我们遇到了一次在下午 17:30 开始到晚上 23:00 期间 MySQL 存储空间稳定下降最终导致 MySQL 可用空间使用完
可用空间监控图展示为
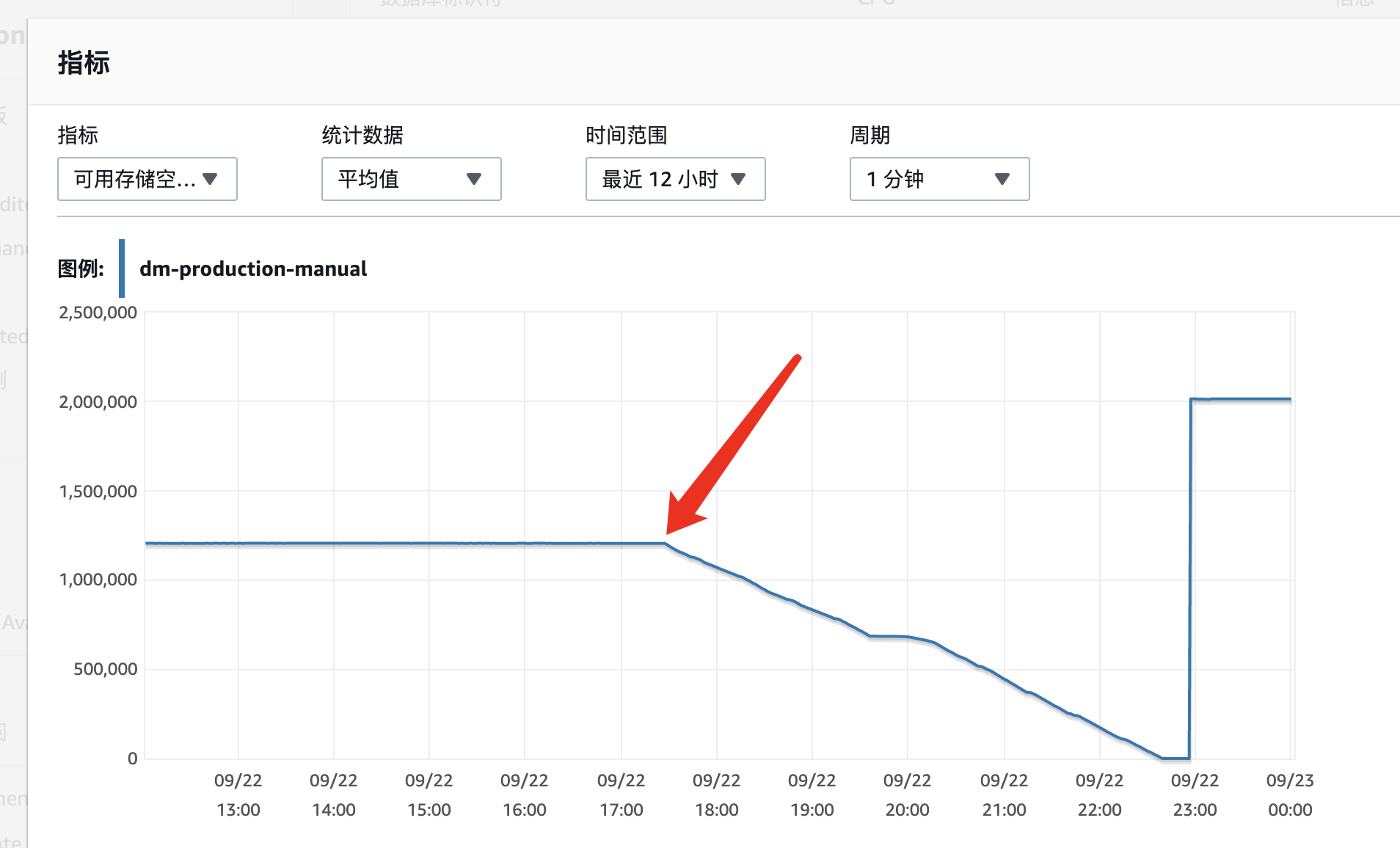
可以看到从 17:00 开始存储空间开始线性下降直至最后 1TB 空间被完全使用完。
当时查找问题时候的第一反应是不是有什么程序起起来周期性写入某个数据表,最后把表写爆导致了这个问题。所以想起来先看看 MySQL 的 binlog。但是比较遗憾的是我们机器的 MySQL 配置几乎没有什么优化和修改,
所以 binlog 的默认存储大小是在 500 M 左右滚动,单个切分文件大小是 128M 我找了一下 aws 似乎没有能设置 max-size 的地方,官方文档也只写了 aws 会尽快删除和将 binlog 文件进行滚动。实际上它也是这么做的,一边增加
滚动,然后删除。设置单个文件 128M 并使得总的 binlog 文件维持在 500M 左右。
因为我们的 binlog 被大量数据冲掉了,发现的时候已经无法通过 binlog 回溯当时是否有大批量不符合预期的 insert 语句插入数据表。
于是我们换了一个方法,直接扫描数据表的 information_schema.table 和 直接对一些表进行 count 查询。以确定是否有大量不符合预期的数据被写入数据库,结果都完全没有发现有任何异常。
平白无故多出 1TB 数据却在数据库表里无法体现?
非常奇怪的情况,于是重新去找了一下数据库的 error.log 信息仔细看了一下得到以下信息
1 2020-09-22T14:39:43.466320Z 26855093 [ERROR] InnoDB: posix_fallocate(): Failed to preallocate data for file /rdsdbdata/db/innodb/ibtmp1, desired size 67108864 bytes. Operating system error number 28. Check that the disk is not full or a disk quota exceeded. Make sure the file system supports this function. Some operating system error numbers are described at http://dev.mysql.com/doc/refman/5.7/en/ operating-system-error-codes.html 2 2020-09-22T14:39:43.517029Z 26869328 [ERROR] Disk is full writing '/rdsdbdata/log/binlog/mysql-bin-changelog.672430' (Errcode: 15885504 - No space left on device). Waiting for someone to free space... 3 2020-09-22T14:39:43.517726Z 26869328 [ERROR] Retry in 60 secs. Message reprinted in 600 secs 4 2020-09-22T14:39:43.617317Z 26855093 [Warning] InnoDB: 1048576 bytes should have been written. Only 176128 bytes written. Retrying for the remaining bytes. 5 2020-09-22T14:39:43.617364Z 26855093 [Warning] InnoDB: Retry attempts for writing partial data failed. 6 2020-09-22T14:39:43.617370Z 26855093 [ERROR] InnoDB: Write to file /rdsdbdata/db/innodb/ibtmp1failed at offset 1283732799488, 1048576 bytes should have been written, only 176128 were written. Operating system error number 28. Check that your OS and file system support files of this size. Check also that the disk is not full or a disk quota exceeded. 7 2020-09-22T14:39:43.617387Z 26855093 [ERROR] InnoDB: Error number 28 means 'No space left on device' 8 2020-09-22T14:39:43.617391Z 26855093 [Note] InnoDB: Some operating system error numbers are described at http://dev.mysql.com/doc/refman/5.7/en/operating-system-error-codes.html 9 2020-09-22T14:39:43.617403Z 26855093 [Warning] InnoDB: Error while writing 67108864 zeroes to /rdsdbdata/db/innodb/ibtmp1 starting at offset 1283670933504 10 2020-09-22T14:39:43.617444Z 26855093 [ERROR] /rdsdbbin/mysql/bin/mysqld: The table '/rdsdbdata/tmp/#sql_2111_1' is full 11 2020-09-22T14:39:43.617482Z 26854253 [ERROR] InnoDB: posix_fallocate(): Failed to preallocate data for file /rdsdbdata/db/innodb/ibtmp1, desired size 5066752 bytes. Operating system error number 28. Check that the disk is not full or a disk quota exceeded. Make sure the file system supports this function. Some operating system error numbers are described at http://dev.mysql.com/doc/refman/5.7/en/ operating-system-error-codes.html 12 2020-09-22T14:39:43.617658Z 26854253 [Warning] InnoDB: Retry attempts for writing partial data failed. 13 2020-09-22T14:39:43.617670Z 26854253 [Warning] InnoDB: Error while writing 5066752 zeroes to /rdsdbdata/db/innodb/ibtmp1 starting at offset 1283732975616 14 2020-09-22T14:39:43.617689Z 26854253 [ERROR] /rdsdbbin/mysql/bin/mysqld: The table '/rdsdbdata/tmp/#sql_2111_0' is full15 2020-09-22T14:43:24.521888Z 0 [Note] InnoDB: page_cleaner: 1000ms intended loop took 4087ms. The settings might not be optimal. (flushed=20002020-09-22T14:57:43.521368Z 26870123 [Note] Aborted connection 26870123 (Got an error reading communication packets)
可以注意到第6行
6 2020-09-22T14:39:43.617370Z 26855093 [ERROR] InnoDB: Write to file /rdsdbdata/db/innodb/ibtmp1failed at offset 1283732799488, 1048576 bytes should have been written, only 176128 were written. Operating system error number 28. Check that your OS and file system support files of this size. Check also that the disk is not full or a disk quota exceeded.
临时表存储文件 ibtmp1 的偏移量高达 1283732799488kb => 1195gb 这不正好一个 t 吗
看这个文件 ibtmp1 是和临时表相关的,马上反应过来是不是其实根本不是数据插入了,而是 join 创建临时表过大导致的上述情况。
很明显完全有可能在最后存储耗尽存储之后挂掉,然后被写入 slow query 里面。
于是查找了挂掉时候的 slow_query.log 找到了这条执行了上万 s 的自链接语句。
# Query_time: 19010.513418 Lock_time: 0.000048 Rows_sent: 0 Rows_examined: 876574
select f1.CreatorChannelId, f1.tweets, f1.createdAt, f2.updatedAt from xx f1, xx f2 where f1.createdAt != f2.createdAt ORDER BY updatedAt DESC limit 200;
问题很明显了 xx 这个表是一个上千万的大表。由于 createdAt 的时间有太多的不同,所以满足这个条件的情况就会非常多,是一个很大很大的笛卡尔积。
由于我们 MySQL 没有设置查询语句超时时间,导致该语句需要的空间无限膨胀最终击穿了我们的可用存储。
High Light 那么最后总结一下,供参考:
〇 在线上环境执行的 SQL,还是需要非常非常非常谨慎,包括通过 client 执行的错误查询语句 cancel 掉之后需要仔细检查是否真的已经被杀掉。
〇 考虑是否可以限制 ibtmp1 的大小,也就是设定 innodb_temp_data_file_path 的最大值来防止过度膨胀。
〇 也可以设置 MySQL 的超时时间来避免这种超长时间无法结束的语句一直执行消耗资源。
〇 做好监控和及时响应,这次最让人意外的就是主数据库存储资源一直降低却最终无人发现,最后挂了才发现引发了线上的 P0 故障。稍微有一个环节做得再好一些都不至于如此。
〇 所以一个系统有太多的问题一直拖延不解决,最终总是会以非常极端的事件进行反馈,这大概就是技术债吧。
Reference:
http://blog.itpub.net/29773961/viewspace-2142197/ 【MySQL】一条SQL使磁盘暴涨并导致MySQL Crash
https://zhuanlan.zhihu.com/p/82554609 从MySQL的ibtmp1文件太大说起