前面介绍了文件通道的读写操作,其中用到字节缓存ByteBuffer,它是位于通道内部的存储空间,也是通道唯一可用的存储形式。ByteBuffer有两种构建方式,一种是调用静态方法wrap,根据输入的字节数组生成对应的缓存对象;另一种是调用静态方法allocateDirect,根据输入的数值分配指定大小的空缓存。字节缓存又是一种特殊的存储空间,因为它可能会被多次读写,所以为了有效地控制读写操作,Java给它设计了下列五种概念:容量、当前限制量、当前位置、本次剩余空间、标记位置,分别说明如下:
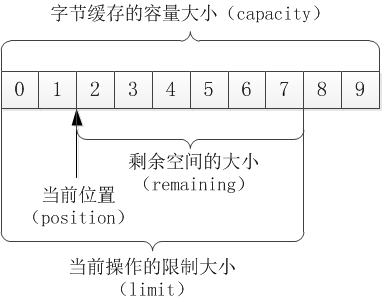
1、容量(capacity):指的是字节缓存的整个长度。容量大小可通过缓存对象的capacity方法获得。
2、当前限制量(limit):指的是当前读写操作所能处理的最大空间大小。当前限制量可通过缓存对象的limit方法获得(不带输入参数),携带输入参数的limit方法用来设置当前限制量的数值。如果不设置当前限制量的大小,则limit数值默认为字节缓存的容量大小。
3、当前位置(position):指的是字节缓存当前操作的起始位置。当前位置可通过缓存对象的position方法获得(不带输入参数),携带输入参数的position方法用来设置当前位置的数值。字节缓存一开始的当前位置是0,每次进行读写操作位置之后,当前位置都会往后跟着挪动。
4、本次剩余空间(remaining):它的数值等于当前限制量减去当前位置(即limit-position)。本次剩余空间可通过缓存对象的remaining方法获得。
5、标记位置(mark):其概念类似缓存输入流的标记,同样是调用mark方法在当前位置做个标记,以便后续调用reset方法能够回到上次标记的位置。
举个例子,现在分配了一个容量大小为10的字节缓存,并且设置它的当前限制量为8,接着将当前位置移到第三个字节处(下标为2),那么该字节缓存的存储结构应当如下图所示。
搞清楚了字节缓存的内部结构,再来看与字节缓存有关的数据流向。字节缓存与磁盘文件之间通过文件通道FileChannel交互,与内存字符串之间通过字节数组byte[]交互,于是内存中的一个字符串想要与磁盘上的某个文件内容相互转换的话,就存在以下两种数据流转过程:
1、把字符串写入文件,此时数据流向为:字符串String→字节数组byte[]→字节缓存ByteBuffer→指定路径的文件。
2、把文件内容读到字符串,此时数据流向为:指定路径的文件→字节缓存ByteBuffer→字节数组byte[]→字符串String。
其中与字节缓存有关的读写操作又可拆分为下列四种方法调用:
1、字节数组byte[]→字节缓存ByteBuffer,该操作除了调用ByteBuffer的静态方法wrap之外,还能通过缓存对象的put方法往字节缓存写入字节数组。
2、字节缓存ByteBuffer→指定路径的文件,该操作需要调用通道对象的write方法,往磁盘文件写入字节缓存中的数据。
3、指定路径的文件→字节缓存ByteBuffer,该操作需要调用通道对象的read方法,把磁盘文件中的数据读到字节缓存。
4、字节缓存ByteBuffer→字节数组byte[],该操作需要通过缓存对象的get方法,把字节缓存中的数据取到字节数组。
详细的数据流转过程可见下图,其中动作①和动作②实现了将字符串写入文件的功能,动作③和动作④实现了将文件内容读到字符串的功能。
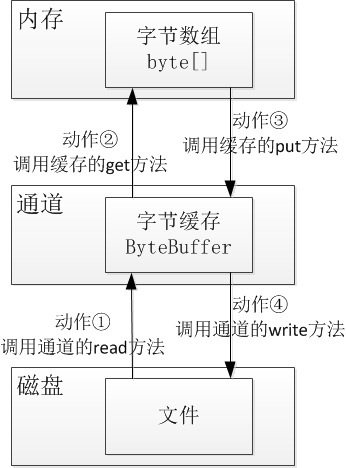
注意到上图的动作①与动作③都是把数据输入给字节缓存,因此这两个动作可视为对字节缓存的写操作。而动作②与动作④都是从字节缓存中取出数据,因此这两个动作可视为对字节缓存的读操作。那么反复读写可能产生不同的处理需求,比如把当前位置挪回字节缓存的开头,接下来是要写入数据还是读出数据,为此ByteBuffer又提供了下列四个方法:
clear:缓冲区数据写入通道之后,如果还想把新数据写入缓冲区,就要先调用clear方法清空它。
compact:只清除已经读过的数据,剩余的未读数据会移到缓冲区开头,新增的数据将加到未读数据后面。
flip:把缓冲区从写模式切换到读模式。从缓冲区读取数据之前,必须先调用flip方法。
rewind:让缓冲区的指针回到开头,以便重新再来一遍。
上面的四个方法在部分功能上互有异同点,为了更好地梳理它们之间的区别,下面整理了一个表格,说明每个方法在调用之后将会引起哪些参数的变化。
position limit mark
clear 0 容量大小 -1
compact 0 容量大小 -1
flip 0 上次的当前位置 -1
rewind 0 保持不变 -1
就具体的代码逻辑而言,一般在写入字节缓存之前(上图的动作①与动作③),需要先调用compact方法;在读取字节缓存之前(上图的动作②与动作④),需要先调用flip方法。当然如果是创建字节缓存后的第一次操作,就不必调用compact方法或者flip方法,因为在一开始字节缓存的当前位置都是指向0,无需再将当前位置挪回缓存开头了。回头看上一篇文章末尾通过文件通道读取文件的代码片段:
int size = (int) channel.size(); // 获取文件通道的大小(即文件长度) // 分配指定大小的字节缓存 ByteBuffer buffer = ByteBuffer.allocateDirect(size); channel.read(buffer); // 把文件通道中的数据读到字节缓存 buffer.flip(); // 把缓冲区从写模式切换到读模式。从缓冲区读取数据之前,必须先调用flip方法 byte[] bytes = new byte[size]; // 创建与文件大小相同长度的字节数组 buffer.get(bytes); // 把字节缓存中的数据取到字节数组
根据前面的文字介绍,能够很好地解释以上代码的方法调用次序。由于通道对象的read方法是创建字节缓存之后的首个读写操作,因此无需先调用compact方法;而缓存对象的get方法不是首个读写操作,就必须在get之前先调用flip方法了。
更多Java技术文章参见《Java开发笔记(序)章节目录》