Java Stream使用
这段时间在学数据库和Java,发现Java的Stream实际上和数据库的查询操作非常类似。这里简单介绍Stream的用法,并和Sql Server中的操作联系起来。
此文为初学Stream所写,以后对Stream有更深的理解后会重写
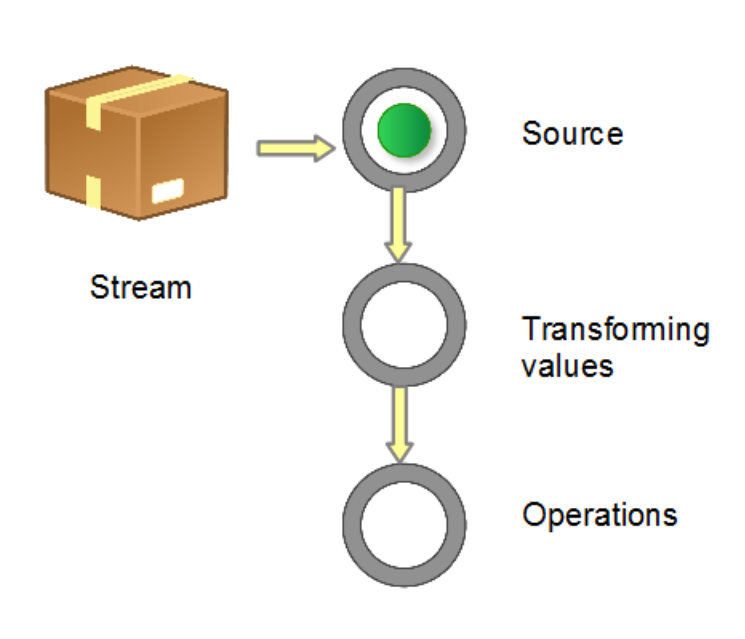
当我们使用一个流的时候,通常包括三个基本步骤:
- 获取一个数据源(source)
- 数据转换
- 执行操作获取想要的结果
每次转换原有 Stream 对象不改变,返回一个新的 Stream 对象(可以有多次转换),这就允许对其操作可以像链条一样排列,变成一个管道,如下图所示。
一、创建 stream
有多种方式生成 Stream Source:
-
从 Collection 和数组
- Collection.stream()
- Collection.parallelStream()
- Arrays.stream(T array) or Stream.of()
从 BufferedReader
- java.io.BufferedReader.lines()
-
静态工厂
- java.util.stream.IntStream.range()
- java.nio.file.Files.walk()
-
自己构建
- java.util.Spliterator
- 其它
- Random.ints()
- BitSet.stream()
- Pattern.splitAsStream(java.lang.CharSequence)
- JarFile.stream()
创建Stream示例
// 1. Individual values
Stream stream = Stream.of("a", "b", "c");
// 2. Arrays
String [] strArray = new String[] {"a", "b", "c"};
stream = Stream.of(strArray);
stream = Arrays.stream(strArray);
// 3. Collections
List<String> list = Arrays.asList(strArray);
stream = list.stream();
二、stream 操作
stream的操作分为两大类,一类为中间操作,一类为终端操作。
中间操作:返回值仍然为一个流,不会消耗流
终端操作:返回最终结果;终端操作会消耗掉流,使之不再可用
1.stream.filter()
stream.filter() 是一个中间操作
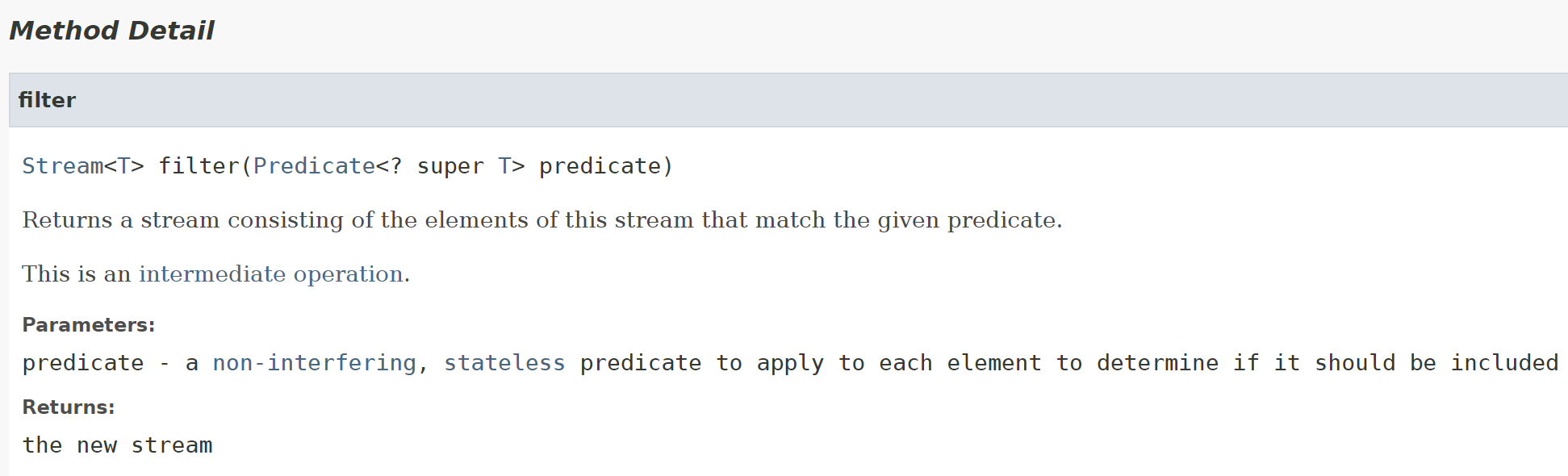
stream.filter()用于对stream进行某种筛选,stream.filter() 相当于Sql server 中,from ... where ...
在filter()中应当给出筛选条件,准确的说,应该实现Predicate接口,这个接口将被应用于stream中的每一个元素,判断其是否应该被包含在结果stream中。
这个接口只有一个抽象方法待用户实现

抽象方法应该返回一个布尔值,当布尔值为真时,stream.filter()将这个元素包含在结果stream中
stream.filter()使用示例:创建Integer流,然后筛选出偶数
ArrayList<Integer> arrlist = new ArrayList<Integer>();
Stream<Integer> st = arrlist.stream();
Stream<Integer> st2 = st.filter(new Predicate<Integer>() {
@Override
public boolean test(Integer arg0) {
return arg0 % 2 == 0;
}
});
还可以用lambda表达式来实现
ArrayList<Integer> arrlist = new ArrayList<Integer>();
Stream<Integer> st = arrlist.stream();
Stream<Integer> st2 = st.filter((o1)->(o1 % 2 == 0));
关于Predicate接口,它还有.and(),.or(),.negate(),.isEqual()四个默认方法,这里不多介绍。但这些方法也十分常用,对于稍微复杂一点的逻辑就需要使用。
使用Precicate接口需要导入
import java.util.function.Predicate;

2.stream.map()
stream.map()是一个中间操作
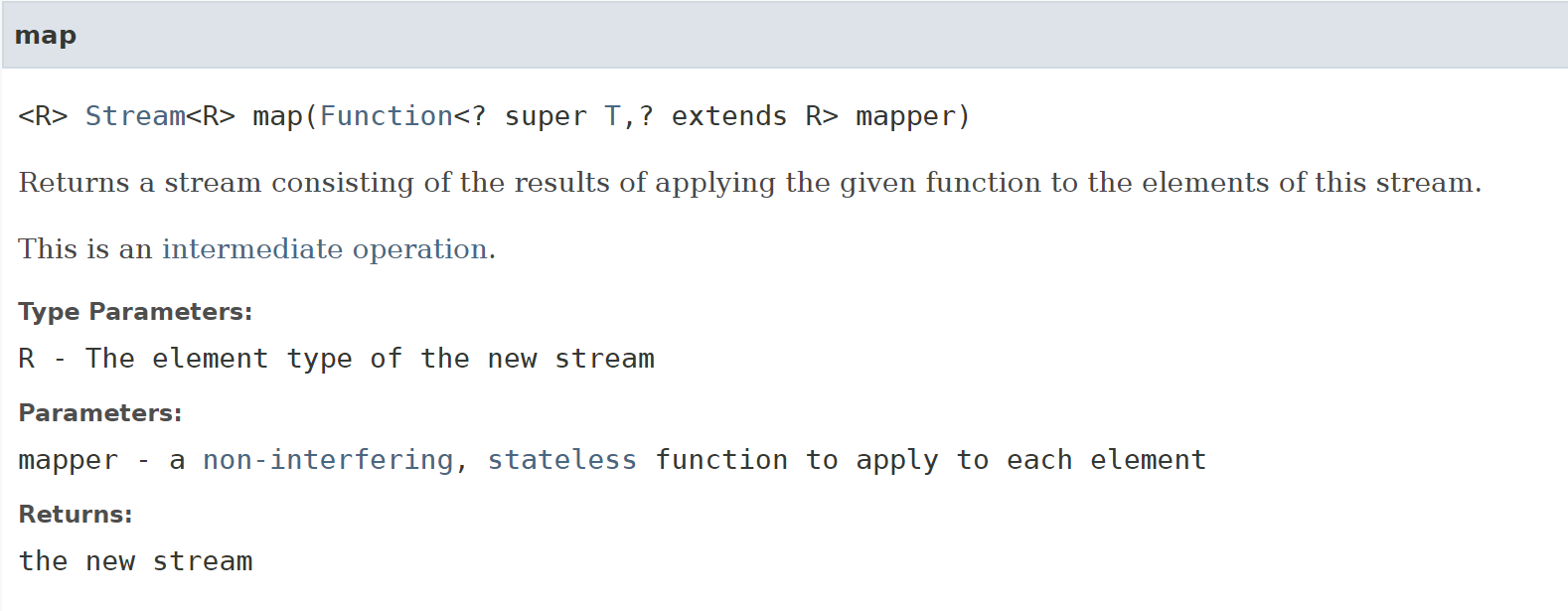
stream.map()用于对stream进行某种映射,stream.map() 相当于Sql server 中,select
虽然这么说不太恰当,因为Sql sever 的select实际上时 SQL语言中 (sigma , prod)的加和,而stream.map() 应该是(prod).
在stream.map()中应该指定转换条件,准确的说,应该实现一个Function()接口,这个接口将被用于stream的每一个元素,将元素按照一定的映射关系映射成新的元素。
Function接口的参数意义

使用Function接口需要导入
import java.util.function.Function;
这个接口只有一个抽象方法待用户实现

抽象方法apply() 接受一个T类型的参数,返回一个R类型的结果
stream.map()使用示例:创建Integer流,然后映射到其原值的两倍
ArrayList<Integer> arrlist = new ArrayList<Integer>();
for(int i = 1; i <= 5; i++) {
arrlist.add(i);
}
Stream<Integer> st = arrlist.stream();
Stream<Integer> st2 = st.map(new Function<Integer,Integer>() {
@Override
public Integer apply(Integer arg0) {
return arg0 * 2;
}
});
ArrayList<Integer> ans = new ArrayList<Integer>();
ans = (ArrayList<Integer>) st2.collect(Collectors.toList());
for(Integer i : ans) {
System.out.print(i + " ");
}
还可以用lambda表达式来实现
// 初学可以先不这么写
ArrayList<Integer> ans = (ArrayList<Integer>)arrlist.stream()
.map((o1)->(2*o1))
.collect(Collectors.toList());
stream.map() 的几种其他形式
IntStream mapToInt(ToIntFunction<? super T> mapper);
LongStream mapToLong(ToLongFunction<? super T> mapper);
DoubleStream mapToDouble(ToDoubleFunction<? super T> mapper);
这三者实际上是对(Function<T,R>) 中 R的固定封装
3.stream.flatMap()
stream.flatMap()是一个中间操作

stream.flatMap()和stream.map()都是进行映射的方法,区别在于,flatMap()处理的元素类型仍是流,flagMap用于将若干个流先拆分成若干个单个元素,再整合成一个流,即流的合并。
简单来说,flatMap()将集合的集合降维成单个元素的集合
实例: 将数组([[1,2,3],[4,5,6],[7,8],[9]])转化为[1,2,3,4,5,6,7,8,9]
ArrayList<ArrayList<Integer>> list_2 = new ArrayList<>();
list_2.add(new ArrayList<>(Arrays.asList(1,2,3)));
list_2.add(new ArrayList<>(Arrays.asList(4,5,6)));
list_2.add(new ArrayList<>(Arrays.asList(7,8)));
list_2.add(new ArrayList<>(Arrays.asList(9)));
ArrayList<Integer> list_1 = (ArrayList<Integer>) list_2.stream()
// list_2.stream() 为 "[1,2,3]" "[4,5,6]" "[7,8]" "[9]" 每个""表示流的不同元素
.flatMap((o1)->(o1).stream())
// 以 o1 = "[1,2,3]"为例,(o1)->(o1).stream() 转化为"1","2","3"
.collect(Collectors.toList());
for(Integer i : list_1) {
System.out.print(i+" ");
}
stream.flagMap()的几种其他形式
IntStream flatMapToInt(Function<? super T, ? extends IntStream> mapper);
LongStream flatMapToLong(Function<? super T, ? extends LongStream> mapper);
DoubleStream flatMapToDouble(Function<? super T, ? extends DoubleStream> mapper);
这三者实际上是对(Function<T,R>) 中 R的固定封装
4.stream.allMatch() ,stream.anyMatch() 和 stream.noneMatch()
stream.allMatch() 和 stream.anyMatch()均为终端操作

传入一个Predicate函数式接口,用于指定条件
5.stream.collect()
stream.collect()为终端操作

Stream的核心在于collect,即对数据的收集。
- 用法一:将流转化为Collection或Map
Collectors.toCollection() 将数据转换成Collection,只要是Collection的实现都可以,例如ArrayList,HashSet,该方法能够接受一个Collection对象
示例:
//List
Stream.of(1,2,3,4,5,6,7,8,9).collect(Collectors.toCollection(ArrayList::new));
//Set
Stream.of(1,2,3,4,5,6,7,8,9).collect(Collectors.toCollection(HashSet::new));
// Stream.of(1,2,3,4,5,6,7,8,9).collect(Collectors.toList());
// Stream.of(1,2,3,4,5,6,7,8,9).collect(Collectors.toSet());
// Stream.of(1,2,3,4,5,6,7,8,9).collect(Collectors.toMap(key,value));
- 用法二:字符串聚合规约
Collectors.joining(),拼接,有三个重载方法,底层实现是StringBuilder,通过append方法拼接到一起,并且可以自定义分隔符(这个感觉还是很有用的,很多时候需要把一个list转成一个String,指定分隔符就可以实现了,非常方便)、前缀、后缀。
Student studentA = new Student("20190001", "小明");
Student studentB = new Student("20190002", "小红");
Student studentC = new Student("20190003", "小丁");
//使用分隔符:201900012019000220190003
Stream.of(studentA, studentB, studentC)
.map(Student::getId)
.collect(Collectors.joining());
//使用^_^ 作为分隔符
//20190001^_^20190002^_^20190003
Stream.of(studentA, studentB, studentC)
.map(Student::getId)
.collect(Collectors.joining("^_^"));
//使用^_^ 作为分隔符
//[]作为前后缀
//[20190001^_^20190002^_^20190003]
Stream.of(studentA, studentB, studentC)
.map(Student::getId)
.collect(Collectors.joining("^_^", "[", "]"));
- 用法三:统计个数
Collectors.counting() 统计元素个数,这个和Stream.count() 作用都是一样的,返回的类型一个是包装Long,另一个是基本long,但是他们的使用场景还是有区别的,这个后面再提。
// Long 8
Stream.of(1,0,-10,9,8,100,200,-80)
.collect(Collectors.counting());
//如果仅仅只是为了统计,那就没必要使用Collectors了,那样更消耗资源
// long 8
Stream.of(1,0,-10,9,8,100,200,-80)
.count();
- 用法四:集合分组
Collectos.groupingBy()实现集合分组,返回值为一个Map
假如现在有一个实体Student
public class Student {
private String name;
private int score;
private int age;
public Student(String name,int score,int age){
this.name = name;
this.score = score;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getScore() {
return score;
}
public void setScore(int score) {
this.score = score;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
}
现在对其按照Name分组
Map<String,List<Student>> StrListStrMap = students.stream()
.collect(Collectors.groupingBy(Student::getName));
6.stream.forEach() 和
stream.forEach() 终端操作
stream.forEach()遍历流中的每一个元素,不一定依靠流的顺序,而stream.forEachOrdered()按照流的顺序遍历。
Stream.of(1,2,3,4,5,6).forEach(System.out::println);
7.stream.max() , stream.min() , stream.count()
三个终端操作
-
stream.max()返回流中的最大值
-
stream.min()返回流中的最小值
未传入Comparator则填null,默认用Comparable的compareTo函数比较。
- stream.count()返回流中元素个数
8.stream.findAny()
返回流中任意一个元素,如果流为空,返回一个空的Optional.
List<Integer> list = Arrays.asList(1, 2, 3, 4, 5, 6);
Optional<Integer> any = list.stream().findAny();
参考