|
目录 |
|
- 事件响应 - IACD框架 - 事件响应方式 - 后悔矩阵 - 响应操作 - 事件响应环 - 准备 - 识别 - 遏制 - 遏制手段 - Openc2 - 根除 - 恢复 - 重建 - 总结
|
事件响应
事件响应的目标是消除事件产生的影响。这依赖于将威胁分析阶段生成的威胁情报转换成防守方可执行的行动方案COA,并将COA拆解成可供执行的命令准确下达到安全能力中。
所有响应的动作可分为遏制、补救、重建3类,自动化响应系统目前主要工作的阶段主要在遏制和补救。而人工则可用从任意阶段介入。自动响应系统在获取到正确的情报之后,需要判断在哪个节点上执行哪一类的操作。这同时依赖威胁情报和安全基线的输入。以IACD的框架为例:
IACD框架
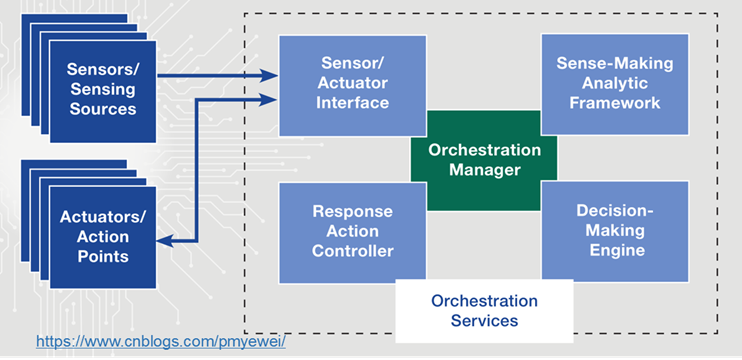
IACD Baseline Architecture
在IACD架构中,最左侧的Sensors负责采集数据,发送给编排服务;Actuator负责执行编排服务下发的响应指令。编排服务通过标准接口与采集器和执行器对接。在实际的应用中,采集器和执行器可以是同一类设备,比如网络防火墙既可以充当网络流量和网络入入侵事件的Sensor 也可以作为阻断攻击流量的Actuator。
Sense-Making Analytic Framework (SMAF)负责对采集到的数据进行富化。Decision-Making Engine (DME) 需要决定采用什么行动方案COA。Response Action Controller (RAC)负责将COA拆解为可执行的命令,并由Actuator的接口去执行。
整个IACD的模块设计还是参照的OODA模型。从“采集数据——富化信息——决定行动方案——执行”全过程的管理。
数据采集和信息富化的过程我已经把它放在前章的威胁分析里面了。生成行动方案、执行过程中需要解决的问题包括:
1、由威胁情报推导出事件响应需要采取哪些措施;
2、由资产的安全基线推导出,哪些措施是可执行的;
3、通过什么方式将措施下发到安全能力中;
可见在安全自动化体系中,事件响应紧密依赖威胁情报提供的数据和安全基线中的基础能力。没有威胁分析提供情报数据支撑或没有资产安全基线提供安全防护和响应能力,单独建设一个事件响应平台是没有意义的。
事件响应方式
后悔矩阵
说回事件响应,事实上我们对于事件响应这一概念并不陌生,以前对安全事件的处理很常见的一招就是拔网线——直接将受影响的资产/业务断网,简单粗暴、立竿见影,但是同样对业务的正常运行影响也最大。在安全自动化体系中自然无法直接拔网线,但为了达到目的同样有类似的手段。
但一旦说到自动化响应则意味着不信任和不确定性,当使用者对可能发生的后果无法预知的时候,自动化也就无法实施。于是开始人工介入,由人工对动作进行审批,或完全由人工手动规划所有的动作。这无疑延长了处理周期,回归到对于人力的依赖。所以在追求自动化响应效率的同时如何解决自动化带来的不确定性。IACD框架中建议的方法为通过后悔矩阵来识别出可以自动化的操作以及需要人工介入的操作。

后悔矩阵以收益为纵坐标,代表自动化带来的时间和效率上的优势。后悔程度为横坐标,代表因为自动化引入的结果不确定性。矩阵分为4个象限:高收益低后悔、高收益高后悔、低收益低后悔、低收益高后悔。
 高收益、低悔的是已经经过大量验证的行之有效且对业务影响较小的手段。例如阻止情报中的恶意软件运行,这类恶意软件通常不在业务运行必备的列表内,阻断后某些场景下能够迅速恢复业务可用性。高收益低后悔操作最能体现自动化响应带来的好处,能在整网中实现非常好的处置效果,为后续进一步的处理节约出宝贵的时间。
高收益、低悔的是已经经过大量验证的行之有效且对业务影响较小的手段。例如阻止情报中的恶意软件运行,这类恶意软件通常不在业务运行必备的列表内,阻断后某些场景下能够迅速恢复业务可用性。高收益低后悔操作最能体现自动化响应带来的好处,能在整网中实现非常好的处置效果,为后续进一步的处理节约出宝贵的时间。
低收益、低悔的通常对应一些在事件响应流程中经常会要使用,但价值不高的重复劳动。例如封禁某一个外部的恶意URL、邮件发件人等,这类操作对于已知的事件有一定的阻断作用,但常常没有完全封堵掉所有入侵的路径。这类操作对于安全人员来说是有必要但收益较低的类型。
高收益、高悔对应那类能够显著消除事件影响,但同样可能对业务带来较大影响的操作。例如阻断资产的所有网络流量(断网)、恢复操作系统、还原数据等。这些在正常运维过程中都需要小心翼翼的操作,在事件响应过程中同样需要对其影响进行评估。
 低收益、高悔类的操作则直接不建议处理了。通常是因为采集到的数据不足以支撑COA,还需要更进一步的调查。
低收益、高悔类的操作则直接不建议处理了。通常是因为采集到的数据不足以支撑COA,还需要更进一步的调查。
需要指出的是,响应操作的属性不是固定的,而是根据业务场景变化,例如:断网操作在保密部门中,可能是高收益低悔的操作。而在公共服务部门可能是低收益高后悔的操作。在决策时,需要企业或者组织根据自身习惯和安全合规要求决定那些操作自动执行哪些人工介入。
响应操作
根据事件响应的阶段,可以将响应操作分为:遏制、补救、重建这3大类。
· 遏制:缓解正在发生的入侵行为,防止事件进一步恶化。这通常是所有事件发生后第一时间采取的措施,这类操作通常最适合通过自动化响应的方式实现,能够后续操作争取到更多的时间。
· 根除:清除事件对资产/业务的影响。包括清除入侵者的后门,恢复被篡改的系统设置、账号权限,修补系统漏洞等,根除的措施中一部分可以通过自动的方式实现,一部分需要安全专业人员进行修复。根除操作的结束意味着业务已经基本恢复正常。
· 重建:针对某一类型的攻击建立长效的免疫机制,防止相同的事件再次发生。这包括积累知识库、重新建立基础安全基线、分享威胁情报等。这通常需要人员经验的积累和专业分析判断,
处理阶段越往后操作对业务的影响越大,处理起来也应该越谨慎。当前的大部分实践中,对于事件的响应处理大部分都止步于根除阶段,且过度依赖人工进行排除和复检,难免有遗漏或事后追溯较为困难。建设安全自动化响应流程的好处是,通过标准化的响应动作,提升响应速度,减轻人员的压力。事件处理的记录也将同步到知识库中。

接下来还是通过完整的事件响应环流程来探讨事件响应环节的设计。
事件响应环
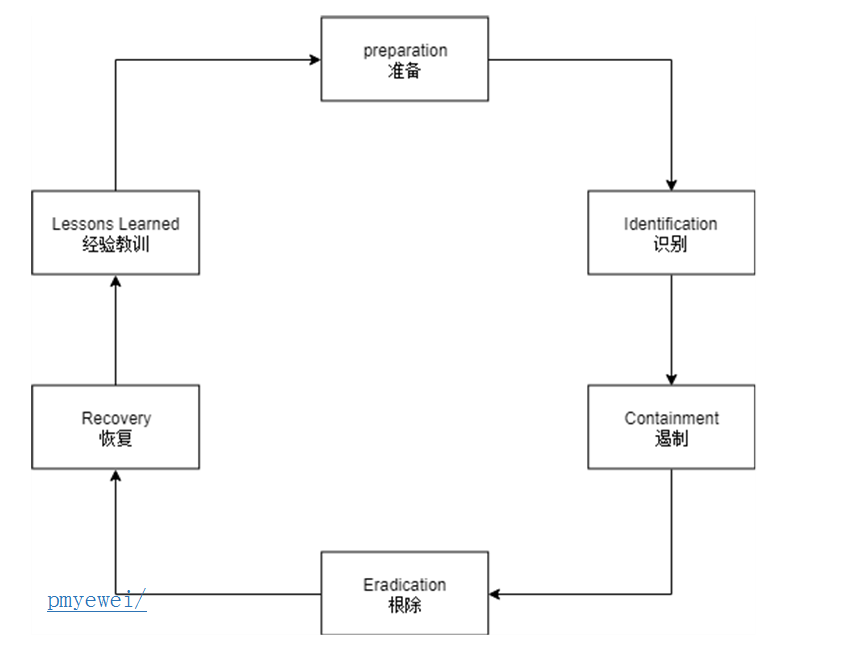
完整的事件响应环包含了:准备、识别、遏制、根除、恢复、经验教训 这个六大步骤。
这六大步骤涵盖了事件响应流程中的主要工作内容,是通用的处理步骤,也是事件响应模块的设计指导。这六大步骤中的“准备”“识别”两个过程对应我设计的“安全基线”和“威胁分析”模块的主要工作,所以这里不再展开讨论,仅说明事件响应如何与这两个模块交互。
准备
我个人更愿意称之为“布防”阶段,这一阶段对于防御者来说,即为资产建立安全基线的过程。主要工作就是划清资产责任人、建立资产安全基线、部署安全检测系统、建立应急响应流程。为了保证事件响应能够运转起来,资产的基线应该至少包含:
·网络、主机层面的安全检测能力,包括数据泄露检测、终端检测、网络流和原始报文检测等,保证有足够的信息用于产生威胁情报。
·具备对已识别威胁和风险的阻断能力,包括:网络、主机、人员接入多个层面的威胁指标的阻断能力。为自动化响应提供足够的弹药。
当然实际中不应该只满足于这些底线,基线越完善可观测到的数据就越多,可封堵的手段也就越多。在安全基线和威胁分析章节已经详细讨论过。
识别
识别是识别出攻击行为的阶段。在 威胁分析 的那篇博客中已经分析过,不能认为简答地认为收到一条告警信息就已经识别到了攻击,要启动事件响应最朴素的标准为资产、业务受到了直接的影响,需要事件响应介入。在这之前就是识别攻击模式、攻击途径、攻击工具、受影响范围等。具体内容可以参考之前的文章。识别阶段最重要的输出物就是威胁情报。无论是自动响应还是人工处理,分析阶段产生的威胁情报将直接影响后续的事件响应动作。
为了方便对事件响应进行说明,我们虚拟一个red01事件,并假设威胁分析已经获取到足够的信息,并输出了包含以下信息的威胁情报:
已得出Red01事件中入侵事件的情报如下:
攻击模式:使用恶意URL引诱人员点击、利用word软件漏洞、通过自制的恶意软件进行远程控制、从而获取企业内部数据
受到影响的资产包括:xxx终端、xxx域服务器
恶意email:zhongjiang@173.com
恶意URL对象:xxx.duijiang118.com
漏洞对象:CVE-2016-1234
恶意软件名称:wmiprvse.exe,md5:D4C435FE6CB69D1872ADC089517AC9DC
进程:C:\Windows\System32\wmiprvse.exe
修改注册表:HKEY_LOCAL_MACHINE\Microsoft\xxx
远控IP:210.xx.188.xx
网络行为:源地址 x.x.x.x,目的地址:210.xx.188.xx,src_port:123,dst_port:234,protocol:pptp,开始时间:02:00
下面环节我们针对这一个示例展开响应。
遏制
遏制手段
遏制是限制的攻击者进一步造成伤害,采取临时措施防止入侵恶化的过程,所以遏制通常是对入侵者进行的操作。所使用的手段都是最为直接的隔离、阻断。为了达到效果,遏制措施应以多种路径和阻断方式迅速进行,以避免在你切断入侵者的访问过程中,被入侵者察觉并给他们一个作出反应的时间。所以应该尽可能快地在杀伤链的多个阶段同时进行,包括投递、命令和控制以及对目标行动。
根据攻击模式和技战术的不同,可以执行的遏制手段包括:
·投递阶段
阻断外部IP、端口流量
将恶意邮箱添加到黑名单
阻断外部恶意URL的访问
网络隔离受感染终端
·命令控制阶段
未知进程、应用控制
恶意软件隔离(hash)
中断用户会话
临时禁用账号,降低访问权限
临时禁止主机访问重要资产
·目标行动
数据访问权限管控
数据流出黑名单
之前有提过,遏制阶段的操作是最适合进行自动响应的,因为隔离可疑文件、阻断外部IP这些操作广泛地应用于各种安全设备,统一上收到事件响应中心,不存在较大的阻力。只是在设计上需要注意将各种动作关联到事件中,并对执行结果进行跟踪。
我们可以拆解一下事件响应的决策引擎在拿到red01威胁情报后的工作流程。
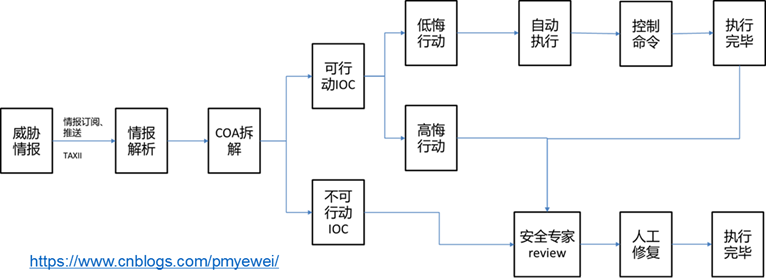
事件响应模块拿到威胁情报。第一步既是解析威胁情报的类型,情报采用什么格式编写的,从而解析出情报的内容。
Red01情报以STIX格式编写,"spec_version": "2.0"
之后开始将情报中包括的所有指标拆解出来。拆解的主要对象为威胁情报中的各种观测物对象、IOC,以及情报中推荐的COA。最终输出应对威胁的完整COA。
Red01情报中的可观测物包含:恶意email、恶意URL对象、漏洞CVE编号、恶意软件、进程、注册表键值、远控IP、网络行为。
然后就是根据安全基线的数据,判断出可执行的COA动作和不可执行的COA动作,不可执行的动作有很多原因,例如:资产没有配置对应的安全防护能力、动作在业务场景中被禁等。(是的,这里再次出现安全基线)
Red01事件涉及到的资产:xxx终端、xxx域服务器
xxx终端配置了安全防护服务:终端恶意代码防护、邮件内容过滤
xxx域服务器配置了安全检测服务:恶意代码检测,安全防护服务:应用控制、网络访问控制
对于xxx终端,可执行的动作包括:隔离恶意文件、阻断外部恶意邮件发件人
xxx域服务器,可执行的动作包括:阻断远控IP、恶意代码md5检测、应用控制
可执行的动作再被分为:低悔行动和高悔行动。低悔行动对应后悔矩阵中的高收益低后悔动作和低收益低后悔动作,这些动作可以交由事件响应模块自动执行。高悔行动应该在第一时间通知安全专家,由安全专家人工决策是否执行。
不可执行的动作,主要由无法自动化的操作组成,例如:虽然有威胁情报发现主机存在远控IP,但是主机却没有配置任何网络访问控制的防护服务,或者当前服务提供商没有给事件响应模块提供配置接口,这类操作需要交由安全专家人工去修复。
Red01中的系统漏洞,自动修复风险较大,需要通过漏洞管理进行人工修复。
对于注册表键值,需要交由人工进行修复,并在评估后加入安全基线检测项中。
安全专家最终需要对所有安全事件的执行结果进行review,自动执行的操作可以回退,需要人工介入的操作签发工单到对应的负责人。最终所有事件的处理结果积累到知识库中,进一步进行积累。
事件响应模块在执行自动化控制时,需要将遏制的命令下发到各种安全能力中。这里涉及到一个关键的控制语言:openc2。
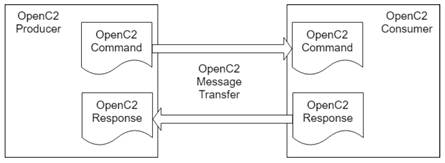
Openc2
Openc2是目前由OASIS组织在维护的开放式命令与控制语言规范,用于在安全事件响应过程中能够使用标准的语言向安全设备下发控制命令。对应的IACD框架中sensor/actuator interface。
为了实现对安全能力的控制,openc2的规范中定义了一系列的动作,例如:query、scan、deny、allow、start、stop等等,给这些动作加上一个对象之后,即可告诉安全设备需要执行的动作。例如:
对于防火墙设备

每种命令和对象的组合在不同的设备中可能表现出不同的形式,所以需要定义出不不同的profile,保证在某一个特定的profile内,命令和对象的语义是唯一的。
关于openc2还有很多内容,但是不再展开。从openc2语言的设计和用途来看,用于事件响应的遏制命令下发再合适不过。(Openc2的动作很多,不仅可以用于响应指令的下发,还适用于工件调查、事件恢复等领域,且可方便地扩展,用于系统与系统之间的高速命令传递。)
示例威胁情报中的大部分数据被事件响应模块识别之后都能自动生成对应的遏制命令,并下发到对应的安全能力中。

根除
根除移除所有地方能力并使资产回归基线的过程。与遏制不同,根除通常是对自身资产和业务进行的操作。遏制操作能解得了一时的燃眉之急,但是如果不拔掉入侵者在网络和主机中残留的据点、修复入侵途径,入侵者换个IP、工具就能卷土重来。
根据攻击阶段的不同,可以采取的根除措施包括:
·漏洞利用
更新系统补丁、更新软件版本
修复系统中受到影响的用户和权限
修改管理员密码
·安装植入
清除残留恶意代码、rootkit、shell
恢复注册表项和系统配置
防病毒特征库
重装系统、恢复系统
·目标行动
更换系统密钥、证书
使用备份恢复数据
作废已泄露数据
报警
根除操作会深入到对业务运行环境的改变,影响业务的运行,所以对这些行动应该经过深思熟虑,以及可能产生的后果的预演,这可能需要相当多的时间和资源进行评估和准备。除了对业务和资产的直接操作以外,根除还包含对社会工程学入侵手段的修复。这包括对于人员安全意识的培训、安全事件分享、可疑活动上报流程等,这些内容没有在安全自动化体系中讨论,但是不代表它们不重要。
而当对事件波及到的范围无法准确评估时,只能采取焦土策略。例如当无法准确地检测到用户的rootkit时,可能需要重装整个操作系统。当对用户获取的数据范围无法准确评估时,需要将所有数据作废,并重新生成。这通常是无奈之举,但却是有必要采取的措施。
恢复
修复完成的系统具备了重新上线的条件。业务或资产的风险已经回归到可接受的范围内,事件的造成的影响基本已经消除。接下来就是选择合适的时机让一切回归正轨,让被中断的业务对外接受新一轮的检阅。恢复阶段的输出物为恢复运行的业务系统。
这里面甚至包括移除早期执行的一些遏制措施。例如:重新放开之前隔离的网段、恢复某一个打完补丁的程序运行、用户权限的恢复。当然也不是所有的遏制措施都需要回退,例如:被删除掉的恶意文件或进程。
从发现异常指标到业务恢复上线,这中间所花费的时间既是网络安全领域的RTO(Recovery Time Objective)恢复时间目标。安全自动化的目标即是最大化地缩短所需的时间,减少因安全事件带来的业务损失。提升整体的自动化程度和设计一套落地的事件响应流程能够很好地帮助缩短这个时间差。安全事件的响应目前是一项紧密将多个团队的人员和系统紧密结合起来的工作流,或许将来IT、业务、安全团队的通力合作,外加完善的安全自动化体系,安全事件的RTO也许能降到最低。
而最让人无奈的是,不是所有的安全事件都能走到恢复这一步,某些情况下入侵者对系统的打击可能是毁灭性的。被入侵后导致损失无法挽回的事例不是没有发生过。它可能导致组织多年的积累数据毁于一旦,企业商誉受到毁灭性打击,即使修复完业务系统也无济于事。恢复通常是由业务部门推动,安全部门进行放行。
重建
重建是对事件进行总结,吸取经验教训的过程。重建是面向未来的,是对自身弱点的刨析,如何从已经发生的事件中发现自生的缺陷,从而提升自身免疫能力。同样重要的是,事件分析处理过程产生的情报也能成为一种疫苗,让其他组织也能具备免疫能力。重建过程中的工作包括:损失评估、威胁情报分享、对攻击者的分析、经验教训学习。重建工作建议通过圆桌会议的方式进行,这其中需要包括了安全运营团队、业务团队、威胁分析团队、事件响应团队的共同参与,允许的情况下,可能还需要技术外援。通过从多个视角来吸取经验教训,实现防护水平的提升。
重建阶段的输出物主要是知识库和新基线。
评估重建内容时,也同样可以结合kill chain的生命周期进行评估。
确认目标
本次是有针对性的入侵行为还是一次随机的事件?
同行业其他组织是否已经发现类似攻击行为?
是否需要将入侵者情报共享出去?共享的范围是?
侦查
资产基线与资产面临的风险是否匹配?
业务系统设计与面临的风险是否匹配?
武器化
入侵者的攻击模式是什么?有没有过类似的攻击事件?
当前的防护能力能否满足业务的需求?
投递
我们如何才能完全避免这一事件?这包括对网络体系结构、系统配置、用户培训甚至基线的更改?
我们是否采集到足够的信息用于威胁分析?
本次事件中哪个能力提供了最有力的证据?
本次事件分析中缺少了哪一个环节的数据?
事件中的干系人发现了异常事件么?
人员有顺畅的通道反馈异常事件么?
漏洞利用
事件是否利用的已知漏洞?
我们是否建立了完善的漏洞管理机制?
安装植入
当前的根除能力能否满足业务的需求?
哪个根除措施发挥了最大的作用?
命令控制
当前的遏制能力能否满足业务的需求?
哪个遏制措施发挥了最大的作用?
目标行动
当前的恢复能力能否业务的需求?
是什么影响了我们的RTO和RPO?
我们应该如何缩短安全事件响应的RTO?
总结经验教训是让安全“内生化”的重要环节,也是避免事件响应团队沦为救火队的环节。现实中大部分团队都略过了这一阶段,可能的原因有:将安全事件总结视作是一种惩罚,当事人害怕工作失误在总结的过程中被放大,从而影响到个人评价;缺乏对应的指导,将事件处理止步于恢复环节;
这依赖建立完善的事件处理流程、人员安全意识培训、设置优化奖励。通过学习已有事件的经验,明确提升业务安全性的方向,并优化现有基线或流程,避免同样的事件再次发生。
总结的经验在录入知识库后,完成内部知识的积累。共享的威胁情报也有利于外部组织识别和响应攻击。
总结
至此,从建立基线、发现危害指标、生成威胁情报、事件响应整个流程走完,安全自动化体系完成了一个完整的循环。这个过程中,我们讨论了一个完整的体系应该包含的内容,各个模块之间如何交付,每个模块应该如何工作,哪些工作适合自动化实现。
当然这一系列的内容还没有结束。因为还有很多问题等着我们去解决。