一、Kafka消费者源码介绍
1.分区消费模式源码介绍

分区消费模式直接由客户端(任何高级语言编写)使用Kafka提供的协议向服务器发送RPC请求获取数据,服务器接受到客户端的RPC请求后,将数据构造成RPC响应,返回给客户端,客户端解析相应的RPC响应获取数据。
Kafka支持的协议众多,使用比较重要的有:
获取消息的FetchRequest和FetchResponse
获取offset的OffsetRequest和OffsetResponse
提交offset的OffsetCommitRequest和OffsetCommitResponse
获取Metadata的Metadata Request和Metadata Response
生产消息的ProducerRequest和ProducerResponse
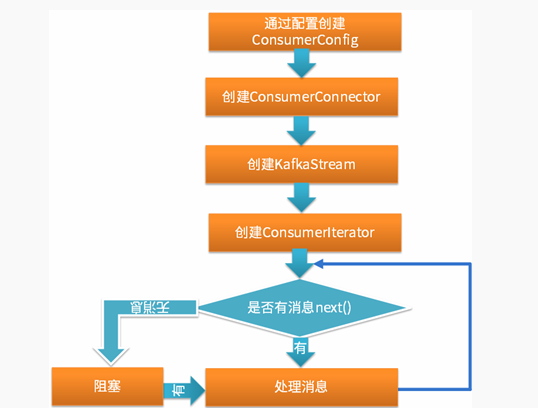
2.组消费模式源码介绍

3.两种消费模式服务器端源码对比
分区消费模式具有以下特点:
指定消费topic、partition和offset通过向服务器发送RPC请求进行消费;
需要自己提交offset;
需要自己处理各种错误,如:leader切换错误
需要自己处理消费者负载均衡策略
组消费模式具有以下特点:
最终也是通过向服务器发送RPC请求完成的(和分区消费模式一样);
组消费模式由Kafka服务器端处理各种错误,然后将消息放入队列再封装为迭代器(队列为FetchedDataChunk对象) ,客户端只需在迭代器上迭代取出消息;
由Kafka服务器端周期性的通过scheduler提交当前消费的offset,无需客户端负责
Kafka服务器端处理消费者负载均衡
监控工具Kafka Offset Monitor 和Kafka Manager 均是基于组消费模式;
所以,尽可能使用组消费模式,除非你需要:
自己管理offset(比如为了实现消息投递的其他语义);
自己处理各种错误(根据自己业务的需求);
二、Kafka生产者源码介绍
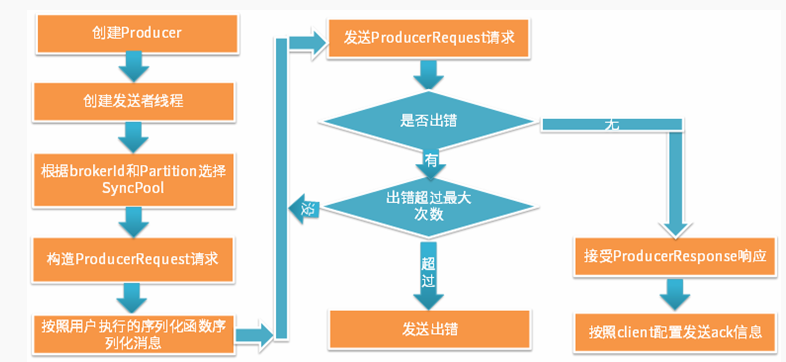
1.同步发送模式源码介绍
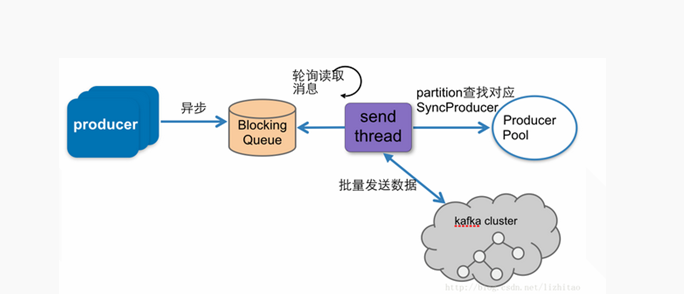
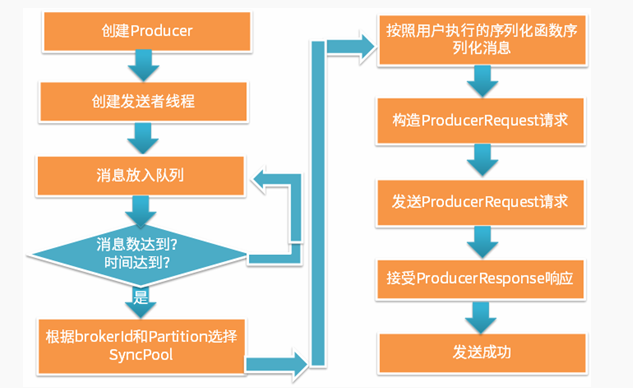
2.异步发送模式源码介绍
3.两种生产模式服务器端源码对比
同步发送模式具有以下特点:
同步的向服务器发送RPC请求进行生产;
发送错误可以重试;
可以向客户端发送ack;
异步发送模式具有以下特点:
最终也是通过向服务器发送RPC请求完成的(和同步发送模式一样);
异步发送模式先将一定量消息放入队列中,待达到一定数量后再一起发送;
异步发送模式不支持发送ack,但是Client可以调用回调函数获取发送结果;
所以,性能比较高的场景使用异步发送,准确性要求高的场景使用同步发送
三、Kafka Server Reactor设计模型
1.认识Java NIO
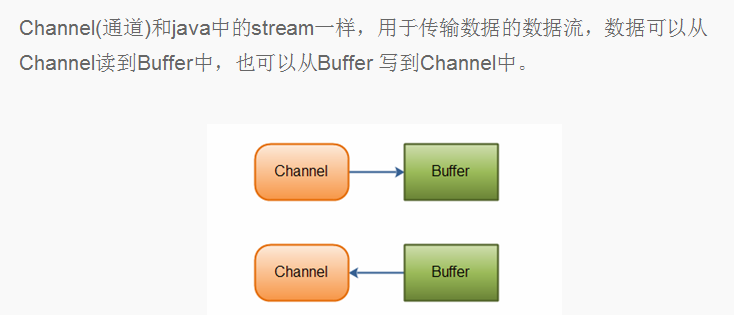
Java NIO由以下几个核心部分组成 :
Channels;
Buffers;
Selectors
2.认识Linux epoll模型
epoll 是一种IO多路复用技术 ,在linux内核中广泛使用。常见的三种IO多路复用技术为select模型、poll模型和epoll模型。
select 模型需要轮询所有的套接字查看是否有事件发生 。缺点: (1)套接字最大支持1024个;(2)主动轮询效率很低;(3) 事件发生后需要将套接字从内核空间拷贝到用户空间,效率低
poll模型和select模型原理一样,但是修正了select模型最大套接字限制的缺点;
epoll模型修改主动轮询为被动通知,当有事件发生时,被动接收通知。所以epoll模型注册套接字后,主程序可以做其他事情,当事件发生时,接收到通知后再去处理。修正了select模型的三个缺点(第三点使用共享内存修正)。
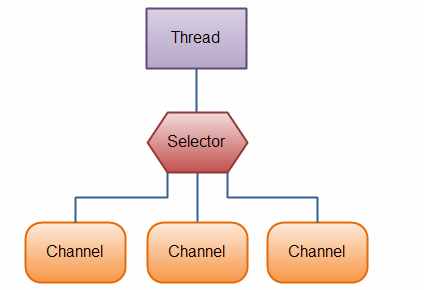
Java NIO的Selector模型底层使用的就是epoll IO多路复用模型
3.Kafka Server Reactor模型
Kafka SocketServer是基于Java NIO开发的,采用了Reactor的模式(已被大量实践证明非常高效,在Netty和Mina中广泛使用)。Kafka Reactor的模式包含三种角色:
Acceptor;
Processor ;
Handler;
Kafka Reacator包含了1个Acceptor负责接受客户端请求,N个Processor线程负责读写数据(为每个Connection创建出一个Processor去单独处理,每个Processor中均引用独立的Selector),M个Handler来处理业务逻辑。在Acceptor和Processor,Processor和Handler之间都有队列来缓冲请求。
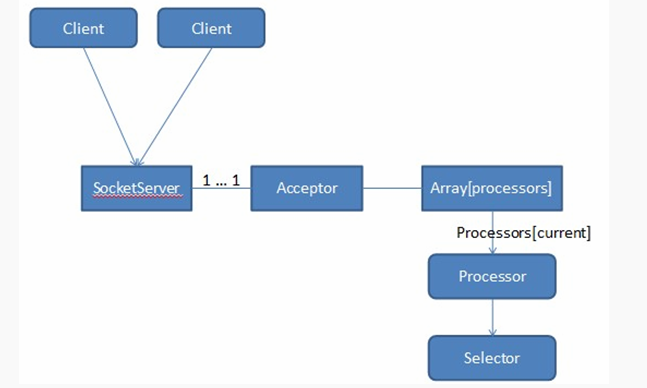
Acceptor的主要职责是监听客户端的连接请求,并建立和客户端的数据传输通道,然后为这个客户端指定一个Processor,它的工作就到此结束,这样它就可以去响应下一个客户端的连接请求了;
Processor的主要职责是负责从客户端读取数据和将响应返回给客户端,它本身不处理具体的业务逻辑,每个Processor都有一个Selector,用来监听多个客户端,因此可以非阻塞地处理多个客户端的读写请求,Processor将数据放入RequestChannel的RequestQueue 中和从ResponseQueue读取响应 ;
Handler(kafka.server.KafkaRequestHandler,kafka.server.KafkaApis)的职责是从RequestChannel中的RequestQueue取出Request,处理以后再将Response添加到RequestChannel中的ResponseQueue中;
四、Kafka Partition Leader选举机制
1.大数据常用的选主机制
Leader选举算法非常多,大数据领域常用的有 以下两种:
Zab(zookeeper使用);
Raft;
……
它们都是Paxos算法的变种。
Zab协议有四个阶段:
Leader election;
Discovery(或者epoch establish);
Synchronization(或者sync with followers)
Broadcast
比如3个节点选举leader,编号为1,2,3。1先启动,选择自己为leader,然后2启动首先也选择自己为 leader,由于1,2都没过半,选择编号大的为leader,所以1,2都选择2为leader,然后3启动发现1,2已经协商好且数量过半,于是3也选择2为leader,leader选举结束。
在Raft中,任何时候一个服务器可以扮演下面角色之一
Leader: 处理所有客户端交互,日志复制等,一般只有一个Leader;
Follower: 类似选民,完全被动
Candidate候选人: 可以被选为一个新的领导人
启动时在集群中指定一些机器为Candidate ,然后Candidate开始向其他机器(尤其是Follower)拉票,当某一个Candidate的票数超过半数,它就成为leader。
2.常用选主机制的缺点
由于Kafka集群依赖zookeeper集群,所以最简单最直观的方案是,所有Follower都在ZooKeeper上设置一个Watch,一旦Leader宕机,其对应的ephemeral znode会自动删除,此时所有Follower都尝试创建该节点,而创建成功者(ZooKeeper保证只有一个能创建成功)即是新的Leader,其它Replica即为Follower。
前面的方案有以下缺点:
split-brain (脑裂): 这是由ZooKeeper的特性引起的,虽然ZooKeeper能保证所有Watch按顺序触发,但并不能保证同一时刻所有Replica“看”到的状态是一样的,这就可能造成不同Replica的响应不一致 ;
herd effect (羊群效应): 如果宕机的那个Broker上的Partition比较多,会造成多个Watch被触发,造成集群内大量的调整;
ZooKeeper负载过重 : 每个Replica都要为此在ZooKeeper上注册一个Watch,当集群规模增加到几千个Partition时ZooKeeper负载会过重
3.Kafka Partition选主机制
Kafka 集群controller的选举过程如下 :
每个Broker都会在Controller Path (/controller)上注册一个Watch。当前Controller失败时,对应的Controller Path会自动消失(因为它是ephemeral Node),此时该Watch被fire,所有“活”着的Broker都会去竞选成为新的Controller(创建新的Controller Path),但是只会有一个竞选成功(这点由Zookeeper保证)。竞选成功者即为新的Leader,竞选失败者则重新在新的Controller Path上注册Watch。因为Zookeeper的Watch是一次性的,被fire一次之后即失效,所以需要重新注册。
Kafka partition leader的选举过程如下 (由controller执行):
从Zookeeper中读取当前分区的所有ISR(in-sync replicas)集合
调用配置的分区选择算法选择分区的leader

所以,对于下图partition 0先选择broker 2,之后选择broker 0作为leader;对于partition 1 先选择broker 0,之后选择broker 1作为leader;partition 2先选择broker 1,之后选择broker 2作为leader。
