hongKouJobInfo = chooseByAddress(jobInfo, "虹口区"); // Table OtherInfo = chooseByAddress(jobInfo, "异地招聘"); // Table puTuoJobInfo = chooseByAddress(jobInfo, "普陀区"); addressJobInfo.add(jobInfo); //上海地区招聘 addressJobInfo.add(ShanghaiJobInfo); addressJobInfo.add(jingAnJobInfo); addressJobInfo.add(puDongJobInfo); addressJobInfo.add(changNingJobInfo); addressJobInfo.add(minHangJobInfo); addressJobInfo.add(xuHuiJobInfo); // addressJobInfo.add(songJiangJobInfo); // addressJobInfo.add(yangPuJobInfo); // addressJobInfo.add(hongKouJobInfo); // addressJobInfo.add(puTuoJobInfo); // addressJobInfo.add(OtherInfo); for(Table t: addressJobInfo) { System.out.println(salaryInfo(t)); } for(Table t: addressJobInfo) { System.out.println(sortBySalary(t).first(10)); } } //工资平均值,最小,最大 public static Table salaryInfo(Table t) { return t.summarize("salary",mean,stdDev,median,max,min).apply(); } //salary进行降序 public static Table sortBySalary(Table t) { return t.sortDescendingOn("salary"); } //选择地区 public static Table chooseByAddress(Table t, String address) { Table t2 = Table.create(address) .addColumns( StringColumn.create("jobName"), StringColumn.create("company"), StringColumn.create("address"), DoubleColumn.create("salary"), StringColumn.create("jobURL")); for(Row r: t) { if(r.getString(2).equals(address)) { t2.addRow(r); } } return t2; } }
前半段是各个地区的信息
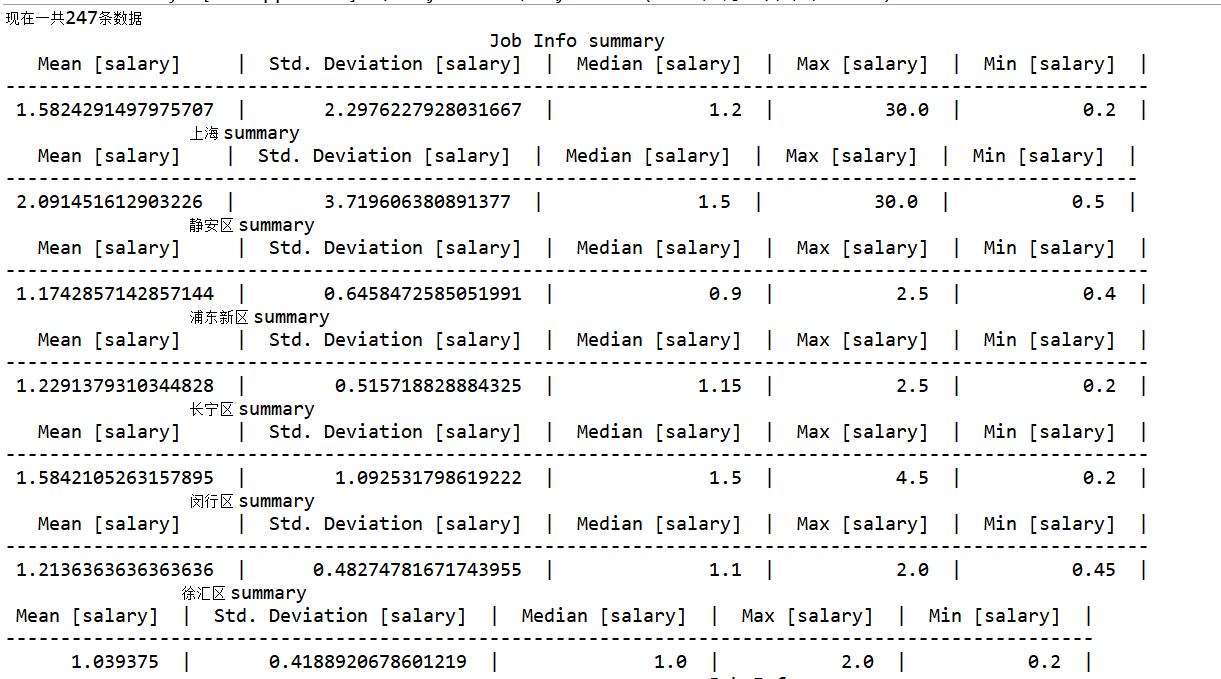
后半段是各个区工资最高的前10名的信息,可以看到这个tablesaw的表要多难看有多难看。。。
jobURL可以直接在浏览器里面看,
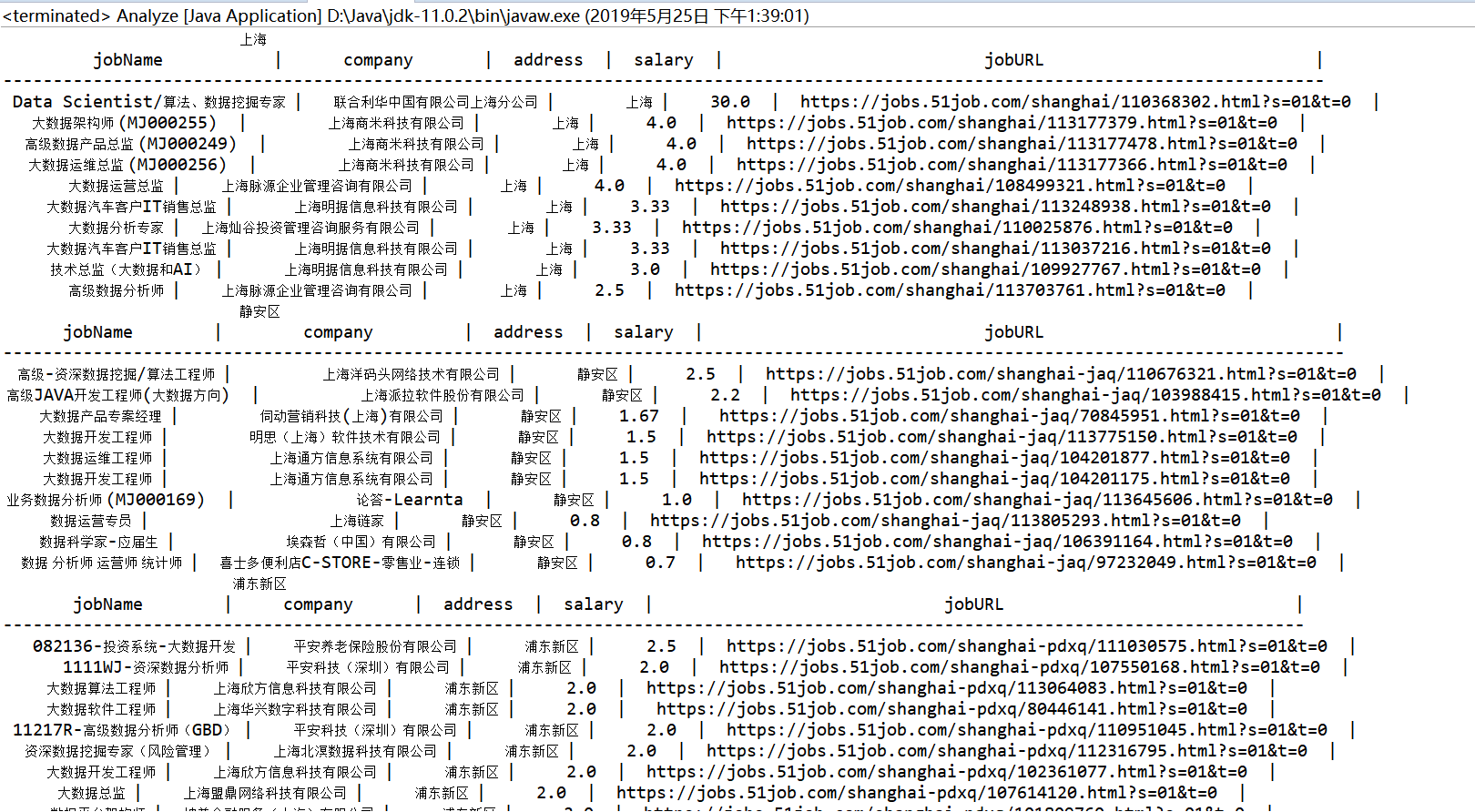
换个URL进行测试
我要找Java开发工作
将之前TestMain中的strURL换成Java+上海
https://search.51job.com/list/020000,000000,0000,00,9,99,java,2,1.html?lang=c&stype=&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&providesalary=99&lonlat=0%2C0&radius=-1&ord_field=0&confirmdate=9&fromType=&dibiaoid=0&address=&line=&specialarea=00&from=&welfare=
删除JobInfo.txt,重建数据库
运行,爬了270多页,本地JobInfo.txt

数据库
然后到Analyze中把bf.filterJobName("数据");
改为“Java”,再加一个“开发”,然后运行



信息全部都出来了,分析什么的,先照着表格说一点把。。。
后面想要拓展的内容就是继续爬取jobURL然后把职位要求做统计。这还没做,暑假有兴趣应该会搞一下,
然后可以把数据库设计一下,把工资分为最低和最高两项,存进去就变成double类型,这样以后分析也会轻松一点