现在Redis越来越火,为了适应技术的发展,开始学习一下Redis,在学习Redis之前先学习一下Nosql。
第一部分:入门概述
1.1 互联网时代背景下大机遇,为什么用nosql
1.1.1 单机Mysql的美好年代(好几年前)
当时的业务很相对简单,就是JSP--->Action---->Service---->DAO----->数据库,数据库也就是一个实例而已,无论是Mysql还是Oracle。把这五层缩减为三层的话便是:应用层------>DAO层------>Mysql实例。

以前一个网站的访问量一般不大,用单个数据库可以轻松应付。但是随着时代的发展,上述数据存储遇到了存储的瓶颈:
1) 数据量的总大小,一个机器放不下时(以Mysql为例,单表存储大概三百多万的数据的时候DBA就该进行预警并优化分割了)
2) 数据的索引(B+Tree),一个机器的内存放不下时(众所周知,为表建立索引也是需要消耗内存的,当我们所建立的索引内存盛不下时)
3) 访问量(读写混合)一个实例不能承受
1.1.2 Memcached(缓存)+MySQL+垂直拆分
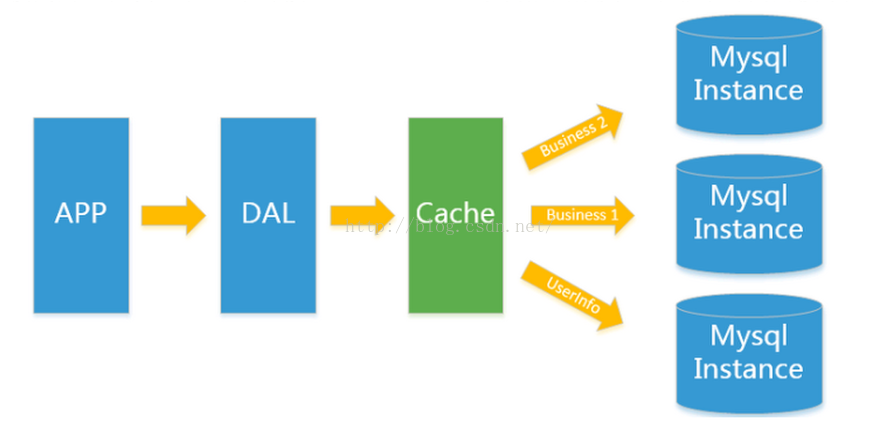
后来,随着访问量的上升,几乎大部分使用MySQL架构的网站在数据库上都开始出现了性能问题,web程序不再仅仅专注在功能上,同时也在追求性能。程序员们开始大量的使用缓存技术来缓解数据库的压力,优化数据库的结构和索引。开始比较流行的是通过文件缓存(MongoDB)来缓解数据库的压力,但是当访问量继续增大的时候,多 台web机器通过文件缓存不能共享,大量的小文件缓存也带来了比较高的IO压力。在这个时候,Memcached就自然的成为一个非常时尚的技术产品。如下图所示,我们所 说的Memcached及Redis其实都在Cache这一层。Memcached或Redis相当于在DAO层与数据库实例之间挡了一层,众所周知,对数据库来说,压力主要来自于大量频繁的 查询,我们把频繁查询并且固定的数据放到缓存当中,这样以后查询的时候就会从缓存中去读取数据,从而减轻了数据库的压力。同时,Mysql数据库的实例也由原来的一 个变成了多个,数据被分别存储到不同的数据库实例当中。
1.1.3 Mysql主从复制,读写分离
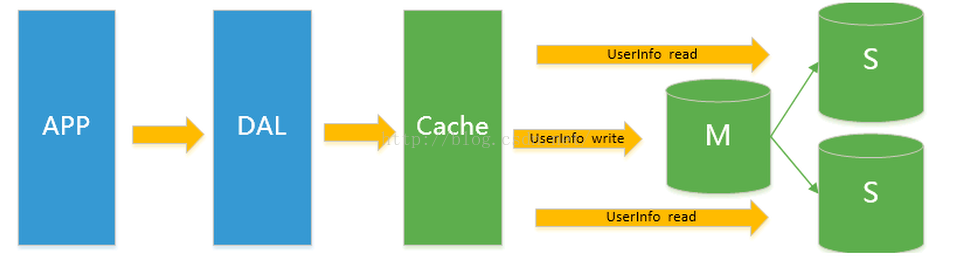
由于数据库的写入压力增加,Memcached只能缓解数据库的读取压力。读写集中在一个数据库上让数据库不堪重负,大部分网站开始使用主从复制技术来达到读写分离以提高读写性能和读库的可扩展性。Mysql的master-slave成为这个时候的网站标配了。Mysql数据库有多个实例,其中有一个主库(M),有多个从库(S),如果用户在主库插入一条数据,为了数据的安全,需要马上向从库也插入一条相同的数据(这就是主从复制),这样当主库出现问题的时候,就可以通过从库进行数据恢复;读写分离是指,主库只负责写操作,从库只负责读操作,因为对于现实用户的行为来说,读写的操作要远远少于查询的操作,因此我们专门用一台设备来存储用户的写操作,用多台设备来共同分担查询的压力,这样就比传统的单数据库的性能提升很多倍。如下图所示:
1.1.4 分表分库+水平拆分+mysql集群
在Memcached的高速缓存,MySQL的主从复制,读写分离的基础之上,这时MySQL主库的写压力开始出现瓶颈,而数据量的持续猛增,由于MyISAM使用表锁,在高并发 下会出现严重的锁问题,大量的高并发MySQL应用开始使用InnoDB(行锁)引擎代替MyISAM。
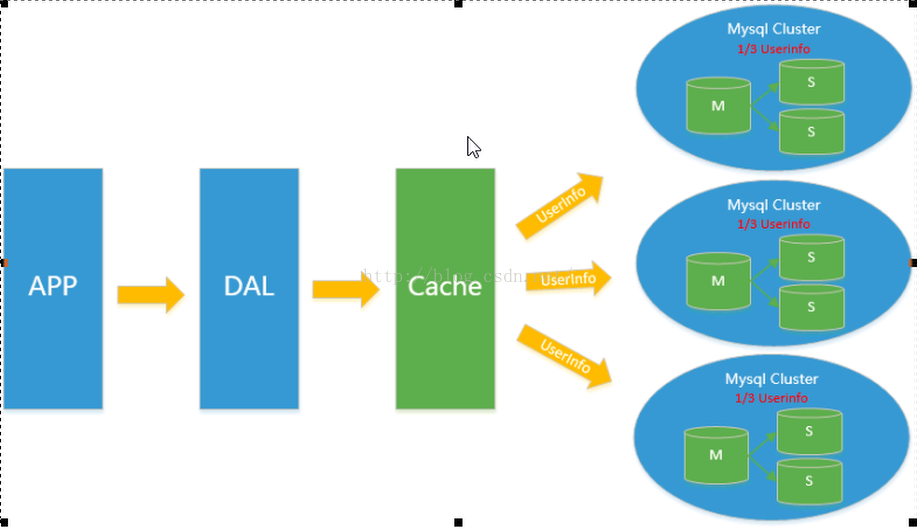
同时,开始流行使用分表分库来缓解写压力和数据增长的扩展问题。这个时候,分表分库成了一个热门技术,是面试的热门问题也是业界讨论的热门技术问题。也就在这个时候,MySQL推出了还不太稳定的表分区,这也给技术实力一般的公司带来了希望。虽然MySQL推出了MySQL Cluster集群,但性能也不能很好满足互联网的要求,只是在高可靠性上提供了非常大的保证。如下图所示。假如有九千万条的数据,如果都存到一个数据库,肯定受不了,但是如果把这九千万条数据分成三部分,头三千万存到1号库,中间三千万条存到2号库,后三千万条存到3号库,这样每个数据库的实例的压力就会小很多,查询的时候只需到相应的库中去查询即可。
1.1.5 MySQL的扩展性瓶颈
MySQL数据库也经常存储一些大文本字段,导致数据库表非常的大,在做数据库恢复的时候就导致非常的慢,不容易快速恢复数据库。比如1000万4KB大小的文本就 接近40GB的大小,如果能把这些数据从MySQL省去,MySQL将变得非常的小。关系数据库很强大,但是它并不能很好的应付所有的应用场景。MySQL的扩展性差(需要 复杂的技术来实现),大数据IO压力大,表结构更改困难,正是当前使用MySQL的开发人员面临的问题。
1.1.6 今天
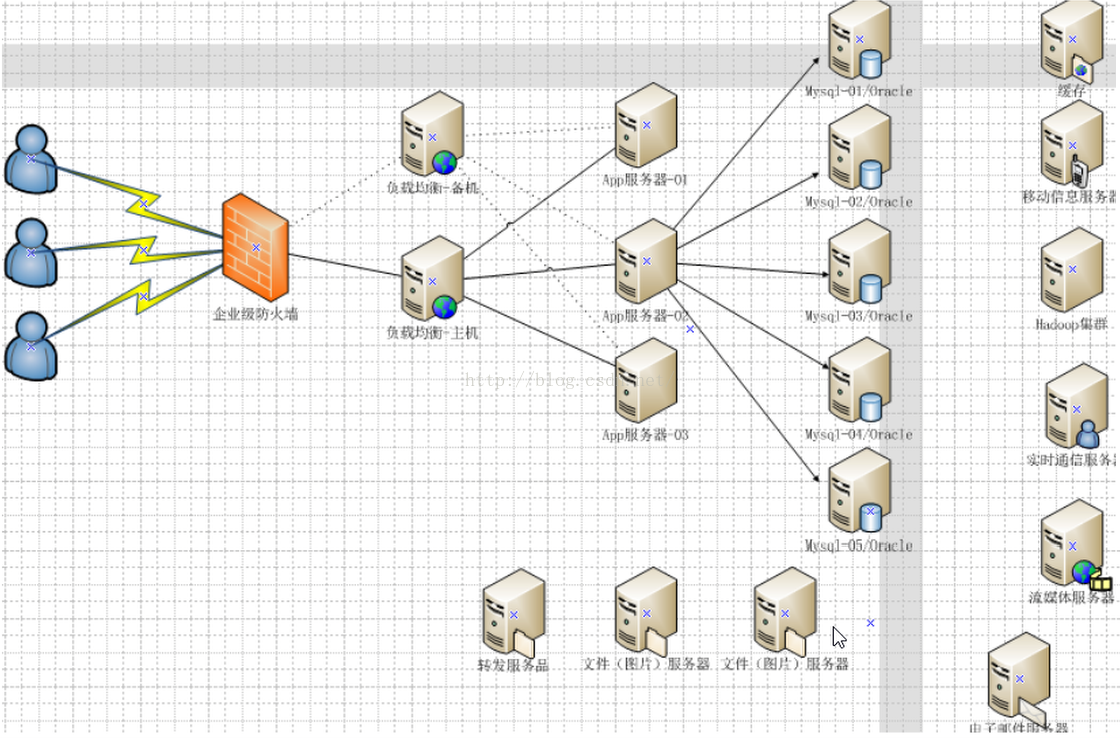
今天的架构如下所示,负载均衡用的是Nginx,App服务器集群(Tomcat集群),数据库集群,再加上分布式缓存等,组成了一个强大的组网图。
1.1.7 为什么用NoSql
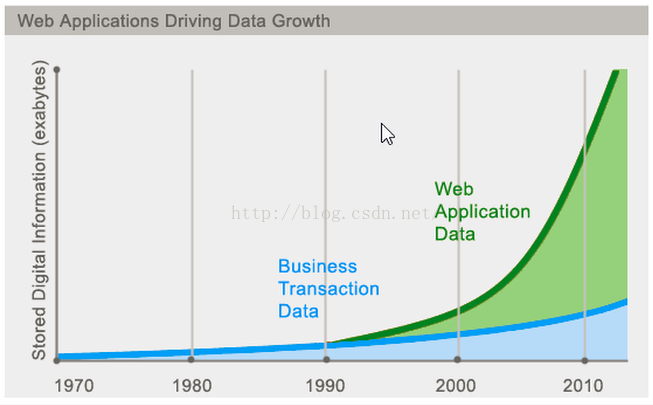
今天我们可以通过第三方平台(如:Google,Facebook等)可以很容易的访问和抓取数据。用户的个人信息,社交网络,地理位置,用户生成的数据和用户操作日志 已经成倍的增加。我们如果要对这些用户数据进行挖掘,那SQL数据库已经不适合这些应用了,NoSQL数据库的发展也却能很好的处理这些大数据。从下面这张图中可以 看到,近几年Web数据成几何倍数增加,我们传统的关系型数据库已经无法满足要求了。
1.2 什么是NoSQL?
NoSQL(NoSQL = Not Only SQL),意即“不仅仅是SQL”,泛指非关系型数据库。随着互联网web2.0网站的兴起,传统的关系型数据库在应付web2.0网站,特别是超大规模 和高并发的SNS类型的web2.0纯动态网站已经显得力不从心,暴露了很多难以克服的问题,而非关系型的数据库则由于其本身的特点得到了非常迅速的发展。NoSQL数据库 的产生就是为了解决大规模数据集合多重数据种类带来的挑战,尤其是大数据应用难题,包括超大规模数据的存储。
(例如谷歌或Facebook每天为他们的用户收集万亿比特的数据),这些类型的数据的存储不需要固定的模式,无需多余操作就可以横向扩展。
1.3 NoSQL能干嘛?
1.3.1 易扩展
NoSQL数据库种类繁多,但是一个共同的特点都是去掉关系数据库的关系型特性。数据之间无关系,这就非常容易扩展。也无形之间,在架构的层面上带来了可扩展的 能力。对于传统关系型数据库来说,对于一张横向或纵向的表,扩展终有限,而且数据类型也就那么几种(比如varchar、int、date、blob、long等),随着业务的发展尤其 是社交网络的发展,亲情之间的关系我们很难用传统数据库去描述(比如:他姑姑家的女儿的大伯父家的儿子的邻居的爸爸的大表舅...这样复杂的人际关系网,我们很难想 象通过传统的关系型数据库去描述),取而代之的是用图来描述。对NoSQL而言,其实就是一大堆key-value键值对,value我们可以随意存放,这就给我们带来了非常大的 灵活性。
1.3.2 大数据量高性能
NoSQL数据库都具有非常高的读写性能(读,一秒钟11万;写,一秒钟8万),尤其在大数据量下,同样表现优秀。这得益于它的无关系型性,数据库的结果简单。
一般MySQL使用Query Cache,每次表的更新Cache就失败,是一种大粒度的Cache,在针对web2.0的交互频繁的应用,Cache性能不高。而NoSQL的Cache是记录级 的,是一种细粒度的Cache,所以NoSQL在这个层面上来说就要性能高很多了。
1.3.3 多样灵活的数据模型
NoSQL无需事先为要存储的数据建立字段,随时可以存储自定义的数据格式。而在关系数据库里,增删字段是一件非常麻烦的事情。如果是非常大的数据量的表,增加 字段就是一个噩梦。
1.3.4 RDBMS(关系型数据库)VS NoSQL(泛指非关系型数据库)
RDBMS
- 高度组织化结构化数据
- 结构化查询语言(SQL)
- 数据和关系都存储在单独的表中
- 数据操纵的语言,数据定义语言
- 严格的一致性
- 基础事务
NoSQL
- 代表着不仅仅是SQL
- 没有声明性查询语言
- 没有预定义的模式
- 键 - 值对存储,列存储,文档存储,图形数据库
- 最终一致性,而非ACID属性
- 非结构化和不可预知的数据
- CAP定理
- 高性能,高可用性和可伸缩性
1.4 去哪下
NoSQL目前比较流行的有Mongoodb、Memcache、Redis三种,其中Mongodb是最像关系型数据库的一种了,主要处理文档,单论缓存的处理能力,Memcache是目前最 牛逼的技术,不过,要处理多样化的数据的话,Redis更强悍。我们下载去官网下载即可。
1.5 怎么玩
NoSQL说白了就是KV键值对、Cache缓存、持久化这三部分(后续会有详解)。
第二部分:3V+3高
2.1 大数据时代的3V
3V分别指海量(Volume)、多样(Variety)、实时(Velocity)
2.2 互联网需求的3高
3高分别是指高并发(高并发不用多说了,就是同一时间的访问量非常大)、高可扩(主要针对的是横向扩展,因为纵向扩展终有瓶颈,比如一台设备一个内存条不够用,我们插两条,一个硬盘不够用,我们再加固态硬盘,但这种方式终究是有限度的,横向扩展是把原来的一台服务器变成一个集群,多台服务器同时提供服务,这种扩展性就很强了,5台不行8台,8台不行10台,而且集群都有负载均衡,从而分配到每台服务器上的请求相对就少了)、高性能(比如单点故障、数据库容灾备份等都要求有很高的性能)
第三部分:当下的NoSQL经典应用
3.1 当下的应用是sql和nosql一起使用
我们不能陷入一个误区,就是认为redis既然很强大,是不是要把oracle、mysql给干掉了,其实不是这样的,现实应用中肯定是两者都用的,它们现在负责的内容不一样,不存在谁干掉谁的问题。
3.2 阿里巴巴中文站商品信息如何存放
3.2.1 阿里巴巴框架的演变,如下所示。
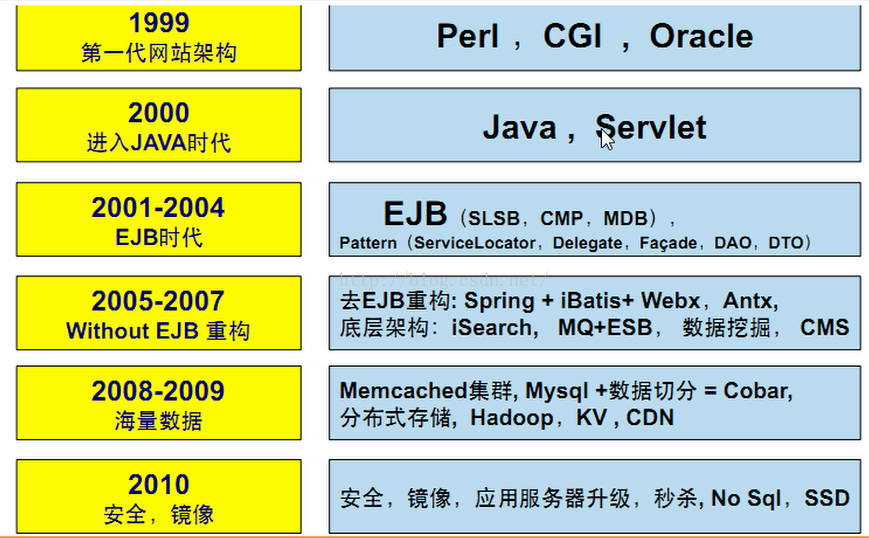
现在阿里巴巴的架构到了第五代,第五代架构的特点是:
1) 敏捷
业务快速增长,每天都要上线大量的小需求;
应用系统日益膨胀,耦合恶化,架构越来越复杂,会带来更高的开发成本,如何保持业务开发敏捷性?
2) 开放
Facebook和AppStore带来的启示,如何提升网站的开放性,吸引第三方开发者加入到网站的共建中来
3) 体验
网站的并发压力快速增长,用户却对体验提出了更高的要求

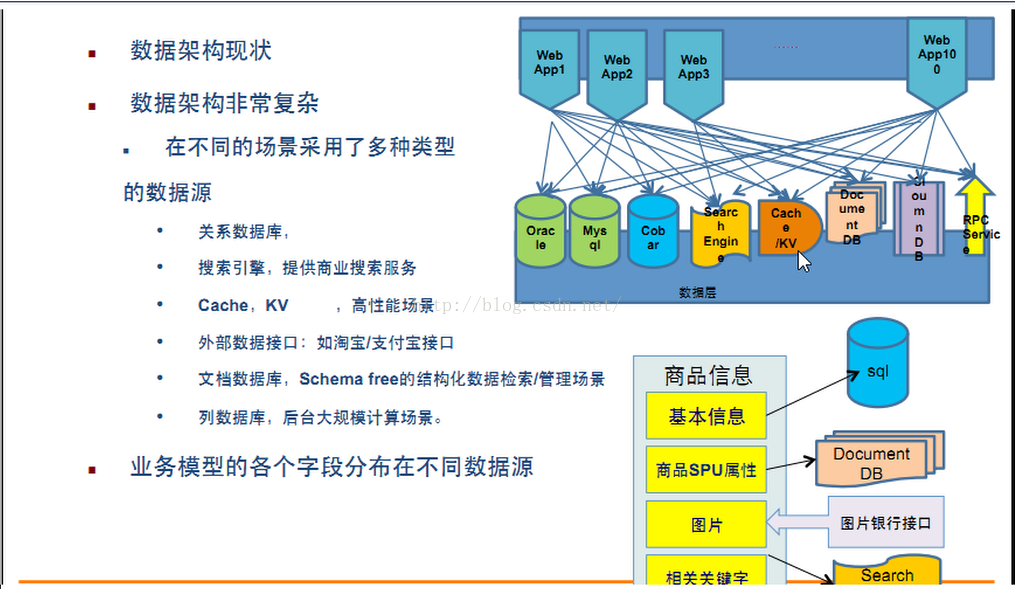
3.2.2 和我们相关的,多数据源、多数据类型的存储问题
多数据源是指我们看到的淘宝商品的文字、图片、视频等内容不是来自于同一源头,而是来自于不同的源头,多数据类型,也就很明显了,就是我们要存储的内容不仅有文本,还有图片还有声音还有视频,不同的数据类型我们往往要存储到不同的地方。下面是淘宝架构图,可见是非常复杂的。
3.3 商品基本信息
包括名称、价格、出厂日期、生产厂商等,这些信息我们称为冷数据,就是一般情况下不会发生改变,像这样的数据我们一般把它们存放到关系型数据库当中。目前淘宝已经逐渐去掉Oracle数据库了,关系型数据库用的主要是MySQL,不过他们用的MySQL是经过改造的,与我们所用的MySQL已经不是同一个东西了。淘宝主张去“IOE”(在IT建设过程中,去除IBM小型机、Oracle数据库及EMC存储设备),阿里巴巴集团首席架构师王坚这样概括“去IOE”运动和阿里云之间的关系:“去IOE”彻底改变了阿里集团IT架构师的基础,是阿里拥抱云计算,产出计算服务的基础。“去IOE”的本质是分布化,让随处可以买到的Commodity PC架构成为可能,使云计算能够落地的首要条件。众所周知,Oracle数据库是非常昂贵的,一般的公司根本买不起,去掉Oracle,让更多的公司通过使用廉价的数据库就能满足自己的需求,这将是改变中国IT界的一件大事。
3.4 商品描述、详情、评价信息(多文字类)
多文字信息描述类,IO读写性能变差,把它们存储到文档数据库MongoDB当中
3.5 商品的图片
商品图片的展现类存储在分布式的文件系统当中,比如淘宝自己的TFS,Google的GFS,Hadoop的HDFS。
3.6 商品的关键字(搜索框)
淘宝用的是他们自己开发的ISearch
3.7 商品的波段性的热点高频信息
比如情人节,玫瑰花和巧克力肯定是搜索量很大的,淘宝将可以预测到的热搜的内容提前存放到了内存数据库(Tair、Redis、Memcache)
3.8 商品的交易、价格计算、积分累计
外部系统,外部第3方支付接口或支付宝
3.9 总结大型互联网应用(大数据、高并发、多样数据类型)的难点和解决方案
3.9.1 难点:
1) 数据类型多样化
2) 数据源多样性和变化重构
3) 数据源改造而数据服务平台不需要大面积重构
3.9.2 解决办法
淘宝的做法是实现了一套统一数据平台服务UDSL
第四部分:NoSQL数据模型简介
4.1 以一个电商客户、订单、订购、地址模型来对比下关系型数据库和非关系型数据库
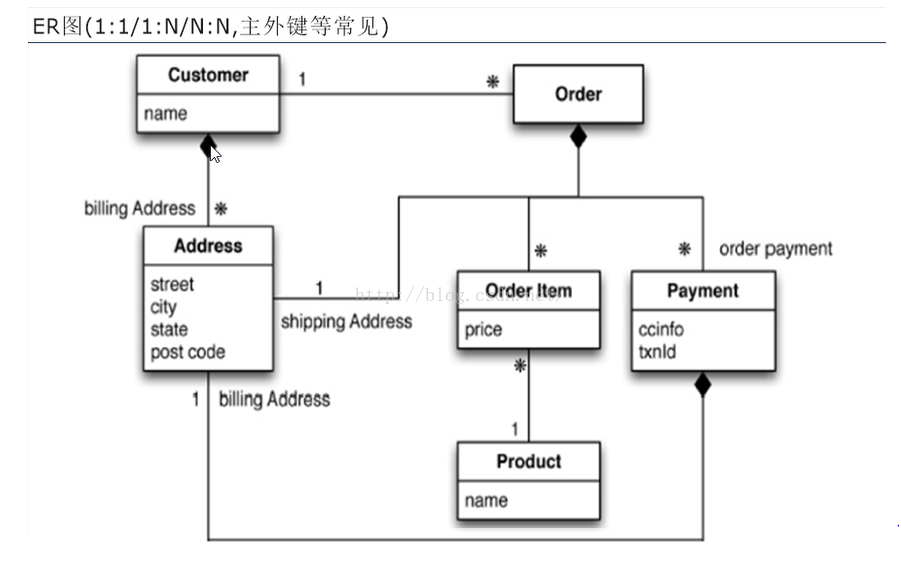
4.1.1 传统的关系型数据库你如何设计?主要通过ER图(1:1/1:N/N:N,主外键等常见),一个顾客与订单Order显然是一对多的关系,同理,一个顾客也可以有多个收件地址(最常见的莫过于公司一个地址还有住的地方一个地址),一个Order可能对应多个Order Item(比如饮品类、书类、衣服类)同理,Product(商品)与Order Item也是一对多的关系。订单与支付也是一对多的关系(支付的方式多种多样嘛)
4.1.2 NoSQL 你如何设计
4.1.2.1 什么是BSON,BSON()是一种类似json的一种二进制形式的存储格式,简称Binary JSON,它和JSON一样,支持内嵌的文档对象和数组对象
4.1.2.2 用BSON来表示上面ER图所示的关系,可以看出用BSON来表示ER关系图明显是比ER关系图灵活很多,我们可以单独把里面的json字符串拿出来。
{
"customer":{
"id":1136,
"name":"Z3",
"billingAddress":[{"city":"beijing"}],
"orders":[
"id":17,
"customerId":1136,
"orderItems":[{"productId":27,"price":77.5,"productName":"thinking in java"}],
"shippingAddress":[{"city":"beijing"}],
"orderPayment":[{"cciinfo":"111-222-333","tenid":"asdfadcd334","billingAddress":{"city":"beijing"}}],
}
]
}
}
高并发的操作是不太建议有关联查询的,互联网公司用冗余数据来避免关联查询。
分布式事务是支持不了太多的并发的。
我们传统的关系型数据库如果要查询出来ER图的关系的话,需要多次进行join操作,既复杂又容易出错,但是用BSON来存储的话,我们只需要一个customerId便可以得到一个完整的json字符串,所有的信息都在里面,从而避免进行表关联。
4.2 聚合模型
4.2.1 KV值
4.2.2 BSON
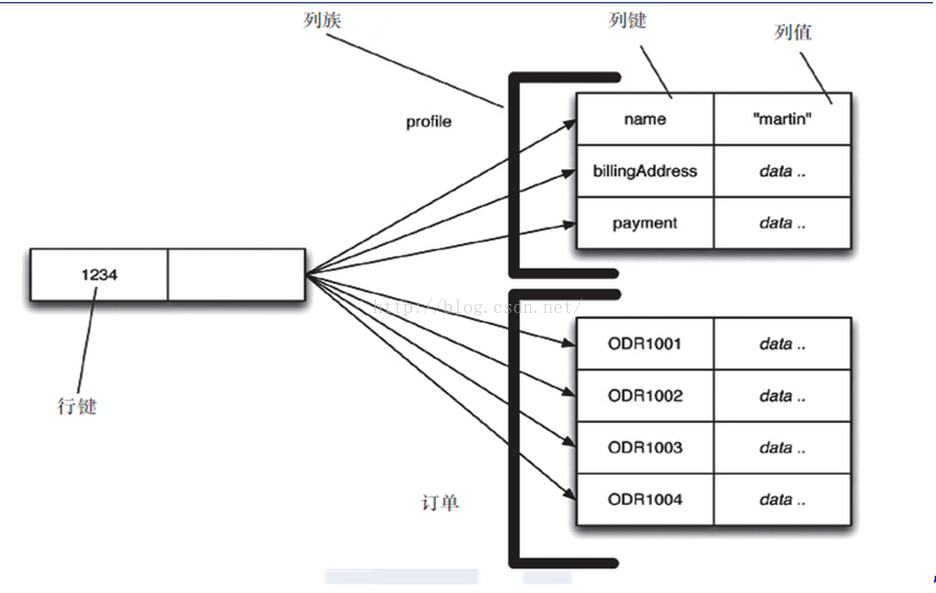
4.2.3 列族
顾名思义,是按列存储数据的,最大的特点是方便存储结构化和半结构化数据,方便做数据压缩,对针对某一列或者某几列的查询有非常大的IO优势。
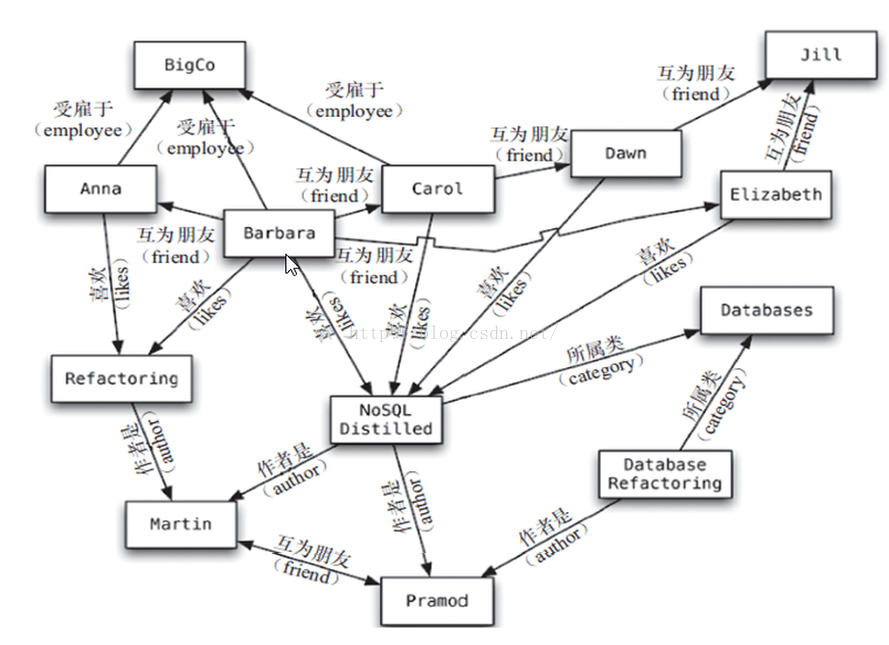
4.2.4 图表
第五部分:NoSQL数据库的四大分类
5.1 KV键值:典型介绍
目前,新浪:BerkeleyDB+redis
美团:redis+tair
阿里、百度:memcache+redis
5.2 文档型数据库(bson格式比较多):典型介绍
CouchDB
MongoDB:是一个基于分布式文件存储的数据库。由C++语言编写。旨在为WEB应用提供可扩展的高性能数据存储解决方案。
MongoDB是一个介于关系数据库和非关系型数据库之间的产品,是非关系数据库当中功能最丰富,最像关系数据库的。
5.3 列存储数据库
Cassandra,HBase
分布式文件系统
5.4 图关系数据库
它不是放图形的,放的是关系比如:朋友圈社交网络、广告推荐系统
社交网络,推荐系统等。专注于构建关系图谱
Neo4J,InfoGrid
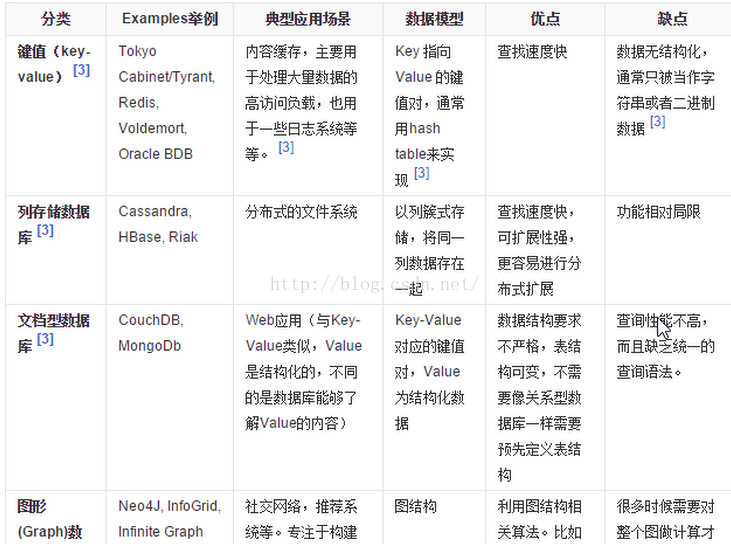
5.5 四者对比
第六部分:在分布式数据库中CAP原理CAP+BASE
6.1 传统的ACID分别是什么
A(Atomicity)原子性
C(Consistency)一致性
I(Isolation)独立性
D(Durability)持久性

6.2 CAP
C:Consistency(强一致性)
A:Availability(可用性)
P:Partition tolerance(分区容错性)
6.3 CAP只能三选二
CAP理论的核心是:一个分布式系统不可能同时很好的满足一致性,可用性和分区容错性这三个需求,最多只能同时较好的满足两个。因此,根据CAP原理将NoSQL数据库分成了满足CA原则、满足CP原则和满足AP原则三大类:
CA - 单点集群,满足一致性,可用性的系统,通常在可扩展性上不太强大。
CP - 满足一致性,分区容错性的系统,通常性能不是特别高。
AP - 满足可用性,分区容忍性的系统,通常可能对一致性要求低一些。
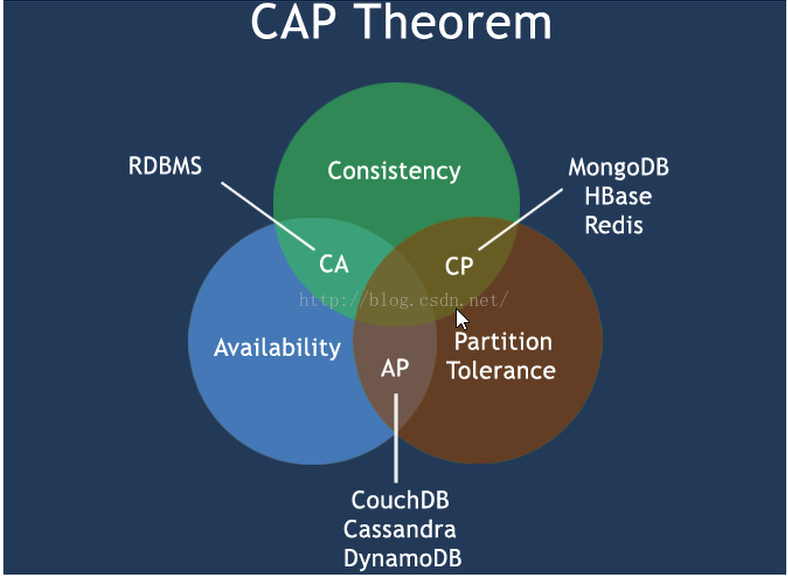
CAP理论就是说在分布式存储系统中,最多只能实现上面的亮点。而由于当前的网络硬件肯定会出现延迟对包等问题,所以分区容忍性是我们必须要实现的。所以我们只能在一致性和可用性之间进行权衡,没有NoSQL系统能同时保证这三点。
CA的代表是传统Oracle数据库,AP的代表是大多数网站架构的选择,CP的代表是Redis、Mongodb
注意:分布式架构的时候必须做出取舍。
那么,为什么说现在大多数网站的架构师AP呢?我们举天猫双十一为例,在这一天顾客的点击如潮水般涌来,这时作为顾客来说,某商品这一秒的点赞数等信息并不是顾客所关心的,换句话说,这时的点赞数可以弱一致性,不必做到实时准确。如果天猫网站这天崩溃了,这肯定是我们所不能忍受的,因此两害相权取其轻,我们会选择高可用性,虽然不能马上做到强一致性,但是双十一过后,我们依然有时间来做到最终的强一致性。
6.4 BASE
BASE就是为了解决数据库强一致性引起的问题而引起的可用性降低而提出的解决方案。
BASE其实是下面三个术语的缩写:
基本可用(Basically Available)
软状态(Soft state)
最终一致(Eventually consistent)
它的思想是通过让系统放松对某一时刻数据一致性的要求来换取系统整体伸缩性和性能上改观。为什么这么说呢,缘由就在于大型系统往往由于地域分布和极高性能的要求,不可能采用分布式事务来完成这些指标,要想获得这些指标,我们必须采用另外一种方式来完成,这里BASE就是解决这个问题的办法。
6.5 分布式系统和集群


声明本文资料均来源于:
《尚硅谷Redis视频》周阳老师思维导图