优化目的与目标:
1.优化的目的:
- 提高资源利用率
- 避免短板效应
- 提高系统吞吐量
- 同时满足更多用户在线需求
2.优化的目标:
- 减少磁盘IO:全表扫描,磁盘临时表,日志和数据块fsync
- 减少网络带宽:返回太多数据,交互次数过多
- 降低CPU消耗:排序分组(order by,group by),聚合函数(max,min,sum),逻辑读
需要关注的性能指标:
1.QPS/TPS:
- TPS:平均每秒的事务数
- QPS:平均每秒SQL语句的执行数
- QPS(TPS)= 并发请求数/平均响应时间
- QPS/TPS反映了一个系统的吞吐量
- QPS/TPS低的几种可能:并发量不够,平均响应时间长(慢SQL导致资源争用),某个资源出现性能瓶颈。
2.InnoDB逻辑读:
逻辑读指从内存中读取block的数量,一次逻辑读即读取一个内存块,指标单位为blocks。逻辑读体现了数据库整体的SQL执行性能。
Logical Reads Per Query=InnoDB Logical Reads/QPS
逻辑读过高意味着读取了过量的非需要的block。
3.临时表:
MySQL用于存储中间结果集的表,查询完成后自动删除。当临时表被大量创建时,往往意味着复杂SQL过多。内存临时表使用MEMORY存储引擎,硬盘临时表使用MyISAM存储引擎。
大多数情况,参数tmp_table_size决定MySQL创建临时表的行为,应该尽量避免mysql创建临时表的行为,尤其是磁盘临时表。
创建临时表的场景:
union查询,子查询,semi-join(IN,exists),高代价的order by/group by
创建磁盘临时表的场景:
表包含TEXT或者BLOB列;GROUP BY或者DISTINCT子句中包含长度大于512字节的列;使用UNION或UNION ALL时,SELECT 子句中包含大于512字节的列。
4.CPU使用率:
- CPU是如何被消耗的?
处理逻辑读:1) 维护从存储系统到内存中的数据一致性问题 2) filter 过滤条件(where a=?)
排序分组查询。order by,group by
聚合运算。sum,max,avg - CPU资源与逻辑读的关系
avg_lgc_io:每条查询需要的平均逻辑IO
total_lgc_io:实例CPU资源单位时间能够处理的逻辑IO总量
计算公式:total_lgc_io=avg_lgc_io×qps
单位时间CPU资源=查询执行的平均成本×单位时间执行的查询数量 - CPU使用率高的几种可能:
1) QPS高。单条查询简单,执行成本低,QPS和CPU使用率曲线吻合,SQL优化余地小
2) 查询执行成本高。执行效率低,资源消耗大,一般表现为慢SQL或较差的执行计划,SQL优化空间大。
5.连接数/会话数:
一定程度上体现了系统的业务压力,RDS最大连接数由实例规格决定。活跃连接数指同时存在SQL‘请求的链接数量。
连接数过多可能的原因:程序未使用或合理配置连接池,查询效率低下,事务未及时提交,等待事件。
6.IOPS:
每秒发生磁盘IO的次数,一旦磁盘IO成为数据库的瓶颈,性能会急剧下降,磁盘的性能瓶颈一般在于iops而不是吞吐量,RDS上默认分配SSD,具有优秀的随机读写能力。
IOPS高的集中可能:
1) 热平衡被破坏(频繁的全表扫描) 2) 事务提交频繁(fsync) 3) 磁盘临时表 4) 不合理的系统设计(日志入库。。。)
优化思路:
1.优化流程:
完整的监控体系:细致合理的告警;多维度图形化指标;暴露性能缺陷,掌握大规模资源
V
分析日志定位问题:Exceptional Time Range;DB/System error log;slow log;SQL执行统计
V
分析业务逻辑:读写需求;业务精简;资源调用关系
V
SQL优化:explain;SQL改写;索引调整;参数调整
2.MySQL的执行流程:
1) 客户提交一条语句
2) 现在查询缓存查看是否有对应的缓存数据,如果有直接返回(有的可能性很小,因此一般建议关闭查询缓存)
3) 交给解析器处理,解析器会将提交的语句生成一个解析树
4) 预处理器会处理解析树,形成新的解析树。此阶段存在一些SQL改写的过程
5) 改写后的解析树提交给查询优化器。查询优化器生成执行计划
6) 执行计划交由执行引擎调用存储引擎接口,完成执行过程,这里要注意MySQL的server层和Engine层是分离的
7) 最终结果由执行引擎返回给客户端,如果开启查询缓存的话则会缓存
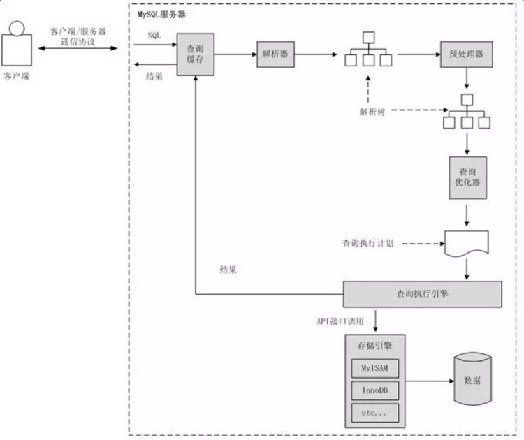
执行过程:
SQL执行顺序:
(8) SELECT (9) DISTINCT
(1) FROM
(3)
(2) ON
(4) WHERE
(5) GROUP
(6) WITH {CUBE|ROLLUP}
(7) HAVING
(10) ORDER BY
(11) LIMIT
3.MySQL优化器和执行计划:
查询优化器:
- 负责生成SQL语句的有效执行计划的数据库组件
- 优化器是数据库核心价值所在,它是数据库的’大脑‘
- 优化SQL,某种意义上就是理解优化器的行为
- 优化的依据是执行成本(CBO)
- 优化器工作的前提是了解数据,工作的目的是解析SQL,生成执行计划
查询优化器工作过程:
4.查看执行计划:
explain Synax
- 查看一个SQL语句的执行计划:explain SQL_Statement
- 结合show warning查看优化器的改写:explain extended SQL_Statement
- 用于分区表查看执行计划:explain partition SQL_Statement

解读执行计划:
id :包含一组数字,表示查询中执行select子句或操作表的顺序(id若相同,执行顺序由上而下;如果是子查询,id序号会递增,id越大优先级越高,越先被执行)
select_type :表示查询中每个select子句的类型:
- SIMPLE:查询中不包含子查询或者UNION
- PRIMARY:查询中若包含任何复杂的子部分,最外层查询则被标记为PRIMARY
- SUBQUERY:在select或者where列表中包含子查询,该子查询被标记为SUBQUERY
- DERIVED:在from列表中包含的子查询被标记为DERIVED
- UNION:位于UNION关键字之后的查询;UNION语句的第一个查询根据情况被标记PRIMARY/SUBQUERY/DERIVED
- UNION RESULT:UNION语句的结果集
type:表示MySQL在表中找到所需行的方式,又称为访问类型: - ALL:Full Table Scan,全表扫描
- index:Full Index Scan,索引全扫描
- range:索引范围扫描
- ref:非唯一性索引扫描
- eq_ref:唯一性索引扫描
- const、system:常量匹配,如PRIMARY KEY/UNIQUE KEY
- NULL:MySQL不用访问表或者索引可以直接得到结果
(Null性能最好,依次向上递减,ALL性能最差)
possible_keys:指出MySQL从where条件上找到的可用索引,过滤条件中的字段上若存在索引,则会在此列出,不能决定哪个索引被引用
key:显示MySQL在查询中实际使用的索引,若没有使用索引则显示为NULL
key_len:表示索引中使用的字节数,可通过该列计算查询中使用索引的长度
ref:表示上述表的连接匹配条件,即哪些列或常量被用于查找索引列上的值
rows:表示MySQL根据表的统计信息及索引选用情况,估算的找到所需的记录需要读取的行数
Extra:包含不适合在其他列中显示但是十分重要的额外信息
- Using index: 使用覆盖索引标志(Covering Index)
- Using where: 使用where条件进行过滤
- Using temporary: 查询中使用到了临时表或临时文件,通常会造成性能的下降
- Using filesort: MySQL不得不进行额外的排序操作,通常会造成性能下降
- Using index condition: 使用到ICP特性进行查询优化(index condition push down)