1、为什么用线程池
1)降低资源消耗,线程是稀缺资源,所以反复的创建销毁,是非常消耗资源的
2) 提高响应率 ,大量请求高并发,多线程速度快
3)提高线程的可管理性,线程池进行管理和监控
2、线程池继承实现关系
public class ThreadPoolExecutor extends AbstractExecutorService
public abstract class AbstractExecutorService implements ExecutorService
public interface ExecutorService extends Executor
public interface Executor{
void execute(Runnable command);
}
ExecutorService里面放的是管理线程池的方法
Executors
放的是4个创建线程池的方法
第一个是newSingleThreadPoolExcutor 定义一个线程进行使用串行话
第二个是newFixsThreadPoolExcutor定义n个线程进行使用,空闲线程会一直保留
第三个是newCacheThreadPoolExcutor 不用指定线程数,空闲线程不会创建
第四个是 newSheduelThreadPoolExcutor 创建一个大小无限的线程池。此线程池支持定时以及周期性执行任务的需求
都是使用的execute方法进行调用线程池
问什么不建议使用excutors静态工厂创建线程池
因为
newSingleThreadPoolExcutor和
newFixsThreadPoolExcutor他们使用的LinkedBlockingQueue这个队列,他是都是有长度限制的integer.max,当超过了就会报内存溢出的
newCacheThreadPoolExcutor和
newSheduelThreadPoolExcutor 他们允许创建的线程数最多是
integer.maxValue 2^31 超过了就会报内存溢出的
所以建议使用
new ThreadPoolExecutor (
核心线程数,
最大线程数,
线程数量超过corePoolSize,空闲线程的最大超时时间
时间单位,
工作队列,
用来保存等待被执行的任务的阻塞队列,且任务必须实现Runable接口,在JDK中提供了如下阻塞队列:
1、ArrayBlockingQueue:基于数组结构的有界阻塞队列,按FIFO排序任务;
2、LinkedBlockingQuene:基于链表结构的阻塞队列,按FIFO排序任务,吞吐量通常要高于ArrayBlockingQuene;
3、SynchronousQuene:一个不存储元素的阻塞队列,每个插入操作必须等到另一个线程调用移除操作,否则插入操作一直处于阻塞状态,吞吐量通常要高于LinkedBlockingQuene;
4、priorityBlockingQuene:具有优先级的无界阻塞队列;
1、ArrayBlockingQueue:基于数组结构的有界阻塞队列,按FIFO排序任务;
2、LinkedBlockingQuene:基于链表结构的阻塞队列,按FIFO排序任务,吞吐量通常要高于ArrayBlockingQuene;
3、SynchronousQuene:一个不存储元素的阻塞队列,每个插入操作必须等到另一个线程调用移除操作,否则插入操作一直处于阻塞状态,吞吐量通常要高于LinkedBlockingQuene;
4、priorityBlockingQuene:具有优先级的无界阻塞队列;
工厂类,
拒绝策略
线程池的饱和策略,当阻塞队列满了,且没有空闲的工作线程,如果继续提交任务,必须采取一种策略处理该任务,线程池提供了4种策略:
1、AbortPolicy:直接抛出异常,默认策略;
2、CallerRunsPolicy:用调用者所在的线程来执行任务;
3、DiscardOldestPolicy:丢弃阻塞队列中靠最前的任务,并执行当前任务;
4、DiscardPolicy:直接丢弃任务;
1、AbortPolicy:直接抛出异常,默认策略;
2、CallerRunsPolicy:用调用者所在的线程来执行任务;
3、DiscardOldestPolicy:丢弃阻塞队列中靠最前的任务,并执行当前任务;
4、DiscardPolicy:直接丢弃任务;
)
线程池底层逻辑
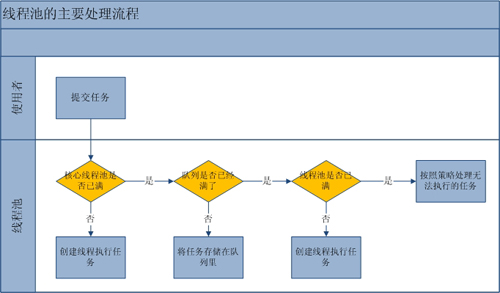
1、判断线程池里的核心线程是否都在执行任务,如果不是(核心线程空闲或者还有核心线程没有被创建)则创建一个新的工作线程来执行任务。如果核心线程都在执行任务,则进入下个流程。
2、线程池判断工作队列是否已满,如果工作队列没有满,则将新提交的任务存储在这个工作队列里。如果工作队列满了,则进入下个流程。
3、判断线程池里的线程是否都处于工作状态,如果没有,则创建一个新的工作线程来执行任务。如果已经满了,则交给饱和策略来处理这个任务。
假如提交到线程池中的任务,IO耗时占比是90%,计算耗时占比10%,忽略提交到线程池中的任务数量,在4C8G的机器上,理想情况下线程池中创建多少个线程是最优的
一般平时只埋头写CURD的候选人,难以计算出来,当然也遇到了不少能算出来结果来的,线程数=(1/0.1) * 4 = 40假如e有一类cpu密集性的任务,没有IO操作,日常的时候只有1个任务,流量高峰会有50个任务,4C8G的机器上,使用的线程池,如何设置corePoolSize, maxPoolSize以及BlockingQueue的大小
很显然,日常只需要一个线程,那么corePoolSize=1,而高峰时候,虽然任务有50个,但是只是4C的机器,对于cpu密集型任务,4个线程是最优的,因此理想情况下maxCorePoolSize=4,最后再看看队列,因为队列满了,max才会被创建,而我们需要让max快速被创建出来,又不会出现任务拒绝,因此,可将队列大小设置成46,那么线程池的行为如下:
- 提交第一个任务,创建出core,1个线程
- 提交第二个到第47个任务时,这些任务进入到队列中,此时队列已满
- 提交第48个任务到第50个任务时,创建出max,此时一共有4个线程
- 4个线程同时将队列里的46个任务消费完
- 一段时间后,max - core数量的线程销毁,即销毁3个线程,还剩下一个线程