结对编程——马尔科夫链
需求分析
- 仅考虑英文输入输出
- 从文件读入待”学习“文章
- 能处理标点符号(参考材料中有说明)
- 能控制输出文章的篇幅
- 通过参数指定输出的单词数
- 误差控制
- 生成的语句要能完整结束(比如遇到句号、问号、感叹号等结束标志)。
- 为了能实现上述条件,允许输出的单词数量误差 ±50。
- 避免环
- 程序执行效率分析
- 读入文章耗费多少时间(毫秒), 附上读入文章篇幅(单词数)
- “学习”(分析)文章耗费多长时间(毫秒)
- 输出一篇文章耗费的时间(毫秒), 附上输出文章篇幅(单词数)
设计思路
- 读取文章。
因为文章篇幅较小(500k左右),所以考虑直接读入内存。 - 学习文章。
上下文分析,因为上下文结构本身可以抽象为Key-Value对,所以使用轻量级数据库SQLite进行存储。这里介绍一下split的细节,因为在文章中存在" ",多个空格等分隔单词的情况,所以split的参数就不能简单地使用空格了,因为split是支持正则表达式的,所以可以使用text.split("\s+")来形成单词数组。
String[] wordList = text.split("\s+");
一开始为了减少内存占用,采取的是每次插入一条record就建立一次connection,后来发现这样速度太慢了,一共需要差不多200s才能完成上下文分析,所以改成全部分析完成后,再全部批量插入SQLite忠,采用这种方案,减少了数据库连接的I/O开销,速度快了100多倍,1000ms左右就能完成全部的分析和持久化。
可是当需要学习的数据量加大,我现在采用的这种方法就不再适用,一旦有了GB级别的文本分析数据,就极有可能导致OOM,当然,到了这个级别,就可以直接使用大型并且灵活的NoSQL数据库进行持久化了。但是只考虑程序中的操作,我的想法是对文本数据进行分片,每个chunk为1024KB,每个chunk建立一个数据库连接,兼顾时间复杂度和空间复杂度。
其实大型的文本分析应用还是挺多的,我暑假就有个在GB级别的服务器日志中分析恶意流量的项目,我现在的想法就是对日志文件进行分片成每个100MB的block,这个时候就可以用几台机器做分布式了,master机做block的分发和任务调控,然后每台slave机再用类似于上面的方法在程序中分成更小的chunk分析。
3. 生成文本。
文本生成的部分还是相对比较简单的,我采用的是先设置一个最为一般的初始值"It is",用这两个单词作为每次生成文本的初始值,当然也可以使用其他的常用初始值作为开头。然后在数据库中执行:
SELECT * FROM MARKOV WHERE BEFORE="It is";
将结果存储到一个ArrayList中,使用
return afterLst.get((int)(Math.random()* afterLst.size()));
返回一个随机的结果,用这种方法就不用再另外存储各个单词的出现概率了。
为了控制篇幅,我使用了while判断来进行。
while ((wordLst.size() < Integer.parseInt(args[1]) - 50 || before.charAt(before.length()-1)!='.') && wordLst.size() < Integer.parseInt(args[1]) + 50)
有三个条件,当总单词数满足比规定值低50的时候,或者这时候一句话还没说完(最后一个字符不为"."),那就让程序接着生成文本,一旦总次数超过规定值+50,就让程序强行停止。
数据结构
这次的数据结构比较简单,主要就是对上下文的存储。因为直接采用数据库持久化了,所以也没有难的技术细节,就是两个字段,一个是before,一个是after,分别存前两个单词和最后一个单词。如果是存在内存中的话,可以考虑
HashMap<String,String>
来作为上下文的数据结构
如何避免环
这个问题确实很棘手,但是我个人认为实际意义不大,因为在题目给出的生成100个单词左右的规模中,给了10000词的样本集,所以出现小环的可能性是非常小的,然后100词的规模又决定了不会出现大环,如果生成的文本量变多,这时候环的检测会大幅度提升时间复杂度和空间复杂度,如果要大规模生成文本,与其检查是否成环,还不如扩大样本集,因为成环就是因为样本空间太小导致的。
所以就这个应用场景而言,出于用户体验的考虑,我没有把环的检测应用在代码中。但是我还是讲一下我的思路。我考虑的是把每个不同的单词分别作为一个有向图的节点,上下文的关系就是路径,然后每生成一个单词,保存当前状态,检查一遍有没有那个节点通过同一条路径回到原点两次,如果有,就回溯到第一次回到原点的状态,重新生成。所以我这种算法,不管是时间复杂度还是空间复杂度都非常高。
UML类图
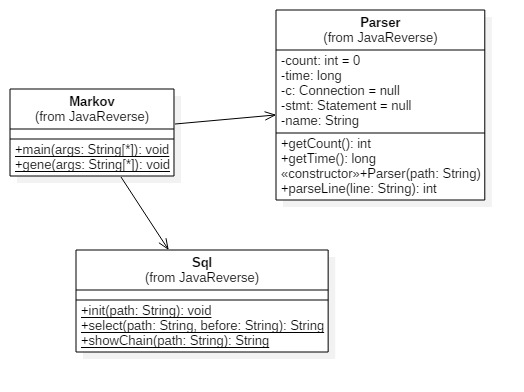
实现过程中的关键代码解释
调用select方法,生成下一个单词
while ((wordLst.size() < Integer.parseInt(args[1]) - 50 || before.charAt(before.length()-1)!='.') && wordLst.size() < Integer.parseInt(args[1]) + 50){
String temp = Sql.select(args[0],before);
wordLst.add(temp);
before = before.split(" ")[1] +" "+ temp;
content.append(" " + temp);
}
下面是select方法,在数据库中根据上文,随机返回一个下文
public static String select(String path,String before){
Connection c = null;
Statement stmt = null;
ArrayList<String> afterLst = new ArrayList<String>();
try {
Class.forName("org.sqlite.JDBC");
c = DriverManager.getConnection(String.format("jdbc:sqlite:%s.db",path));
c.setAutoCommit(false);
stmt = c.createStatement();
String sql = "SELECT * FROM MARKOV WHERE BEFORE="" + before + "";";
ResultSet rs = stmt.executeQuery(sql);
while ( rs.next()) {
String after = rs.getString("AFTER");
afterLst.add(after);
}
rs.close();
stmt.close();
c.close();
} catch ( Exception e ) {
e.printStackTrace();
System.exit(0);
}
return afterLst.get((int)(Math.random()* afterLst.size()));
}
读取文件,并调用parseText方法,解析和持久化结果
InputStreamReader read = new InputStreamReader(new FileInputStream(f));
BufferedReader bufferedReader = new BufferedReader(read);
String lineTxt = null;
StringBuffer text = new StringBuffer();
while ((lineTxt = bufferedReader.readLine()) != null) {
text.append(lineTxt + " ");
}
count += parseText(text.toString());
c.commit();
c.close();
read.close();
遇到的困难及解决方法
这次的结对编程作业,我觉得还是比四则运算要简单的(如果不考虑检测环的话)。比较大的困难就在于提高数据库的存储速度,经过优化,让数据库只建立一次连接,减少I/O开销,很大地提高了速度。
代码链接
结对伙伴评价
希望结对伙伴能够做中学,积极主动敲代码。
碰到问题多百度。
PSP
| PSP2.1 | Personal Software Process Stages | 预估耗时(小时) | 实际耗时(小时) |
|---|---|---|---|
| Planning | 计划 | 0.5 | 0.5 |
| Estimate | · 估计这个任务需要多少时间 | 0.5 | 1 |
| Development | 开发 | 11 | 11.5 |
| · Analysis | ·需求分析 (包括学习新技术) | 1.5 | 1 |
| · Design Spec | ·生成设计文档 | 0.5 | 0.5 |
| Design Review | ·设计复审 (和同事审核设计文档) | 1 | 0.5 |
| · Coding Standard | ·代码规范 (为目前的开发制定合适的规范) | 1 | 0.5 |
| · Design | · 具体设计 | 2 | 1.5 |
| · Coding | · 具体编码 | 2 | 4 |
| · Code Review | · 代码复审 | 1 | 1 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 2 | 2.5 |
| Reporting | 报告 | 2 | 2 |
| · Test Report | · 测试报告 | 0.5 | 0.5 |
| · Size Measurement | · 计算工作量 | 0.5 | 0.5 |
| · Postmortem & Process Improvement Plan | ·事后总结, 并提出过程改进计划 | 1 | 1 |
| 合计 | 13.5 | 14 |