本文爬取了掘金上关于前端前n页的标题。将文章的标题进行分析,可以看出人们对前端关注的点或者近来的热点。
- 导入库
import requests import re from bs4 import BeautifulSoup import json import urllib import jieba from wordcloud import WordCloud import matplotlib.pyplot as plt import numpy as np import xlwt import jieba.analyse from PIL import Image,ImageSequence
- 爬取json
#动态网页json爬取 response=urllib.request.urlopen(ajaxUrl) ajaxres=response.read().decode('utf-8') json_str = json.dumps(ajaxres) #编码 strdata = json.loads(json_str) # 解码 data=eval(strdata)
- 循环输出title内容,并写入文件
for i in range(0,25): ajaxUrl = ajaxUrlBegin + str(i) + ajaxUrlLast; for i in range(0,19): result=[] result=data['d'][i]['title'] print(result+' ') f = open('finally.txt', 'a', encoding='utf-8') f.write(result) f.close()
- 生成词云
#词频统计 f = open('finally.txt', 'r', encoding='utf-8') str = f.read() stringList = list(jieba.cut(str)) symbol = {"/", "(", ")", " ", ";", "!", "、", ":","+","?"," ",")","(","?",",","之","你","了","吗","】","【"} stringSet = set(stringList) - symbol title_dict = {} for i in stringSet: title_dict[i] = stringList.count(i) print(title_dict) #导入excel di = title_dict wbk = xlwt.Workbook(encoding='utf-8') sheet = wbk.add_sheet("wordCount") # Excel单元格名字 k = 0 for i in di.items(): sheet.write(k, 0, label=i[0]) sheet.write(k, 1, label=i[1]) k = k + 1 wbk.save('前端数据.xls') # 保存为 wordCount.xls文件 font = r'C:WindowsFontssimhei.ttf' content = ' '.join(title_dict.keys()) # 根据图片生成词云 image = np.array(Image.open('cool.jpg')) wordcloud = WordCloud(background_color='white', font_path=font, mask=image, width=1000, height=860, margin=2).generate(content) # 显示生成的词云图片 plt.imshow(wordcloud) plt.axis("off") plt.show() wordcloud.to_file('c-cool.jpg')
- 一个项目n个坑,一个坑踩一万年
- 获取动态网页的具体内容
爬取动态网页时标题并不能在html里直接找到,需要通过开发者工具里的Network去寻找。寻找到的是ajax发出的json数据。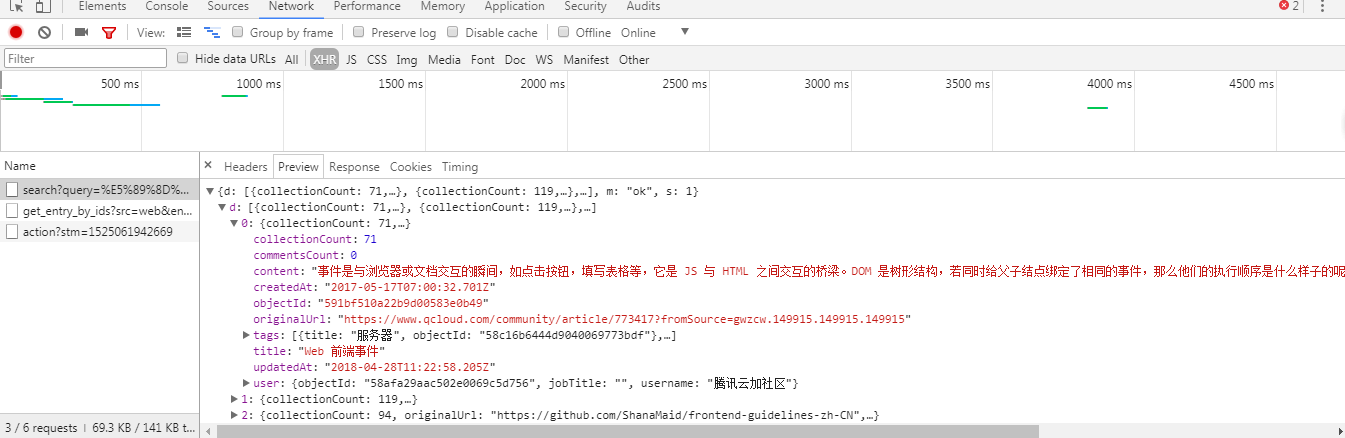
- 获取json里面的具体某个数据
我们获取到json数据之后(通过url获取)发现它。。

(wtf,啥玩意啊这是???)
这时我们可以用一个Google插件JSONview,用了之后发现他说人话了终于!

- 接下来就是wordCloud的安装
这个我就不说了(说了之后只是网上那批没用的答案+1.)。想知道怎么解决的出门右转隔壁的隔壁的隔壁老黄的博客。(芬达牛比)
- 总体代码
import requests import re from bs4 import BeautifulSoup import json import urllib import jieba from wordcloud import WordCloud import matplotlib.pyplot as plt import numpy as np import xlwt import jieba.analyse from PIL import Image,ImageSequence url='https://juejin.im/search?query=前端' res = requests.get(url) res.encoding = "utf-8" soup = BeautifulSoup(res.text,"html.parser") #遍历n次 ajaxUrlBegin='https://search-merger-ms.juejin.im/v1/search?query=%E5%89%8D%E7%AB%AF&page=' ajaxUrlLast='&raw_result=false&src=web' for i in range(0,25): ajaxUrl=ajaxUrlBegin+str(i)+ajaxUrlLast; #动态网页json爬取 response=urllib.request.urlopen(ajaxUrl) ajaxres=response.read().decode('utf-8') json_str = json.dumps(ajaxres) #编码 strdata = json.loads(json_str) # 解码 data=eval(strdata) #str转换为dict for i in range(0,25): ajaxUrl = ajaxUrlBegin + str(i) + ajaxUrlLast; for i in range(0,19): result=[] result=data['d'][i]['title'] print(result+' ') f = open('finally.txt', 'a', encoding='utf-8') f.write(result) f.close() #词频统计 f = open('finally.txt', 'r', encoding='utf-8') str = f.read() stringList = list(jieba.cut(str)) symbol = {"/", "(", ")", " ", ";", "!", "、", ":","+","?"," ",")","(","?",",","之","你","了","吗","】","【"} stringSet = set(stringList) - symbol title_dict = {} for i in stringSet: title_dict[i] = stringList.count(i) print(title_dict) #导入excel di = title_dict wbk = xlwt.Workbook(encoding='utf-8') sheet = wbk.add_sheet("wordCount") # Excel单元格名字 k = 0 for i in di.items(): sheet.write(k, 0, label=i[0]) sheet.write(k, 1, label=i[1]) k = k + 1 wbk.save('前端数据.xls') # 保存为 wordCount.xls文件 font = r'C:WindowsFontssimhei.ttf' content = ' '.join(title_dict.keys()) # 根据图片生成词云 image = np.array(Image.open('cool.jpg')) wordcloud = WordCloud(background_color='white', font_path=font, mask=image, width=1000, height=860, margin=2).generate(content) # 显示生成的词云图片 plt.imshow(wordcloud) plt.axis("off") plt.show() wordcloud.to_file('c-cool.jpg')

 (词云图)
(词云图)