参考:https://zhuanlan.zhihu.com/p/208637508
参考:https://developer.arm.com/ip-products/processors/machine-learning/arm-nn?_ga=2.151853756.44767251.1597296174-1508087795.1589351508
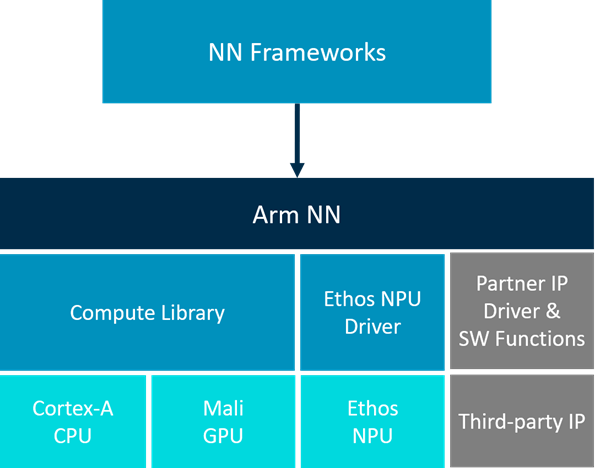
Arm NN
Arm NN 是适用于 CPU、GPU 和 NPU 的推理引擎。 它弥合了现有 NN 框架和底层 IP 之间的差距。 它支持现有神经网络框架(例如 TensorFlow 和 Caffe)的高效转换,使它们无需修改即可在 Arm Cortex-A CPU、Arm Mali GPU 和 Arm Ethos NPU 上高效运行。
Arm NN 是免费的。
关于Arm NN SDK
Arm NN SDK是一套开源Linux软件和工具,可在低功耗设备上实现机器学习工作负载。它在现有的神经网络框架和高效能的Cortex-a CPU、Arm-Mali GPU和Arm-Ethos NPU之间架起了一座桥梁。
Arm NN SDK利用Compute Library尽可能高效地针对可编程内核,如Cortex-A CPU和Mali GPU。Arm NN不支持Cortex-M CPU。
最新版本支持Caffe、TensorFlow、TensorFlow Lite和ONNX。Arm NN从这些框架中获取网络,将其转换为内部Arm NN格式,然后通过Compute Library,将其有效地部署在Cortex-A CPU上,如果存在,则部署在Mali-G71和Mali-G72等Mali GPU上。
2018年9月,Arm将Arm NN捐赠给Linaro Machine Intelligence Initiative,该计划目前完全以开源方式开发。要了解更多信息,请访问mlplatform.org。

 、
、
适用于 Android 的 Arm NN
也可以使用用于 NNAPI 的 Arm NN,这是 Google 用于在 Android 设备上加速神经网络的接口,可在 Android O 中使用。默认情况下,NNAPI 在设备的 CPU 内核上运行神经网络工作负载,但也提供了一个硬件抽象层 (HAL),它可以以其他处理器类型为目标,例如 GPU。适用于 Android NNAPI 的 Arm NN 为 Mali GPU 提供此 HAL。另一个版本增加了对 Arm Ethos-N NPU 的支持。
对 Android NNAPI 的 Arm 支持可将性能提升 4 倍。
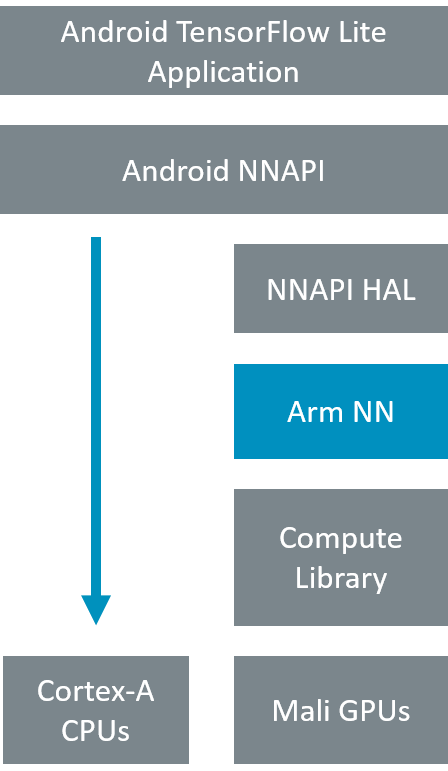
在高层支持神经网络推理的方式看似简单。 首先,表示神经网络及其相关权重的模型由应用程序或 ML 框架(例如 TensorFlow Lite)提供。 然后,Android NN 运行时执行调度以确定图应如何运行——在 CPU 或任何已注册以支持神经网络计算的设备上。 在此之后,选定的设备——通常是 CPU 或 GPU,有时还有另一个加速器——将获得要运行的模型。 最后,设备会将工作负载分解为关键操作,并在模型上运行推理过程,生成应用程序将使用的结果。
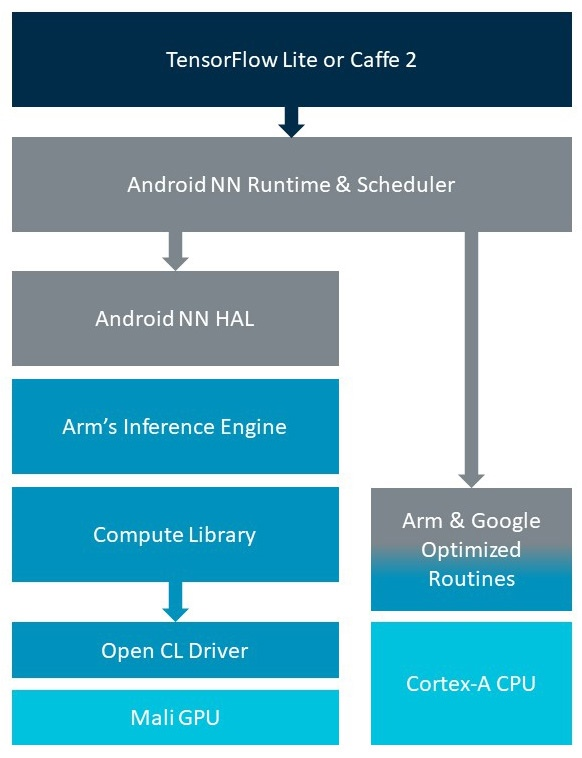
这看起来可能很简单,但我们的软件团队已经投入了大量的工作,以使每个阶段都能很好地运行——特别是当涉及到对Mali GPU和在CPU和GPU上运行的高度优化的operators的HAL和驱动程序支持时。这些都是Arm精心调整的,是Android NN的Google CPU后端的核心,也是通过Android NN HAL的GPU实现提供的Arm Mali GPU例程的核心。
支持卷积神经网络所需的关键operators,随时准备加速现有应用程序,并为部署新的应用程序开辟可能性。幸运的是,我们已经构建这些软件组件很长时间了,所以当这个新API可用时,我们已经准备好了。
自宣布以来,Arm 和 Google 都在进行大量艰苦的工作,以确保在 Arm 平台上轻松实现高性能神经网络推理。最终发布了针对 Cortex-A 的优化 CPU 算子,集成到谷歌的框架中,以及针对 Arm Mali GPU,以及运行它们的推理引擎。更重要的是,这些算子作为开源发布,并作为计算库的一部分提供。
Arm 已经提供了对 32 位浮点的支持,我们的 NNAPI 版本改进了这种支持,将神经网络计算速度提高了三倍。我们还致力于支持 8 位整数运算,当在大多数移动设备中已部署的 Mali GPU 上运行时,它的性能将是 fp32 的四倍。
此外,我们还在继续努力增加对发布的更多 Arm CPU 和 GPU 的支持。例如,Cortex-A55 和 Cortex-A75 开始出现在产品中,我们将释放新的 ARMv8.2 架构的强大功能,将 8 位卷积和矩阵乘法的性能提升 4 倍。
对于任何想要在 Arm 上部署卷积神经网络的人来说,所有这些都是个好消息,因为它们总是量化到 8 位,精度几乎与 32 位相同,但性能明显更高。
除此之外,减少带宽的额外好处以及内存子系统带来的改进,无论您选择哪种 Arm 平台,都能带来更好的性能。
相对于其他 NN 框架的 Arm NN 性能
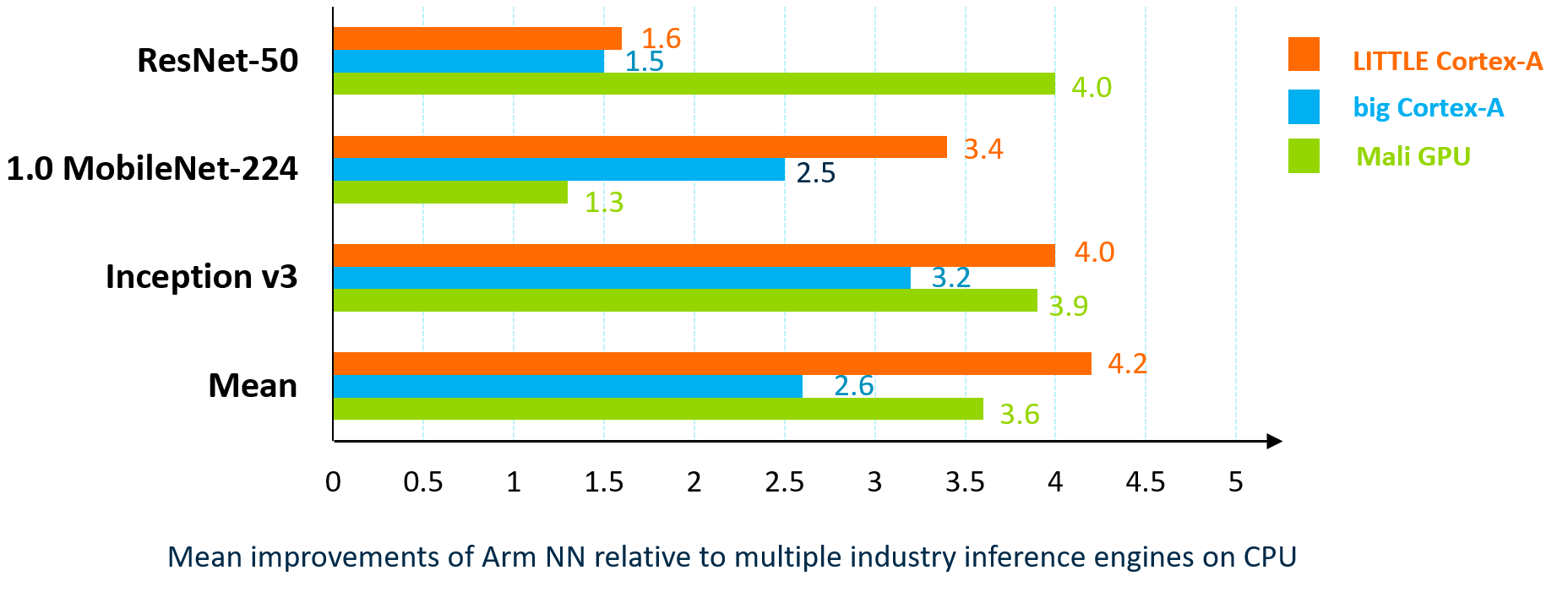
- Arm NN 开源协作可实现最佳的第三方实施
- 部署在多个生产设备中(>250Mu)
支持 Cortex-M CPU
TensorFlow Lite Micro 为 Cortex-M 微控制器提供机器学习支持。 通过CMSIS-NN可进行进一步优化,CMSIS-NN 是一组高效的神经网络内核,旨在最大限度地提高性能并最大限度地减少神经网络在 Cortex-M 处理器内核上的内存占用。
Arm NN 未来路线图
Arm NN 的未来版本将支持其他机器学习框架作为输入,以及其他形式的处理器内核作为目标。 这包括来自 Arm 合作伙伴的处理器内核和加速器,假设有合适的扩展可用。
