微信公众号:内核小王子
关注可了解更多关于数据库,JVM内核相关的知识;
如果你有任何疑问也可以加我pigpdong[^1]
拜占庭将军问题
在存在消息丢失的不可信信道上通过消息传递的方式得到一致性是不可能的
由于当时拜占庭帝国国土辽阔,为了防御目的,每个军队都分隔很远,将军和将军之间只能靠信差来通信,但是军队内可能存在间谍和叛徒,那么如何在已知有叛徒的情况下,在其他忠诚的将军之间达成一致性协定。映射到网络问题,例如网络被劫持,网络不可达等
CAP
一个分布式系统中,最多只能同时满足一致性,可用性,分区容忍性

- 一致性(Consistance)
一致性是指,all nodes see the same data at same time,怎么理解这句话? 假设在一个有N个节点的集群环境下,同一时刻访问不同的节点的同一个数据,返回的值应该一样.
例如一个写请求发送到节点A将值从5改为6,在写操作之前假设所有节点上的数据都是5,那么当节点A把值从5改为6之后,还需要把这个操作同步到其他的节点,直到其他节点都同步成功后,才能返回客户端写成功,并且在这个过程中节点如果已经修改为6的值不能被外界看到.
- 可用性 (Availablity)
可用性是指 read and write always succeed.是指服务永远可以响应客户端的请求,这个也是在集群环境下,当一个节点不可用的时候,可以将请求发到其他节点上,一个节点不可用不一定是因为宕机,网络不通等原因,也有可能是这个节点的数据没有复制全.当然狭义上的可用性也可以指代请求响应时间,在现在高并发的环境下,如果一个请求的响应时间太长,一方面影响用户体验倒置不可用,另一方面由于响应时间太长倒置QPS太低,当客户端大量请求打过来的时候会将服务端打垮倒置机器不可用.
在一个分布式系统中,上下游系统任何一个节点出故障都可能倒置整个系统不可用,像数据库,负载均衡,缓存,微服务中的某一个服务,所以分布式系统在满足高可用的需求上需要进行弹性设计,即可以支持服务降级,限流,以及监控等.
- 分区容忍性
分区容忍性是指 the system continue to operate despite arbitrary message loss or failure of part of the system, 也就是说当网络存在丢包和某几个节点网络不可达的情况下,整个服务集群可以继续保持可用,operate是经营,管理的意思,despite是尽管的意思,arbitrary是随意的意思.
在分布式系统中,只有多个节点才能保证一个节点挂了另外一个节点可以顶上来实现高可用,不能存在单点,而为了满足高可用必须保证每个节点上都有完整的数据,也就是需要各个节点之间需要进行数据复制,这个复制操作只能通过网络,而网络环境是不稳定的,光纤被挖,机房断电,操作员失误等是机器无法预料的,当网络的不可靠就可能引起数据不同步,数据不同步就会导致节点不可用,所以在现代软件架构中,会在三者之间做一个权衡,例如对一致性,可以放低要求做到弱一致性,就是运行中间短暂的数据不一致,而最终数据还是一致的,所以出来了一个变种就是BASE.
basic avalilablity,基本可用意味着系统可以出现短暂的不可用,后面会恢复,Soft-state 软状态,是在有状态和无状态之间的一种中间态,运行应用短暂的保存一小部分数据和状态.Eventual Consistency 最终一致性,系统在一个短暂的时间段内是不一致的,但最终会恢复一致.
2PC
两阶段提交Two Phase Commit,一阶段,协调者发起prepare操作,参与者将操作结果同步给协调者,二阶段 由协调者根据上一阶段操作的结果,决定提交还是回滚.也就是所有参与者都返回成功就提交,有一个参与者返回失败就回滚.
该协议比较简单,我们对照下图进行理解,就不在具体分析过程了.
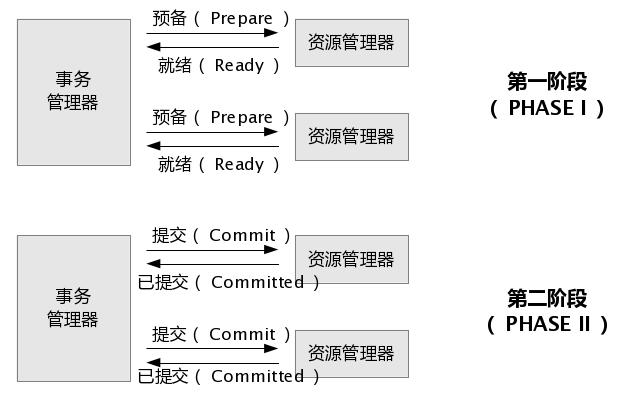
两阶段提交有以下缺点
-
1.单点故障 一旦协调者发生故障,那么事物的其他参与者会一直阻塞下去,尤其在第二阶段,由于一阶段已经将资源锁定,协调者可以设计为分布式集群部署,当master节点宕机,可以重新选举一个master,但是协调者就需要将参与者的返回结果状态进行持久化,并且和其他协调者进行同步,这个过程又会涉及新的一致性问题.
-
2.同步阻塞问题,阻塞周期长,当第一个参与者锁定资源后需要等到阶段2提交后才会释放资源
-
3.可能出现数据不一致,当协调者发出commit后,某一个参与者由于网络原因没有收到,而其他参与者已经commit,于是出现数据不一致
基于两阶段提交的缺陷,后来提出了三阶段提交的方案,就是在2pc的基础上增加了一个CanCommit的询问动作,这一步可以保证后续的commit操作大概率会成功,例如从用户账户扣50块钱,而canCommit询问的时候发现账户只有40,就会直接返回不可以提交,提高成功率,同时减少了锁定资源的时间,但是3PC并没有解决2PC的问题
当然三阶段也设置了超时时间,二阶段只有协调中的请求会有超时时间.
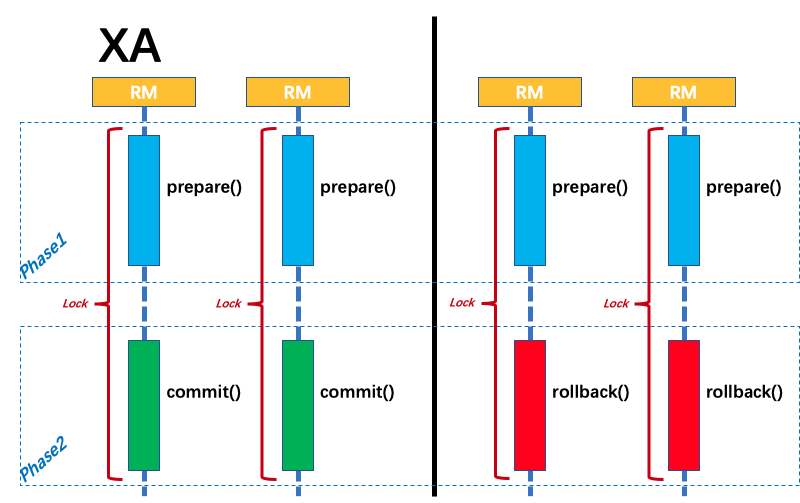
XA
X/OPEN 组织定义了一套分布式事物处理模型,也就是Distributed Trasaction Processing Reference Model 简称DTP模型,并定义了两套协议,分别是XA,TX
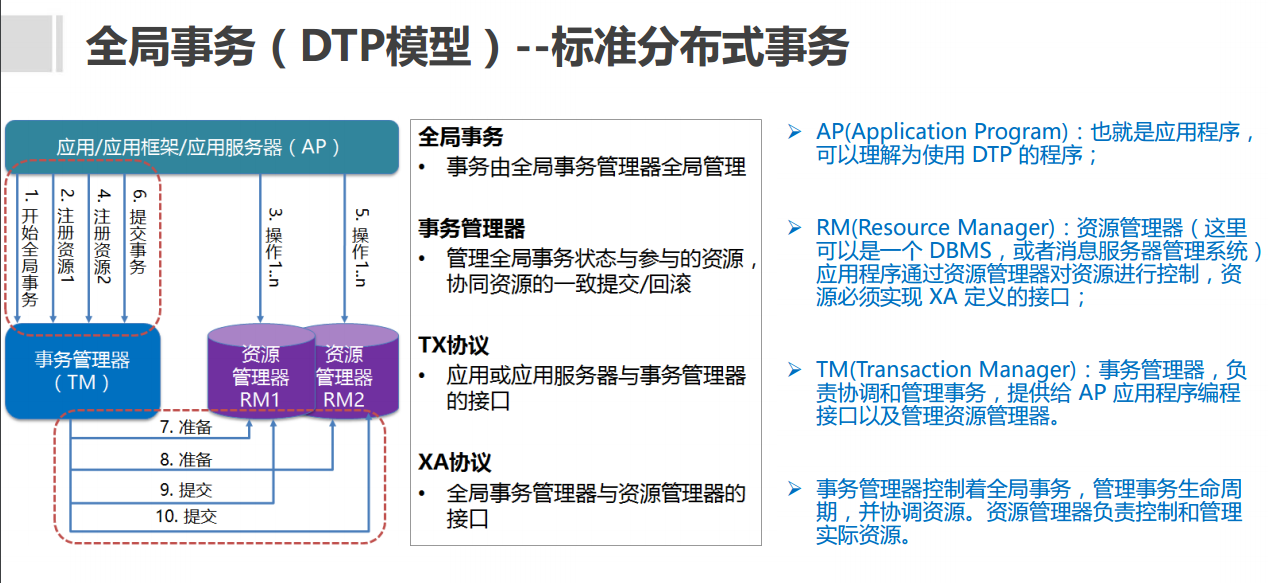
从上图可以看出,DTP使用了两阶段提交协议,并提出了RM,AP,TM的概念,目前mysql的innodb有对XA的支持,spring也封装了XA相关的接口,但是XA存在两阶段提交相关问题,所以目前在互联网公司高并发的场景下并没有太普及.
业务补偿
在分布式环境下,由于在大多数情况下我们无法做到强一致性的ACID,特别是我们的系统跨越多个系统,而且有些系统可能还需要调用其他公司的服务,我们要保证一个事物全部执行成功,要么全部回滚,在哪些场景需要回滚,哪些场景不需要回滚可能会和业务强相关.
业务补偿的设计,就是业务正常执行,当遇到某个分支场景不可用的时候就启用回滚流程,将之前的流程进行逆向操作.我们用客户购买理财产品的例子,第一步 下订单,第二步,扣产品份额,第三步,支付.第四部给用户加持仓,第五步将订单状态改为成功.
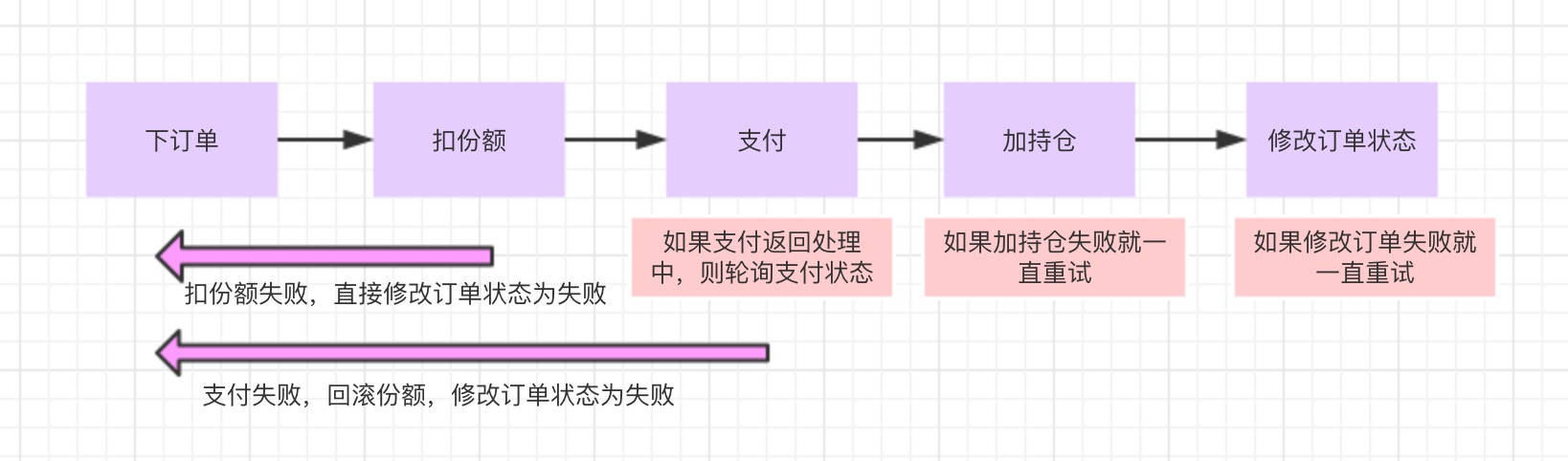
- 1.扣份额失败则直接修改订单状态为失败
- 2.如果支付失败,则回滚产品份额,修改订单状态为失败
- 3.如果加持仓失败就一直重试
- 4.如果修改订单状态失败就一直重试
- 5.如果支付返回处理中就不停轮询支付状态直到有确定结果
根据以上流程我们可以总结下采用补偿方案的设计重点
- 1.可以采用工作量引擎进行业务补偿操作
- 2.业务服务需要支持重试
- 3.业务服务要幂等
- 4.业务服务要提高回滚接口,如上面的回滚标的份额
- 5.有些业务失败可能不需要进行回滚,所以业务补偿和业务关联紧密,很难用中间件解决
- 6.有些业务可能没有明确结果,需要采用JOB进行状态查询
- 7.业务服务要支持状态查询的接口
- 8.补偿业务不一定是强相关或依赖的,有些服务可以并行执行可以提高效率
TCC
TCC是(Try Commit Cancel)的简称,源于国外的一篇论文,最早由阿里的程立博士在infoQ的一篇介绍中引入国内,目前国内大多数互联网公司都在采用这种方案.
我们用一个账户A转账给账户B100元为例子
- Try 预留资源,完成一致性检查 (账户A可用余额减少100,冻结金额增加100元,账户B冻结金额增加100)
- Commit 执行业务,不做任何一致性检查,而且只能使用try中预留的资源 (账户A冻结金额减少100,账户B可用余额增加100,冻结金额减少100)
- Cancel 释放TRY阶段预留的资源 (账户A可用余额增加100,冻结金额减少100,账户B冻结金额减少100)

TCC模式本质上也是两阶段提交,上图对比了TCC和XA方案,两者一个是业务操作一个是针对数据库,所以TCC方案不会采用数据库本地事物去锁定资源,所以使用TCC也需要各个接口能够支持幂等,并且能够重试,而且需要提供状态查询接口,不然在网络超时后,发起方不确定分支事物是执行成功还是失败.
SAGA
saga提供了一种根据工作流引擎进行管理事物的提交和回滚,流程上类似于上面的事物补偿机制
可靠消息最终一致性
大多时候我们希望多个业务能够并行处理,这个时候我们可以借助消息队列来异步通知其他应用进行相应的操作,那么怎么保证本地事物和接受消息的应用上处理的服务要么全部成功,要么全部失败呢,我们根据之前的最终一致性方案,允许两个分支事物可以先后执行,但是最终肯定会执行,不会不执行.
这种方案其实也是业务补偿的一种,只是借助消息队列进行解耦和异步通知,下面我们分析下这种方案的两个难点.
-
如何保证消息投递和本地事物要么全部成功,要么全部失败
首先,事物管理器先发送一条记录给消息服务,消息服务将这条消息存储,状态记录为待确认,然后执行本地数据库操作,然后发送确认消息给消息服务,这两个动作可以放在一个本地事物内,如果本地数据库操作成功,消息确认失败,就将本地数据库操作回滚,如果本地数据库操作失败就发消息给消息服务请求删除消息.
如果发送给消息服务的确认和删除由于网络没有回应,那么就需要把在消息服务里定时轮询事物的状态,也就是消息服务去反查服务发送方,然后决定提交消息或者删除消息,所以消息服务和服务发送方应该维护一个双向通道,rocketMQ的做法是将PID和对应的channel缓存起来 -
如何保证消息百分百会被消费
消费端消费完消息后,给个确认消息给消息服务,消息服务不停轮询当前消息列表中,查看是否存在没有消费完成的消息,如果存在就让消息队列重新通知一次. -
如何保证消息不会重复消费
原则上我们希望分支事物自己能够支持幂等,如果一定要让中间件去重,实际上消息队列去重的代价是很大的,会牺牲掉高可用性,我们可以在应用层维护一张表去存储已经处理的消息,这样可以根据消息ID去重.
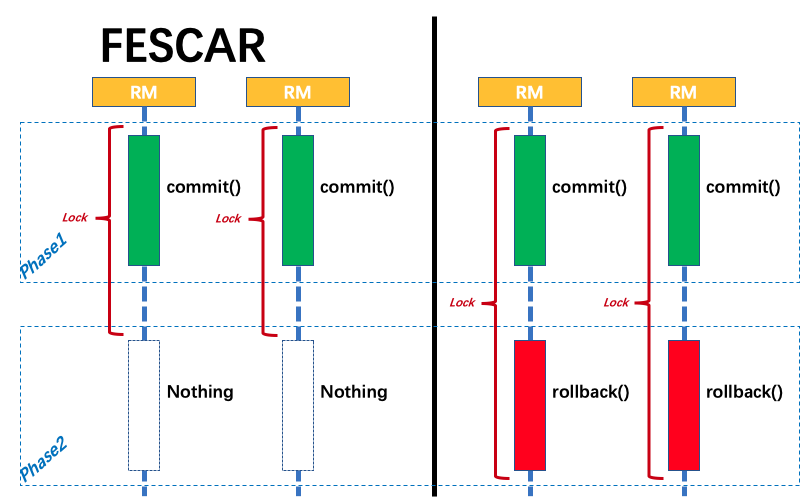
FESCAR
FESCAR (Fast easy commit and rollback),是阿里GTS的社区开源版本,基于现有的分布式事物解决方案,要么像XA这种会有严重的性能问题,要么像业务补偿,TCC,SAGA,可靠消息保证等,这种需要根据业务场景在应用中进行定制,我们不希望引入微服务后给业务层带来额外的研发负担,另外一方面不希望引入分布式事物后拖慢业务,所以FesCar的初衷就是对业务0侵入,并且高性能.
下面先通过官方上的介绍,看下fescar的思想,后面在结合代码看下fescar的具体实现细节
我们先简单回顾下XA里面分布式事物的三个角色,TM事物管理器.负责发起一个全局事物,TC事物协调器,独立在应用层外,负责维护全局事物和分支事物的状态,来决策提交还是回滚,RM:资源管理器,存储实际状态的容器,像硬盘,数据库,消息中间件,内存等都可以称为RM,Fescar将RM作为一个二方包的形式迁入到了应用层,作为应用层和TC进行通讯的代理,并且协助本地事物处理.
- 1.TM向TC申请开启一个全局事物,全局事物创建成功,并返回一个唯一的XID
- 2.XID在微服务调用链路中进行传递,dubbo可以通过filter方式,spring cloud也很方便,RPC服务端收到XID后存放在本地线程局部变量threadlocal中
- 3.分支事物RM向TC注册分支事物,将其纳入XID对应的全局事物管理中
- 4.TM向TC发起针对XID的全局事物的提交或者回滚操作
- 5.TC调用XID管辖下的分支事物完成提交和回滚
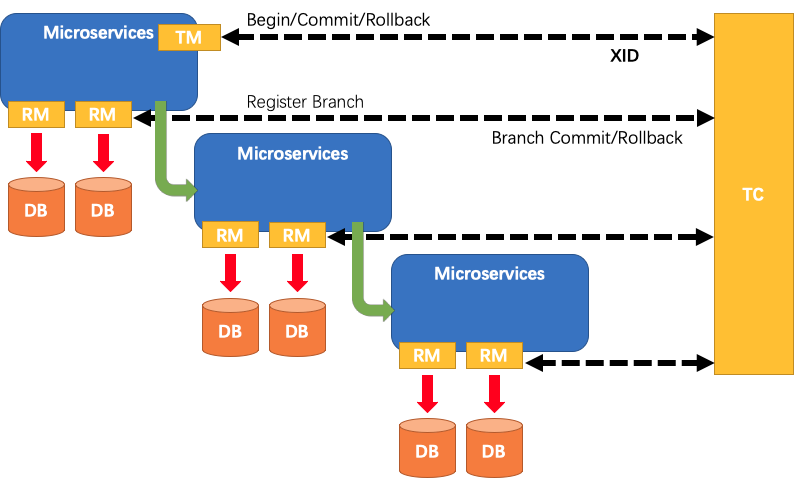
FESCAR取消了数据库层的prepare操作,而是直接进行commit操作,这样就不会带来昂贵的数据库锁开销,而每一个commit操作对应的都是数据库的本地事物,这个改变是Fescar性能高的主要原因,同时使他牺牲了隔离性,导致目前Fescar只能支持读未提交的隔离级别,如果要实现读已提交需要应用层做一些定制.
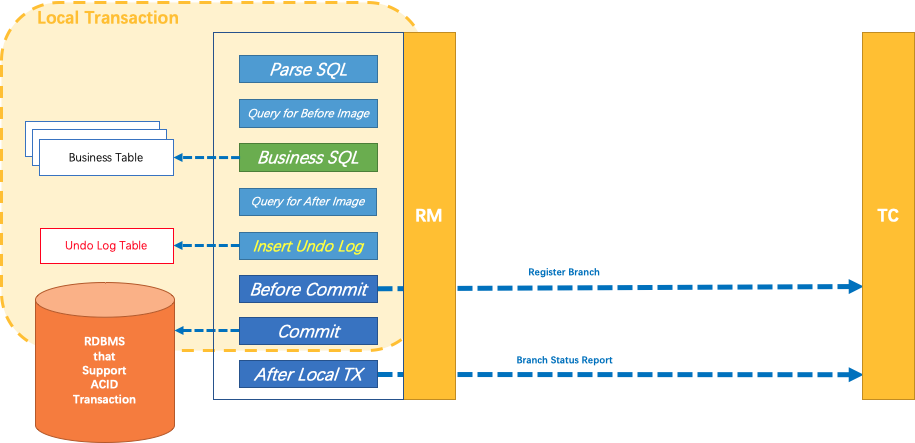
Fescar的RM插件,重新实现了一遍JDBC,从而拦截掉数据库的sql进行解析,并生成undolog,以及事物提交后的增强处理,这种设计使应用方完全无感,只需要开启一个全局事物

undolog是存储在业务方本地的数据库实例里,这样业务更新和插入undolog在一个本地事物内,可以保证事物回滚的时候一定有undolog.
目前fescar刚开源,在可靠性上还需要验证,目前社区也在计划完善一些新功能.
下面我们分析下Fescar的一些核心功能
事物管理器
我们先看下全局事物的三个核心接口,begin,commit,rollback,我在代码中都加了注释
public interface GlobalTransaction {
/**
* Begin a new global transaction with default timeout and name.
*
* 开启一个全局事物,像TC发起请求,返回一个XID,并将这个XID进行缓存到ThreadLocal
*
* @throws TransactionException Any exception that fails this will be wrapped with TransactionException and thrown
* out.
*/
void begin() throws TransactionException;
/**
* Commit the global transaction.
*
* 提交一个全局事物,将XID发给TC,并清除threadlocal里的缓存
*
* @throws TransactionException Any exception that fails this will be wrapped with TransactionException and thrown
* out.
*/
void commit() throws TransactionException;
/**
* Rollback the global transaction.
*
* 回滚一个全局事物,将XID发给TC,并清除threadlocal里的缓存
*
* @throws TransactionException Any exception that fails this will be wrapped with TransactionException and thrown
* out.
*/
void rollback() throws TransactionException;
}
然后我们在看下事物处理模板,也就是我们使用的入口,也是接入fescar唯一要关心的一个地方
public class TransactionalTemplate {
/**
* Execute object.
*
* @param business the business 只需要传人一个TransactionalExecutor就可以了,业务实现放在execute里面就可以了
* @return the object
* @throws ExecutionException the execution exception
*/
public Object execute(TransactionalExecutor business) throws TransactionalExecutor.ExecutionException {
// 1. get or create a transaction
GlobalTransaction tx = GlobalTransactionContext.getCurrentOrCreate();
// 2. begin transaction
try {
tx.begin(business.timeout(), business.name());
} catch (TransactionException txe) {
throw new TransactionalExecutor.ExecutionException(tx, txe,
TransactionalExecutor.Code.BeginFailure);
}
Object rs = null;
try {
// Do Your Business
rs = business.execute();
} catch (Throwable ex) {
// 3. any business exception, rollback.
try {
tx.rollback();
// 3.1 Successfully rolled back
throw new TransactionalExecutor.ExecutionException(tx, TransactionalExecutor.Code.RollbackDone, ex);
} catch (TransactionException txe) {
// 3.2 Failed to rollback
throw new TransactionalExecutor.ExecutionException(tx, txe,
TransactionalExecutor.Code.RollbackFailure, ex);
}
}
// 4. everything is fine, commit.
try {
tx.commit();
} catch (TransactionException txe) {
// 4.1 Failed to commit
throw new TransactionalExecutor.ExecutionException(tx, txe,
TransactionalExecutor.Code.CommitFailure);
}
return rs;
}
}
有没有发现跟我们平时使用的JTA用法一样,由于分支事物是RPC调用,所以存在网络超时的情况,所以分支事物如果超时了,即使分支事物的本地执行成功了,全局事物一样会进行回滚,因为这里会捕获这个超时异常,后面我们在分析为什么要这样设计.
xid怎么在rpc中传递
我们在做分布式链路监控的时候,也需要在rpc之间传递一个traceid,方法类似,如果是dubbo,我们可以写一个filter
@Activate(group = { Constants.PROVIDER, Constants.CONSUMER }, order = 100)
public class TransactionPropagationFilter implements Filter {
private static final Logger LOGGER = LoggerFactory.getLogger(TransactionPropagationFilter.class);
@Override
public Result invoke(Invoker<?> invoker, Invocation invocation) throws RpcException {
String xid = RootContext.getXID();
String rpcXid = RpcContext.getContext().getAttachment(RootContext.KEY_XID);
if (LOGGER.isDebugEnabled()) {
LOGGER.debug("xid in RootContext[" + xid + "] xid in RpcContext[" + rpcXid + "]");
}
boolean bind = false;
if (xid != null) {
RpcContext.getContext().setAttachment(RootContext.KEY_XID, xid);
} else {
if (rpcXid != null) {
RootContext.bind(rpcXid);
bind = true;
if (LOGGER.isDebugEnabled()) {
LOGGER.debug("bind[" + rpcXid + "] to RootContext");
}
}
}
try {
return invoker.invoke(invocation);
} finally {
if (bind) {
String unbindXid = RootContext.unbind();
if (LOGGER.isDebugEnabled()) {
LOGGER.debug("unbind[" + unbindXid + "] from RootContext");
}
if (!rpcXid.equalsIgnoreCase(unbindXid)) {
LOGGER.warn("xid in change during RPC from " + rpcXid + " to " + unbindXid);
if (unbindXid != null) {
RootContext.bind(unbindXid);
LOGGER.warn("bind [" + unbindXid + "] back to RootContext");
}
}
}
}
}
}
RootContext是fescar的threadlocal容器,RpcContext是dubbo得threadcontext容器,Attachment可以让dubbo在远程调用过程中携带更多地参数,服务调用方传递xid,服务提供方接收xid并保存,服务调用结束记得清空threadlocal以防止内存泄露.
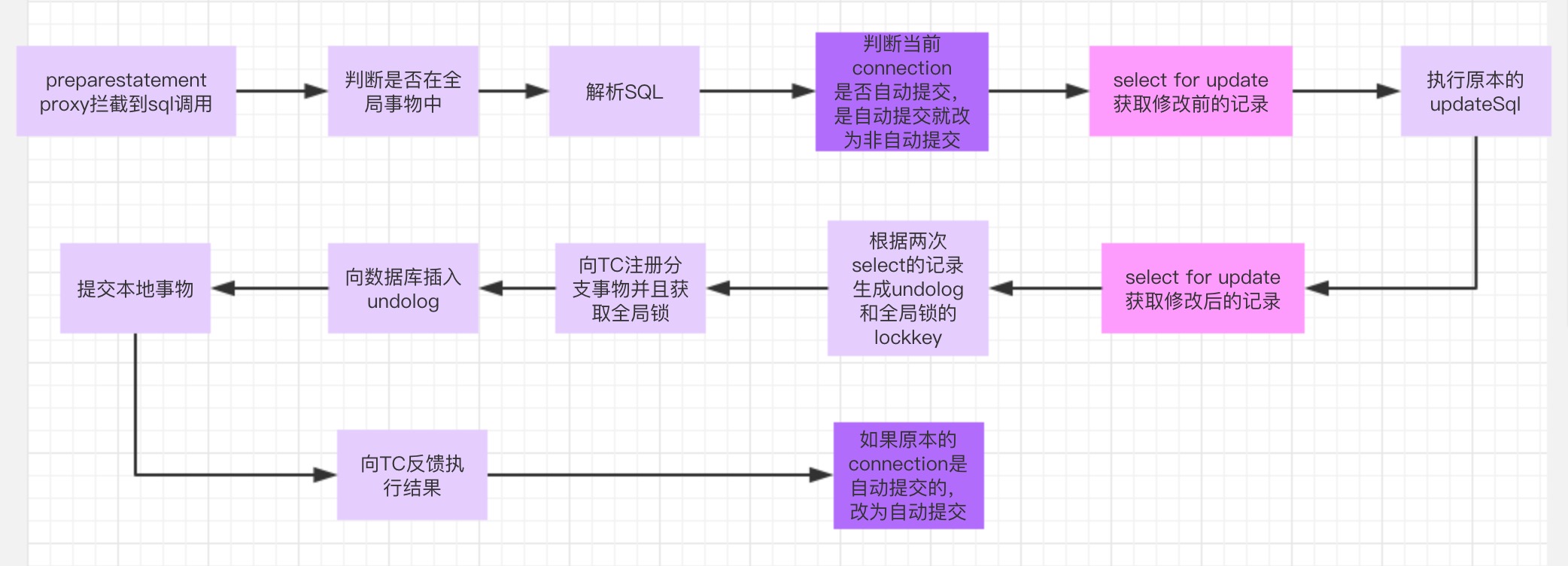
分支在一阶段的处理流程
PreparedStatementProxy -> ExecuteTemplate -> UpdateExecutor ->ConnectionProxy
- 0.sql进入jdbc的PreparedStatement中,然后这个jdbc对象被PreparedStatementProxy代理,进入他的execute方法
- 1.查看自己是否在一个Fescar的全局事物中,根据线程本地变量threadlocal中是否存在全局事物id进行判断,具体代码在ExecuteTemplate中
- 2.如果存在,就进入jdbc代理中,解析sql,根据类型选择不同的执行器

- 3.使用 select for update 查询获取原始当前update的记录当前值,就是修改前的值
- 4.执行原本的update修改记录的值
- 5.使用 select for update 查询获取update后的值,就是修改后的值
- 6.根据修改前和修改后的值,生成undolog,并根据主键的值生成lockkey放入context中
- 5.向TC请求,注册分支事物并将lockkey传给TC加上全局锁
- 6.如果注册并且获取锁成功,将把undolog插入数据库中
- 7.提交本地事物,并向TC反馈执行结果 (本地事物中包含原本的执行语句和插入undolog)

我们发现分支事物上的RM操作是基于statement和connection,在原来的connection上做了增强,用的时同一个物理connection,所以分支应用上的分支的定义为一个本地事物,所以
在一个RPC实现中,一个方法中如果存在多个sql语句,那么将会注册多个分支,向TC注册多次,如果这个方法在一个本地事物中,那么即使多个sql最终一起提交,并且只会向TC注册一次,undolog也是一起插入数据库的,这个地方注意下,如果这个connection是自动提交的,为了让update语句和插入undolog放在一个本地事物中,所以会将connection改为非自动提交,开启一个事物,在用完只会在改为自动提交,不要影响应用程序.

我们回顾下分支一阶段的处理流程
二阶段的处理流程
-
1.如果所有的分支都返回执行成功,TC将立即释放全局锁,并且TC异步通知分支删除undolog
-
2.如果有一个分支事物返回执行失败,则TC发起请求执行undolog,所有undolog执行成功了,释放锁,异步删除undolog
如何实现读已提交
目前官方给出的方案,在需要进行读取全局事物已经提交的记录的话,需要将select 语句后面加上for update,fescar发现加上排他锁后,会去TC获取对应的锁,如果没有锁上就执行,锁上就自旋等待,为了避免读取未提交的记录,后面全局事物回滚了,就导致脏读,当然目前可能大部分应用都可以接受这种情况,例如在扣商品份额的时候都会最终在校验一次,
当然我们也可以借助undolog实现一个read-view,让这条sql语句读取到这个全局事物还没有执行之前的数据.
目前fescar的实现方式是在sql解析后如果发现是select for update语句,将会进入SelectForUpdateExecutor执行器,不管是不是在一个全局事物中,都需要去TC看下是否被锁住,这里将不会获取锁,只是校验锁是否会释放.
如果分支超时,实际已经执行成功,那么肯定是已经向TC注册成功的,那么如果TM发起回滚,分支可以正常回滚,没有毛病,如果超时后,分支本地事物还没有提交,那么回滚请求已经到达分支,那么将会回滚失败,但是TC会重试不停进行回滚.
实现HA的挑战
TC目前是一个单点,如果需要集群部署,则需要一个服务发现的系统,让TC可以自动扩展,应用不需要关心TC具体节点,而TC的全局锁就不能直接放内存了,可能需要借助第三方存储系统,mysql或者etcd
实现XA的方案
可能需要在分支事物中,当解析到在一个全局事物中,不会进行commit,等到所有分支都返回成功了,事物管理器发起commit请求给TC,然后TC在通知各个分支进行提交,和rollback流程差不多
一致性协议 raft
由于paxos算法太复杂,我们分析下raft协议是如何保证分布式集群下数据复制的一致性的.
-
1.通过选举保证集群中只有一个leader,只有leader对外提供写服务,leader将日志广播给follower,每一条日志都按顺序维护在一个队列里,所有节点的队列里有一个index来控制前面的是已经提交的,后面的是没提交的,提交代表已经有超过半数的节点应答,leader先把日志复制给所有follower,在收到半数节点应答后在通知follower,index位置来控制那些日志是已经提交的,只有提交过的日志,follower才会提供给应用方使用
-
2、选举过程,当一个leader长时间没有应答时,所有的follower都可以成为candidate,向其他follower节点发送投票请求,如果超过半数follower节点应答后这个candidate就会升级为leader,为了避免所有的follower节点已经作为candidate发起投票,引入随机超时机制,每个follower和leader的超时时间在一定范围内随机,当candidate发起投票没有结果时,随机等待一定时间。
-
3.candidate的日志长度要大于等于半数follower节点的日志才能成为leader,所以发起投票的时候如果follower发现自己的日志长度大于后选择的就会投反对票
-
4.日志补齐,当leader发生故障的时候,各个follower上的状态不一样,所以新leader产生后需要补齐所有follow的日志,而且新leander的日志也不一定是最长的,但是foller日志上面没有的日志肯定是未提交的,这个时候补齐就可以
-
5.老leader复活,每一次选举到下一次选举的时间称为一个term任期,每一个任期内都会维护一个数字并自增,当leader发送复制请求的时候会带上term编号,如果follower发现term比自己小就拒绝,
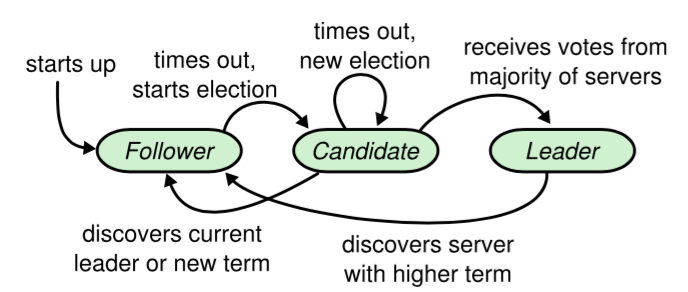
raft设计中只有两个rpc请求,一个选举,一个复制日志,复制日志顺便做了心跳检测,当没有日志复制的时候发送空日志,触发选举的唯一条件是 election timeout到期,每一个节点的 election timeout都会将自己设置为candidate然后发起投票,每个节点的election timeout都会存在一个随机值,所以不同,当一个节点被选为leader后会定期向所有的follower发送心跳包,follower收到心跳包后会延长election timeout的值。节点选举的时候term值大的会优先于term值小的,每一轮选举term值都会加1.