超图 embedding 相关论文笔记。按照时间先后排序
| 名称 | 会议/期刊 | 时间 |
|---|---|---|
| Hypergraph Neural Network | 会议 | 2019.2 |
| Dynamic Hypergraph Neural Networks | 会议 | 2019 |
| Be More with Less: Hypergraph Attention Networks for Inductive Text Classification | 2020.11.1 | |
| Dual-view hypergraph neural networks for attributed graph learning | 2021.1.1 |
1 Hypergraph Neural Networks (HGNN)
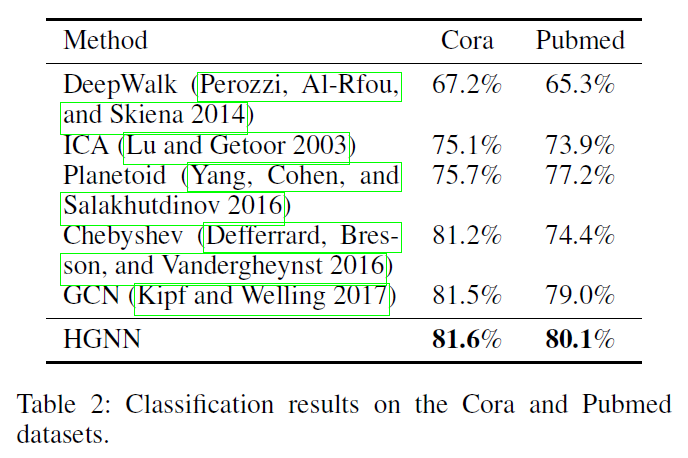
这一篇论文可以说是超图 embedding 相关论文中影响力较大的一篇。文章从纯谱域角度,设计了基于超图结构数据的 embedding 模型。由于我后期的工作重点以空域方法为主,本文只对 HGNN 做简单的介绍,不详细分析。
普通图和超图的区别:
- 普通图:(X) + (A)
- 超图:(X) + (H)
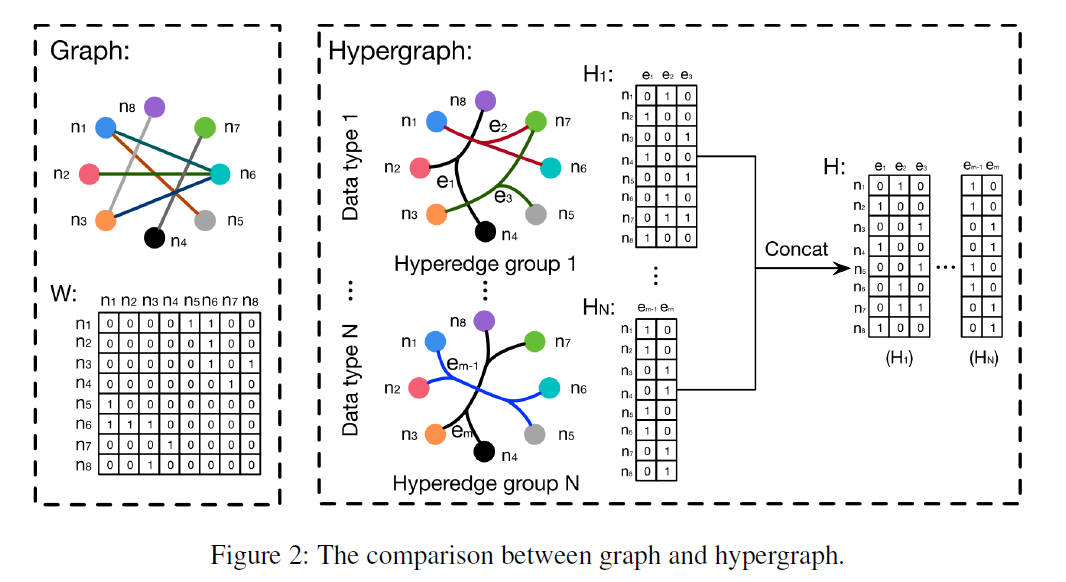
文章中构造超图的方法为 KNN,构造得到的超图为 K-均匀超图。
def construct_H_with_KNN_from_distance(dis_mat, k_neig, is_probH=True, m_prob=1):
"""
construct hypregraph incidence matrix from hypergraph node distance matrix
:param dis_mat: node distance matrix
:param k_neig: K nearest neighbor
:param is_probH: prob Vertex-Edge matrix or binary
:param m_prob: prob
:return: N_object X N_hyperedge
"""
n_obj = dis_mat.shape[0]
# construct hyperedge from the central feature space of each node
n_edge = n_obj
H = np.zeros((n_obj, n_edge))
for center_idx in range(n_obj):
dis_mat[center_idx, center_idx] = 0
dis_vec = dis_mat[center_idx]
nearest_idx = np.array(np.argsort(dis_vec)).squeeze()
avg_dis = np.average(dis_vec)
if not np.any(nearest_idx[:k_neig] == center_idx):
nearest_idx[k_neig - 1] = center_idx
for node_idx in nearest_idx[:k_neig]:
if is_probH:
H[node_idx, center_idx] = np.exp(-dis_vec[0, node_idx] ** 2 / (m_prob * avg_dis) ** 2)
else:
H[node_idx, center_idx] = 1.0
return H
框架图:
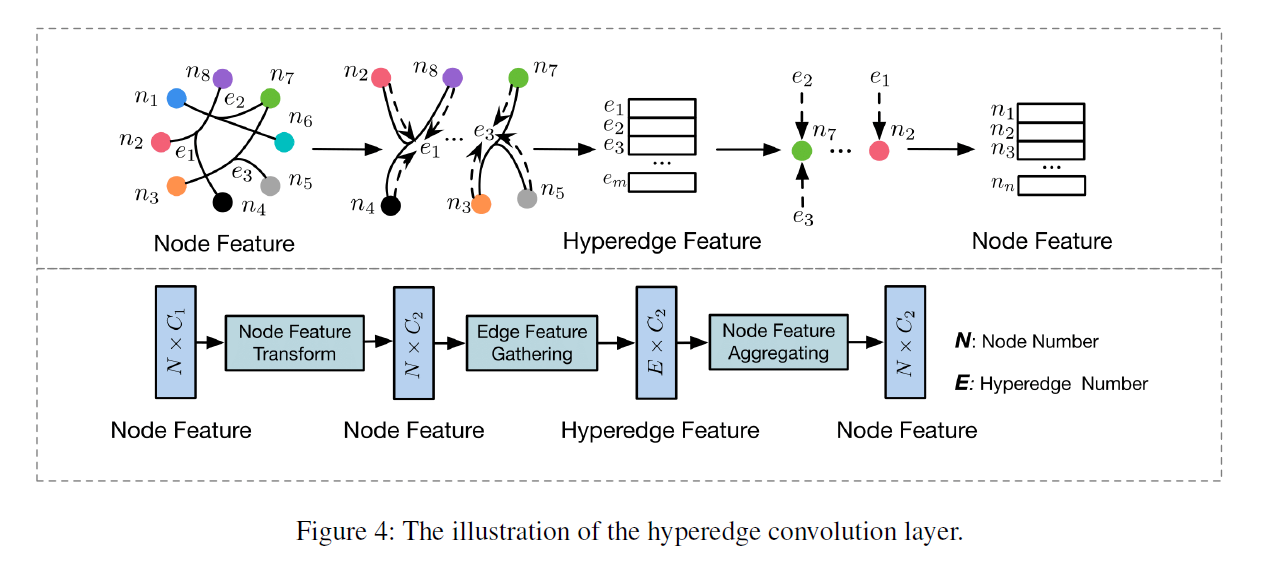
简单来说,就是每一个超边 (e) 先聚合得到每一个节点 (v) 的特征,然后再将超边 (e) 的特征反馈到其包含的每一个节点 (v) 上去。
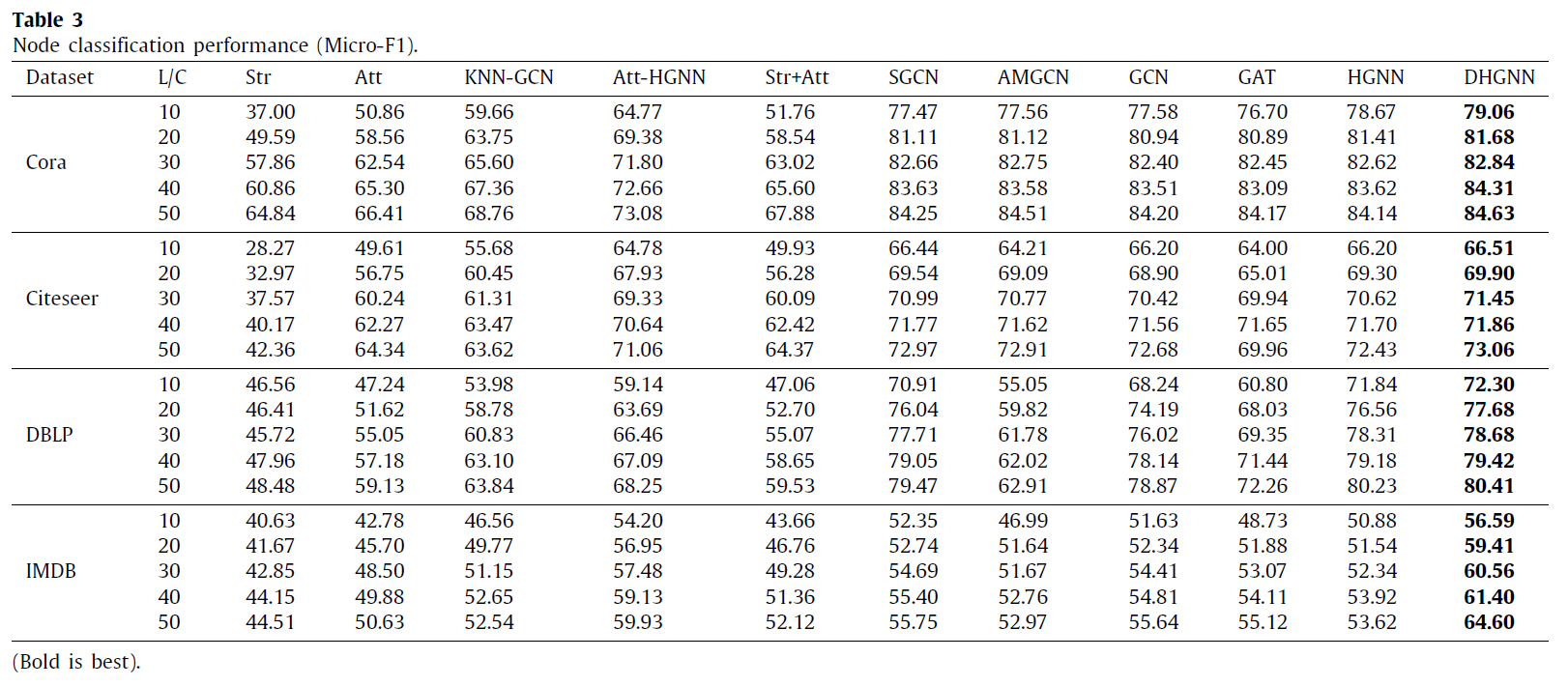
实验结果(分类):
2 Dynamic Hypergraph Neural Networks (DHGNN)
本文最大的创新点:采用图进化的思想进行超图 embedding 。本文提出了两个算法:动态超图构建(dynamic hypergraph construction,DHG)和超图卷积(HGC)。整个模型采用多个堆叠的 DHG+HGC 层,即 {DHG+HGC} - {DHG+HGC} - ... - {DHG+HGC} 。最终模型能够得到较好的 embedding 。在经过对比后,该模型是当时的 sota 方法。
图进化思想:每一次更新 embedding, 都重新构造一次超图
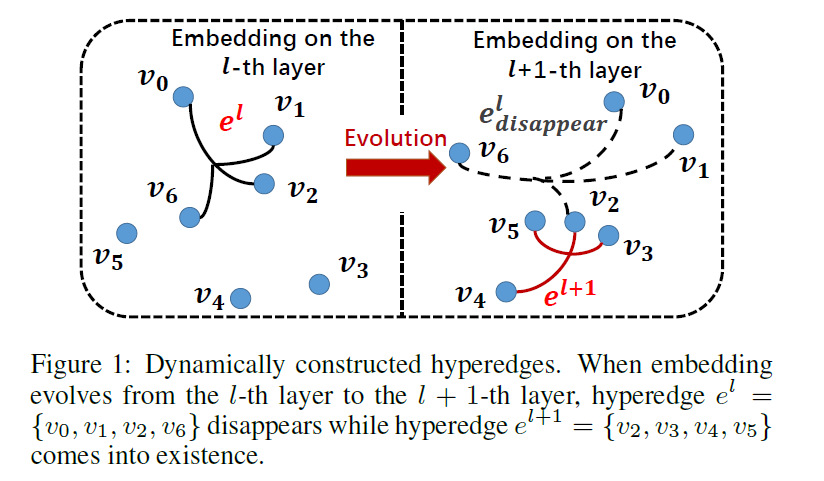
- DHG算法:

-
首先对当前的 embedding 矩阵 (X) 使用 K-Means 算法,得到簇类结果 (C)。 (C[i]) 表示第 (i) 簇,(C. ext{center}) 表示簇类中心的集合。
-
对每一个节点 (u) ,通过 KNN 算法找到和该节点最近的 k 个节点(包含自身),构成集合 (e_b) 。将 (e_b) 和 (u) 共同构成一个超边。
-
找出簇类中心离当前节点 (u) 的距离前 (S-1) 近的簇。对于每一个簇的节点集 (C_i),与节点 (u) 共同构成一个超边。即这一步一共会构造 (S-1) 个超边。
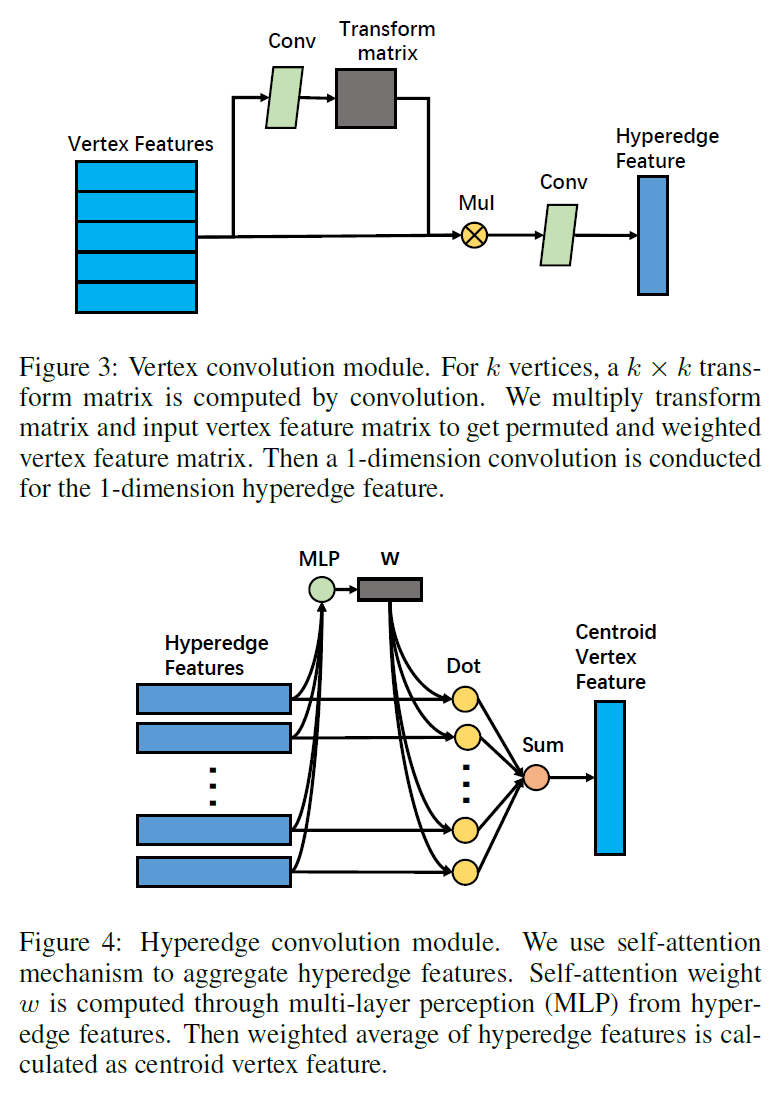
- HGC算法:

引入了 节点集注意力 和 超边集注意力 两个层次的注意力来进行图 embedding,思路比较直接。
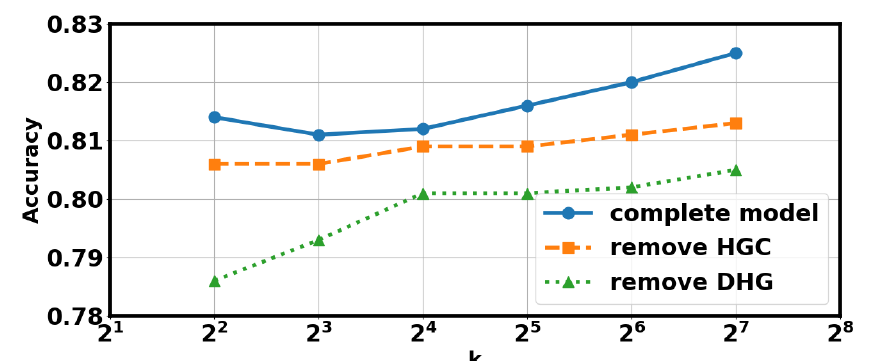
模块重要性: 可以看出动态超图构建是非常重要的过程,移除直接导致模型效果骤降。
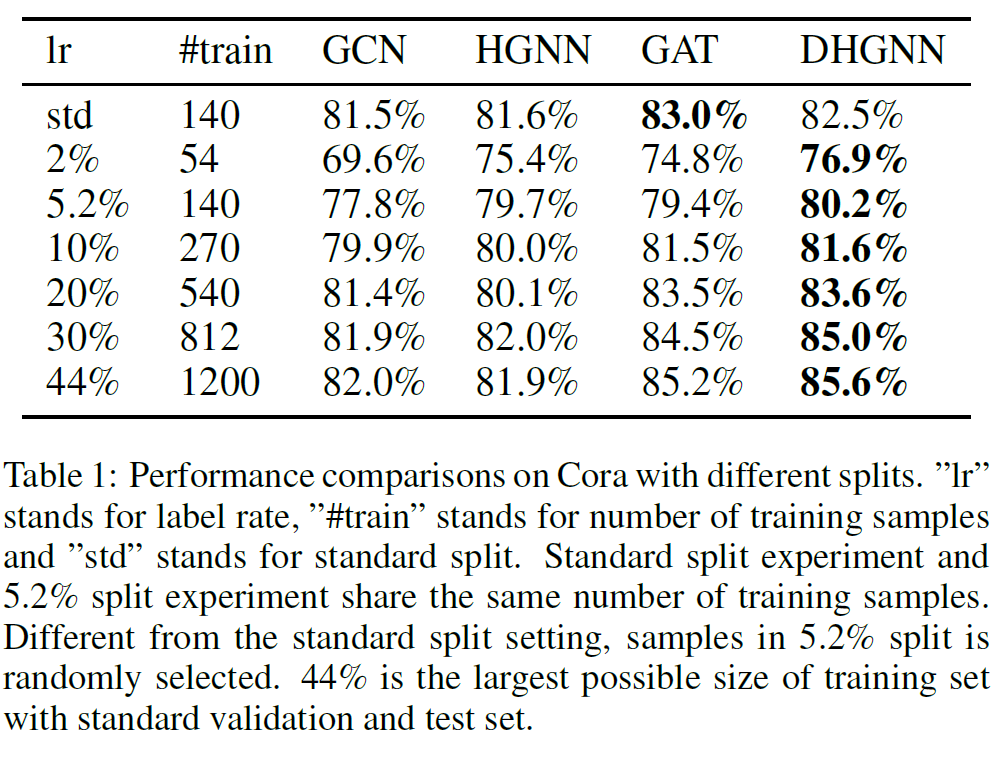
实验结果
3 Be More with Less: Hypergraph Attention Networks for Inductive Text Classification(HyperGAT)
本文提出了一种基于超图结构数据的模型,HyperGAT。最终将此模型应用到NLP中的文字表示学习上,在当时属于sota方法。
本文提出的模型与 DHGNN 中提到的模型有一些区别,主要表现在节点注意力的计算方式和超边注意力的计算方式上,个人任务 DHGNN 中的计算方式更常规,因此本文不再介绍。另外,本文的实验baseline也主要基于文本分类任务,没有太多参考价值。
4 Dual-view hypergraph neural networks for attributed graph learning (DHGNN)
之前写好的没保存,就不重新写了。整体感觉不太靠谱。基本思路是将普通图从结构和属性两种角度分别构造超图,共同学习,分别得到结构超图的 embedding (z^s) 和属性超图的 embedding (z^a) ,然后再引入注意力机制融合两个 embedding, 得到最终的 embedding (z),用于下游任务。对比其他的图 embedding 算法,该方法是sota的。
实验效果