下载
wget https://mirrors.bfsu.edu.cn/apache/spark/spark-3.1.1/spark-3.1.1-bin-hadoop2.7.tgz
解压
tar -vxf spark-3.1.1-bin-hadoop2.7.tgz -C /opt/module/
配置文件改名
cp spark-env.sh.template spark-env.sh
cp workers.template workers
修改配置表
[datalink@slave3 conf]$ vim spark-env.sh
export JAVA_HOME=/usr/java/jdk1.8.0_131
export HADOOP_HOME=/opt/module/hadoop-3.1.4
export SCALA_HOME=/opt/module/scala-2.12.13
export HADOOP_CONF_DIR=/opt/module/hadoop-3.1.4/etc/hadoop
export SPARK_MASTER_HOST=slave2
export SPARK_EXECUTOR_MEMORY=1G
export SPARK_WORKER_CORES=2
export SPARK_WORKER_INSTANCES=1
export SPARK_WORKER_PORT=7078
export SPARK_MASTER_PORT=7077
[datalink@slave3 conf]$ vim workers
slave1
slave3
slave4
修改启动脚本名称
[datalink@slave3 sbin]$ cp start-all.sh start-spark-all.sh
[datalink@slave3 sbin]$ cp stop-all.sh stop-spark-all.sh
分发到其他服务器
scp -r spark-3.1.1-bin-hadoop2.7/ datalink@slave2:/opt/module/
scp -r spark-3.1.1-bin-hadoop2.7/ datalink@slave1:/opt/module/
scp -r spark-3.1.1-bin-hadoop2.7/ datalink@slave2:/opt/module/
scp -r spark-3.1.1-bin-hadoop2.7/ datalink@slave4:/opt/module/
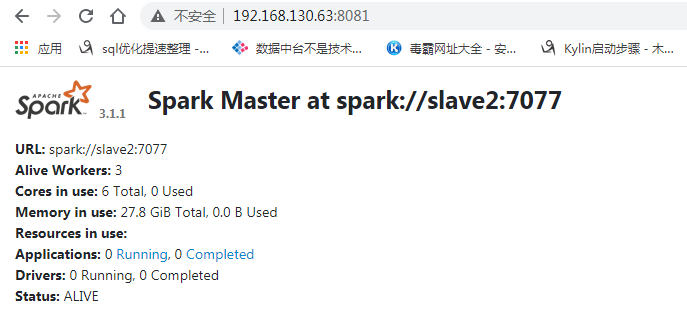
启动
[datalink@slave2 sbin]$ ./start-spark-all.sh
starting org.apache.spark.deploy.master.Master, logging to /opt/module/spark-3.1.1-bin-hadoop2.7/logs/spark-datalink-org.apache.spark.deploy.master.Master-1-slave2.out
slave4: starting org.apache.spark.deploy.worker.Worker, logging to /opt/module/spark-3.1.1-bin-hadoop2.7/logs/spark-datalink-org.apache.spark.deploy.worker.Worker-1-slave4.out
slave3: starting org.apache.spark.deploy.worker.Worker, logging to /opt/module/spark-3.1.1-bin-hadoop2.7/logs/spark-datalink-org.apache.spark.deploy.worker.Worker-1-slave3.out
slave1: starting org.apache.spark.deploy.worker.Worker, logging to /opt/module/spark-3.1.1-bin-hadoop2.7/logs/spark-datalink-org.apache.spark.deploy.worker.Worker-1-slave1.out
[datalink@slave2 sbin]$
sparksql整合hive
Spark SQL主要目的是使得用户可以在Spark上使用SQL,其数据源既可以是RDD,也可以是外部的数据源(比如文本、Hive、Json等)。Spark SQL的其中一个分支就是Spark on Hive,也就是使用Hive中HQL的解析、逻辑执行计划翻译、执行计划优化等逻辑,可以近似认为仅将物理执行计划从MR作业替换成了Spark作业。SparkSql整合hive就是获取hive表中的元数据信息,然后通过SparkSql来操作数据。
将hive-site.xml文件拷贝到Spark的conf目录下,这样就可以通过这个配置文件找到Hive的元数据以及数据存放位置。
[datalink@slave3 conf]$ cp hive-site.xml /opt/module/spark-3.1.1-bin-hadoop2.7/conf/
如果Hive的元数据存放在Mysql中,我们还需要准备好Mysql相关驱动
[datalink@slave3 module]$ cp mysql-connector-java-8.0.23.jar /opt/module/spark-3.1.1-bin-hadoop2.7/jars/
测试sparksql整合hive是否成功
[datalink@slave2 bin]$ ./spark-sql --master spark://slave2:7077 --executor-memory 1g --total-executor-cores 4
.....................
spark-sql (default)> show databases;
namespace
default
testdb
zqgamedb
Time taken: 3.768 seconds, Fetched 3 row(s)
sparksql与hive 对比,差距明显:
spark-sql (default)> select count(1) from fact_login;
count(1)
8529410
Time taken: 1.798 seconds, Fetched 1 row(s)
hive (zqgamedb)> select count(1) from fact_login;
...........................
8529410
Time taken: 46.151 seconds, Fetched: 1 row(s)