生成器
先从列表生成式说起
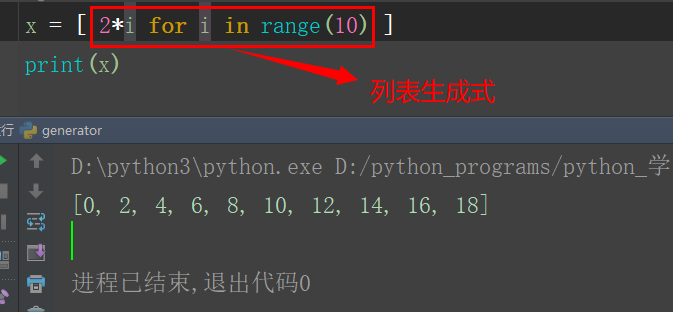
可以通过简单的式子,生成有规律的列表
如果把 [ ] 换为 ( ) 会发生什么呢?
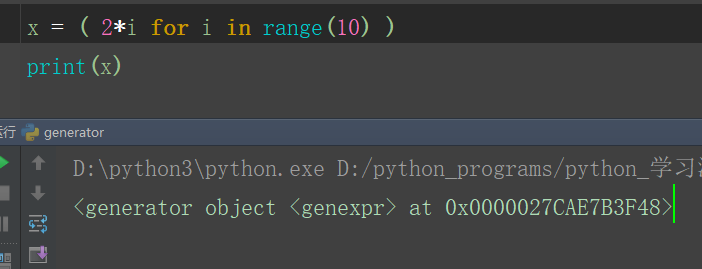
看到 x 存的不再是列表,而是一个地址,而这个地址就是我们的生成器对象的地址
这东西有什么用呢? 当然时,节省内存啦
假设现在有很庞大的一组数据要处理,貌似不可能把它一次性载入内存再进行处理,这时候就体现出了生成器的好处,因为它只占用一个数据的内存空间,当需要访问下一个
数据时,当前的数据会被覆盖掉,所以有多少数据都无所谓啦,都是可以处理的。可以通过 next() 或 __next__() 方法访问下一个数据。

当然还是要借助循环来进行对元素的访问,100w个数据不可能敲一百万个 next() 吧。

当然如果这些数据不能用表达式表示怎么办?答案就是用函数 + yield 关键字,有yield关键字的函数就是一个生成器。
来个栗子(打印斐波那契数列):
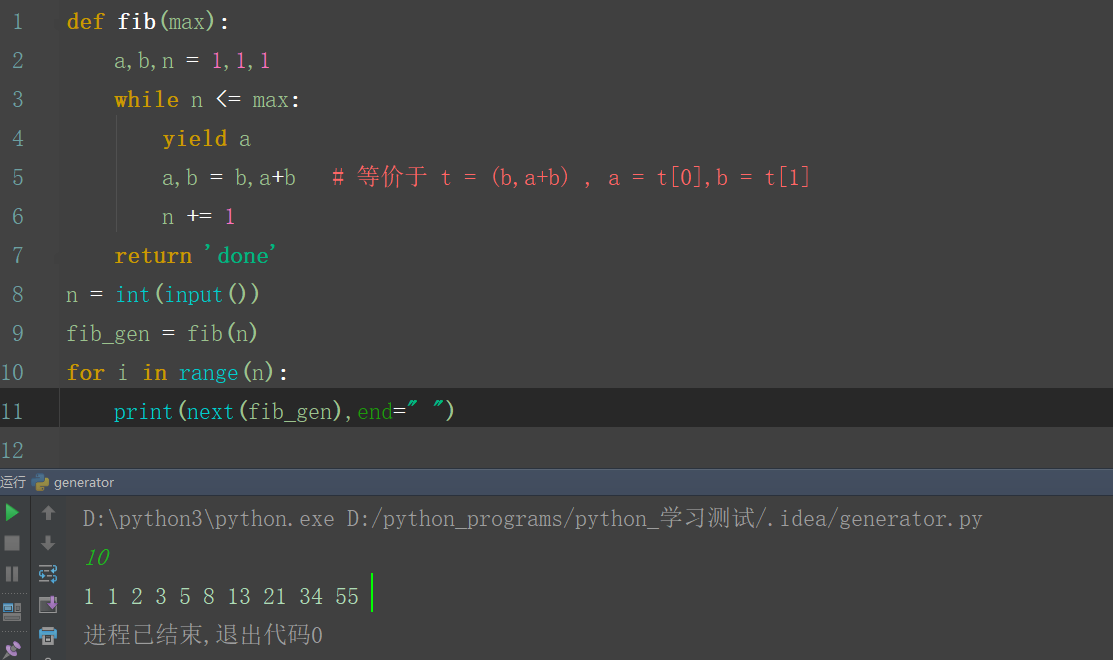
yield a 可以理解为返回一个a,但会记下当前代码的位置,下次将从yield a 的下一句开始执行代码。拿这段代码来说,从最后的循环说起。
1.next() 方法启动生成器,生成器要执行一次
2.程序进入wile循环
3.遇到yield a 返回a值并几下断点
4.for 循环的print语句受到a的值打印a=1
5.for继续循环,有调用了next()方法,生成器再次启动
6.生成器找到上次断点的位置执行代码(a,b = b,a+b)...
7.再次遇到yield语句,回到步骤 3
......
除了 next()方法 ,send ( )也可以启动生成器,但是send可以给生成器传值,而这个值将强制替换上次断点的处的返回值
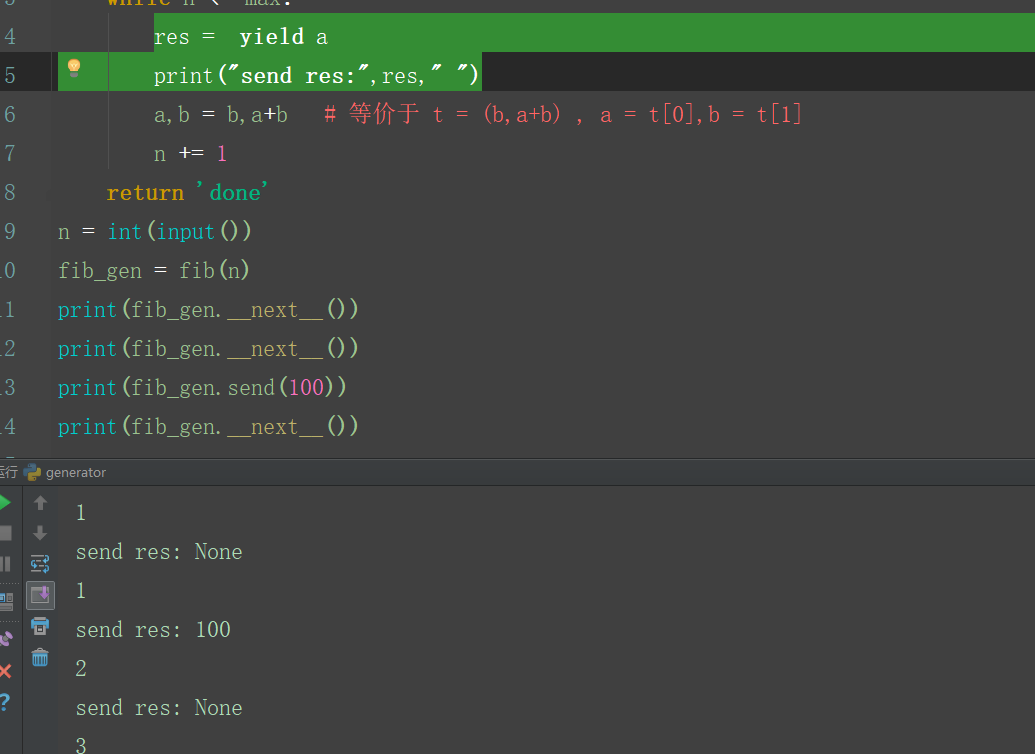
看到 send 传入的参数替换的是 res 的值,而不是 a 的值!!!,至于为什么会打印 ‘None’ 其实 next 默认传入一个 None 所以一调用 next() 就会打印 None,而调用 send 则
打印 sned 传入的参数。
最后来一个经典的生产者消费者问题吧
1 import time 2 def consumer(name): 3 print("%s is ready to consume" % name) 4 while True: 5 res = yield 6 print("%s has consumed goods %d" % (name,res)) 7 def producer(name): 8 print("%s is ready to produce" % name) 9 while True: 10 time.sleep(3) 11 succ = yield 12 print("produce goods %d and goods %d successfully" % (succ,succ+1)) 13 c1 = consumer('c1') 14 c2 = consumer('c2') 15 c1.__next__() 16 c2.__next__() 17 p1 = producer('p1') 18 p1.__next__() 19 for i in range(10): 20 p1.send(i+1) 21 c1.send(i+1) 22 c2.send(i+2)