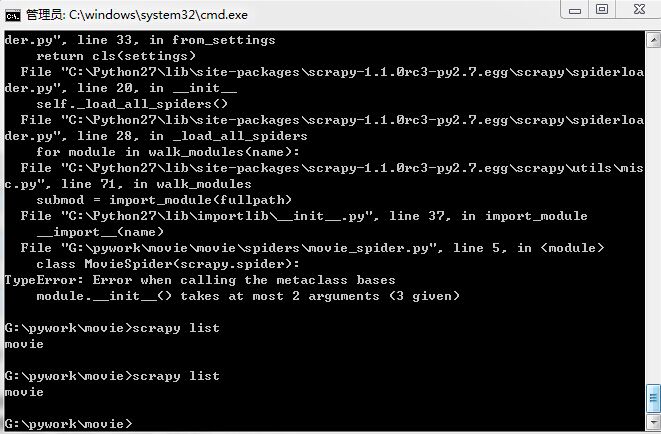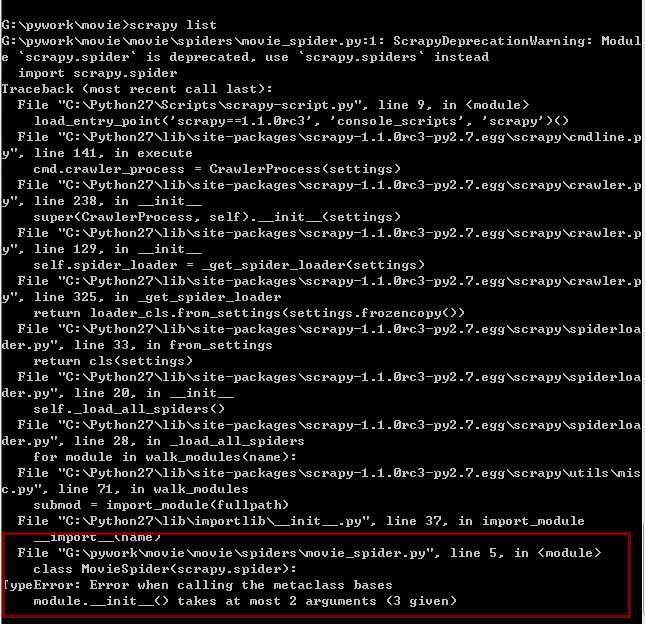
如图中所标出的,提示参数的问题
解决办法:
spider目录下的 爬虫文件内容做些更改:
出现报错的文件内容:
from scrapy.spider
from scrapy.selector import HtmlXPathSelector
class MovieSpider(scrapy.spider):
name="movie"
# allowed_domains=["loldytt.com"]
start_urls=[
"http://www.loldytt.com/"
"http://www.loldytt.com/Xijudianying/"
]
def parse(self,response):
html=HtmlXpathSelector(response)
page=html.select('//ul/li')
for cc in page:
filename=cc.select('a/text()').extract
link=cc.select('a/@href').extract
print filename,link
修改后的文件内容:
from scrapy.spiders import Spider
from scrapy.selector import HtmlXPathSelector
class MovieSpider(Spider):
name="movie"
# allowed_domains=["loldytt.com"]
start_urls=[
"http://www.loldytt.com/"
"http://www.loldytt.com/Xijudianying/"
]
def parse(self,response):
html=HtmlXpathSelector(response)
page=html.select('//ul/li')
for cc in page:
filename=cc.select('a/text()').extract
link=cc.select('a/@href').extract
print filename,link
之后运行 就OK了: