Scala是一门多范式的编程语言,一种类似java的编程语言[1] ,设计初衷是实现可伸缩的语言[2] 、并集成面向对象编程和函数式编程的各种特性。
Scala 具有很完整又很强大的集合处理能力。Scala拥有庞大而完整的集合类库,比如Set, List, Vector, Tuple, Map,而有效的泛型能让你肆意组合这些类型得到新的类型,比如像这样的类别:List[Map[String, (Int, List[String)]]],这是一个链表,每个链表元素是一个映射,映射中用字符做key,另一个Tuple元组做value(值)这个元组的第一个元素是整数,第二个元素是一个链表,这样的集合在其他语言中实现起来比较麻烦。
scala不仅有函数式语言对集合处理的先天优势:map, fold, zip, foreach, collect, filter等等,还有OOP面向对象语言的辅助函数(比如take(5)可以取得前五个元素,takeRight(5)是最后五个)
Scala对集合预制的辅助方法(Helper functions)数量之多甚至超过了Java。同时Scala还提供immutable(不可变)结构与mutable(可变)结构,让程序员可以在命令式与函数式中自由切换。
启动解释器 tab键补全方法名,补全后继续tab可以打印出函数的定义。
REPL 交互式解释器或者交互式编程环境 R(read)、E(evaluate)、P(print)、L(loop)
使用自带的sbt console启动或者scala直接启动
scala> 1.+(1)
res0: Int = 2
res0是解释器自动创建的变量名称,用来指代表达式的计算结果。它是Int类型,值为2。
scala> val aa=2
aa: Int = 2
scala> aa=5
<console>:12: error: reassignment to val
aa=5
^
val 定义的不可变量 var 定义可变量
scala> var name="tianyongtao"
name: String = tianyongtao
scala> var name:String="tianyongtao"
name: String = tianyongtao
scala> var name:string="tianyongtao"
<console>:11: error: not found: type string
var name:string="tianyongtao"
^
定义变量可以同时赋值
scala> def add(num:Int):Int=num+100
add: (num: Int)Int
scala> add(10)
res2: Int = 110
scala> def printnum(str:String)=println(str)
printnum: (str: String)Unit
scala> printnum("hello world!")
hello world!
用def 定义函数
scala> def printstr()=println("love china")
printstr: ()Unit
scala> printstr()
love china
scala> def printstr1=println("love china")
printstr1: Unit
scala> printstr1
love china
如果函数不带参数可以不用()
scala> (x:Int)=>x+50
res7: Int => Int = $$Lambda$1169/1638591569@69dc0dd1
scala> res7(100)
res8: Int = 150
scala 允许创建匿名函数如上所示
scala> val addnum=(x:Int)=>x+10
addnum: Int => Int = $$Lambda$1175/26815371@16af0251
scala> addnum(10)
res9: Int = 20
你可以传递匿名函数,或将其保存成不变量。如上所示
如果你的函数有很多表达式,可以使用{}来格式化代码。
_ 下划线的用法
1.导入引用的时候
import math._
这里的math._就相当于Java中的math.*; 即“引用包中的所有内容”。
2.集合中使用
val newArry= (1 to 10).map(_*2)
这里的下划线代表了集合中的“某(this)”一个元素。
3.模式匹配
scala> val v="tian"
v: String = tian
scala> val vaule=v match {
case "yong"=>1
case "tian"=>2
case _ =>"not match"
}
vaule: Any = 2
在这里的下划线相当于“others”的意思,就像Java switch语句中的“default”。
//匹配以0开头,长度为三的列表
expr match {
case List(0, _, _) => println("found it")
case _ =>
}
//匹配以0开头,长度任意的列表
expr match {
case List(0, _*) => println("found it")
case _ =>
}
//匹配元组元素
expr match {
case (0, _) => println("found it")
case _ =>
}
//将首元素赋值给head变量
val List(head, _*) = List("a")
访问Tuple元素
scala> val ls=(1,2,3)
ls: (Int, Int, Int) = (1,2,3)
scala> ls._1
res33: Int = 1
scala> ls._2
res34: Int = 2
如果函数的参数在函数体内只出现一次,则可以使用下划线代替:
val f1 = (_: Int) + (_: Int)
//等价于
val f2 = (x: Int, y: Int) => x + y
scala> val ls=List(1,2,3,4)
scala> ls.foreach(println(_))
//等价于
ls.foreach(e => println(e))
scala> ls.filter(x=>x>2)
res37: List[Int] = List(3, 4)
scala> ls.filter(_>2)
res38: List[Int] = List(3, 4)
我们通过下划线实现赋值操作符,从而可以精确地控制赋值过程:
class Foo {
def name = { "foo" }
def name_=(str: String) {
println("set name " + str)
}
val m = new Foo()
m.name = "Foo" //等价于: m.name_=("Foo")
定义部分应用函数(partially applied function)偏函数
我们可以为某个函数只提供部分参数进行调用,返回的结果是一个新的函数,即部分应用函数。因为只提供了部分参数,所以部分应用函数也因此而得名。
scala> def addint(a:Int,b:Int,c:Int):Int=a+b+c
addint: (a: Int, b: Int, c: Int)Int
scala> val addb=addint(10,_:Int,10)
addb: Int => Int = $$Lambda$1183/1050280259@644e2230
scala> addb(10)
res14: Int = 30
柯里化(Currying)指的是将原来接受两个参数的函数变成新的接受一个参数的函数的过程。新的函数返回一个以原有第二个参数为参数的函数。你可以对任何多参数函数执行柯里 化。
scala> def sumint(x:Int)(y:Int)=x+y
sumint: (x: Int)(y: Int)Int
scala> val res1=sumint(2)_
res1: Int => Int = $$Lambda$1490/770087521@6b2a290d
scala> res1(1)
res40: Int = 3
Scala 语言中提供的数组是用来存储固定大小的同类型元素,数组对于每一门编辑应语言来说都是重要的数据结构之一。
数组中某个指定的元素是通过索引来访问的。数组的第一个元素索引为0,最后一个元素的索引为元素总数减1。
scala> var myarray=Array("tian","yong","tao")
myarray: Array[String] = Array(tian, yong, tao)
scala> myarray(0)
res42: String = tian
scala> myarray.size
res47: Int = 3
scala> myarray.length
res48: Int = 3
scala> myarray.head
res3: String = tian
scala> for(i<- 0 to myarray.length-1) println(myarray(i))
tian
yong
tao
scala> for(x<-myarray) println(x)
tian
yong
tao
打印乘法表
scala> for(j<- 1 to 9;i<-1 to j){ print(i+"*"+j+"="+j*i+" ");if(j==i) println()}
1*1=1
1*2=2 2*2=4
1*3=3 2*3=6 3*3=9
1*4=4 2*4=8 3*4=12 4*4=16
1*5=5 2*5=10 3*5=15 4*5=20 5*5=25
1*6=6 2*6=12 3*6=18 4*6=24 5*6=30 6*6=36
1*7=7 2*7=14 3*7=21 4*7=28 5*7=35 6*7=42 7*7=49
1*8=8 2*8=16 3*8=24 4*8=32 5*8=40 6*8=48 7*8=56 8*8=64
1*9=9 2*9=18 3*9=27 4*9=36 5*9=45 6*9=54 7*9=63 8*9=72 9*9=81
多维数组
scala> val mutarray=Array.ofDim[Int](2,3)
mutarray: Array[Array[Int]] = Array(Array(0, 0, 0), Array(0, 0, 0))
scala> mutarray(0)(0)=1
scala> mutarray(0)(1)=2
..........
scala> mutarray
res23: Array[Array[Int]] = Array(Array(1, 2, 3), Array(5, 5, 4))
多维数组遍历
scala> for(x<-mutarray) for(y<-x) print(y)
123554
scala> var aa=Array(1,2,3)
aa: Array[Int] = Array(1, 2, 3)
scala> var bb=Array(1,2,3,5,6)
bb: Array[Int] = Array(1, 2, 3, 5, 6)
scala> aa++bb
res28: Array[Int] = Array(1, 2, 3, 1, 2, 3, 5, 6)
scala> aa union bb
res29: Array[Int] = Array(1, 2, 3, 1, 2, 3, 5, 6)
scala> val cc=Array("a","bff","ddf")
cc: Array[String] = Array(a, bff, ddf)
scala> cc++aa
res30: Array[Any] = Array(a, bff, ddf, 1, 2, 3)
scala> aa.diff(bb)
res35: Array[Int] = Array()
scala> bb.diff(aa)
res36: Array[Int] = Array(5, 6)
scala> aa.intersect(bb)
res37: Array[Int] = Array(1, 2, 3)
scala> Array.concat(aa,bb) //必须是相同类型的
res42: Array[Int] = Array(1, 2, 3, 1, 2, 3, 5, 6)
scala> Array.range(1,10)
res43: Array[Int] = Array(1, 2, 3, 4, 5, 6, 7, 8, 9)
scala> Array.range(1,10,2)
res44: Array[Int] = Array(1, 3, 5, 7, 9)
def iterate[T]( start: T, len: Int )( f: (T) => T ): Array[T]
返回指定长度数组,每个数组元素为指定函数的返回值。
以下实例数组初始值为 1,长度为 5,计算函数为a=>a+1:
scala> Array.iterate(1,5)(a=>a+1)
res50: Array[Int] = Array(1, 2, 3, 4, 5)
scala> Array.fill(5)(10)
res53: Array[Int] = Array(10, 10, 10, 10, 10)
scala> Array.fill(2,5)(10)
res54: Array[Array[Int]] = Array(Array(10, 10, 10, 10, 10), Array(10, 10, 10, 10, 10))
scala> Array.fill(10)(10)
res229: Array[Int] = Array(10, 10, 10, 10, 10, 10, 10, 10, 10, 10)
scala> Array.fill(10)(5)
res230: Array[Int] = Array(5, 5, 5, 5, 5, 5, 5, 5, 5, 5)
scala> Array.fill(10)(5,2)
res231: Array[(Int, Int)] = Array((5,2), (5,2), (5,2), (5,2), (5,2), (5,2), (5,2), (5,2), (5,2), (5,2))
scala> Array.fill(10)(5,2,3)
res232: Array[(Int, Int, Int)] = Array((5,2,3), (5,2,3), (5,2,3), (5,2,3), (5,2,3), (5,2,3), (5,2,3), (5,2,3), (5,2,3), (5,2,3))
返回指定长度数组,每个数组元素为指定函数的返回值,默认从 0 开始。tabulate ['tæbjulet] 制表 使成平面
scala> Array.tabulate(3)(a=>a+5)
res56: Array[Int] = Array(5, 6, 7)
scala> arrb.-(100)
res268: scala.collection.mutable.ArrayBuffer[Int] = ArrayBuffer(1, 2, 3, 5, 8, 80, 60, 8, 16, 90)
scala> arrb.-(8)
res269: scala.collection.mutable.ArrayBuffer[Int] = ArrayBuffer(1, 2, 3, 5, 80, 60, 8, 16, 90)
scala> gg++arrb
res262: Array[Int] = Array(100, 2, 3, 1, 2, 3, 5, 8, 80, 60, 8, 16, 90)
scala> gg++:arrb
res263: scala.collection.mutable.ArrayBuffer[Int] = ArrayBuffer(100, 2, 3, 1, 2, 3, 5, 8, 80, 60, 8, 16, 90)
List
Scala 列表类似于数组,它们所有元素的类型都相同,但是它们也有所不同:列表是不可变的,值一旦被定义了就不能改变,
其次列表 具有递归的结构(也就是链接表结构)而数组不是
scala> List.range(1,5)
res61: List[Int] = List(1, 2, 3, 4)
scala> List.fill(3,2)(5)
res62: List[List[Int]] = List(List(5, 5), List(5, 5), List(5, 5))
scala> List.concat(ls1,ls2)
res63: List[Int] = List(1, 2, 3, 4, 3, 3, 3, 3, 3)
scala> List.iterate(1,5)(a=>a+1)
res65: List[Int] = List(1, 2, 3, 4, 5)
scala> List.tabulate(3)(a=>a+3)
res67: List[Int] = List(3, 4, 5)
构造列表的两个基本单位是 Nil 和 ::
Nil 也可以表示为一个空列表。
scala> val site = "Runoob" :: ("Google" :: ("Baidu" :: ("sohu"::("sina"::Nil))))
site: List[String] = List(Runoob, Google, Baidu, sohu, sina)
scala> val site = "Runoob" :: ("Google" :: ("Baidu" :: Nil))
site: List[String] = List(Runoob, Google, Baidu)
// 二维列表
val dim = (1 :: (0 :: (0 :: Nil))) ::
(0 :: (1 :: (0 :: Nil))) ::
(0 :: (0 :: (1 :: Nil))) :: Nil
scala> ls1.:::(ls2)
res99: List[Int] = List(3, 3, 3, 3, 3, 1, 2, 3, 4)
scala> ls1:::ls2
res100: List[Int] = List(1, 2, 3, 4, 3, 3, 3, 3, 3)
scala> ls1.drop(1)
res102: List[Int] = List(2, 3, 4)
scala> ls1.:+(100)
res108: List[Int] = List(1, 2, 3, 4, 100)
scala> ls1.+:(100)
res109: List[Int] = List(100, 1, 2, 3, 4)
scala> ls1++ls2
res133: List[Int] = List(1, 2, 3, 4, 3, 3, 3, 3, 3)
scala> ls1++:ls2
res136: List[Int] = List(1, 2, 3, 4, 3, 3, 3, 3, 3)
-
::该方法被称为cons,意为构造,向队列的头部追加数据,创造新的列表。用法为x::list,其中x为加入到头部的元素,无论x是列表与否,它都只将成为新生成列表的第一个元素,也就是说新生成的列表长度为list的长度+1(btw,x::list等价于list.::(x)) -
:+和+:两者的区别在于:+方法用于在尾部追加元素,+:方法用于在头部追加元素,和::很类似,但是::可以用于pattern match ,而+:则不行. 关于+:和:+,只要记住冒号永远靠近集合类型就OK了。 -
++该方法用于连接两个集合,list1++list2 -
:::该方法只能用于连接两个List类型的集合
scala> val strb=new StringBuilder()
strb: StringBuilder =
scala> ls1.addString(strb)
res161: StringBuilder = 1234
scala> ls1.addString(strb,",")
res164: StringBuilder = 1,2,3,4
scala> val strb=new StringBuilder()
strb: StringBuilder =
scala> ls1.addString(strb,",")
res165: StringBuilder = 1,2,3,41,2,3,4
scala> ls1.contains(1)
res166: Boolean = true
scala> ls1++ls2.distinct
res167: List[Int] = List(1, 2, 3, 4, 3)
scala> ls1.dropRight(2)
res169: List[Int] = List(1, 2)
scala> ls1.dropWhile(_<2)
res182: List[Int] = List(2, 3, 4)
find:查找集合第一个符合条件的元素
scala> ls1.find(_>2)
res183: Option[Int] = Some(3)
scala> ls1.partition(_%2==0)
res187: (List[Int], List[Int]) = (List(2, 4),List(1, 3))
scala> ls1.takeWhile(_<3)
res195: List[Int] = List(1, 2)
scala> ls1.takeWhile(_>2)
res196: List[Int] = List() //结果为空 为什么不是3 4??
scala> ls1.map(x=>(x,1))
res211: List[(Int, Int)] = List((1,1), (2,1), (3,1), (4,1))
Map
scala> val mymap=Map("name"->"tianyongtao","sex"->"man","age"->100)
mymap: scala.collection.immutable.Map[String,Any] = Map(name -> tianyongtao, sex -> man, age -> 100)
scala> mymap.keys
res215: Iterable[String] = Set(name, sex, age)
scala> mymap.keySet
res217: scala.collection.immutable.Set[String] = Set(name, sex, age)
scala> mymap.values
res218: Iterable[Any] = MapLike.DefaultValuesIterable(tianyongtao, man, 100)
scala> mymap.keys.foreach{i=>print(" key= "+i); println(" value="+mymap(i))}
key= name value=tianyongtao
key= sex value=man
key= age value=100
scala> for((k,v) <- mymap) println(k+" "+v)
name tianyongtao
sex man
age 100
def contains(key: Int): Boolean
scala> mymap.contains("name")
res227: Boolean = true
scala> mymap.contains("named")
res228: Boolean = false
scala> mymap.-("sex")
res230: scala.collection.immutable.Map[String,Any] = Map(name -> tianyongtao, age -> 100)
scala> mymap.-("age","sex")
res234: scala.collection.immutable.Map[String,Any] = Map(name -> tianyongtao)
scala> val tmap=Map("name"->"tianyong")
tmap: scala.collection.immutable.Map[String,String] = Map(name -> tianyong)
scala> mymap++tmap
res243: scala.collection.immutable.Map[String,Any] = Map(name -> tianyong, sex -> man, age -> 100)
def get(key: Int): Option[Int]
scala> mymap.get("name")
res247: Option[Any] = Some(tianyongtao)
def apply(key: Int): Int
scala> mymap.apply("name")
res252: Any = tianyongtao
scala> mymap.iterator.foreach(println)
(name,tianyongtao)
(sex,man)
(age,100)
Scala Set(集合)是没有重复的对象集合,所有的元素都是唯一的。
Scala 集合分为可变的和不可变的集合。
scala> val myset=Set(1,2,3,4,5,6)
myset: scala.collection.immutable.Set[Int] = Set(5, 1, 6, 2, 3, 4)
scala> val myset=Set(1,2,3,4,5,6,6)
myset: scala.collection.immutable.Set[Int] = Set(5, 1, 6, 2, 3, 4)
scala> myset.+(8)
res289: scala.collection.immutable.Set[Int] = Set(5, 1, 6, 2, 3, 8, 4)
scala> myset+(8)
res290: scala.collection.immutable.Set[Int] = Set(5, 1, 6, 2, 3, 8, 4)
scala> myset+8
res291: scala.collection.immutable.Set[Int] = Set(5, 1, 6, 2, 3, 8, 4)
scala> myset.-(2)
res294: scala.collection.immutable.Set[Int] = Set(5, 1, 6, 3, 4)
scala> val tset=Set(5,9,30)
tset: scala.collection.immutable.Set[Int] = Set(5, 9, 30)
scala> myset&tset
res300: scala.collection.immutable.Set[Int] = Set(5)
scala> myset&~tset
res301: scala.collection.immutable.Set[Int] = Set(1, 6, 2, 3, 4)
scala> myset+(200,100)
res313: scala.collection.immutable.Set[Int] = Set(5, 1, 6, 2, 3, 4, 200, 100)
scala> myset++:tset
res315: scala.collection.immutable.Set[Int] = Set(5, 1, 6, 9, 2, 3, 30, 4)
scala> myset++tset
res316: scala.collection.immutable.Set[Int] = Set(5, 1, 6, 9, 2, 3, 30, 4)
scala> myset-(5,1)
res318: scala.collection.immutable.Set[Int] = Set(6, 2, 3, 4)
scala> myset.product //所有数字元素的乘积
res320: Int = 720
scala> myset.partition(_>5)
res321: (scala.collection.immutable.Set[Int], scala.collection.immutable.Set[Int]) = (Set(6),Set(5, 1, 2, 3, 4))
scala程序并不是一个解释器,实际上发生的是,你输入的内容被编译成字节码,交由java虚拟机执行
一行存在多条语句时需要用分号分号
scala> val aa=Array(1,2,3,4,"ddd");for(x<-aa)print(x)
1234ddd aa: Array[Any] = Array(1, 2, 3, 4, ddd)
多个变量或者值可以一起声明
scala> val aa,bb:Int=100
aa: Int = 100
bb: Int = 100
scala> 1.to(5).foreach(print _)
12345
scala> 1.to(5).foreach(print(_))
12345
scala> 1.to(5)
res24: scala.collection.immutable.Range.Inclusive = Range 1 to 5
scala> 1.to(5).foreach(print)
12345
scala> "hello".toCharArray.map(x=>(x,1)).toMap
res43: scala.collection.immutable.Map[Char,Int] = Map(h -> 1, e -> 1, l -> 1, o -> 1)
a.方法(b) 可以简写成 a 方法 b
scala> 1 to 10
res73: scala.collection.immutable.Range.Inclusive = Range 1 to 10
scala> 1.to(10)
res74: scala.collection.immutable.Range.Inclusive = Range 1 to 10
scala 没有提供++,--等 我们需要使用+=1或者-=1
一个类对应一个伴生对象,BigInt类有一个生成指定位数随机数的方法
scala> BigInt.probablePrime(100,scala.util.Random)
res97: scala.math.BigInt = 836126297418205382932817866499
scala> BigInt.probablePrime(5,scala.util.Random)
res98: scala.math.BigInt = 23
scala> BigInt.apply("7546465645645")
res146: scala.math.BigInt = 7546465645645
scala> BigInt("7546465645645") //将字符串转为BigInt
res147: scala.math.BigInt = 7546465645645
scala> "hello".apply(1)
res144: Char = e
scala> "hello"(1)
res145: Char = e
scala> "Hello".count(_.isUpper)
res153: Int = 1
def copyValueOf(x$1: Array[Char]): String
def copyValueOf(x$1: Array[Char],x$2: Int,x$3: Int): String
scala> String.copyValueOf(str.toCharArray)
res188: String = Hello
scala> String.copyValueOf(str.toCharArray,1,2)
res190: String = el
scala> Math.max(10,5)
res191: Int = 10
scala> 10 max 5
res192: Int = 10
scala> str.last
res198: Char = o
scala> str.tail
res199: String = ello
scala条件表达式有值
scala> val a=10
a: Int = 10
scala> val b=50
b: Int = 50
scala> if(a>b) 1 else 0
res215: Int = 0
可以将条件表达式的值赋给变量如下:
scala> val res=if(a>b) 1 else 0
res: Int = 0
没有输出值的情况下,引入了Unit类,写作(),()是无有用值的占位符,相当于c++的void
scala> val gg=if(a>b) 1
gg: AnyVal = ()
val gg=if(a>b) 1 相当于val gg=if(a>b) 1 else ()
如果想黏贴代码段的话输入
:paste
在scala中,除非一行有写下多个语句,每个语句用;分割,单个语句占一行 不必;
scala> var a,b=9
scala> b-=1
scala> b
res21: Int = 8
scala> while(b>0) {b-=1;print(b)}
76543210
块表达式与赋值
块语句就是包括在{}的语句序列,块最后一个表达式的值就是块的值
scala> var a,b,c=100
a: Int = 100
b: Int = 100
c: Int = 100
scala> var ss={a=3;b=5;c}
ss: Int = 100
scala> var ss={a=3;b=5;c=8} //最后一个是赋值语句所以返回了一个void值即()
ss: Unit = ()
scala> a=b=1 //由于b的值为(),不可能传递给a 因此报错
<console>:13: error: type mismatch;
found : Unit
required: Int
a=b=1
^
printf像C语言一样支持传递参数,如下:
scala> println("%s dlajfl %s dage %d","ddd","aaaa",100)
(%s dlajfl %s dage %d,ddd,aaaa,100)
scala> printf("%s dlajfl %s dage %d","ddd","aaaa",100)
ddd dlajfl aaaa dage 100
scala2.11版本后使用 readline需要导入import scala.io.StdIn._
scala> import scala.io.StdIn._
import scala.io.StdIn._
scala> val a=readLine("Enter your name:")
Enter your name:a: String = tianyongta
scala> a
res28: String = tianyongta
scala> val b=readInt()
b: Int = 88
scala> b
res29: Int = 88
循环语句
Scala 可以使用一个或多个 if 语句来过滤一些元素。
scala> for(i<- 1 to 10 if i%3==0) print(i)
369
scala循环语句中没有提供break,continue跳出循环
可以设置boolean型变量控制;嵌套函数里面return;使用break对应的beak方法
你可以以 变量<-表达式 的形势提供多个生成器,并用;分割
scala> for(i<- 1 to 3;j<- 1 to 3) print(i*10+j+" ")
11 12 13 21 22 23 31 32 33
每个生成器都可以有一个守卫用来过滤一些数据即 if,注意if之前不用;分割
scala> for(i<- 1 to 3 if i!=1;j<- 1 to 3 if j%2!=0) print(i*10+j+" ")
21 23 31 33
每次循环以yield开始,则会循环生成一个集合,每次迭代生成集合中的一个值
scala> for(c<-"hello";i<- 1 to 3) yield(c+i.toString)
res46: scala.collection.immutable.IndexedSeq[String] = Vector(h1, h2, h3, e1, e2, e3, l1, l2, l3, l1, l2, l3, o1, o2, o3)
scala> for(i<- 1 to 3) yield(i)
res47: scala.collection.immutable.IndexedSeq[Int] = Vector(1, 2, 3)
你也可以将生成器,守卫定义在花括号里面
scala> for{i<-1 to 3;from=i+1;j<-1 to from} print(i*10+j+" ")
11 12 21 22 23 31 32 33 34
函数
scala除了提供了方法以外还提供了函数;方法是对对象操作,函数则不然
定义函数 需要先定义 名称 参数 函数体
函数如果未定义返回值类型,会根据=后面的表达式类型来推断出返回值类型,最后一个表达式的值就是返回值
scala> def fac(n:Int)={var res=1; for(i<- 1 to n) res=res*i;res }
fac: (n: Int)Int
scala> fac(5)
res57: Int = 120
---------------
下面返回为void
scala> def fac(n:Int)={var res=1; for(i<- 1 to n) res=res*i }
fac: (n: Int)Unit
scala> fac(5)
递归函数必须制定返回值类型
scala> def fac(n:Int):Int={ if(n>1) n*fac(n-1) else n}
fac: (n: Int)Int
scala> fac(4)
res66: Int = 24
默认参数和带名参数
函数参数可以设置默认值,调用的时候,默认参数不赋值,则使用默认值
如果调用时参数带参数名进行调用,可以不需要和函数定义的参数顺序一致
scala> def catnam(f:String,s:String="yongtao")={f+s}
catnam: (f: String, s: String)String
scala> catnam("tian")
res68: String = tianyongtao
scala> catnam("tian","gege")
res69: String = tiangege
scala> catnam(s="bb",f="wang")
res70: String = wangbb
变长参数,值的序列或者数组什么的不能直接传入,如果想作为参数序列输入,则需要在后面添加 :_*
scala> def intsum(arr:Int*)={ var res=0;for(v<- arr) res+=v;res}
intsum: (arr: Int*)Int
scala> intsum(1,2,3,4,5,6)
res77: Int = 21
scala> val se1=Array(1,2,3,4,5,6)
se1: Array[Int] = Array(1, 2, 3, 4, 5, 6)
scala> intsum(se1)
<console>:18: error: type mismatch;
found : Array[Int]
required: Int
intsum(se1)
^
scala> intsum(se1:_*)
res89: Int = 21
scala> intsum(1 to 6:_*)
res90: Int = 21
没有返回值的函数称为过程,因为没有返回值,可以去掉=
scala> def sumnum(n:Int){var res=0; for(i<-1 to n) res+=i;println(res)}
sumnum: (n: Int)Unit
scala> sumnum(10)
55
如果val 变量被定义为lazy 时,它的初始化将被推迟,直到首次对它取值
懒值对于开销大的初始化来说比较有用;懒值的额外开销是,每次调用它的时候
都会有有一个方法以线程安全的方式检查是否该变量已经是否已经被初始化
scala> lazy val aa=100
aa: Int = <lazy>
scala> aa
res93: Int = 100
编写函数计算xn,其中n是整数,使用如下的递归定义:
- xn=y2,如果n是正偶数的话,这里的y=x(n/2)
- xn = x*x(n-1),如果n是正奇数的话
- x0 = 1
- xn = 1/x(-n),如果n是负数的话
不得使用return语句
scala> :paste
// Entering paste mode (ctrl-D to finish)
def mi(x:Int,n:Int):Double=
{
if(n==0)1
else if(n>0 && n%2==0) mi(x,n/2)*mi(x,n/2)
else if(n>0 && n%2==1) x*mi(x,n-1)
else 1/mi(x,-n)
}
// Exiting paste mode, now interpreting.
mi: (x: Int, n: Int)Double
scala> mi(2,-3)
res12: Double = 0.125
scala> mi(2,2)
res13: Double = 4.0
scala> mi(2,5)
res14: Double = 32.0
变长数组
scala> import scala.collection.mutable._
import scala.collection.mutable._
scala> val arrb=ArrayBuffer[Int]()
arrb: scala.collection.mutable.ArrayBuffer[Int] = ArrayBuffer()
scala> arrb+=1
res59: arrb.type = ArrayBuffer(1)
scala> arrb++=Array(2,3)
res60: arrb.type = ArrayBuffer(1, 2, 3)
scala> arrb-=1
res61: arrb.type = ArrayBuffer(2, 3)
scala> arrb++=Array(5,6,7,8)
res62: arrb.type = ArrayBuffer(2, 3, 5, 6, 7, 8)
scala> arrb--=Array(5,6)
res63: arrb.type = ArrayBuffer(2, 3, 7, 8)
scala> arrb.groupBy(_>5)
res69: scala.collection.immutable.Map[Boolean,scala.collection.mutable.ArrayBuffer[Int]] = Map(false -> ArrayBuffer(2, 3), true -> ArrayBuffer(7, 8))
scala> arrb
res66: scala.collection.mutable.ArrayBuffer[Int] = ArrayBuffer(2, 3, 7, 8)
scala> arrb.find(_%2==1)
res67: Option[Int] = Some(3)
scala> arrb.find(_%7==1)
res68: Option[Int] = Some(8)
scala> arrb.groupBy(_>5).toMap
res70: scala.collection.immutable.Map[Boolean,scala.collection.mutable.ArrayBuffer[Int]] = Map(false -> ArrayBuffer(2, 3), true -> ArrayBuffer(7, 8))
scala> arrb.takeWhile(_<5)
res75: scala.collection.mutable.ArrayBuffer[Int] = ArrayBuffer(2, 3)
scala> arrb
res77: scala.collection.mutable.ArrayBuffer[Int] = ArrayBuffer(2, 3, 7, 8)
scala> arrb.drop(2)
res78: scala.collection.mutable.ArrayBuffer[Int] = ArrayBuffer(7, 8)
scala> arrb
res79: scala.collection.mutable.ArrayBuffer[Int] = ArrayBuffer(2, 3, 7, 8)
scala> arrb.dropRight(2)
res80: scala.collection.mutable.ArrayBuffer[Int] = ArrayBuffer(2, 3)
scala> arrb
res93: scala.collection.mutable.ArrayBuffer[Int] = ArrayBuffer(2, 3, 8, 100, 52, 9, 60)
scala> arrb.remove(2,3)
scala> arrb
res95: scala.collection.mutable.ArrayBuffer[Int] = ArrayBuffer(2, 3, 9, 60)
scala> arrb.filter(_%2==0).map(x=>x*2)
res98: scala.collection.mutable.ArrayBuffer[Int] = ArrayBuffer(4, 120)
scala> for(item<-arrb if item%2==0) yield item*2
res99: scala.collection.mutable.ArrayBuffer[Int] = ArrayBuffer(4, 120)
scala> arrb.sortWith((a,b)=>a.compareTo(b)>0)
res110: scala.collection.mutable.ArrayBuffer[Int] = ArrayBuffer(60, 9, 9, 3, 2)
scala> arrb.sortWith((a,b)=>a.compareTo(b)<0)
res112: scala.collection.mutable.ArrayBuffer[Int] = ArrayBuffer(2, 3, 9, 9, 60)
scala> arrb.sortWith(_.compareTo(_)<0)
res114: scala.collection.mutable.ArrayBuffer[Int] = ArrayBuffer(2, 3, 9, 9, 60)
scala> arrb.map(x=>x+100)
res117: scala.collection.mutable.ArrayBuffer[Int] = ArrayBuffer(102, 103, 109, 160, 109)
scala> arrb.map(_+100)
res118: scala.collection.mutable.ArrayBuffer[Int] = ArrayBuffer(102, 103, 109, 160, 109)
scala> arrb.sortBy(a=>a*(-1))
res152: scala.collection.mutable.ArrayBuffer[Int] = ArrayBuffer(60, 9, 9, 3, 2)
scala> arrb.sorted
res153: scala.collection.mutable.ArrayBuffer[Int] = ArrayBuffer(2, 3, 9, 9, 60)
scala> val mm=arrb.clone
mm: scala.collection.mutable.ArrayBuffer[Int] = ArrayBuffer(2, 3, 9, 60, 9)
scala> val nn=mm
nn: scala.collection.mutable.ArrayBuffer[Int] = ArrayBuffer(2, 3, 9, 60, 9)
---------
scan[B >: A, That](z: B)(op: (B, B) ⇒ B)(implicit cbf: CanBuildFrom[List[A], B, That]): That
由一个初始值开始,从左向右,进行积累的op操作,这个比较难解释,具体的看例子吧。
scala> arrb
res180: scala.collection.mutable.ArrayBuffer[Int] = ArrayBuffer(2, 3, 9, 60, 9)
scala> arrb.scan(10)((a,b)=>a+b)
res178: scala.collection.mutable.ArrayBuffer[Int] = ArrayBuffer(10, 12, 15, 24, 84, 93)
scala> arrb.clear
scala> arrb
res182: scala.collection.mutable.ArrayBuffer[Int] = ArrayBuffer()
scala> arrb.append(100,500)
scala> arrb
res188: scala.collection.mutable.ArrayBuffer[Int] = ArrayBuffer(2, 3, 9, 60, 9, 100, 100, 500)
scala> arrb.withFilter(a=>a>60)
res222: scala.collection.generic.FilterMonadic[Int,scala.collection.mutable.ArrayBuffer[Int]] = scala.collection.TraversableLike$WithFilter@4a9d7735
scala> arrb.withFilter(a=>a>60).foreach(print(_))
100100500
scala> arrb.withFilter(a=>a>60).foreach(print)
100100500
scala> arrb.withFilter(_>60).foreach(print)
100100500
def addString(b: StringBuilder): StringBuilder
将数组中的元素逐个添加到b中
scala> arrb.map(a=>a+" ").addString(strb)
res241: StringBuilder = 2 3 9 60 9 100 100 500
def addString(b: StringBuilder, sep: String): StringBuilder
scala> arrb.map(a=>a+" ").addString(strb,",{")
res244: StringBuilder = 2 ,{3 ,{9 ,{60 ,{9 ,{100 ,{100 ,{500
def addString(b: StringBuilder, start: String, sep: String, end: String): StringBuilder
在首尾各加一个字符串,并指定sep分隔符
scala> arrb.map(a=>a+" ").addString(strb,"{",",","}")
res246: StringBuilder = {2 ,3 ,9 ,60 ,9 ,100 ,100 ,500 }
scala> arrb.apply(0)
res247: Int = 2
def canEqual(that: Any): Boolean
判断两个对象是否可以进行比较
def collect[B](pf: PartialFunction[A, B]): Array[B]
通过执行一个并行计算(偏函数),得到一个新的数组对象
scala> arrb.collect{case a:Int=>a+10}
res63: scala.collection.mutable.ArrayBuffer[Int] = ArrayBuffer(12, 13, 19, 80, 18, 16, 110)
scala> arrb.collectFirst{case a:Int=>a+10}
res64: Option[Int] = Some(12)
-----------------------
def combinations(n: Int): collection.Iterator[Array[T]]
排列组合,这个排列组合会选出所有包含字符不一样的组合,参数n表示序列长度,内容不能相同,顺序不一样也不行
scala> arrb.combinations(2)
res18: Iterator[scala.collection.mutable.ArrayBuffer[Int]] = non-empty iterator
scala> arrb.combinations(2).foreach(print) //会 产生arrb.size*(arrb.size-1)/(2*1)的组合
ArrayBuffer(1, 2)ArrayBuffer(1, 3)ArrayBuffer(1, 100)ArrayBuffer(1, 20)ArrayBuffer(1, 8)ArrayBuffer(1, 6)ArrayBuffer(2, 3)ArrayBuffer(2, 100)ArrayBuffer(2, 20)ArrayBuffer(2, 8)ArrayBuffer(2, 6)ArrayBuffer(3, 100)ArrayBuffer(3, 20)ArrayBuffer(3, 8)ArrayBuffer(3, 6)ArrayBuffer(100, 20)ArrayBuffer(100, 8)ArrayBuffer(100, 6)ArrayBuffer(20, 8)ArrayBuffer(20, 6)ArrayBuffer(8, 6)
def contains[A1 >: A](elem: A1): Boolean
scala> arrb.contains(200)
res20: Boolean = false
def containsSlice[B](that: GenSeq[B]): Boolean
判断当前序列中是否包含另一个序列,和顺序有关系
scala> arrb
res22: scala.collection.mutable.ArrayBuffer[Int] = ArrayBuffer(1, 2, 3, 100, 20, 8, 6)
scala> arrb.sorted.containsSlice(Array(3,2,1))
res26: Boolean = false
scala> arrb.sorted.containsSlice(Array(3,2,1).sorted)
res27: Boolean = true
scala> arrb.sorted.containsSlice(Array(8,20).sorted)
res28: Boolean = true
scala> val arr=Array[Int](10) //初始化了一个元素为10的数组
arr: Array[Int] = Array(10)
scala> val arr=new Array[Int](10)//定义了一个长度为10的数组
arr: Array[Int] = Array(0, 0, 0, 0, 0, 0, 0, 0, 0, 0)
copyToArray(xs: Array[A], start: Int, len: Int): Unit
scala> val arr=new Array[Int](10)
arr: Array[Int] = Array(0, 0, 0, 0, 0, 0, 0, 0, 0, 0)
scala> arrb.copyToArray(arr,1,2)
scala> arr
res70: Array[Int] = Array(0, 1, 2, 0, 0, 0, 0, 0, 0, 0)
scala> arrb.copyToArray(arr,0,2)
scala> arr
res72: Array[Int] = Array(1, 2, 2, 0, 0, 0, 0, 0, 0, 0)
def corresponds[B](that: GenSeq[B])(p: (T, B) ⇒ Boolean): Boolean //correspond [,kɔrə'spɑnd] 一致 对应
判断两个序列长度以及对应位置元素是否符合某个条件。
scala> val a=Array(1,2,3,4,5)
a: Array[Int] = Array(1, 2, 3, 4, 5)
scala> val b=Array(4,5,6,7,8)
b: Array[Int] = Array(4, 5, 6, 7, 8)
scala> a.corresponds(b)(_>_)
res74: Boolean = false
scala> a.corresponds(b)(_<_)
res75: Boolean = true
def count(p: (T) ⇒ Boolean): Int
统计符合条件的元素个数
scala> arrb.count(a=>a>10)
res100: Int = 2
scala> arrb.count(_>10)
res101: Int = 2
def drop(n: Int): Array[T]
将当前序列中前 n 个元素去除后,作为一个新序列返回,并非是从本序列中移除。
def dropWhile(p: (T) ⇒ Boolean): Array[T]
去除当前数组中符合条件的元素,碰到第一个不满足条件的元素结束.
res113: scala.collection.mutable.ArrayBuffer[Int] = ArrayBuffer(1, 2, 3, 100, 20, 8, 6)
scala> arrb.dropWhile(_<10)
res114: scala.collection.mutable.ArrayBuffer[Int] = ArrayBuffer(100, 20, 8, 6)
scala> arrb.sorted.dropWhile(_<10)
res117: scala.collection.mutable.ArrayBuffer[Int] = ArrayBuffer(20, 100)
scala> arrb
res5: scala.collection.mutable.ArrayBuffer[Int] = ArrayBuffer(1, 2, 3, 6, 100, 80, 6, 2, 70)
scala> arrb.endsWith(Array(2,70))
res6: Boolean = true
def exists(p: (T) ⇒ Boolean): Boolean
判断当前数组是否包含符合条件的元素
scala> arrb.exists(_%3==1)
res10: Boolean = true
scala> arrb.filter(_>10)
res13: scala.collection.mutable.ArrayBuffer[Int] = ArrayBuffer(100, 80, 70)
scala> arrb.filterNot(_>10)
res15: scala.collection.mutable.ArrayBuffer[Int] = ArrayBuffer(1, 2, 3, 6, 6, 2)
def flatMap[B](f: (A) ⇒ GenTraversableOnce[B]): Array[B]
对当前序列的每个元素进行操作,结果放入新序列返回,参数要求是GenTraversableOnce及其子类
scala> arrb.flatMap(x=>x.to(10))
res34: scala.collection.mutable.ArrayBuffer[Int] = ArrayBuffer(1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 2, 3, 4, 5, 6, 7, 8, 9, 10, 3, 4, 5, 6, 7, 8, 9, 10, 6, 7, 8, 9, 10, 6, 7, 8, 9, 10, 2, 3, 4, 5, 6, 7, 8, 9, 10)
def flatten[U](implicit asTrav: scala.collection.mutable.ArrayBuffer[Int] => Traversable[U],implicit m: scala.reflect.ClassTag[U]): Array[U]
将二维数组的所有元素联合在一起,形成一个一维数组返回
scala> :paste
// Entering paste mode (ctrl-D to finish)
var index = new Array[ArrayBuffer[Int]](3)
for(i <- 0 until index.length){
index(i) = new ArrayBuffer[Int]()
}
// Exiting paste mode, now interpreting.
index: Array[scala.collection.mutable.ArrayBuffer[Int]] = Array(ArrayBuffer(), ArrayBuffer(), ArrayBuffer())
scala>
scala> index(0)+=(1,2,3,4,5)
res76: scala.collection.mutable.ArrayBuffer[Int] = ArrayBuffer(1, 2, 3, 4, 5)
scala> index(1)+=(2,3,6,7,8)
res77: scala.collection.mutable.ArrayBuffer[Int] = ArrayBuffer(2, 3, 6, 7, 8)
scala> index(2)+=(2,3,6,7,8)
res78: scala.collection.mutable.ArrayBuffer[Int] = ArrayBuffer(2, 3, 6, 7, 8)
scala> index
res79: Array[scala.collection.mutable.ArrayBuffer[Int]] = Array(ArrayBuffer(1, 2, 3, 4, 5), ArrayBuffer(2, 3, 6, 7, 8), ArrayBuffer(2, 3, 6, 7, 8))
scala> index.flatten
res83: Array[Int] = Array(1, 2, 3, 4, 5, 2, 3, 6, 7, 8, 2, 3, 6, 7, 8)
def fold[A1 >: Int](z: A1)(op: (A1, A1) => A1): A1
对序列中的每个元素进行二元运算 fold 折叠
scala> arrb.fold(5)((a,b)=>a+b)
res86: Int = 275
scala> arrb.fold(0)((a,b)=>a+b)
res87: Int = 270
scala> arrb.sum
res88: Int = 270
------------------------------
scala> arrb.foldLeft(5)((a,b)=>a+b)
res109: Int = 275
同
scala> (5/:arrb)(_+_)
res108: Int = 275
------------------------
scala> arrb.foldRight(5)((a,b)=>a+b)
res110: Int = 275
同
scala> (arrb:5)(_+_)
res107: Int = 275
def aggregate[B](z: => B)(seqop: (B, Int) => B,combop: (B, B) => B): B
scala> arrb.aggregate(5)((a,b)=>a+b,(m,n)=>m+n)
res89: Int = 275
scala> arrb.aggregate(5)((a,b)=>a+b,(m,n)=>m+n)
res90: Int = 275
def forall(p: (T) ⇒ Boolean): Boolean
检测序列中的元素是否都满足条件 p,如果序列为空,返回true
scala> arrb.forall(_.isValidInt)
res112: Boolean = true
scala> arrb.forall(_>10)
res113: Boolean = false
override def foreach[U](f: Int => U): Unit
遍历序列中的元素,进行 f 操作
scala> arrb.foreach(print _)
1236100806270
def groupBy[K](f: Int => K): scala.collection.immutable.Map[K,scala.collection.mutable.ArrayBuffer[Int]]
按条件f分组,返回一个Map类型
scala> arrb.groupBy(_>10)
res126: scala.collection.immutable.Map[Boolean,scala.collection.mutable.ArrayBuffer[Int]] = Map(false -> ArrayBuffer(1, 2, 3, 6, 6, 2), true -> ArrayBuffer(100, 80, 70))
def grouped(size: Int): Iterator[scala.collection.mutable.ArrayBuffer[Int]]
按数量进行分组
scala> arrb.grouped(5).toList
res142: List[scala.collection.mutable.ArrayBuffer[Int]] = List(ArrayBuffer(1, 2, 3, 6, 100), ArrayBuffer(80, 6, 2, 70))
scala> arrb.grouped(5).toSet
res149: scala.collection.immutable.Set[scala.collection.mutable.ArrayBuffer[Int]] = Set(ArrayBuffer(1, 2, 3, 6, 100), ArrayBuffer(80, 6, 2, 70))
scala> val ll=arrb.grouped(5).toArray
ll: Array[scala.collection.mutable.ArrayBuffer[Int]] = Array(ArrayBuffer(1, 2, 3, 6, 100), ArrayBuffer(80, 6, 2, 70))
scala> ll.foreach((x)=>println("line "+ll.indexOf(x)+":"+x.mkString(",")))
line 0:1,2,3,6,100
line 1:80,6,2,70
def hasDefiniteSize: Boolean
长度是否有限,Stream流数据会返回false Definite:有限的
scala> arrb.hasDefiniteSize
res175: Boolean = true
scala> ll.hasDefiniteSize
res176: Boolean = true
def headOption: Option[Int] 选项
返回Option类型对象,就是scala.Some 或者 None,如果序列是空,返回None
scala> arrb.headOption
res179: Option[Int] = Some(1)
def indexOf[B >: Int](elem: B,from: Int): Int
def indexOf[B >: Int](elem: B): Int
返回B第一个出现的索引,from查找的起始位置
scala> arrb.indexOf(100)
res181: Int = 4
scala> arrb.indexOf(100,6)
res182: Int = -1
def indexOfSlice[B >: Int](that: scala.collection.GenSeq[B],from: Int): Int
def indexOfSlice[B >: Int](that: scala.collection.GenSeq[B]): Int
同indexOf,返回第一个元素出现的索引位置 Slice片 薄片
scala> arrb
res184: scala.collection.mutable.ArrayBuffer[Int] = ArrayBuffer(1, 2, 3, 6, 100, 80, 6, 2, 70)
scala> arrb.indexOfSlice(Array(100,80))
res185: Int = 4
scala> arrb.indexOfSlice(Array(100,90))
res186: Int = -1
override def indexWhere(p: Int => Boolean,from: Int): Int
def indexWhere(p: Int => Boolean): Int
返回第一个满足满足条件的元素的索引
scala> arrb.indexWhere(_>55)
res189: Int = 4
scala> arrb.indexWhere(_>55,5)
res191: Int = 5
def indices: scala.collection.immutable.Range
返回索引范围 indices ['ɪndɪsiz] 索引
scala> arrb.filter(_<10).indices
res198: scala.collection.immutable.Range = Range 0 until 6
scala> arrb.indices
res199: scala.collection.immutable.Range = Range 0 until 9
init 返回不包括最后一个元素的数组
scala> arrb.init
res200: scala.collection.mutable.ArrayBuffer[Int] = ArrayBuffer(1, 2, 3, 6, 100, 80, 6, 2)
scala> arrb
res201: scala.collection.mutable.ArrayBuffer[Int] = ArrayBuffer(1, 2, 3, 6, 100, 80, 6, 2, 70)
def inits: Iterator[scala.collection.mutable.ArrayBuffer[Int]]
对数组进行init操作,第一值是当前数组的克隆,然后每个值都是上一个值的init操作,最后一个值为空
scala> arrb.inits.toArray.foreach(println)
ArrayBuffer(1, 2, 3, 5, 8, 80, 60, 8, 16, 90)
ArrayBuffer(1, 2, 3, 5, 8, 80, 60, 8, 16)
ArrayBuffer(1, 2, 3, 5, 8, 80, 60, 8)
ArrayBuffer(1, 2, 3, 5, 8, 80, 60)
ArrayBuffer(1, 2, 3, 5, 8, 80)
ArrayBuffer(1, 2, 3, 5, 8)
ArrayBuffer(1, 2, 3, 5)
ArrayBuffer(1, 2, 3)
ArrayBuffer(1, 2)
ArrayBuffer(1)
ArrayBuffer()
scala> val jj=arrb.inits
jj: Iterator[scala.collection.mutable.ArrayBuffer[Int]] = non-empty iterator
scala> jj.size
res304: Int = 11
scala> jj.size //迭代器执行一次就没了,不能重复使用
res305: Int = 0
intersect 两个集合的交集
scala> arrb.intersect(Array(8,900,3,50,70,60,16))
res10: scala.collection.mutable.ArrayBuffer[Int] = ArrayBuffer(3, 8, 60, 16)
isDefinedAt 判断某个索引值是否存在 /Define 确定 已定义
scala> arrb.isDefinedAt(10)
res12: Boolean = false
scala> arrb.isDefinedAt(6)
res13: Boolean = true
override def isEmpty: Boolean
scala> arrb.isEmpty
res14: Boolean = false
final def isTraversableAgain: Boolean
判断序列是否可以反复遍历,该方法是GenTraversableOnce中的方法,
对于 Traversables 一般返回true,对于 Iterators 返回 false,除非被复写
scala> arrb.isTraversableAgain
res15: Boolean = true
def iterator: collection.Iterator[T]
对序列中的每个元素产生一个 iterator
scala> arrb.iterator
override def iterator: Iterator[Int]
scala> arrb.toIterator
override def toIterator: Iterator[Int]
scala> arrb
res1: scala.collection.mutable.ArrayBuffer[Int] = ArrayBuffer(1, 2, 3, 5, 8, 80, 60, 8, 16, 90)
scala> arrb.last
res3: Int = 90
def lastIndexOf(elem: T): Int
def lastIndexOf(elem: T, end: Int): Int //取得序列中最后一个等于 elem 的元素的位置,可以指定在 end 之前(包括)的元素中查找
scala> arrb.lastIndexOf(8) //最后一次出现某个元素的位置
res4: Int = 7
scala> arrb.lastIndexOf(8,6)
res6: Int = 4
def lastIndexOfSlice[B >: A](that: GenSeq[B]): Int
def lastIndexOfSlice[B >: A](that: GenSeq[B], end: Int): Int
同lastIndexOf
def lastIndexWhere(p: (T) ⇒ Boolean): Int
返回当前序列中最后一个满足条件 p 的元素的索引
scala> arrb.lastIndexWhere(_>80)
res8: Int = 9
def lastIndexWhere(p: (T) ⇒ Boolean, end: Int): Int
同上
scala> arrb.lastOption // 返回当前序列中最后一个对象
res9: Option[Int] = Some(90)
scala> arrb.length
res10: Int = 10
override def lengthCompare(len: Int): Int
比较序列的长度和参数 len
scala> arrb.lengthCompare(10)
res14: Int = 0
scala> arrb.lengthCompare(11)
res15: Int = -1
scala> arrb.lengthCompare(8)
res16: Int = 2
def map[B, That](f: Int => B)(implicit bf: scala.collection.generic.CanBuildFrom[scala.collection.mutable.ArrayBuffer[Int],B,That]): That
def map[B](f: Int => B): scala.collection.TraversableOnce[B]
对序列中的元素进行 f 操作
scala> arrb.map(x=>x+1)
res17: scala.collection.mutable.ArrayBuffer[Int] = ArrayBuffer(2, 3, 4, 6, 9, 81, 61, 9, 17, 91)
scala> arrb.map(x=>(x,1))
res18: scala.collection.mutable.ArrayBuffer[(Int, Int)] = ArrayBuffer((1,1), (2,1), (3,1), (5,1), (8,1), (80,1), (60,1), (8,1), (16,1), (90,1))
scala> arrb.max
res19: Int = 90
def maxBy[B](f: Int => B)(implicit cmp: Ordering[B]): Int
返回序列中第一个符合条件的元素
scala> arrb.maxBy(_>10)
res21: Int = 80
scala> arrb
res22: scala.collection.mutable.ArrayBuffer[Int] = ArrayBuffer(1, 2, 3, 5, 8, 80, 60, 8, 16, 90)
mkString将所有元素组合成一个字符串
scala> arrb.mkString
res27: String = 12358806081690
scala> arrb.mkString("*")
res28: String = 1*2*3*5*8*80*60*8*16*90
def mkString(start: String, sep: String, end: String): String
scala> arrb.mkString("{","*","}")
res31: String = {1*2*3*5*8*80*60*8*16*90}
scala> arrb.nonEmpty
res32: Boolean = true
def padTo[B >: Int, That](len: Int,elem: B)(implicit bf: scala.collection.generic.CanBuildFrom[scala.collection.mutable.ArrayBuffer[Int],B,That]): That
后补齐序列,如果当前序列长度小于 len,那么新产生的序列长度是 len,多出的几个位值填充 elem,如果当前序列大于等于 len ,则返回当前序列
scala> arrb.padTo(15,20) //pad 填补
res34: scala.collection.mutable.ArrayBuffer[Int] = ArrayBuffer(1, 2, 3, 5, 8, 80, 60, 8, 16, 90, 20, 20, 20, 20, 20)
override def par: scala.collection.parallel.mutable.ParArray[Int]
返回一个并行序列
scala> arrb.par
res35: scala.collection.parallel.mutable.ParArray[Int] = ParArray(1, 2, 3, 5, 8, 80, 60, 8, 16, 90)
def partition(p: Int => Boolean): (scala.collection.mutable.ArrayBuffer[Int], scala.collection.mutable.ArrayBuffer[Int])
按条件生成两个序列
scala> arrb.partition(_>5)
res37: (scala.collection.mutable.ArrayBuffer[Int], scala.collection.mutable.ArrayBuffer[Int]) = (ArrayBuffer(8, 80, 60, 8, 16, 90),ArrayBuffer(1, 2, 3, 5))
scala> arrb.partition(_>5).
_1 _2 canEqual copy equals hashCode invert productArity productElement productIterator productPrefix swap toString zipped
scala> arrb.partition(_>5)._1
res40: scala.collection.mutable.ArrayBuffer[Int] = ArrayBuffer(8, 80, 60, 8, 16, 90)
scala> arrb.partition(_>5)._2
res41: scala.collection.mutable.ArrayBuffer[Int] = ArrayBuffer(1, 2, 3, 5)
Set是集合,不含重复元素,元素顺序不定 ,因此没有indexOf方法
def patch[B >: Int, That](from: Int,patch: scala.collection.GenSeq[B],replaced: Int)(implicit bf: scala.collection.generic.CanBuildFrom[scala.collection.mutable.ArrayBuffer[Int],B,That]): That
批量替换,从原序列的 from 处开始,后面的 replaced 数量个元素,将被替换成序列 patch //补丁,打补丁,修补
scala> arrb.patch(5,Array(100,200,150,5,5,3),8)
res36: scala.collection.mutable.ArrayBuffer[Int] = ArrayBuffer(1, 2, 3, 5, 8, 100, 200, 150, 5, 5, 3)
def permutations: Iterator[Array[Int]]
排列组合,内容可以相同,顺序必须不同。 permutation ['pɝmjʊ'teʃən] 排列,排序
scala> Array(1,2,3,4).permutations.size //数组有四个元素 会有4*3*2*1=24种组合
res50: Int = 24
scala> Array(1,2,3,4).combinations(4).toList //四个元素的组合只有1种,因为内容不能相同
res54: List[Array[Int]] = List(Array(1, 2, 3, 4))
def prefixLength(p: Int => Boolean): Int
返回数列前部满足条件P的长度直到不满足止,后面再有满足条件的不会再做统计
scala> arrb
res101: scala.collection.mutable.ArrayBuffer[Int] = ArrayBuffer(1, 2, 3, 5, 8, 80, 60, 8, 16, 90)
scala> arrb.prefixLength(_>5) //因为首个元素为1,小余5
res102: Int = 0
scala> arrb.prefixLength(_<5)
res103: Int = 3
scala> Array(1,2,3,4,5).product //返回所欲元素的乘积
res108: Int = 120
def reduce[A1 >: Int](op: (A1, A1) => A1): A1
操作同fold,没有初始值
def fold[A1 >: Int](z: A1)(op: (A1, A1) => A1): A1
scala> Array(1,2,3,4,5).reduce((a,b)=>a+b)
res109: Int = 15
scala> Array(1,2,3,4,5).fold(0)((a,b)=>a+b)
res111: Int = 15
scala> Array(1,2,3,4,5).reduceLeftOption((x,y)=>x+y)
res114: Option[Int] = Some(15)
scala> Array(1,2,3,4,5).reduceRightOption((x,y)=>x+y)
res115: Option[Int] = Some(15)
scala> arrb
res384: scala.collection.mutable.ArrayBuffer[Int] = ArrayBuffer(1000, 2000, 100, 55, -8, -60, 88, -90, 200, 300, 1, 2, 3, 5, 8, 80, 60, 8, 16, 90)
scala> arrb.aggregate(0)((a,b)=>a+b,(p1,p2)=>p1+p2)
res379: Int = 3858
scala> arrb.reduce((a,b)=>a+b)
res380: Int = 3858
scala> arrb.reduce(_+_)
res381: Int = 3858
scala> arrb.reduce(_+_)
res382: Int = 3858
scala> arrb.reduce((a,b)=>a+b)
res383: Int = 3858
scala> Array(1,2,3,4,5).reverse
res117: Array[Int] = Array(5, 4, 3, 2, 1)
scala> Array(1,2,3,4,5).map(_+10)
res118: Array[Int] = Array(11, 12, 13, 14, 15)
scala> Array(1,2,3,4,5).reverseMap(_+10)
res119: Array[Int] = Array(15, 14, 13, 12, 11)
override def sameElements[B >: Int](that: scala.collection.GenIterable[B]): Boolean
判断两个序列是否顺序和对应位置上的元素都一样
scala> Array(1,2,3,4,5).sameElements(Array(1,2,3))
res121: Boolean = false
scala> Array(1,2,3,4,5).sameElements(Array(1,2,3,4,6))
res122: Boolean = false
scala> Array(1,2,3,4,5).sameElements(Array(1,2,3,4,5))
res123: Boolean = true
def scan[B >: Int, That](z: B)(op: (B, B) => B)(implicit cbf: scala.collection.generic.CanBuildFrom[Array[Int],B,That]): That
def scan[B >: Int, That](z: B)(op: (B, B) => B)(implicit cbf: scala.collection.generic.CanBuildFrom[scala.collection.mutable.WrappedArray[Int],B,That]): That
同fold,但每次计算都会返回一个结果,而fold只返回一个最终的结果
scala> Array(1,2,3,4,5).scan(5)(_+_)
res124: Array[Int] = Array(5, 6, 8, 11, 15, 20)
scala> Array(1,2,3,4,5).scan(0)(_+_)
res125: Array[Int] = Array(0, 1, 3, 6, 10, 15)
scala> Array(1,2,3,4,5).fold(5)(_+_)
res126: Int = 20
scala> Array(1,2,3,4,5).scan(5)(_+_)
res131: Array[Int] = Array(5, 6, 8, 11, 15, 20)
scala> Array(1,2,3,4,5).scanLeft(5)(_+_)
res132: Array[Int] = Array(5, 6, 8, 11, 15, 20)
scala> Array(1,2,3,4,5).scanRight(5)(_+_)
res133: Array[Int] = Array(20, 19, 17, 14, 10, 5)
def split(x$1: String,x$2: Int): Array[String]
def split(separator: Char): Array[String]
def split(x$1: String): Array[String]
def split(separators: Array[Char]): Array[String]
将字符串以字符或者字符集合为分割符,转换为数组
scala> val strarr=arrb.mkString("#")
strarr: String = 1000#2000#100#55#-8#-60#88#-90#200#300#1#2#3#5#8#80#60#8#16#90
scala> strarr.split("#")
res420: Array[String] = Array(1000, 2000, 100, 55, -8, -60, 88, -90, 200, 300, 1, 2, 3, 5, 8, 80, 60, 8, 16, 90)
scala> strarr.split("#",3)
res423: Array[String] = Array(1000, 2000, 100#55#-8#-60#88#-90#200#300#1#2#3#5#8#80#60#8#16#90)
scala> strarr.split("#",4)
res424: Array[String] = Array(1000, 2000, 100, 55#-8#-60#88#-90#200#300#1#2#3#5#8#80#60#8#16#90)
scala> val sss="tianyongtao,100;man,3:300"
sss: String = tianyongtao,100;man,3:300
scala> sss.split(Array(',',';',':'))
res426: Array[String] = Array(tianyongtao, 100, man, 3, 300)
override def segmentLength(p: Int => Boolean,from: Int): Int
从from位置开始查找满足连续P条件的元素长度 (segment 段 部分 分割)
scala> arrb
res134: scala.collection.mutable.ArrayBuffer[Int] = ArrayBuffer(1, 2, 3, 5, 8, 80, 60, 8, 16, 90)
scala> arrb.segmentLength(_>5,2)
res137: Int = 0
scala> arrb.segmentLength(_>5,4)
res138: Int = 6
scala> arrb.segmentLength(_<50,4)
res139: Int = 1
scala> arrb.segmentLength(_<50,5)
res140: Int = 0
scala> arrb.segmentLength(_>50,5)
res141: Int = 2
override def seq: scala.collection.mutable.IndexedSeq[Int]
生成一个引用当前序列的 sequential 视图
scala> arrb.seq
res160: scala.collection.mutable.IndexedSeq[Int] = ArrayBuffer(1, 2, 3, 5, 8, 80, 60, 8, 16, 90)
scala> arrb.size
res161: Int = 10
scala> arrb.slice
override def slice(from: Int,until: Int): scala.collection.mutable.ArrayBuffer[Int]
从from到until获取片段
scala> arrb.slice(2,3)
res7: scala.collection.mutable.ArrayBuffer[Int] = ArrayBuffer(3)
scala> arrb.slice(2,5)
res8: scala.collection.mutable.ArrayBuffer[Int] = ArrayBuffer(3, 5, 8)
def sliding(size: Int,step: Int): Iterator[Array[Int]] def sliding(size: Int): Iterator[Array[Int]]
从第一个元素开始,每个元素和它后面的 size - 1 个元素组成一个数组,最终组成一个新的集合返回,当剩余元素不够 size 数,则停止
设置步进 step,第一个元素组合完后,下一个从 上一个元素位置+step后的位置处的元素开始
scala> Array(1,2,3,4,5).sliding(3).toList
res21: List[Array[Int]] = List(Array(1, 2, 3), Array(2, 3, 4), Array(3, 4, 5))
scala> Array(1,2,3,4,5).sliding(3,2).toList
res22: List[Array[Int]] = List(Array(1, 2, 3), Array(3, 4, 5))
def sortBy[B](f: (T) ⇒ B)(implicit ord: math.Ordering[B]): Array[T]
按指定的排序规则排序
scala> arrb.sortBy(_*(-1))
res33: scala.collection.mutable.ArrayBuffer[Int] = ArrayBuffer(90, 80, 60, 16, 8, 8, 5, 3, 2, 1)
scala> arrb.sortBy(x=>x)
res34: scala.collection.mutable.ArrayBuffer[Int] = ArrayBuffer(1, 2, 3, 5, 8, 8, 16, 60, 80, 90)
def sortWith(lt: (T, T) ⇒ Boolean): Array[T]
自定义排序方法 lt
scala> arrb.sortWith{case(a,b)=>a>b}
res458: scala.collection.mutable.ArrayBuffer[Int] = ArrayBuffer(2000, 1000, 300, 200, 100, 90, 88, 80, 60, 55, 16, 8, 8, 5, 3, 2, 1, -8, -60, -90)
scala> arrb.sortWith{case(a,b)=>a<b}
res459: scala.collection.mutable.ArrayBuffer[Int] = ArrayBuffer(-90, -60, -8, 1, 2, 3, 5, 8, 8, 16, 55, 60, 80, 88, 90, 100, 200, 300, 1000, 2000)
scala> arrb.sortWith(_<_)
res460: scala.collection.mutable.ArrayBuffer[Int] = ArrayBuffer(-90, -60, -8, 1, 2, 3, 5, 8, 8, 16, 55, 60, 80, 88, 90, 100, 200, 300, 1000, 2000)
def sorted[B >: Int](implicit ord: scala.math.Ordering[B]): scala.collection.mutable.ArrayBuffer[Int]
使用默认的排序规则对序列排序
scala> arrb.sorted
res39: scala.collection.mutable.ArrayBuffer[Int] = ArrayBuffer(1, 2, 3, 5, 8, 8, 16, 60, 80, 90)
scala> arrb.span
override def span(p: Int => Boolean): (scala.collection.mutable.ArrayBuffer[Int], scala.collection.mutable.ArrayBuffer[Int])
分割序列为两个集合,从第一个元素开始,直到找到第一个不满足条件的元素止,之前的元素放到第一个集合,其它的放到第二个集合
scala> arrb.span(_<10)
res46: (scala.collection.mutable.ArrayBuffer[Int], scala.collection.mutable.ArrayBuffer[Int]) = (ArrayBuffer(1, 2, 3, 5, 8),ArrayBuffer(80, 60, 8, 16, 90))
scala> arrb.partition
def partition(p: Int => Boolean): (scala.collection.mutable.ArrayBuffer[Int], scala.collection.mutable.ArrayBuffer[Int])
scala> arrb.partition(_<10)
res47: (scala.collection.mutable.ArrayBuffer[Int], scala.collection.mutable.ArrayBuffer[Int]) = (ArrayBuffer(1, 2, 3, 5, 8, 8),ArrayBuffer(80, 60, 16, 90))
override def splitAt(n: Int): (scala.collection.mutable.ArrayBuffer[Int], scala.collection.mutable.ArrayBuffer[Int])
从指定位置开始,把序列拆分成两个集合
scala> arrb.splitAt(5)
res48: (scala.collection.mutable.ArrayBuffer[Int], scala.collection.mutable.ArrayBuffer[Int]) = (ArrayBuffer(1, 2, 3, 5, 8),ArrayBuffer(80, 60, 8, 16, 90))
scala> arrb.splitAt(4)
res49: (scala.collection.mutable.ArrayBuffer[Int], scala.collection.mutable.ArrayBuffer[Int]) = (ArrayBuffer(1, 2, 3, 5),ArrayBuffer(8, 80, 60, 8, 16, 90))
override def startsWith[B](that: scala.collection.GenSeq[B],offset: Int): Boolean
def startsWith[B](that: scala.collection.GenSeq[B]): Boolean
scala> arrb
res56: scala.collection.mutable.ArrayBuffer[Int] = ArrayBuffer(1, 2, 3, 5, 8, 80, 60, 8, 16, 90)
scala> arrb.startsWith(Array(1,2,3),1)
res57: Boolean = false
scala> arrb.startsWith(Array(1,2,3),0)
res58: Boolean = true
scala> arrb.startsWith(Array(2,3,5),1)
res59: Boolean = true
scala> arrb.startsWith(Array(1,2,3))
res60: Boolean = true
scala> arrb.startsWith(Array(2,3))
res61: Boolean = false
override def toString(): String
ArrayBuffer返回前缀
scala> arrb.stringPrefix
res96: String = ArrayBuffer
def toString(): String
Array返回 toString 结果的前缀
scala> var gg=Array(1,2,3)
gg: Array[Int] = Array(1, 2, 3)
scala> gg.stringPrefix
res81: String = [I
scala> gg.toString
res95: String = [I@7f662e15
def subSequence(start: Int,end: Int): CharSequence
返回字符队列
scala> val gs=Array('a','b','c','M','o','g','a')
gs: Array[Char] = Array(a, b, c, M, o, g, a)
scala> gs.subSequence(2,3)
res99: CharSequence = c
scala> gs.subSequence(2,5)
res100: CharSequence = cMo
scala> arrb.sum
res111: Int = 273
scala> arrb.take(4)
res112: scala.collection.mutable.ArrayBuffer[Int] = ArrayBuffer(1, 2, 3, 5)
scala> arrb.takeRight(4)
res119: scala.collection.mutable.ArrayBuffer[Int] = ArrayBuffer(60, 8, 16, 90)
scala> arrb.tail
res113: scala.collection.mutable.ArrayBuffer[Int] = ArrayBuffer(2, 3, 5, 8, 80, 60, 8, 16, 90)
scala> arrb.tails
res114: Iterator[scala.collection.mutable.ArrayBuffer[Int]] = non-empty iterator
scala> arrb.tails.size
res115: Int = 11
scala> arrb.tails.toArray
res116: Array[scala.collection.mutable.ArrayBuffer[Int]] = Array(ArrayBuffer(1, 2, 3, 5, 8, 80, 60, 8, 16, 90), ArrayBuffer(2, 3, 5, 8, 80, 60, 8, 16, 90), ArrayBuffer(3, 5, 8, 80, 60, 8, 16, 90), ArrayBuffer(5, 8, 80, 60, 8, 16, 90), ArrayBuffer(8, 80, 60, 8, 16, 90), ArrayBuffer(80, 60, 8, 16, 90), ArrayBuffer(60, 8, 16, 90), ArrayBuffer(8, 16, 90), ArrayBuffer(16, 90), ArrayBuffer(90), ArrayBuffer())
scala> Array(1,2,3,4,5).tails.toList
res485: List[Array[Int]] = List(Array(1, 2, 3, 4, 5), Array(2, 3, 4, 5), Array(3, 4, 5), Array(4, 5), Array(5), Array())
override def takeWhile(p: Int => Boolean): scala.collection.mutable.ArrayBuffer[Int]
返回当前序列中,从第一个元素开始,满足条件的连续元素组成的序列
scala> arrb.takeWhile(_<10)
res122: scala.collection.mutable.ArrayBuffer[Int] = ArrayBuffer(1, 2, 3, 5, 8)
scala> arrb.takeWhile(_>3)
res123: scala.collection.mutable.ArrayBuffer[Int] = ArrayBuffer()
scala> gg
res128: Array[Int] = Array(1, 2, 3)
scala> gg.toBuffer
res129: scala.collection.mutable.Buffer[Int] = ArrayBuffer(1, 2, 3)
def toIndexedSeq: scala.collection.immutable.IndexedSeq[Int]
scala> arrb.toIndexedSeq
res130: scala.collection.immutable.IndexedSeq[Int] = Vector(1, 2, 3, 5, 8, 80, 60, 8, 16, 90)
scala> arrb.toIndexedSeq(1)
res131: Int = 2
scala> val hh=arrb.toIterator
hh: Iterator[Int] = non-empty iterator
scala> hh
res148: Iterator[Int] = non-empty iterator
scala> hh.foreach(print)
12358806081690
scala> arrb.toIterable
res151: Iterable[Int] = ArrayBuffer(1, 2, 3, 5, 8, 80, 60, 8, 16, 90)
scala> arrb
res152: scala.collection.mutable.ArrayBuffer[Int] = ArrayBuffer(1, 2, 3, 5, 8, 80, 60, 8, 16, 90)
scala> arrb.toIterable
override def toIterable: Iterable[Int]
scala> gg
res153: Array[Int] = Array(1, 2, 3)
scala> gg.toList
res154: List[Int] = List(1, 2, 3)
scala> gg.map((_,1))
res156: Array[(Int, Int)] = Array((1,1), (2,1), (3,1))
scala> gg.map((_,1)).toMap
res157: scala.collection.immutable.Map[Int,Int] = Map(1 -> 1, 2 -> 1, 3 -> 1)
scala> gg.toStream
res165: scala.collection.immutable.Stream[Int] = Stream(1, ?)
scala> gg.toStream(1)
res166: Int = 2
scala> gg.toVector
res169: Vector[Int] = Vector(1, 2, 3)
def transpose[U](implicit asArray: Array[Int] => Array[U]): Array[Array[U]]
def transpose[B](implicit asTraversable: Array[Int] => scala.collection.GenTraversableOnce[B]): scala.collection.mutable.IndexedSeq[scala.collection.mutable.IndexedSeq[B]]
矩阵转换,二维数组行列转换
scala> val vv=Array(Array(1,2,3),Array(4,5,6))
vv: Array[Array[Int]] = Array(Array(1, 2, 3), Array(4, 5, 6))
scala> vv.transpose
res172: Array[Array[Int]] = Array(Array(1, 4), Array(2, 5), Array(3, 6))
scala> vv
res176: Array[Array[Int]] = Array(Array(1, 2, 3), Array(4, 5, 6))
scala> gg
res177: Array[Int] = Array(1, 2, 3)
scala> vv.union(gg)
res178: Array[Any] = Array(Array(1, 2, 3), Array(4, 5, 6), 1, 2, 3)
scala> vv.map(x=>(x,1))
res188: Array[(Array[Int], Int)] = Array((Array(1, 2, 3),1), (Array(4, 5, 6),1))
-------------------------------------- zip 拉链
scala> val ff=Array(1,2,3,4,5,6)
ff: Array[Int] = Array(1, 2, 3, 4, 5, 6)
scala> val gg=Array(6,7,8,9,10,11)
gg: Array[Int] = Array(6, 7, 8, 9, 10, 11)
scala> ff.zip(gg)
res498: Array[(Int, Int)] = Array((1,6), (2,7), (3,8), (4,9), (5,10), (6,11))
scala> ff.zip(gg).unzip
res500: (Array[Int], Array[Int]) = (Array(1, 2, 3, 4, 5, 6),Array(6, 7, 8, 9, 10, 11))
def unzip[T1, T2](implicit asPair: ((Array[Int], Int)) => (T1, T2),implicit ct1: scala.reflect.ClassTag[T1],implicit ct2: scala.reflect.ClassTag[T2]): (Array[T1], Array[T2])
def unzip[A1, A2](implicit asPair: ((Array[Int], Int)) => (A1, A2)): (scala.collection.mutable.IndexedSeq[A1], scala.collection.mutable.IndexedSeq[A2])
将含有两个元素的数组,第一个元素取出组成一个序列,第二个元素组成一个序列
scala> vv.map(x=>(x,1)).unzip
res189: (Array[Array[Int]], Array[Int]) = (Array(Array(1, 2, 3), Array(4, 5, 6)),Array(1, 1))
scala> vv.map(x=>(x,1)).unzip._1
res192: Array[Array[Int]] = Array(Array(1, 2, 3), Array(4, 5, 6))
scala> vv.map(x=>(x,1)).unzip._2
res193: Array[Int] = Array(1, 1)
scala> val cc=Array((1,2,3),(4,5,6))
cc: Array[(Int, Int, Int)] = Array((1,2,3), (4,5,6))
def unzip3[T1, T2, T3](implicit asTriple: (T) ⇒ (T1, T2, T3), ct1: ClassTag[T1], ct2: ClassTag[T2], ct3: ClassTag[T3]): (Array[T1], Array[T2], Array[T3])
将含有三个元素的三个数组,第一个元素取出组成一个序列,第二个元素组成一个序列,第三个元素组成一个序列
scala> cc.unzip
<console>:16: error: No implicit view available from (Int, Int, Int) => (T1, T2).
cc.unzip
^
scala> cc.unzip3
res195: (Array[Int], Array[Int], Array[Int]) = (Array(1, 4),Array(2, 5),Array(3, 6))
def update(i: Int, x: T): Unit
将序列中 i 索引处的元素更新为 x
scala> gg
res196: Array[Int] = Array(1, 2, 3)
scala> gg.update(0,100)
scala> gg
res198: Array[Int] = Array(100, 2, 3)
def updated(index: Int, elem: A): Array[A]
将序列中 i 索引处的元素更新为 x ,并返回替换后的数组
scala> gg.updated(1,250)
res201: Array[Int] = Array(100, 250, 3)
def view(from: Int, until: Int): IndexedSeqView[T, Array[T]]
返回 from 到 until 间的序列,不包括 until 处的元素
scala> arrb
res202: scala.collection.mutable.ArrayBuffer[Int] = ArrayBuffer(1, 2, 3, 5, 8, 80, 60, 8, 16, 90)
scala> arrb.view(5)
res211: Int = 80
scala> arrb.view(5,10).toList
res212: List[Int] = List(80, 60, 8, 16, 90)
def zip[B](that: GenIterable[B]): Array[(A, B)]
将两个序列对应位置上的元素组成一个pair序列
scala> gg
res213: Array[Int] = Array(100, 2, 3)
scala> val cc=Array("tian","yong","tao")
cc: Array[String] = Array(tian, yong, tao)
scala> gg.zip(cc)
res214: Array[(Int, String)] = Array((100,tian), (2,yong), (3,tao))
def zipAll[B](that: collection.Iterable[B], thisElem: A, thatElem: B): Array[(A, B)]
同 zip ,但是允许两个序列长度不一样,不足的自动填充,如果当前序列端,空出的填充为 thisElem,如果 that 短,填充为 thatElem
scala> gg
res222: Array[Int] = Array(100, 2, 3)
scala> arrb
res223: scala.collection.mutable.ArrayBuffer[Int] = ArrayBuffer(1, 2, 3, 5, 8, 80, 60, 8, 16, 90)
scala> gg.zipAll(arrb,250,850)
res220: Array[(Int, Int)] = Array((100,1), (2,2), (3,3), (250,5), (250,8), (250,80), (250,60), (250,8), (250,16), (250,90))
scala> arrb.zipAll(gg,250,850)
res221: scala.collection.mutable.ArrayBuffer[(Int, Int)] = ArrayBuffer((1,100), (2,2), (3,3), (5,850), (8,850), (80,850), (60,850), (8,850), (16,850), (90,850))
def zipWithIndex: Array[(A, Int)]
序列中的每个元素和它的索引组成一个序列
scala> arrb.zipWithIndex
res224: scala.collection.mutable.ArrayBuffer[(Int, Int)] = ArrayBuffer((1,0), (2,1), (3,2), (5,3), (8,4), (80,5), (60,6), (8,7), (16,8), (90,9))
scala> arrb.insert
def insert(n: Int,elems: Int*): Unit
在索引n位置插入elems
scala> arrb
res328: scala.collection.mutable.ArrayBuffer[Int] = ArrayBuffer(1, 2, 3, 5, 8, 80, 60, 8, 16, 90)
scala> arrb.insert(0,100,200,300)
scala> arrb
res330: scala.collection.mutable.ArrayBuffer[Int] = ArrayBuffer(100, 200, 300, 1, 2, 3, 5, 8, 80, 60, 8, 16, 90)
def insertAll(n: Int,seq: Traversable[Int]): Unit
scala> arrb.insertAll(0,Array(1000,2000))
scala> arrb
res332: scala.collection.mutable.ArrayBuffer[Int] = ArrayBuffer(1000, 2000, 100, 200, 300, 1, 2, 3, 5, 8, 80, 60, 8, 16, 90)
Map
scala> val mymap=Map((1,2),(2,50),(3,600),(7,450))
mymap: scala.collection.mutable.Map[Int,Int] = Map(2 -> 50, 7 -> 450, 1 -> 2, 3 -> 600)
scala> for((k,v)<-mymap) println(k+" "+v)
2 50
7 450
1 2
3 600
scala> for(x<-mymap) println(x)
(2,50)
(7,450)
(1,2)
(3,600)
scala> for(x<-mymap.values) println(x)
50
450
2
600
scala> for(x<-mymap.keys) println(x)
2
7
1
3
scala> mymap.get(50)
res527: Option[Int] = None
scala> mymap.get(3)
res528: Option[Int] = Some(600)
scala> mymap.getOrElse(50,0)
res529: Int = 0
对偶是元组的基本形态,元组是不同类型值的集合
一元组 ,元组的元从1开始,而不是从0
scala> val vb=(11,22,33)
vb: (Int, Int, Int) = (11,22,33)
scala> vb._2
res549: Int = 22
var 自带getter setter
类


在scala中,每个类都有主构造器,不以this方法定义,而是与类定义交织在一起
1.主构造器直接放置在类名之后
2.主构造器会执行类定义中的所有语句
如果类名无参数,则该类具备一个无参主构造器
可以在主构造器中使用默认参数来避免过多的使用辅助构造器 如:
scala> class person(val name:String="tianyongtao",val age:Int=100)
defined class person
scala> val p=new person("abc")
p: person = person@4fd566d4
scala> p.age
res572: Int = 100
主构造器参数可以是任意形态 ,var val private 等
scala> private class person(val name:String="tianyongtao",val age:Int=100)
defined class person
scala> class person private(val name:String="tianyongtao",val age:Int=100)
defined class person
scala 允许任何语法结构嵌套语法结构,函数嵌套函数,类嵌套类:类中定义类
scala> class person(val name:String="tianyongtao",val age:Int=100){ class member(grid:Int){ println(grid) } }
defined class person
scala> val p1=new person("laowang")
p1: person = person@3002040b
scala> val m1=new p1.member(88)
88
m1: p1.member = person$member@798ffd13
在java中,你会用到既有实例方法又有静态方法的类;Scala可以通过类和类同名的“”伴生“”对象实现同样的目的
class person{.......}
object person{........}
类与伴生对象可以互相访问私有特性,他们必须在同一个源文件中。
Array(100) 与new Array(100) 不同
scala> val xx=Array(100)
xx: Array[Int] = Array(100)
scala> xx
res574: Array[Int] = Array(100)
scala> val bb=new Array(100)
bb: Array[Nothing] = Array(null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null)
包
可以不用{},直接文件顶部使用package .......即可
包可以包括类 对象和特质,但不能包含函数与变量的定义,这是java虚拟机的局限。把工具函数或常量添加到包而不是某个utils对象,
这是更加合理的做法,包对象的出现就是为了解决这个局限。
每个包都可以有一个包对象,它需要在父包中定义它,且名称与子包一样
在scala中,引入可以出现在任何地方
继承
扩展类使用extends :class subclassname extends 父类{..........}
final类不能被扩展
重写一个非抽象的方法必须使用override: overridedef 函数名.............
scala调用超类的方法和java一致,使用super关键字:super.函数名
判断某个对象是否属于某个类
scala> class person(val name:String="tianyongtao",val age:Int=100){ class member(grid:Int){ println(grid) } }
defined class person
scala> val p1=new person("laowang",10)
p1: person = person@5570c832
scala> p1.isInstanceOf[person]
res580: Boolean = true
如果检测成功,可以通过asInstanceOf将引用转换了子类的引用
每个辅助构造器必须以先前定义的辅助构造器或者主构造器的调用开始
子类的辅助构造器最终都要调用主构造器,只有主构造器可以调用超类的构造器
def 只能重写另一个def
val 只能重写另一个val 或者不带参数的def
var 只能重写另一个抽象的var
被abstract修饰的类是抽象类,不能被实例化,通常他有一个或者几个方法没有被完整定义
抽象方法不用abstract修饰,没有方法体,至少存在一个抽象方法,则该类必须声明为抽象类
没有初始值的字段,就是抽象字段。val var
提前定义
所谓 提前定义的语法 让你在超类的构造器构造器执行之前,初始化子类的val字段
引用相等性
在 scala中,AnyRef的eq 方法检查两个引用是否指向同一个对象,AnyRef的equals方法调用eq。
实现类时应该根据实际情况重写equals方法。在引用程序里,一般不直接调用eq或者equals,
直接用==就可以了
文件
scala> import scala.io.Source
import scala.io.Source
读取行
scala> val fl=Source.fromFile("/root/tmpdata/tian.txt")
fl: scala.io.BufferedSource = non-empty iterator
scala> fl.getLines.foreach(println)
name tianyongtao
sex man
game wzry
age 100
score 120
home linying
scala> fl.getLines.map(x=>x+"#").foreach(println) //很明显 getlines按行读取
name tianyongtao#
sex man#
game wzry#
age 100#
score 120#
home linying#
scala> val fl=Source.fromFile("/root/tmpdata/tian.txt")
fl: scala.io.BufferedSource = non-empty iterator
scala> for(line<-fl.getLines) println(line+"#") //很明显 getlines按行读取
name tianyongtao#
sex man#
game wzry#
age 100#
score 120#
home linying#
读完Source对象后,记得close
按字符逐个读取
scala> for(c<-fl)print(c+"#")
n#a#m#e# #t#i#a#n#y#o#n#g#t#a#o#
#s#e#x# #m#a#n#
#g#a#m#e# #w#z#r#y#
#a#g#e# #1#0#0#
#s#c#o#r#e# #1#2#0#
#h#o#m#e# #l#i#n#y#i#n#g#
scala> val fl=Source.fromFile("/root/tmpdata/tian.txt")
fl: scala.io.BufferedSource = non-empty iterator
scala> fl.foreach(print)// 按字符逐个读取
name tianyongtao
sex man
game wzry
age 100
score 120
home linying
scala> fl.map(c=>c+"#").foreach(print)// 很明显,按字符读取
n#a#m#e# #t#i#a#n#y#o#n#g#t#a#o#
#s#e#x# #m#a#n#
#g#a#m#e# #w#z#r#y#
#a#g#e# #1#0#0#
#s#c#o#r#e# #1#2#0#
#h#o#m#e# #l#i#n#y#i#n#g#
#
scala> val ite=fl.buffered
ite: scala.collection.BufferedIterator[Char] = non-empty iterator
scala> while(ite.hasNext){print(ite.next)}
name tianyongtao
sex man
game wzry
age 100
score 120
home linying
scala> fl.mkString("#")
res49: String =
"n#a#m#e# #t#i#a#n#y#o#n#g#t#a#o#
#s#e#x# #m#a#n#
#g#a#m#e# #w#z#r#y#
#a#g#e# #1#0#0#
#s#c#o#r#e# #1#2#0#
#h#o#m#e# #l#i#n#y#i#n#g#
"
scala> val urlfl=Source.fromURL("http://spark.apache.org/")
urlfl: scala.io.BufferedSource = non-empty iterator
scala> urlfl.get
getClass getLines
scala> urlfl.getLines.foreach(println)
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="utf-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>
Apache Spark™ - Lightning-Fast Cluster Computing
</title>
---------------------------------
scala> val strfl=Source.fromString("How are you!")
strfl: scala.io.Source = non-empty iterator
scala没有内建的对写入文件的支持,可以调用java.io.PrintWriter
scala> import java.io.PrintWriter
import java.io.PrintWriter
scala> val wfl=new PrintWriter("/root/tmpdata/hello.txt")
wfl: java.io.PrintWriter = java.io.PrintWriter@241eb542
scala> for(i<- 1 to 100) wfl.write(i+" ")
scala> wfl.close
scala> val wfl=new PrintWriter("/root/tmpdata/hello.txt")
wfl: java.io.PrintWriter = java.io.PrintWriter@1da943b1
scala> for(i<- 1 to 100) wfl.print(i+"#")
scala> wfl.close
scala没有访问目录中的文件或者遍历所有目录的类
scala> import scala.reflect.io.Directory
import scala.reflect.io.Directory
scala> import java.io.File
import java.io.File
//遍历某目录下所有的子目录
scala> def subdirs(fs:File):Iterator[File]={ var child=fs.listFiles.filter(_.isDirectory);child.toIterator++child.toIterator.flatMap(subdirs _)}
subdirs: (fs: java.io.File)Iterator[java.io.File]
scala> for (f<-subdirs(new File("/root/tmpdata"))) println(f)
/root/tmpdata/spark-2.2.0-bin-hadoop2.7
/root/tmpdata/metastore_db
.................................................
//遍历某目录下所有的文件
scala> def filedirs(fs:File):Iterator[File]={
var dirs=fs.listFiles.filter(_.isDirectory);
var files=fs.listFiles.filter(_.isFile);
files.toIterator++dirs.toIterator.flatMap(filedirs _)
}
scala> for (f<-filedirs(new File("/root/tmpdata")) if f.toString.indexOf("spark")<0) println(f)
/root/tmpdata/20171026.txt
/root/tmpdata/name.csv
/root/tmpdata/derby.log
/root/tmpdata/tian.txt
/root/tmpdata/hello.txt
/root/tmpdata/namejson.txt
/root/tmpdata/metastore_db/dbex.lck
/root/tmpdata/metastore_db/db.lck
...........................................
序列化 (Serialization)将对象的状态信息转换为可以存储或传输的形式的过程。
在序列化期间,对象将其当前状态写入到临时或持久性存储区。以后,可以通过从存储区中读取或反序列化对象的状态,
重新创建该对象。
把对象转换为字节序列的过程称为对象的序列化;把字节序列恢复为对象的过程称为对象的反序列化。
进程控制
scala设计的目的之一就是在简单的脚本化任务与大型程序之间保持良好的伸缩性
sys.process包含了一个从字符串到ProcessBuilder对象的隐式转换,!操作符执行的就是执行这个ProcessBuilder对象
,返回的结果是被执行程序的返回值:执行成功就是0,否则显示错误的非0的值
scala> import sys.process._
import sys.process._
scala> "ls " !
<console>:20: warning: postfix operator ! should be enabled
by making the implicit value scala.language.postfixOps visible.
This can be achieved by adding the import clause 'import scala.language.postfixOps'
or by setting the compiler option -language:postfixOps.
See the Scaladoc for value scala.language.postfixOps for a discussion
why the feature should be explicitly enabled.
"ls " !
scala> import scala.language.postfixOps
import scala.language.postfixOps
scala> "ls " !
10
1.txt
20170920.txt
anaconda-ks.cfg
app
derby.log
hadoop
scala> "jps "!
1745 DataNode
19122 Jps
2660 Worker
2229 NodeManager
2585 Master
1642 NameNode
2124 ResourceManager
17692 MainGenericRunner
1948 SecondaryNameNode
res17: Int = 0
scala> "hdfs dfs -lsr /tmp/20171024"!
lsr: DEPRECATED: Please use 'ls -R' instead.
-rw-r--r-- 1 root supergroup 46 2017-10-24 17:04 /tmp/20171024/20171024.txt
-rw-r--r-- 1 root supergroup 38 2017-10-24 17:04 /tmp/20171024/20171026.txt
drwxr-xr-x - root supergroup 0 2017-10-24 17:32 /tmp/20171024/avg.txt
.......................................
你可以将程序输出以管道的形式作为输入传递给另一个程序,用#|操作符,如下:
scala> "hdfs dfs -lsr /tmp/20171024"#|"grep tian"!
lsr: DEPRECATED: Please use 'ls -R' instead.
-rw-r--r-- 1 root supergroup 66 2017-10-24 16:10 /tmp/20171024/tian.txt
res19: Int = 0
重新定向到文件使用 #>
scala> "ls -al "#>new File("/root/tmpdata/files.txt")!
res26: Int = 0
执行成功,成功找到files.txt文件
scala> "ls /root/tmpdata "#|"grep file"!
files.txt
res29: Int = 0
scala> "cat /root/tmpdata/files.txt"!
total 282064
dr-xr-x---. 22 root root 4096 Nov 20 16:22 .
dr-xr-xr-x. 26 root root 4096 Nov 17 10:10 ..
-rw-r--r-- 1 root root 0 Oct 19 10:06 10
.................
res30: Int = 0
追加到文件尾部: #>>
scala> "jps"#>>new File("/root/tmpdata/files.txt")!
res35: Int = 0
将某个文件的内容作为输入 :#<
scala> "grep mysql"#<new File("/root/tmpdata/files.txt")!
drwxr-xr-x 2 root root 4096 Sep 6 14:54 mysql
-rw-r--r-- 1 root root 989495 Sep 6 16:37 mysql-connector-java-5.1.39.jar
-rw------- 1 root root 6525 Nov 2 15:54 .mysql_history
res32: Int = 0
可以将进程结合在一起使用 p#&&q,进程p执行成功执行q;
scala> "jps "#&& "ps "!
1745 DataNode
2660 Worker
2229 NodeManager
2585 Master
1642 NameNode
19835 Jps
2124 ResourceManager
17692 MainGenericRunner
1948 SecondaryNameNode
PID TTY TIME CMD
17679 pts/2 00:00:00 bash
17692 pts/2 00:01:31 java
19853 pts/2 00:00:00 ps
25026 pts/2 00:00:00 bash
res38: Int = 0
p#||q p执行不成功执行q
scala> "jps "#|| "ps "!
1745 DataNode
2660 Worker
2229 NodeManager
2585 Master
1642 NameNode
2124 ResourceManager
17692 MainGenericRunner
19964 Jps
1948 SecondaryNameNode
res44: Int = 0
如果你需要在不同目录下运行进程,或者使用不同的环境变量


正则表达式
regex:正则表达式
构造regex对象,使用String类的r方法即可
scala> val reg1="...[0-9][a-z]".r
reg1: scala.util.matching.Regex = ...[0-9][a-z]
scala> reg1.findAllIn("hhh8z 8h99 abc1z").toList
res48: List[String] = List(hhh8z, abc1z)
或者
scala> import scala.util.matching.Regex
import scala.util.matching.Regex
scala> val reg2=new Regex("...[0-9][a-z]")
reg2: scala.util.matching.Regex = ...[0-9][a-z]
scala> reg2.findAllIn("hhh8z 8h99 abc1z").toList
res49: List[String] = List(hhh8z, abc1z)
scala> reg2.findFirstIn("hhh8z 8h99 abc1z").toList
res50: List[String] = List(hhh8z)
scala> reg2.replaceAllIn("hhh8z 8h99 abc1z","tian")
res55: String = tian 8h99 tian
scala> reg2.replaceFirstIn("hhh8z 8h99 abc1z","tian")
res60: String = tian 8h99 abc1z
Scala Trait 特质
Trait相当于java的接口,但比接口更强大,它可以定义属性和方法的实现
scala的类一般继承单一父类,Trait可以继承多个父类
Trait定义与类类似,但使用的关键字是Trait
子类继承特征可以实现未被实现的方法。所以其实 Scala Trait(特征)更像 Java 的抽象类。
scala> trait compare{ def isbigger(age:Int):Boolean={age>10};def iseq(num:Int):Boolean;}
defined trait compare
scala> class comp(num:Int) extends compare{ def iseq(num:Int):Boolean={ num==99}}
defined class comp
scala> val cp1=new comp(10)
cp1: comp = comp@784ba7c6
scala> cp1.iseq(10)
res67: Boolean = false
scala> cp1.iseq(99)
res68: Boolean = true
scala> cp1.isbigger(50)
res71: Boolean = true
scala> cp1.isbigger(5)
res72: Boolean = false
如果你的特质不止一个,可以使用with添加额外的特质如下:
class 类名 extends Trait1 with Trait2 with Trait3{ ................}
class 类名 extends 父类 with Trait1 with Trait1{ ................}
scala只能有一个超类,但可以有任意数量的特质。
你可以在构造对象的时候添加一个特质:
val ob=new 类名 with Traitname
特质中的字段可以是抽象的,也可以是具体的
和类一样,特质也可以有构造器,由字段的初始化和其他特质体中的语句构成。
构造器的执行顺序:
首先调用超类构造器
特质构造器在超类的构造器之后,类的构造器之前执行
特质由左到右进行构造
每个特质中,父特质先被构造
如果多个特质公用构造器,而父构造器已经被构造,则不会被再次构造
所有特质构造完毕,子类被构造
初始化特质的字段
特质不能有构造器参数,每个特质都有给无参数构造器
1.通过 “提前定义“
2.在构造器中使用懒值
操作符
中置操作符
a 操作符 b :其中操作符代表一个带有两个参数的方法,一个隐式参数,一个显示参数
scala> 1 to 10
res75: scala.collection.immutable.Range.Inclusive = Range 1 to 10
scala> 1.to(10)
res76: scala.collection.immutable.Range.Inclusive = Range 1 to 10
scala> 1->10
res77: (Int, Int) = (1,10)
scala> 1->(10)
res78: (Int, Int) = (1,10)
scala> 1.->(10)
res79: (Int, Int) = (1,10)
一元操作符:只有一个参数的操作符
scala> 1.toString
res81: String = 1
scala> 1.toString()
res82: String = 1
赋值操作符 =
结合性
操作符的结合性决定了 他们是从左到右还是从右到左求值
除了以:结尾的操作符 和 = ,其他操作符都是左结合的
构造列表的操作符 :: 从右到左
scala> 1::2::Nil
res84: List[Int] = List(1, 2)
高级函数
scala> import scala.math._
import scala.math._
def ceil(x: Double): Double
//将b设置为ceil函数,ceil函数后面的 _意味着你确实指的这个函数,而不是忘记给它送参数
//从技术上讲 _ 将方法转换为函数,如下b是一个包含函数的变量而不是一个固定的函数
scala> val b=ceil _
b: Double => Double = $$Lambda$1485/819502150@1e2f5da2
scala> b(10.20)
res94: Double = 11.0
函数的使用:
直接调用
传递它,存放在变量中,或者作为参数传递给另一个函数
scala> def sum(a:Int,b:Int):Int={a+b}
sum: (a: Int, b: Int)Int
scala> sum(10,10)
res96: Int = 20
scala> Array(1,2,3,4,5,6,7,8,9).reduce(sum)
res95: Int = 45
匿名函数
不需要函数名,直接 传参数给它
scala> (x:Int)=>x*3
res97: Int => Int = $$Lambda$1500/807254826@611590df
你可以将匿名函数存放在变量中
scala> val gg=(x:Int)=>x*3
gg: Int => Int = $$Lambda$1501/6609675@721d4b44
scala> gg(32)
res98: Int = 96
scala> def gg(x:Int)={x*3}
gg: (x: Int)Int
scala> gg(32)
res99: Int = 96
不用命名直接传递给另一个函数
scala> Array(1,2,3,4,5).map(x=>x+100)
res100: Array[Int] = Array(101, 102, 103, 104, 105)
scala> Array(1,2,3,4,5).map((x)=>x+100)
res101: Array[Int] = Array(101, 102, 103, 104, 105)
scala> Array(1,2,3,4,5).map((x:Int)=>x+100)
res102: Array[Int] = Array(101, 102, 103, 104, 105)
scala> Array(1,2,3,4,5).map(_+100)
res103: Array[Int] = Array(101, 102, 103, 104, 105)
//中置法可以没有.
scala> Array(1,2,3,4,5)map(_+100)
res104: Array[Int] = Array(101, 102, 103, 104, 105)
你也可以将函数参数放在花括号里面
scala> Array(1,2,3,4,5)map{_+100}
res106: Array[Int] = Array(101, 102, 103, 104, 105)
scala> Array(1,2,3,4,5).map{(x:Int)=>x+100}
res107: Array[Int] = Array(101, 102, 103, 104, 105)
带函数参数的函数
//这里的参数可以是任何参数为double,返回值为double的函数
scala> def gvl(f:(Double)=>Double)=f(25.1)
gvl: (f: Double => Double)Double
scala> gvl(ceil _)
res115: Double = 26.0
scala> gvl(sqrt _)
res116: Double = 5.0099900199501395
scala> def gvl(f:(Double)=>Double)={sqrt(f(25.1))}
gvl: (f: Double => Double)Double
scala> gvl(ceil _)
res118: Double = 5.0990195135927845
scala> gvl(sqrt _)
res119: Double = 2.2383006991801033
scala> def gvl(f:(Double)=>Double)={ceil(f(25.1))}
gvl: (f: Double => Double)Double
scala> gvl(sqrt _)
res120: Double = 6.0
参数类型是:(参数类型)=结果类型 因此gvl的参数类型是((Double)=>Double)=>Double
一个接受函数参数的函数被称为高阶函数 higher-order function
高阶函数也是产生另一个函数,如下:
scala> def cj(x:Int)=(y:Int)=>x*y
cj: (x: Int)Int => Int
scala> cj(5) //返回一个(y:Int)=5*y的匿名函数
res121: Int => Int = $$Lambda$1563/1407262520@391c14ee
scala> val hh=cj(5) //返回一个(y:Int)=5*y的匿名函数
hh: Int => Int = $$Lambda$1563/1407262520@ad701ad
scala> hh(10)
res122: Int = 50
参数推断
当一个匿名函数传递给另一个函数或者方法时,scala会帮你推断出类型信息
Array(1,2,3,4,5).map((x:Int)=>x+100)
可以写成:Array(1,2,3,4,5).map((x)=>x+100)
只有一个参数可以省去()
可以写成:Array(1,2,3,4,5).map(x=>x+100)
如果参数在=>右边只出现一次,可以用_替换
可以写成:Array(1,2,3,4,5).map(_+100)
一些有用的高阶函数:
scala> (1 to 9).map("*"*_).reverse.foreach(println) //map,foreach 为高级函数
*********
********
*******
******
*****
****
***
**
*
scala> (1 to 9).filter(_%4!=0).reduce(_+_)//filter reduce 为高级函数
res144: Int = 33
闭包
闭包是一个函数,由代码和代码用到的任何非局部变量定义构成,它的返回值取决于函数之外声明的一个或多个变量的值
face是匿名函数函数 (i:Int) => i * face之外的变量,但在闭合的范围之内,但属于函数以外声明的变量
scala> def mulcol(face:Int) = (i:Int) => i * face
mulcol: (face: Int)Int => Int
scala> val colm=mulcol(10) //返回(i:Int)=>i*10
colm: Int => Int = $$Lambda$1068/602572848@59a09be
scala> colm(5) //5*10
res1: Int = 50
SAM转换(single abstract method) ??
柯里化(currying)
柯里化就是将原来接受两个参数的函数转化为新的接受一个参数的函数的过程。
scala> def sumInt(a:Int,b:Int)={a+b}
sumInt: (a: Int, b: Int)Int
scala> sumInt(8,5)
res3: Int = 13
scala> def sumcurry(a:Int)(b:Int)={a+b}
sumcurry: (a: Int)(b: Int)Int
scala> val sumb=sumcurry(8)(_) //柯里化
sumb: Int => Int = $$Lambda$1113/310452117@68f1b89
scala> sumb(5)
res4: Int = 13
def corresponds[B](that: scala.collection.GenSeq[B])(p: (String, B) => Boolean): Boolean
在这里that序列与前提函数p是分开的两个柯里化参数,类型推断器可以推断出B是that类型,
以下例来看,前提函数的类型应该是(String,String)=>Boolean,有了这个信息,编译器就可以接受
_.equals(_)) 的简写了
scala> val arra=Array("hello","world")
arra: Array[String] = Array(hello, world)
scala> val arrb=Array("hello","World")
arrb: Array[String] = Array(hello, World)
scala> val arrc=Array("hello","world")
arrc: Array[String] = Array(hello, world)
scala> arra.corresponds(arrb)(_.equals(_))
res5: Boolean = false
scala> arra.corresponds(arrc)(_.equals(_))
res6: Boolean = true
scala> def equ(a:String,b:String)={a.equals(b)}
equ: (a: String, b: String)Boolean
scala> arra.corresponds(arrb)(equ(_,_)) //将函数equ映射到集合
res7: Boolean = false
scala> arra.corresponds(arrc)(equ(_,_))
res8: Boolean = true
scala> arra.corresponds(arrc)((a,b)=>equ(a,b))
res9: Boolean = true
控制抽象 ??
return 表达式
如下例所示,return表达式执行以后,函数charindex执行就会终止并返回值
scala> def charindex(str:String,c:Char):Char={for(i<- str){if(i==c) return i}; return '#'}
charindex: (str: String, c: Char)Char
scala> charindex("hello",'u')
res4: Char = #
scala> charindex("hello",'e')
res5: Char = e
集合
所有集合都扩展自Iterable特质
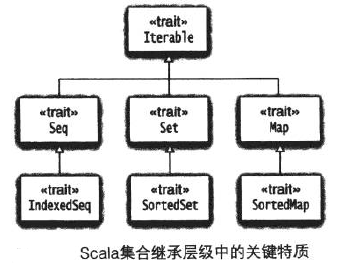
Iterable指的是那些能生成用来访问集合中所有元素的Iterator的集合
Seq是有先后次序的值的序列 比如数组.列表,可以通过整数型下标快速的访问
set 是一组没有先后次序的值,不可重复,SortedSet以某种排过序的顺序被访问
scala> val sset=SortedSet(100,200,50,800,5,-50,100,5,100)
sset: scala.collection.mutable.SortedSet[Int] = TreeSet(-50, 5, 50, 100, 200, 800)
Map是一组键值对偶,SortedMap按照键的排序访问其中的实体
scala> val smp=SortedMap((2,100),(3,800),(4,900),(5,200),(1,50))
smp: scala.collection.mutable.SortedMap[Int,Int] = TreeMap(1 -> 50, 2 -> 100, 3 -> 800, 4 -> 900, 5 -> 200)
scala同时支持可变和不可变的集合,不可变集合从不改变,可以安全的共享其引用,在多线程也没问题
scala.collection.mutable是可变的集合;scala.collection.immutable是不可变集合
scala默认的是不可变的集合,scala.collection包中的伴生对象产出不可变的集合
scala> val mp=Map((1,100))
mp: scala.collection.immutable.Map[Int,Int] = Map(1 -> 100)
scala> val mp2=scala.collection.mutable.Map((1,200))
mp2: scala.collection.mutable.Map[Int,Int] = Map(1 -> 200)
scala> mp2++=Map((2,500))
res22: mp2.type = Map(2 -> 500, 1 -> 200)
scala> mp++=Map((2,500))
<console>:22: error: value ++= is not a member of scala.collection.immutable.Map[Int,Int]
Expression does not convert to assignment because receiver is not assignable.
mp++=Map((2,500))
^
scala> mp2+=100->9
res25: mp2.type = Map(2 -> 500, 100 -> 9, 1 -> 200)
scala> mp2+(100->88) // 将100->9覆盖
res27: scala.collection.mutable.Map[Int,Int] = Map(2 -> 500, 100 -> 88, 1 -> 200)
序列
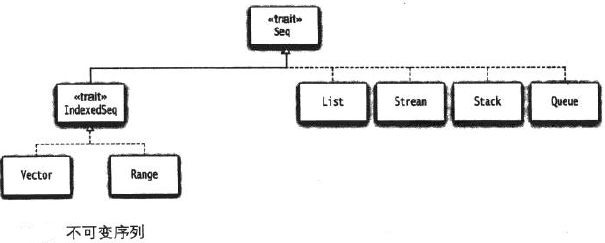
Vector(向量)是ArrayBuffer的不可变版本,一个带下标的序列,支持快速随机访问,向量是以树形
的结构实现的,每个节点可以有不超过32个子节点,对于100w的元素,只需要四层节点
scala> Math.pow(32,4)
res30: Double = 1048576.0
访问这样的列表某个元素只需要4跳,在链表中,则平均需要50W跳
Range对象表示一个整数序列,并不存储所有值,只保存起始值,结束值和增值
scala> val rg=0 to 20 by 5
rg: scala.collection.immutable.Range = Range 0 to 20 by 5
scala> rg.toList
res37: List[Int] = List(0, 5, 10, 15, 20)
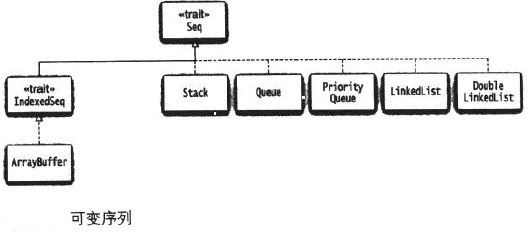
数组缓冲,栈,队列,优先级队列等都是标准的数据结构,用来实现特定运算;链表有些特殊
在scala中,列表要么是要给Nil(空表),要么就是一个head加上一个tail,tail又是一个列表
scala> val lls=LinkedList(1,2,6,4) //2.11版本以后低级的链表已经被弃用
<console>:20: warning: object LinkedList in package mutable is deprecated (since 2.11.0): low-level linked lists are deprecated
val lls=LinkedList(1,2,6,4)
^
lls: scala.collection.mutable.LinkedList[Int] = LinkedList(1, 2, 6, 4)
集
集是不可重复的,添加已有元素没有效果,和列表不同,不保留元素插入顺序
没有导入 import scala.collection.mutable._之前Set默认是immutable,引入以后
默认是mutable,均没有保留元素插叙顺序
scala> val myst=Set(10,8,9,1,20,8,9,9,120,5)
myst: scala.collection.immutable.Set[Int] = Set(5, 120, 10, 20, 1, 9, 8)
scala> import scala.co
collection compat concurrent
scala> import scala.collection.mutable._
import scala.collection.mutable._
scala> val myst=Set(10,8,9,1,20,8,9,9,120,5)
myst: scala.collection.mutable.Set[Int] = Set(9, 1, 5, 20, 120, 10, 8)
LinkedHashSet链式哈希集,会保存元素的插入顺序
下例很明显保留了插入顺序
scala> val mylst=LinkedHashSet(10,8,9,1,20,8,9,9,120,5)
mylst: scala.collection.mutable.LinkedHashSet[Int] = Set(10, 8, 9, 1, 20, 120, 5)
如果需要按已经排序的顺序去访问集中的元素,则可以使用已排序集
已排序集是用红黑树实现的
scala> val mysst=SortedSet[Int]()
mysst: scala.collection.mutable.SortedSet[Int] = TreeSet()
scala> mysst++=myst
res5: mysst.type = TreeSet(1, 5, 8, 9, 10, 20, 120)
scala> mysst
res6: scala.collection.mutable.SortedSet[Int] = TreeSet(1, 5, 8, 9, 10, 20, 120)
scala> mysst.contains(20)
res10: Boolean = true
scala> mysst contains 20 //中置操作符
res11: Boolean = true
TreeSet、HashSet 都继承至 Set
TreeSet 是用「红黑树」来实现的,「红黑树」是一种相对平衡的二叉查找树,
它可以在 O(log2 n) 时间复杂度内做查找
map foreach flatmap collect 应用到所有元素
reduce fold aggregate 以非特定顺序将二元操作应用到所有元素
reduceLeft,foleLeft ,reduceRight,reduceLeft以特定顺序将二元操作应用的所有元素
scala> mysst.dropWhile(_>10) //首元素为1,因此删除了0个
res40: scala.collection.mutable.SortedSet[Int] = TreeSet(1, 5, 8, 9, 20, 90, 100)
scala> mysst.dropWhile(_<8)
res41: scala.collection.mutable.SortedSet[Int] = TreeSet(8, 9, 20, 90, 100)
scala> mysst.takeWhile(_>10)//首原始为8小余10,返回空集
res42: scala.collection.mutable.SortedSet[Int] = TreeSet()
scala> mysst.takeWhile(_<10)
res43: scala.collection.mutable.SortedSet[Int] = TreeSet(1, 5, 8, 9)
split :分离 使分离
将函数映射到集合
scala> myls.reduce
def reduce[A1 >: Int](op: (A1, A1) => A1): A1
scala> myls.reduce(_+_)
res18: Int = 1191
scala> myls.reduce((a,b)=>a+b)
res19: Int = 1191
scala> def sumint(x:Int,y:Int)={x+y}
sumint: (x: Int, y: Int)Int
scala> myls.reduce(sumint(_,_)) //函数sumint映射到集合myls
res20: Int = 1191
scala> myls.reduce((a,b)=>sumint(a,b))
res21: Int = 1191
scala> myls
res27: List[Int] = List(100, 200, 30, 5, 6, 50, 300, 500)
scala> myls.collect{case a =>if (a==5)a+8888 else a } //collect方法用于偏函数
res28: List[Int] = List(100, 200, 30, 8893, 6, 50, 300, 500)
------------------------------
scala> myls
res30: List[Int] = List(100, 200, 30, 5, 6, 50, 300, 500)
scala> myls.reduceLeft(_+_)
res31: Int = 1191
reduceLeft操作如下图所示:
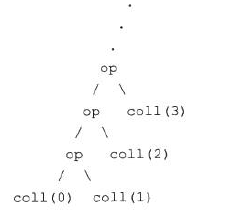
scala> myls.foldLeft(0)(_+_)
res33: Int = 1191
你可以用 /: 写foldLeft操作
scala> (0 /: myls)(_+_)
res73: Int = 1191
foldLeft操作下图所示:
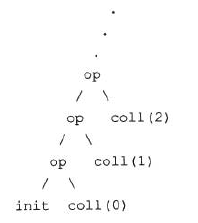
scala> myls.foldRight(0)(_+_)
res34: Int = 1191
你可以用 :写foldRight操作
scala> (myls:�)(_+_)
res77: Int = 1191
foldRight操作如下图所示:

折叠有时候可以作为循环的替代。
计算一个字符串每个字符出现的频率,方式一:循环,访问一个字母更新一个可变映射
scala> val mymp=Map[Char,Int]()
mymp: scala.collection.mutable.Map[Char,Int] = Map()
scala> for(c<-"hellworld") mymp(c)=mymp.getOrElse(c,0)+1
scala> mymp
res47: scala.collection.mutable.Map[Char,Int] = Map(w -> 1, e -> 1, h -> 1, d -> 1, r -> 1, l -> 3, o -> 1)
scala> mymp('z')=100
scala> mymp
res55: scala.collection.mutable.Map[Char,Int] = Map(w -> 1, e -> 1, z -> 100, h -> 1, d -> 1, r -> 1, l -> 3, o -> 1)
scala> mymp('z')=mymp.getOrElse('z',0)+1
scala> mymp('z')
res58: Int = 101
另一种方式,将频率映射和新遇到的字母结合在一起,产出一个新的频率映射,如下图:
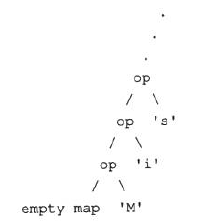
override def foldLeft[B](z: B)(op: (B, Int) => B): B
下例中使用foldleft进行折叠操作:Map[Char,Int]() 相当于foldLeft的初始值(z)
每折叠一次,Map增加或者覆盖个(c->(m.getOrElse(c,0)+1))
scala> (Map[Char,Int]() /: "tianyongtao")((m,c)=>m+(c->(m.getOrElse(c,0)+1)))
res8: scala.collection.mutable.Map[Char,Int] = Map(n -> 2, t -> 2, y -> 1, g -> 1, a -> 2, i -> 1, o -> 2)
----------------------
scala> myls
res3: List[Int] = List(10, 30, 60, 8, 6, 100, 70, 50, 30)
scala> (0 /:myls)((a,b)=>a+b)
res2: Int = 364
scala> "helloworld".foldRight //右折叠,初始值处于二元操作的第二个参数位置
override def foldRight[B](z: B)(op: (Char, B) => B): B
scala> "helloworld".foldLeft//左折叠,初始值处于二元操作的第一个参数位置
override def foldLeft[B](z: B)(op: (B, Char) => B): B
scala> "helloworld".foldRight(Map[Char,Int]())((c,m)=>m+(c->(m.getOrElse(c,0)+1)))
res11: scala.collection.mutable.Map[Char,Int] = Map(w -> 1, e -> 1, h -> 1, d -> 1, r -> 1, l -> 3, o -> 2)
scala> "helloworld".foldLeft(Map[Char,Int]())((m,c)=>m+(c->(m.getOrElse(c,0)+1)))
res13: scala.collection.mutable.Map[Char,Int] = Map(w -> 1, e -> 1, h -> 1, d -> 1, r -> 1, l -> 3, o -> 2)
拉链操作
两个集合,将对应的元素结合在一起,比如 产品名称 与产品价格
zip方法将它们生成一个对偶的列表
scala> val itemlist=List("apple","orange","banana","pear") //产品
itemlist: List[String] = List(apple, orange, banana, pear)
scala> val pricelist=List(8,4,3,3.5) //单价
pricelist: List[Double] = List(8.0, 4.0, 3.0, 3.5)
scala> itemlist.zip(pricelist)
res17: List[(String, Double)] = List((apple,8.0), (orange,4.0), (banana,3.0), (pear,3.5))
scala> val numlist=List(100,200,300,500) //重量
numlist: List[Int] = List(100, 200, 300, 500)
scala> itemlist.zip(pricelist).zip(numlist) //拉链操作
res18: List[((String, Double), Int)] = List(((apple,8.0),100), ((orange,4.0),200), ((banana,3.0),300), ((pear,3.5),500))
scala> itemlist.zip(pricelist).zip(numlist).map(x=>(x._1._1,x._1._2*x._2)) //求每种商品的价值
res19: List[(String, Double)] = List((apple,800.0), (orange,800.0), (banana,900.0), (pear,1750.0))
如果一个集合比两个集合短,对偶数量与较短的的集合数量一致
scala> val numsell=List(10,20,30)
numsell: List[Int] = List(10, 20, 30)
scala> val itemlist=List("apple","orange","banana","pear")
itemlist: List[String] = List(apple, orange, banana, pear)
scala> itemlist.zip(numsell)
res20: List[(String, Int)] = List((apple,10), (orange,20), (banana,30))
zipAll 指定较短列表的缺省值
scala> itemlist.zipAll(numsell,0,0)//缺省用0添补
res21: List[(Any, Int)] = List((apple,10), (orange,20), (banana,30), (pear,0))
scala> itemlist.zipAll(numsell,0,1)//缺省用0添补
res22: List[(Any, Int)] = List((apple,10), (orange,20), (banana,30), (pear,1))
zipWithIndex返回对偶列表,第二组成部分是每个元素的下标
scala> itemlist.zipWithIndex
res23: List[(String, Int)] = List((apple,0), (orange,1), (banana,2), (pear,3))
iterator方法从集合中获得一个迭代器
scala> val myite=itemlist.iterator
myite: Iterator[String] = non-empty iterator
scala> myite.size
res24: Int = 4
scala> myite.size
res25: Int = 0
迭代器
对于那些,结构完整,需要很大开销的集合,迭代器作用很大
迭代器对于集合是一个懒的替代品,需要时才去取元素,不需要更多元素,
则不会付出计算剩余元素的代价。
如:Source.fromFile产出一个迭代器,因为将整个文件读到内存不是很
高效的办法;迭代器可以用next和hasNext方法遍历集合中的元素
scala> for(i<-myite) println(i)
apple
orange
banana
pear
scala> for(i<-myite) println(i)
scala> val myite=itemlist.iterator
myite: Iterator[String] = non-empty iterator
scala> while(myite.hasNext) println(myite.next)
apple
orange
banana
pear
scala> while(myite.hasNext) println(myite.next)
以上两种方法会将迭代器移动到集合的尾部,迭代器就不能再使用了
迭代器不存在tail head init last等方法,执行size,map,count,filter等操作以后
,迭代器将位于集合结尾,执行find,take,迭代器将位于已找到或者已获取元素之后
scala> val myite=itemlist.iterator //包含四个元素 "apple","orange","banana","pear"
myite: Iterator[String] = non-empty iterator
scala> myite
res45: Iterator[String] = non-empty iterator
scala> for(i<-myite)println(i) //找到banana之后剩下之后的pear
pear
scala> myite.take(2).foreach(println)
apple
orange
scala> for(i<-myite)println(i) //take取2个元素后剩余2个
banana
pear
-------------------
scala> val myite=itemlist.iterator
myite: Iterator[String] = non-empty iterator
scala> myite.take(2) //没有行为操作,迭代器依然在起点
res52: Iterator[String] = non-empty iterator
scala> for(i<-myite)println(i)
apple
orange
banana
pear
流
迭代器每次对next的调用都会改变迭代器的指向。流(Stream)提供的是一个不可变的替代品
,流是一个尾部被懒计算的不可变列表
scala> def numsfrom(n:Int):Stream[Int]={ n#::numsfrom(n+1)}
numsfrom: (n: Int)Stream[Int]
#::更像列表中的::操作符,它构建出了一个流
tail强制对下一个元素求值
scala> numsfrom(10)
res8: Stream[Int] = Stream(10, ?)
scala> numsfrom(10).tail
res9: scala.collection.immutable.Stream[Int] = Stream(11, ?) //尾部未被求值
scala> numsfrom(10).tail.tail
res10: scala.collection.immutable.Stream[Int] = Stream(12, ?)//尾部未被求值
scala> numsfrom(10).tail.tail.tail
res11: scala.collection.immutable.Stream[Int] = Stream(13, ?)//尾部未被求值
如果想得到多个答案,可以使用take,
然后使用force,这将强制对所有值求值
scala> numsfrom(1).map(x=>x*x).take(5).force //force推动,促使,力量,强加
res2: scala.collection.immutable.Stream[Int] = Stream(1, 4, 9, 16, 25)
千万不能 numsfrom(1).force或者numsfrom(1).map().force,
将对一个无穷流的所有成员进行求值,内存将会溢出
也不要使用size,length等
迭代器,每个元素只能访问一次;而流将缓存访问过的行,允许你重复访问他们
scala> import scala.io.Source
import scala.io.Source
scala> val words=Source.fromFile("/root/tmpdata/tian.txt").getLines.toStream
words: scala.collection.immutable.Stream[String] = Stream(name tianyongtao, ?)
scala> words
res34: scala.collection.immutable.Stream[String] = Stream(name tianyongtao, ?)
scala> words(0)
res35: String = name tianyongtao
scala> words(1)
res36: String = sex man
scala> words
res37: scala.collection.immutable.Stream[String] = Stream(name tianyongtao, sex man, ?)
scala> words(3)
res38: String = age 100
scala> words
res39: scala.collection.immutable.Stream[String] = Stream(name tianyongtao, sex man, game wzry, age 100, ?)
懒视图
流方法是懒执行的,仅当结果需要时计算,可以对其他集合使用view方法得到相同的效果
和流不同,这个视图并不缓存任何值.
scala> barr
res59: scala.collection.mutable.ArrayBuffer[Int] = ArrayBuffer(1, 2, 3, 4, 5, 6, 7, 8, 9, 10)
scala> val viw=barr.view.map(_+100)
viw: scala.collection.SeqView[Int,scala.collection.mutable.Seq[_]] = SeqViewM(...)
scala> viw
res60: scala.collection.SeqView[Int,scala.collection.mutable.Seq[_]] = SeqViewM(...)
scala> viw(8)
res62: Int = 109
scala> viw(5)
res63: Int = 106
scala> viw
res64: scala.collection.SeqView[Int,scala.collection.mutable.Seq[_]] = SeqViewM(...)
同流一样,force可以对懒视图强制求值
scala> viw.force
res66: scala.collection.mutable.Seq[Int] = ArrayBuffer(101, 102, 103, 104, 105, 106, 107, 108, 109, 110)
与java集合的互操作 未验证
线程安全的集合 未验证

并行集合
更好的利用计算机的多个处理器,支持并发;scala提供了处理大型集合的处理方案,这些任务通常可以
自然的并行操作.例如计算多个元素,多线程并发计算不同区块,然后汇总区块结果,多线程并发编程比较
麻烦,但scala不用考虑这些,如下:par方法产出当前集合的一个并行实现
scala> barr
res70: scala.collection.mutable.ArrayBuffer[Int] = ArrayBuffer(1, 2, 3, 4, 5, 6, 7, 8, 9, 10)
scala> barr.par
res71: scala.collection.parallel.mutable.ParArray[Int] = ParArray(1, 2, 3, 4, 5, 6, 7, 8, 9, 10)
scala> barr.par.sum
res72: Int = 55
对数组,缓冲,哈希表,平衡树,并行实现会直接重用底层实际集合的实现,很高效
但是为什么,count,filter操作会卡死在这里????? 不理解中,for遍历也会死

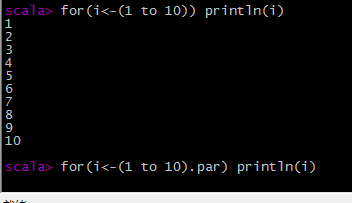
模式匹配
mach
scala> val mc=9 match {case 9=>"nine"; case _=>0}
mc: Any = nine
scala> val mc=1 match {case 9=>"nine"; case _=>0}
mc: Any = 0
守卫
def isDigit(x$1: Int): Boolean
def isDigit(x$1: Char): Boolean
scala> Character.isDigit(5)
res12: Boolean = false
scala> Character.isDigit('5')
res13: Boolean = true
scala> Character.isDigit('A')
res14: Boolean = false
模式总是从上而下进行匹配,如果带守卫的模式不能匹配,则捕获所有的模式(case _)
scala> def mc(n:Int):String={n match{ case 9=>"nine";case 5=>"five" case _ if n%2==0 =>"oushu"; case _=>n.toString+"else"}}
mc: (n: Int)String
scala> mc(5)
res15: String = five
scala> mc(7)
res16: String = 7else
scala> mc(6)
res17: String = oushu
scala> val arr=Array(1,2,3,45,5,6,7,8,9)
arr: Array[Int] = Array(1, 2, 3, 45, 5, 6, 7, 8, 9)
scala> def mc(n:Int):String={n match{ case 9=>"nine";case 5=>"five" ;case _ if n%2==0 =>"oushu"; case _=>"else"}}
mc: (n: Int)String
scala> arr.map(mc)
res23: Array[String] = Array(else, oushu, else, else, five, oushu, else, oushu, nine)
模式中的变量
如果case关键字后面跟着一个变量,那么匹配的表达式会被赋值给哪个变量
scala> val mm=7
mm: Int = 7
scala> arr
res46: Array[Int] = Array(1, 2, 3, 45, 5, 6, 7, 8, 9)
scala> def mc(n:Int):String={n match{ case 9=>"nine";case 5 =>"five"; case mm if mm%45==0=>"45a";case _=>"else"}}
mc: (n: Int)String
scala> arr.map(mc)
res47: Array[String] = Array(else, else, else, 45a, five, else, else, else, nine)
case _是这个特性的一个特殊情况,只不过变量名是_罢了
可以在守卫中使用变量,如上例;以防变量与常量冲突,变量应该以小写字母开头
scala> def typemach(x:Any)=x match{case s:String=>"str";case c:Char=>"char";case i:Int=>"int";case _=>"else";}
typemach: (x: Any)String
//注意模式中的变量,第一个模式中,匹配到的值被当做String绑定到s,第二个匹配中,匹配到的值被当做Char绑定到c,.....
//不需要用asInstan
scala> typemach("sss")
res54: String = str
scala> typemach('c')
res55: String = char
scala> typemach(1)
res56: String = int
scala> typemach(Array(1,2,3))
res57: String = else
scala> 'a'.isInstanceOf[Int]
res60: Boolean = false
scala> 'a'.isInstanceOf[Char]
res61: Boolean = true
scala> "a".isInstanceOf[Char]
res62: Boolean = false
scala> "a".isInstanceOf[String]
res63: Boolean = true
scala> Array(1,2,3).isInstanceOf[String]
<console>:12: warning: fruitless type test: a value of type Array[Int] cannot also be a String (the underlying of String)
Array(1,2,3).isInstanceOf[String]
^
res64: Boolean = false
scala> Array(1,2,3).isInstanceOf[Array[Int]]
res65: Boolean = true
scala> Array(1,2,3).isInstanceOf[Int]
res66: Boolean = false
scala> Array(1,2,3).isInstanceOf[Char]
res67: Boolean = false
scala> ArrayBuffer(1,2,3,4).isInstanceOf[Array[Int]]
<console>:15: warning: fruitless type test: a value of type scala.collection.mutable.ArrayBuffer[Int] cannot also be a Array[Int]
ArrayBuffer(1,2,3,4).isInstanceOf[Array[Int]]
^
res70: Boolean = false
scala> ArrayBuffer(1,2,3,4).isInstanceOf[ArrayBuffer[Int]]
res71: Boolean = true
scala> ArrayBuffer(1,2,3,4).isInstanceOf[Int]
res72: Boolean = false
scala> def typemach(x:Any)=x match{case s:String=>"str";case c:Char=>"char";case i:Int=>"int";case m:Map[_,_]=>"Map"; case _=>"else";}
typemach: (x: Any)String
scala> typemach(Map(("age",100),("name","tianyongtao")))
res87: String = Map
匹配数组,列表以及元组
scala> def typemach(x:Array[Int])=x match{case Array(0)=>0;case Array(x,y)=>x+y;case Array(0,_*)=>"0,......";case _=>"else"}
typemach: (x: Array[Int])Any
scala> typemach(Array(0))
res90: Any = 0
scala> typemach(Array(4,6))
res91: Any = 10
scala> typemach(Array(4,6,6,7,8))
res92: Any = else
scala> typemach(Array(0,4,6,6,7,8))
res93: Any = 0,......
scala> def yuanzu(x:Object)=x match{case (1,100,_)=>1;case (50,_)=>2;case _=>"else"}
yuanzu: (x: Object)Any
scala> yuanzu((1,2,3))
res95: Any = else
scala> yuanzu((50,100,1))
res96: Any = else
scala> yuanzu((50,100))
res97: Any = 2
scala> yuanzu((1,100))
res98: Any = else
scala> yuanzu((1,100,80))
res99: Any = 1
变量声明的模式
scala> val (x,y,z)=(Int,Char,String)
<console>:17: error: object java.lang.String is not a value
val (x,y,z)=(Int,Char,String)
^
scala> val (x,y,z)=(Int,Char,Array[Int](10))
x: Int.type = object scala.Int
y: Char.type = object scala.Char
z: Array[Int] = Array(10)
scala> val (x,y)=(100,30)
x: Int = 100
y: Int = 30
/% 返回带商和余数的对偶
scala> val (x,y)=100 /% 30
<console>:16: error: value /% is not a member of Int
val (x,y)=100 /% 30
^
scala> val (x,y)=BigInt(100) /% 30
x: scala.math.BigInt = 3
y: scala.math.BigInt = 10
同样的语法可以用于任何带有变量的模式
scala> arr
res114: Array[Int] = Array(1, 2, 3, 45, 5, 6, 7, 8, 9)
scala> val Array(f,s,t,_*)=arr
f: Int = 1
s: Int = 2
t: Int = 3
for表达式的模式 ??未研究
样例类 ??未研究
copy方法和带名参数
scala> val aa=(1,2,35)
aa: (Int, Int, Int) = (1,2,35)
scala> val bb=aa.copy()
bb: (Int, Int, Int) = (1,2,35)
case 语句中的中置表达式 ??未研究
匹配嵌套结构??未研究
密封类??未研究
模拟枚举??未研究
Option类型
标准类库中的Option类型是用样例类来表示那种可能存在,可能不存在的的值
样例类的子类Some包装了某个值
偏函数
注解 ??