本文基于互联网多篇blog实战,对自己实际部署安装过程中遇到的问题记录写下。
整个安装部署使用非 root 身份
配置要求:
1. linux 系统
2. 至少2G内存
3. 至少2个CPU
4. 所有机器之间网络互通
5. 机器hostname、mac地址、product_uuid 唯一
6. 6443端口可使用
7. swap 交换分区关闭
一 前置步骤:
1. 统一所有节点的 /etc/hosts 文件中关于k8s集群的主机映射,以及相应机器的hostname
2. 关闭所有机器的swap分区
sudo swapoff -a #修改/etc/fstab,注释掉swap行 sudo vi /etc/fstab
3. 统一机器时区
sudo timedatectl set-timezone Asia/Shanghai #系统日志服务立即生效 sudo systemctl restart rsyslog
4. 统一安装docker服务 (2022.05.03 版本Docker version 20.10.7, build 20.10.7-0ubuntu5~20.04.2)
#这里直接使用自带源来安装,其版本符合要求 sudo apt-get install docker.io
5. 统一安装kubeadm和kubelet工具
sudo apt-get install -y curl curl -s https://mirrors.aliyun.com/kubernetes/apt/doc/apt-key.gpg | sudo apt-key add - # 此处使用 kubernetes-xenial 而不是 Ubuntu 20.04 的focal echo "deb https://mirrors.aliyun.com/kubernetes/apt/ kubernetes-xenial main" | sudo tee /etc/apt/sources.list.d/kubernetes.list sudo apt-get update sudo apt-get install -y kubelet kubeadm kubectl
二 初始化master节点
使用下面命令来初始化master
sudo kubeadm init --image-repository=gcr.akscn.io/google_containers --pod-network-cidr=172.16.0.0/16
返回报错:
“[ERROR ImagePull]: failed to pull image gcr.akscn.io/google_containers/kube-apiserver:v1.23.6: output: Error response from daemon: Get https://gcr.akscn.io/v2/: http: server gave HTTP response to HTTPS client
, error: exit status 1
[ERROR ImagePull]: failed to pull image gcr.akscn.io/google_containers/kube-controller-manager:v1.23.6: output: Error response from daemon: Get https://gcr.akscn.io/v2/: read tcp 192.168.0.200:44566->40.73.69.67:443: read: connection reset by peer
, error: exit status 1
[ERROR ImagePull]: failed to pull image gcr.akscn.io/google_containers/kube-scheduler:v1.23.6: output: Error response from daemon: Get https://gcr.akscn.io/v2/: http: server gave HTTP response to HTTPS client
, error: exit status 1
[ERROR ImagePull]: failed to pull image gcr.akscn.io/google_containers/kube-proxy:v1.23.6: output: Error response from daemon: Get https://gcr.akscn.io/v2/: http: server gave HTTP response to HTTPS client
, error: exit status 1
[ERROR ImagePull]: failed to pull image gcr.akscn.io/google_containers/pause:3.6: output: Error response from daemon: Get https://gcr.akscn.io/v2/: http: server gave HTTP response to HTTPS client
, error: exit status 1
[ERROR ImagePull]: failed to pull image gcr.akscn.io/google_containers/etcd:3.5.1-0: output: Error response from daemon: Get https://gcr.akscn.io/v2/: x509: certificate has expired or is not yet valid
, error: exit status 1
[ERROR ImagePull]: failed to pull image gcr.akscn.io/google_containers/coredns:v1.8.6: output: Error response from daemon: Get https://gcr.akscn.io/v2/: http: server gave HTTP response to HTTPS client
, error: exit status 1”
多次Google搜索没找到解决方法,最后仔细看其他成功的blog发现是因为初始化的命令行参数使用了“--image-repository=gcr.akscn.io/google_containers”导致的,更换为“sudo kubeadm init --image-repository registry.cn-hangzhou.aliyuncs.com/google_containers --pod-network-cidr=172.16.0.0/16” 后成功继续执行,但紧接着又报错:
“[kubelet-check] The HTTP call equal to 'curl -sSL http://localhost:10248/healthz' failed with error: Get "http://localhost:10248/healthz": dial tcp 127.0.0.1:10248: connect: connection refused”
网络搜索后得知是因为kubelet服务没有启动,用 sudo systemctl start kubelet 尝试启动,但是启动没有成功,查看报错日志发现
“kubelet[61248]: E0503 16:54:09.970816 61248 server.go:302] "Failed to run kubelet" err="failed to run Kubelet: misconfiguration: kubelet cgroup driver: \"systemd\" is different from docker cgroup driver: \"cgroupfs\""”
根据错误提示,应该是docker driver导致,通过创建/etc/docker/daemon.json文件,写入如下配置:
{ "exec-opts": [ "native.cgroupdriver=systemd" ] }
并重启相关服务后,kubelet服务成功运行,如下:
sudo systemctl daemon-reload sudo systemctl restart docker sudo systemctl start kubelet

kubelet服务成功后,继续进行kubeadm的初始化,此时报错:
“error execution phase preflight: [preflight] Some fatal errors occurred:
[ERROR Port-6443]: Port 6443 is in use
[ERROR Port-10259]: Port 10259 is in use
[ERROR Port-10257]: Port 10257 is in use
[ERROR FileAvailable--etc-kubernetes-manifests-kube-apiserver.yaml]: /etc/kubernetes/manifests/kube-apiserver.yaml already exists
[ERROR FileAvailable--etc-kubernetes-manifests-kube-controller-manager.yaml]: /etc/kubernetes/manifests/kube-controller-manager.yaml already exists
[ERROR FileAvailable--etc-kubernetes-manifests-kube-scheduler.yaml]: /etc/kubernetes/manifests/kube-scheduler.yaml already exists
[ERROR FileAvailable--etc-kubernetes-manifests-etcd.yaml]: /etc/kubernetes/manifests/etcd.yaml already exists
[ERROR Port-10250]: Port 10250 is in use
[ERROR Port-2379]: Port 2379 is in use
[ERROR Port-2380]: Port 2380 is in use
[ERROR DirAvailable--var-lib-etcd]: /var/lib/etcd is not empty”
从错误中发现端口被占用了,如下
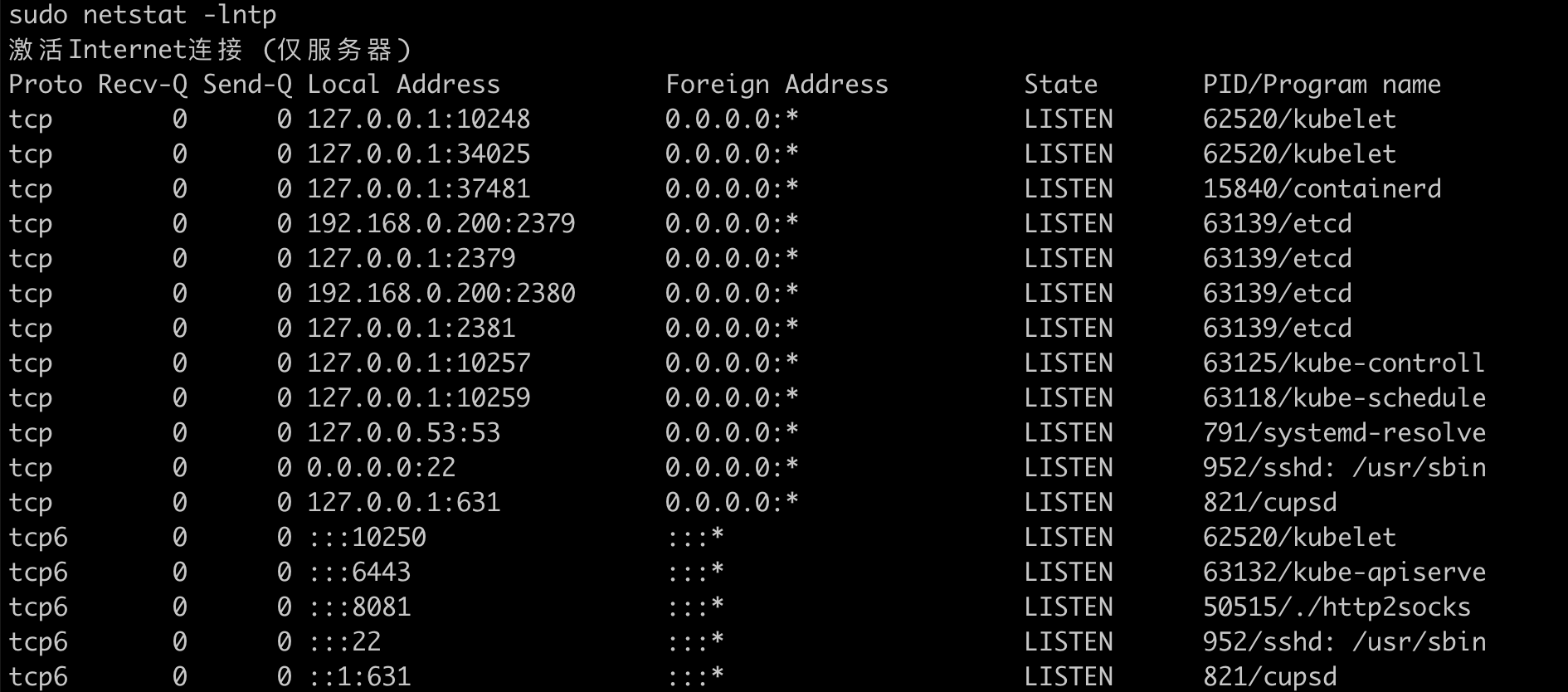
从结果看,很明显是kubeadm init之前的操作部分成功了,重新执行命令会因为之前已经成功的步骤冲突而报错,在kubeadm --help中,发现有个可用的子命令可以用来重置,如下:
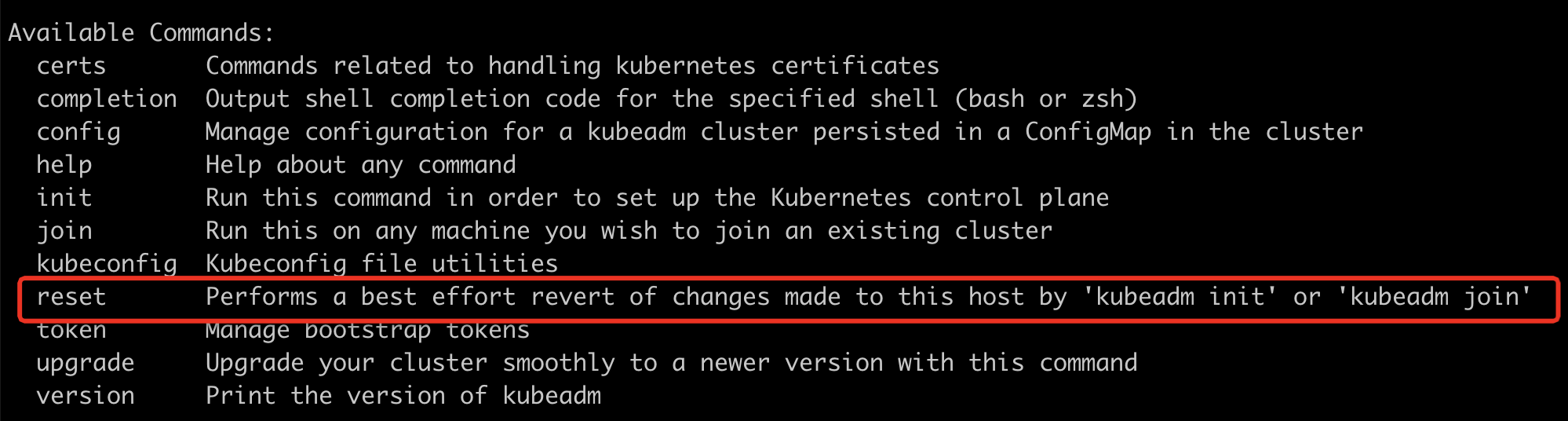
重置成功后再次初始化。到此,k8s的master已经初始化成功,并提示
“kubeadm join 192.168.0.200:6443 --token dcp0ln.070nknu9j8gs2dwc \
--discovery-token-ca-cert-hash sha256:e0f34d8d73b6820ef804a2d5c3b081b0bc1ea29ed19392e405a4aedba916cb07”
这表明,master已经成功部署,可以在node节点中执行上面的命令以加入到集群中。
登录到需要加入的第一台worker节点上执行前面的join命令,报了master曾经出现的错误
“[kubelet-check] The HTTP call equal to 'curl -sSL http://localhost:10248/healthz' failed with error: Get "http://localhost:10248/healthz": dial tcp 127.0.0.1:10248: connect: connection refused.”
一样的,查看日志发现是kubelet服务没启动,一样创建/etc/docker/daemon.json文件并写入相同配置后重启服务,然后再次执行join命令,报错:
“error execution phase preflight: [preflight] Some fatal errors occurred:
[ERROR FileAvailable--etc-kubernetes-kubelet.conf]: /etc/kubernetes/kubelet.conf already exists
[ERROR FileAvailable--etc-kubernetes-bootstrap-kubelet.conf]: /etc/kubernetes/bootstrap-kubelet.conf already exists
[ERROR Port-10250]: Port 10250 is in use
[ERROR FileAvailable--etc-kubernetes-pki-ca.crt]: /etc/kubernetes/pki/ca.crt already exists”
同之前master上执行kubeadm init类似,也是kubeadm join部分步骤成功导致的,同样使用命令 sudo kubeadm reset 重置后重新join就成功了。