线程
线程是什么?
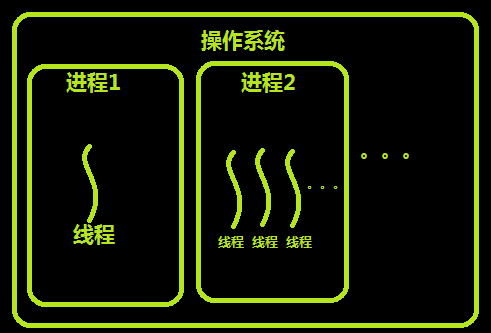
进程是资源分配的最小单位,线程是CPU调度的最小单位.每个进程中至少有一个线程。
为什么有了进程还需要线程?
60年代,在OS中能拥有资源和独立运行的基本单位是进程,然而随着计算机技术的发展,进程出现了很多弊端,一是由于进程是资源拥有者,创建、撤消与切换存在较大的时空开销,因此需要引入轻型进程;二是由于对称多处理机(SMP)出现,可以满足多个运行单位,而多个进程并行开销过大。(官方说法)
进程的缺点:
- 进程在执行任务中如果堵塞,则整个进程就会被挂起
- 进程在同一时间只能执行一个任务(开子进程也只是为了解决一个任务)
- 进程之间的数据是隔离的。想要取到不同进程之间的数据很难
- 多个进程并行开销过大(时间长)
通过代码来解释线程的功能以及特性
1、线程的创建
from threading import Thread def func(n): print("线程的创建", n) t = Thread(target=func, args=('pontoon',)) t.start()
# 多线程并发 import os import time from threading import Thread from multiprocessing import Process def func(): time.sleep(2) print('hello', os.getpid()) if __name__ == '__main__': # for i in range(10): # p1 = Process(target=func) # p1.start() # print('主进程pid', os.getpid()) # print('-' * 30) for i in range(10): t1 = Thread(target=func) t1.start() print('主线程pid', os.getpid()) # 结果我就不贴出来了 # 两者并没有什么实质上的区别,当然也看的出一点点差异就是主线程执行(全部一起出结果)要比主进程快(5个5个来)
2、线程与进程的对比
1、pid的对比


1 import os 2 from threading import Thread 3 from multiprocessing import Process 4 5 6 def func(): 7 print('hello', os.getpid()) 8 9 10 if __name__ == '__main__': 11 p1 = Process(target=func) 12 p2 = Process(target=func) 13 p1.start() 14 p2.start() 15 print('主进程pid', os.getpid()) 16 print('-' * 30) 17 18 t1 = Thread(target=func) 19 t2 = Thread(target=func) 20 t1.start() 21 t2.start() 22 print('主线程pid', os.getpid()) 23 24 # 注意执行顺序 程序从上往下执行,最后执行子进程 25 >>>主进程pid 155928 26 ------------------------------ 27 hello 155928 # 子线程 28 hello 155928 # 子线程 29 主线程pid 155928 30 hello 134120 # 子进程 31 hello 74396 # 子进程
- 从上述代码的执行结果来看所有线程的pid都指向一个155928即主进程的pid,可以的出结论:一个进程可以包含至少一个线程。
-
从代码的执行顺序来看。主进程会随着子进程代码的执行完毕才结束,但是主线程与子线程则是从上向下按顺序执行。

2、开启效率的对比:
1 # 开启效率的对比: 2 import os 3 import time 4 from threading import Thread 5 from multiprocessing import Process 6 7 8 def func(): 9 time.sleep(2) 10 print('hello', os.getpid()) 11 12 13 if __name__ == '__main__': 14 # start_time = time.time() 15 # for i in range(30): 16 # p1 = Process(target=func) 17 # p1.start() 18 # print('主进程pid', os.getpid()) 19 # end_time = time.time() 20 # print('并发进程所用时间:',end_time - start_time) 21 22 start_time = time.time() 23 for i in range(30): 24 t1 = Thread(target=func) 25 t1.start() 26 print('主线程pid', os.getpid()) 27 end_time = time.time() 28 print('并发线程所用时间:', end_time - start_time) 29 30 >>>并发线程所用时间: 0.006010770797729492 31 并发进程所用时间: 1.3949854373931885 32 # 差距相当大
3、内存数据的共享
1 # 3、线程之间数据的共享问题 2 3 import os 4 from threading import Thread 5 6 7 def func(): 8 global g 9 g = 44 10 print(g, os.getpid()) 11 12 13 g = 100 14 t_list = [] 15 for i in range(3): 16 t = Thread(target=func) 17 t.start() 18 t_list.append(t) 19 20 for i in t_list: t.join() 21 print(g) 22 23 >>>44 112740 24 44 112740 25 44 112740 26 44
4、多线程中的input
1 import os 2 from threading import Thread 3 4 5 def func(n): 6 inp = input('%s:' % n) 7 print(inp) 8 9 10 for i in range(3): 11 t = Thread(target=func, args=('name%s' % i, )) 12 t.start() 13 14 >>>name0:name1:name2:fgh 15 fgh 16 # 有点懵逼
总结
进程是最小的内存分配单位
线程是操作系统调度的最小单位
进程中至少含有一个线程
进程中可以开启多个线程
开启线程的时间要远小于进程
多个线程内部都有自己的数据栈,数据栈中的数据不共享
全局变量在多线程之间是共享的
多线程是可以使用Input的(IO请求并不会堵塞)
守护线程 / 守护进程
必问的一个面试题 GIL(全局解释器锁)
在cpython解释器中为了防止线程竞争,导致数据不安全会在进程中加上GIL锁,用来保证在同一个进程在同一时刻,只有一个线程被CPU调度。
线程锁
一段代码引出线程锁的概念
from threading import Thread, Lock import time def func(): global n temp = n time.sleep(1) n = temp - 1 n = 10 # 线程的数据是共享的 t_list = [] for i in range(10): t = Thread(target=func) t.start() t_list.append(t) for i in t_list: i.join() print(n) >>>9 # 得到的为什么会是一个9
画图进行解释:
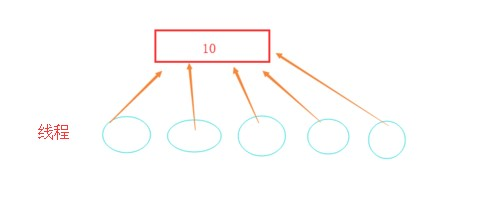
这个时候你还会问,不是有GIL吗?线程被锁住了不应该一个一个的去取数据吗?
用到了GIL之后数据仍然不安全。
操作系统采用时间片轮转算法来执行线程(假设是0.01s),一次线程的执行需1s才能执行完成。可想而知,如果只是单纯的加上GIL数据仍然是不安全的。

线程锁能确保一个线程执行完一次任务,所以在加上锁就能解决这个问题!
1 def func(lock): 2 lock.acquire() 3 global n 4 temp = n 5 time.sleep(1) 6 n = temp - 1 7 lock.release() 8 9 10 n = 10 11 lock = Lock() 12 t_list = [] 13 for i in range(10): 14 t = Thread(target=func, args=(lock, )) 15 t.start() 16 t_list.append(t) 17 18 for i in t_list: 19 i.join() 20 21 >>>0
这里还会出现一个问题就是科学家吃面的问题——死锁(互斥锁)
1 import time 2 from threading import Thread, Lock 3 4 noodle_lock = Lock() 5 fork_lock = Lock() 6 7 8 def eat1(name): 9 noodle_lock.acquire() 10 print('%s 抢到了面条'%name) 11 fork_lock.acquire() 12 print('%s 抢到了叉子'%name) 13 print('%s 吃面'%name) 14 fork_lock.release() 15 noodle_lock.release() 16 17 18 def eat2(name): 19 fork_lock.acquire() 20 print('%s 抢到了叉子' % name) 21 time.sleep(1) 22 noodle_lock.acquire() 23 print('%s 抢到了面条' % name) 24 print('%s 吃面' % name) 25 noodle_lock.release() 26 fork_lock.release() 27 28 29 for name in ['aaa', 'bbb', 'ccc']: 30 t1 = Thread(target=eat1, args=(name,)) 31 t2 = Thread(target=eat2, args=(name,)) 32 t1.start() 33 t2.start() 34 35 >>>aaa 抢到了面条 36 aaa 抢到了叉子 37 aaa 吃面 38 aaa 抢到了叉子 39 bbb 抢到了面条
什么叫互斥锁
是指两个或两个以上的进程或线程在执行过程中,因争夺资源而造成的一种互相等待的现象,若无外力作用,它们都将无法推进下去。此时称系统处于死锁状态或系统产生了死锁,这些永远在互相等待的进程称为死锁进程。上述的代码就是死锁现象。
大白话来讲就是多个线程、进程遇见多个锁,就会产生死锁现象。
解决死锁,递归锁
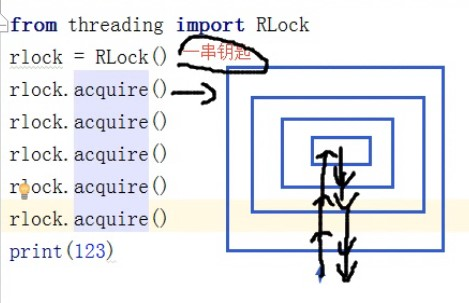
什么叫做递归锁?
下图基本上就解释了递归锁的概念
在Python中为了支持在同一线程中多次请求同一资源,python提供了可重入锁RLock。
这个RLock内部维护着一个Lock和一个counter变量,counter记录了acquire的次数,从而使得资源可以被多次require。直到一个线程所有的acquire都被release,其他的线程才能获得资源。上面的例子如果使用RLock代替Lock。
用递归锁解决死锁代码
1 import time 2 from threading import Thread, Rock 3 4 5 fork_lock = noodle_lock = RLock() # 注意这种写法 6 def eat1(name): 7 noodle_lock.acquire() 8 print('%s 抢到了面条'%name) 9 fork_lock.acquire() 10 print('%s 抢到了叉子'%name) 11 print('%s 吃面'%name) 12 fork_lock.release() 13 noodle_lock.release() 14 15 16 def eat2(name): 17 fork_lock.acquire() 18 print('%s 抢到了叉子' % name) 19 time.sleep(1) 20 noodle_lock.acquire() 21 print('%s 抢到了面条' % name) 22 print('%s 吃面' % name) 23 noodle_lock.release() 24 fork_lock.release() 25 26 27 for name in ['aaa', 'bbb', 'ccc']: 28 t1 = Thread(target=eat1, args=(name,)) 29 t2 = Thread(target=eat2, args=(name,)) 30 t1.start() 31 t2.start() 32 33 aaa 抢到了面条 34 aaa 抢到了叉子 35 aaa 吃面 36 aaa 抢到了叉子 37 aaa 抢到了面条 38 aaa 吃面 39 bbb 抢到了面条 40 bbb 抢到了叉子 41 bbb 吃面 42 bbb 抢到了叉子 43 bbb 抢到了面条 44 bbb 吃面 45 ccc 抢到了面条 46 ccc 抢到了叉子 47 ccc 吃面 48 ccc 抢到了叉子 49 ccc 抢到了面条 50 ccc 吃面
信号量
1 # 7、信号量 2 3 from threading import Thread,Semaphore 4 import threading 5 import time 6 7 8 def func(): 9 sm.acquire() 10 print('%s get sm' %threading.current_thread().getName()) 11 time.sleep(3) 12 sm.release() 13 14 15 if __name__ == '__main__': 16 sm=Semaphore(5) 17 for i in range(23): 18 t=Thread(target=func) 19 t.start()
同进程:规定锁的个数
事件
同进程
1 import threading 2 import time,random 3 from threading import Thread,Event 4 5 def conn_mysql(): 6 count=1 7 while not event.is_set(): 8 if count > 3: 9 raise TimeoutError('链接超时') 10 print('<%s>第%s次尝试链接' % (threading.current_thread().getName(), count)) 11 event.wait(0.5) 12 count+=1 13 print('<%s>链接成功' %threading.current_thread().getName()) 14 15 16 def check_mysql(): 17 print('�33[45m[%s]正在检查mysql�33[0m' % threading.current_thread().getName()) 18 time.sleep(random.randint(2,4)) 19 event.set() 20 if __name__ == '__main__': 21 event=Event() 22 conn1=Thread(target=conn_mysql) 23 conn2=Thread(target=conn_mysql) 24 check=Thread(target=check_mysql) 25 26 conn1.start() 27 conn2.start() 28 check.start()
条件
1 from threading import Condition, Thread 2 3 4 def func(con, i): 5 con.acquire() 6 con.wait() 7 print('在第{0}个循环里'.format(i)) 8 con.release() 9 10 11 con = Condition() 12 for i in range(10): 13 Thread(target=func, args=(con, i)).start() 14 while True: 15 num = int(input('>>>')) 16 con.acquire() 17 con.notify(num) # 在钥匙 18 con.release()
线程队列
为什么线程能够进行数据共享还要在用队列?
因为数据安全的问题。队列中内置了锁。保证数据安全!
因为数据安全的问题。队列中内置了锁。保证数据安全!
就那几个方法,没啥好说的详见女神博客
线程池 (concurrent.futures)
1 import time 2 from concurrent.futures import ThreadPoolExecutor 3 4 5 def func(n): 6 time.sleep(2) 7 print(n) 8 return n * n 9 10 11 t_pool = ThreadPoolExecutor(max_workers=5) # 在线程池中创建5个线程 12 t_list = [] 13 for i in range(20): 14 t = t_pool.submit(func, i) # 创建子线程 15 t_list.append(t) 16 17 t_pool.shutdown() # close() + join() 方法 18 print('主线程') 19 for i in t_list: 20 print("***", t.result()) # 取return的结果
线程池中增加回调函数
1 # 11、线程池中加回调函数 2 import time 3 from concurrent.futures import ThreadPoolExecutor 4 5 6 def func(n): 7 time.sleep(2) 8 print(n) 9 return n * n 10 11 12 def call_back(m): 13 print("结果是 %s" % m.result()) 14 15 16 t_pool = ThreadPoolExecutor(max_workers=5) # 17 for i in range(20): 18 t_pool.submit(func, i).add_done_callback(call_back) 19 20 >>>0 21 结果是 0 22 4 23 3 24 结果是 9 25 结果是 16 26 ...