对于XML解析通常分为两种:
1.DOM解析(Document Object Model,文档对象模型),该方式是W3C 组织推荐的处理 XML 的一种方式。
2.另一种是SAX(Simple API for XML)。
当然IBM公司后面退出了JAXB,基于JavaBean的XML解析方式,不过本文描述的是DOM模型解析原理以及使用Java内置的API(JAXP---Java API for XML Processing)通过DOM模型来解析XML,因为JAXP作为JavaEE规范中的一种技术,所以作为一个Java程序猿来说掌握这套API是必须的。
一:什么是DOM?
Document Object Model(文档对象模型),它是W3C 组织推荐的处理 XML 的一种方式。
DOM模型定义访问和操作XML文档的标准方法。(即定义一种访问XML文档一种规范)
下面来看一份XML文档:
1 <?xml version="1.0" encoding="UTF-8"?> 2 <!--将DTD文件编写在XML文档内部--> 3 <!DOCTYPE bookstore [ 4 <!ELEMENT bookstore (book)+> 5 <!ELEMENT book (title,author,year,price)> 6 <!ELEMENT title (#PCDATA)> 7 <!ELEMENT author (#PCDATA)> 8 <!ELEMENT year (#PCDATA)> 9 <!ELEMENT price (#PCDATA)> 10 <!ATTLIST book category CDATA #REQUIRED> 11 <!ATTLIST title lang CDATA #REQUIRED> 12 ]> 13 14 <bookstore> 15 <book category="操作系统"> 16 <title lang="中文">鸟哥的私房菜</title> 17 <author>鸟哥</author> 18 <year>2005</year> 19 <price>89.5</price> 20 </book> 21 </bookstore>
这是一份有效(格式良好,且有DTD约束)的XML文档。
当我们使用DOM方式去解析该XML文档的时候,XML文档会在内存中形成一个树形结构,而XML 文档中的每个成分都是一个节点。
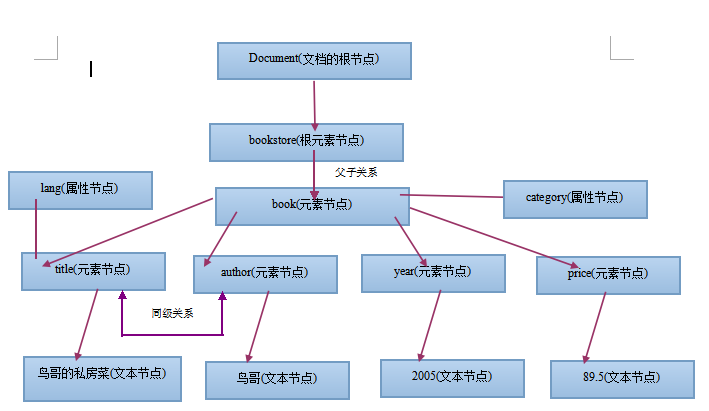
这里特别要注意的是:
W3C组织对DOM是这样定义的:
整个文档是一个文档节点(Document)
XML中的每个标签都是元素节点(Element Node)
XML中的每个文本都是文本节点(Text Node)
XML中的标签属性都是属性节点(Attr Node)
XML中的注释被称为注释节点(Comment Node)
文本总是存储在文本节点中,而不是存储在元素节点中的,在 DOM 处理中一个普遍的错误是,认为元素节点包含文本。
不过,元素节点的文本是存储在文本节点中的。
在这个例子中:<year>2005</year>,元素节点 <year>,拥有一个值为 "2005" 的文本节点。
"2005" 不是 <year> 元素的值!
最后需要注意的是:由于解析器会将XML文档中的所有节点都加载到内存之中,所以可以很方便的完成CRUD操作,但是此方法也过于暴力,当XML文档内容过大时,可能会造成内存溢出的情况,这点大家都应该很清楚。
二:使用JAXP采用DOM编程模型解析XML.
解析XML的本质是通过解析器去完成的,但是我们并不是直接去调用解析器的方法去操作XML文档.而是SUN公司为我们提供了一套API让我们调用,与解析器交互的事情由SUN公司帮助我们完成.
1 package cn.plx.jaxp; 2 3 import java.io.File; 4 5 import javax.xml.parsers.DocumentBuilder; 6 import javax.xml.parsers.DocumentBuilderFactory; 7 import javax.xml.transform.Transformer; 8 import javax.xml.transform.TransformerFactory; 9 import javax.xml.transform.dom.DOMSource; 10 import javax.xml.transform.stream.StreamResult; 11 12 import org.junit.Test; 13 import org.w3c.dom.Attr; 14 import org.w3c.dom.Comment; 15 import org.w3c.dom.Document; 16 import org.w3c.dom.Element; 17 import org.w3c.dom.NamedNodeMap; 18 import org.w3c.dom.Node; 19 import org.w3c.dom.NodeList; 20 21 /** 22 * 使用SUN提供的JAXP解析XML文档 23 * 24 * @author Administrator 25 * 26 */ 27 public class JAXPTest { 28 29 public static void main(String[] args) throws Exception { 30 // 创建XML解析器工厂 31 DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance(); 32 /* 33 * om.sun.org.apache.xerces.internal.jaxp.DocumentBuilderFactoryImpl 34 * xerces是由IBM公司提供的XML解析器 35 */ 36 System.out.println(factory.getClass().getName()); 37 38 // 创建XML解析器 39 DocumentBuilder builder = factory.newDocumentBuilder(); 40 System.out.println(builder.getClass().getName()); 41 42 /** 43 * <pre> 44 * 获取到Document对象,Document对象代表着DOM树的根节点 45 * 使用Document对象可以对XML文档的数据进行基本操作 46 * Document对象在DOM解析模型中也属于一个Node对象, 47 * 它是其他Node对象所在的上下文,其他Node对象包括 48 * Element,Text,Attr,Comment,Processing Instruction等等 49 * 根节点 != 根元素,它们是包含关系 50 * </pre> 51 */ 52 Document document = builder.parse(new File("xml/book.xml")); 53 54 /** 55 * <pre> 56 * 获取到XML文档的根元素 57 * 对于XML中的Document是XML文档的根节点,而它的子元素是XML文档的XML文档根元素 58 * </pre> 59 */ 60 Element root = document.getDocumentElement(); 61 System.out.println("获取的XML文档的根元素节点:" + root.getTagName()); 62 63 /** 64 * <pre> 65 * 获取根元素节点的子节点 66 * 对于XML文档而言,无论是Document,Elment,Text等等, 67 * 它们在DOM解析模型中都属性一个Node,因此这里需要注意的一点是 68 * 空白字符在DOM解析中也会被作为一个Node元素来处理。 69 * </pre> 70 */ 71 // 获取到根元素的子节点 72 NodeList nodeList = root.getChildNodes(); 73 74 /* 75 * 空白字符也会被当作子节点来处理,因为它也是一个Node来处理, 但是属性不会被作为子节点 76 */ 77 System.out.println("子节点的个数为:" + nodeList.getLength()); 78 79 // 遍历所有的子节点 80 for (int i = 0; i < nodeList.getLength(); i++) { 81 Node node = nodeList.item(i); 82 switch (node.getNodeType()) { 83 case Node.ELEMENT_NODE: 84 System.out.println("获取的是元素:" + node.getNodeName()); 85 break; 86 case Node.TEXT_NODE: 87 System.out.println("获取的是文本" + node.getNodeName()); 88 break; 89 case Node.COMMENT_NODE: 90 System.out.println("获取的是注释:" + node.getNodeName()); 91 Comment comment = (Comment) node; 92 System.out.println("注释的内容是:" + comment.getData()); 93 break; 94 } 95 } 96 97 System.out.println("--------访问属性----------"); 98 // 访问属性 99 Attr attr = root.getAttributeNode("名字"); 100 System.out.println("根元素节点属性的值:" + attr.getValue()); 101 102 // 可以是使用一种更加直接的方式访问属性的值 103 String attrValue = root.getAttribute("名字"); 104 System.out.println("另一种方式获取根元素节点属性的值:" + attrValue); 105 106 // 获取元素的全部属性 107 NamedNodeMap attrs = root.getAttributes(); 108 for (int i = 0; i < attrs.getLength(); i++) { 109 Attr attr2 = (Attr) attrs.item(i); 110 System.out.println("name:" + attr2.getName() + ",value:" 111 + attr2.getValue()); 112 } 113 114 } 115 116 /** 117 * <pre> 118 * 使用JAXP完成添加元素节点操作 119 * 对于DOM解析模型来说,因为XML文档的上下文是Document对象 120 * 所以对于XML文档的操作都使用Document对象来完成 121 * </pre> 122 */ 123 @Test 124 public void addElementTest() throws Exception { 125 126 // 创建解析器工厂 127 DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance(); 128 129 // 创建解析器 130 DocumentBuilder builder = factory.newDocumentBuilder(); 131 132 // 获取XML文档的根节点(root node) 133 Document document = builder.parse(new File("xml/book2.xml")); 134 135 // 返回新创建的Element节点 136 Element book = document.createElement("书"); 137 138 Element bookName = document.createElement("书名"); 139 bookName.setTextContent("Liunx"); 140 141 Element author = document.createElement("作者"); 142 author.setTextContent("XXX"); 143 144 Element price = document.createElement("价格"); 145 price.setTextContent(String.valueOf(80.5)); 146 147 // 通过父元素添加子元素 148 book.appendChild(bookName); 149 book.appendChild(author); 150 book.appendChild(price); 151 152 document.getDocumentElement().appendChild(book); 153 154 TransformerFactory transformerFactory = TransformerFactory 155 .newInstance(); 156 Transformer transformer = transformerFactory.newTransformer(); 157 transformer.transform(new DOMSource(document), new StreamResult( 158 new File("xml/book2.xml"))); 159 } 160 161 /** 162 * 更新节点元素 163 */ 164 @Test 165 public void updateElementTest() throws Exception { 166 167 // 创建解析器工厂 168 DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance(); 169 170 // 创建解析器 171 DocumentBuilder builder = factory.newDocumentBuilder(); 172 173 // 获取XML文档的根节点(root node) 174 Document document = builder.parse(new File("xml/book2.xml")); 175 176 // 获取第3个价格元素 177 Node priceNode = document.getElementsByTagName("价格").item(2); 178 // 判断是否是Element类型 179 if (priceNode.getNodeType() == Node.ELEMENT_NODE) { 180 priceNode.setTextContent("200"); 181 } 182 183 TransformerFactory transformerFactory = TransformerFactory 184 .newInstance(); 185 Transformer transformer = transformerFactory.newTransformer(); 186 transformer.transform(new DOMSource(document), new StreamResult( 187 new File("xml/book2.xml"))); 188 } 189 190 @Test 191 public void deleteElementTest() throws Exception { 192 // 创建解析器工厂 193 DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance(); 194 195 // 创建解析器 196 DocumentBuilder builder = factory.newDocumentBuilder(); 197 198 // 获取XML文档的根节点(root node) 199 Document document = builder.parse(new File("xml/book2.xml")); 200 201 Node node = document.getElementsByTagName("书").item(2); 202 203 document.getDocumentElement().removeChild(node); 204 205 TransformerFactory transformerFactory = TransformerFactory 206 .newInstance(); 207 Transformer transformer = transformerFactory.newTransformer(); 208 transformer.transform(new DOMSource(document), new StreamResult( 209 new File("xml/book2.xml"))); 210 } 211 212 /** 213 * 添加子元素到到指定位置 214 * @throws Exception 215 */ 216 @Test 217 public void insertElementTest() throws Exception{ 218 219 // 创建解析器工厂 220 DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance(); 221 222 // 创建解析器 223 DocumentBuilder builder = factory.newDocumentBuilder(); 224 225 // 获取XML文档的根节点(root node) 226 Document document = builder.parse(new File("xml/book2.xml")); 227 228 // 返回新创建的Element节点 229 Element book = document.createElement("书"); 230 231 Element bookName = document.createElement("书名"); 232 bookName.setTextContent("Liunx"); 233 234 Element author = document.createElement("作者"); 235 author.setTextContent("XXX"); 236 237 Element price = document.createElement("价格"); 238 price.setTextContent(String.valueOf(80.5)); 239 240 // 通过父元素添加子元素 241 book.appendChild(bookName); 242 book.appendChild(author); 243 book.appendChild(price); 244 245 document.getDocumentElement().insertBefore(book, document.getElementsByTagName("书").item(1)); 246 247 TransformerFactory transformerFactory = TransformerFactory 248 .newInstance(); 249 Transformer transformer = transformerFactory.newTransformer(); 250 transformer.transform(new DOMSource(document), new StreamResult( 251 new File("xml/book2.xml"))); 252 } 253 254 255 /** 256 * 添加属性 257 * @throws Exception 258 */ 259 @Test 260 public void addAttrTest() throws Exception{ 261 262 // 创建解析器工厂 263 DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance(); 264 265 // 创建解析器 266 DocumentBuilder builder = factory.newDocumentBuilder(); 267 268 // 获取XML文档的根节点(root node) 269 Document document = builder.parse(new File("xml/book2.xml")); 270 271 Node node = document.getElementsByTagName("书").item(1); 272 if(node.getNodeType() == Node.ELEMENT_NODE){ 273 Element element = (Element) node; 274 element.setAttribute("名称","Java开发"); 275 } 276 TransformerFactory transformerFactory = TransformerFactory 277 .newInstance(); 278 Transformer transformer = transformerFactory.newTransformer(); 279 transformer.transform(new DOMSource(document), new StreamResult( 280 new File("xml/book2.xml"))); 281 } 282 283 284 285 }