最近几天,想搭建一下5台机器的HA,就开始查找资料,在搭建的过程中还是出现各种各样的意外。
首先,先说明一下zk分布情况,两台NameNode(nna,nns)三台DataNode(dn1,dn2,dn3),使用zk达到高可用,zk分别分布在两台NameNode与一台DataNode节点上;Journalnode分布情况:分别分布在三台DataNode节点上。这里注意一下zk、Journalnode保证奇数个,最少不少于3个节点。
整体集群规划:
主机名 IP 安装的软件 运行的进程
nna 192.168.10.10 jdk、hadoop、zookeeper NameNode、DFSZKFailoverController(zkfc) 、ResourceManager 、QuorumPeerMain
nns 192.168.10.11 jdk、hadoop、zookeeper NameNode、DFSZKFailoverController(zkfc) 、ResourceManager、QuorumPeerMain
dn1 192.168.10.12 jdk、hadoop DataNode、NodeManager、JournalNode
dn2 192.168.10.13 jdk、hadoop DataNode、NodeManager、JournalNode
dn3 192.168.10.14 jdk、hadoop 、zookeeper DataNode、JournalNode、NodeManager、QuorumPeerMain
说明:
1.在hadoop2.0中通常由两个NameNode组成,一个处于active状态,另一个处于standby状态。Active NameNode对外提供服务,而Standby NameNode则不对外提供服务,仅同步active namenode的状态,以便能够在它失败时快速进行切换。
hadoop2.0官方提供了两种HDFS HA的解决方案,一种是NFS,另一种是QJM。这里我们使用简单的QJM。在该方案中,主备NameNode之间通过一组JournalNode同步元数据信息,一条数据只要成功写入多数JournalNode即认为写入成功。通常配置奇数个JournalNode 。
这里还配置了一个zookeeper集群,用于ZKFC(DFSZKFailoverController)故障转移,当Active NameNode挂掉了,会自动切换Standby NameNode为standby状态 。
2.hadoop-2.2.0中依然存在一个问题,就是ResourceManager只有一个,存在单点故障,hadoop-2.4.1及其以后版本解决了这个问题,有两个ResourceManager,一个是Active,一个是Standby,状态由zookeeper进行协调 。
一、准备任务:
1.安装好 Hadoop 集群;传送门
2.安装好 ZooKeeper 集群;传送门
3.集群在完成上面步骤之后可以从nna克隆出nns、dn1、dn2、dn3:传送门
批注:克隆之后修改主机名 vi /etc/sysconfig/network

注意一下要关闭防火墙、同步时间(如果已经做过,可以跳过此步骤)
关闭防火墙
永久关闭防火墙:chkconfig iptables off(推荐使用),此时当前虚拟机的防火墙还没有关闭。只有在关机重启后才能生效。
暂时关闭防火墙:service iptables off
查看防火墙状态:service iptables status
同步时间:当我们每一次启动集群时,时间基本上是不同步的,所以需要时间同步。要求所以节点保持一致的时间。
注意点:使用root用户修改,5个节点同时修改(如果安装了ntp,下面步骤可以直接跳到第三步)
1、我们先使用date命令查看当前系统时间

如果系统时间与当前时间不一致,可以按照如下方式修改
2.下面我们使用ntp(网络时间协议)同步时间。如果ntp命令不存在,则需要在线安装ntp
使用yum下载安装ntp, yum -y install ntp
-y 表示自动yes,有兴趣的童鞋可以尝试一下不加
install 表示通过网络下载资源

3.安装ntp后,我们可以使用ntpdate命令进行联网时间同步。ntpdate pool.ntp.org

4.测试使用date查看当前时间
二、开始HA 的安装:
1.修改 nna的 core-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://cluster1</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/tmp</value>
</property>
<!-- 设置 Zookeeper 集群位置信息 -->
<property>
<name>ha.zookeeper.quorum</name>
<value>nna:2181,nns:2181,dn3:2181</value>
</property>
</configuration>
2.修改 nna的 hdfs-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<configuration>
<!--定义 NameServices 逻辑名称,此处为 cluster1-->
<property>
<name>dfs.nameservices</name>
<value>cluster1</value>
</property>
<!--映射 NameServices 逻辑名称到 NamNode 逻辑名称 -->
<property>
<name>dfs.ha.namenodes.cluster1</name>
<value>nna,nns</value>
</property>
<!-- 配置 nna为 master -->
<property>
<name>dfs.namenode.rpc-address.cluster1.nna</name>
<value>nna:9000</value>
</property>
<property>
<name>dfs.namenode.http-address.cluster1.nna</name>
<value>nna:50070</value>
</property>
<!-- 配置 nns为 slave1 -->
<property>
<name>dfs.namenode.rpc-address.cluster1.nns</name>
<value>nns:9000</value>
</property>
<property>
<name>dfs.namenode.http-address.cluster1.nns</name>
<value>nns:50070</value>
</property>
<!--配置 JournalNode 集群位置信息及目录 -->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://dn1:8485;dn2:8485;dn3:8485/cluster1</value>
</property>
<!--配置 JournalNode edits 文件位置 -->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/home/hadoop/data/tmp/journal</value>
</property>
<!-- 配置故障迁移实现类 -->
<property>
<name>dfs.client.failover.proxy.provider.cluster1</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!-- 指定切换方式为SSH免密钥方式 -->
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/home/hadoop/.ssh/id_rsa</value>
</property>
<property>
<!-- 设置故障自动切换 -->
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/home/hadoop/data/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/home/hadoop/data/dfs/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.journalnode.http-address</name>
<value>0.0.0.0:8480</value>
</property>
<property>
<name>dfs.journalnode.rpc-address</name>
<value>0.0.0.0:8485</value>
</property>
<property>
<name>ha.zookeeper.quorum</name>
<value>nna:2181,nns:2181,dn3:2181</value>
</property>
</configuration>
3.配置slave
在cd /usr/local/hadoop/etc/hadoop路径下vi slaves内容如下,指定DataNode
dn1
dn2
dn3
4.配置yarn
4.1配置mapred-site.xml,修改内容如下
<?xml version="1.0" encoding="UTF-8"?>
<configuration>
<-- 指定运行mapreduce的环境是Yarn -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>nna:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>nna:19888</value>
</property>
</configuration>
4.2配置yarn-site.xml
<configuration>
<property>
<name>yarn.resourcemanager.connect.retry-interval.ms</name>
<value>2000</value>
</property>
<-- 超时的周期 -->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<-- 打开高可用 -->
<property>
<name>yarn.resourcemanager.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<-- 启动故障自动恢复 -->
<property>
<name>yarn.resourcemanager.ha.automatic-failover.embedded</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>yarn-rm-cluster</value>
</property>
<-- 给yarn cluster 取个名字yarn-rm-cluster -->
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<-- 给ResourceManager 取个名字 rm1,rm2 -->
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>nna</value>
</property>
<-- 配置ResourceManager rm1 hostname -->
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>nns</value>
</property>
<-- 配置ResourceManager rm2 hostname -->
<property>
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
</property>
<-- 启用resourcemanager 自动恢复 -->
<property>
<name>yarn.resourcemanager.zk.state-store.address</name>
<value>nna:2181,nns:2181,dn3:2181</value>
</property>
<-- 配置Zookeeper地址 -->
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>nna:2181,nns:2181,dn3:2181</value>
</property>
<-- 配置Zookeeper地址 -->
<property>
<name>yarn.resourcemanager.address.rm1</name>
<value>nna:8032</value>
</property>
<-- rm1端口号 -->
<property>
<name>yarn.resourcemanager.scheduler.address.rm1</name>
<value>nna:8034</value>
</property>
<-- rm1调度器的端口号 -->
<property>
<name>yarn.resourcemanager.webapp.address.rm1</name>
<value>nna:8088</value>
</property>
<-- rm1 webapp端口号 -->
<property>
<name>yarn.resourcemanager.address.rm2</name>
<value>nns:8032</value>
</property>
<-- rm2端口号 -->
<property>
<name>yarn.resourcemanager.scheduler.address.rm2</name>
<value>nns:8034</value>
</property>
<-- rm2调度器的端口号 -->
<property>
<name>yarn.resourcemanager.webapp.address.rm2</name>
<value>nns:8088</value>
</property>
<-- rm2 webapp端口号 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce_shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<-- 执行MapReduce需要配置的shuffle过程 -->
</configuration>
5.同步 以上配置文件
把 nna上的 slaves、core-site.xml 和 hdfs-site.xml 以及yarn的配置文件发送给 nns和 dn1,dn2,dn3。下面只演示将nna上面的文件发送到nns节点上,dnx类比。
scp /usr/local/hadoop/etc/hadoop/core-site.xml root@nns:/usr/local/hadoop/etc/hadoop
scp /usr/local/hadoop/etc/hadoop/hdfs-site.xml root@nns:/usr/local/hadoop/etc/hadoop
scp /usr/local/hadoop/etc/hadoop/slaves root@nns:/usr/local/hadoop/etc/hadoop
scp /usr/local/hadoop/etc/hadoop/mapred-site.xml root@nns:/usr/local/hadoop/etc/hadoop
scp /usr/local/hadoop/etc/hadoop/yarn-site.xml root@nns:/usr/local/hadoop/etc/hadoop
4.初始化 HA
1.如果 HDFS 正在运行,请关闭;
2.启动 3 个节点的 ZooKeeper,在 3 个节点执行:zkServer.sh start;
3.删除 3 个节点的 hdfs 文件夹,在 3 个节点执行:rm -rf /usr/local/hadoop/hdfs;
4.启动 3 个节点的 journal,在 3 个节点执行:hadoop-daemon.sh start journalnode;
5.格式化 HDFS,在 nna执行:在 master 执行:hdfs namenode -format;
6.启动 nna的 NameNode,在 nna执行:hadoop-daemon.sh start namenode;
7.同步 nna的 NameNode 状态到 nns,在 nns执行:hdfs namenode -bootstrapStandby;
8.关闭 nna的 NameNode,在 nna执行:hadoop-daemon.sh stop namenode;
9.格式化 zkfc,在 nna执行:hdfs zkfc -formatZK;
10.关闭 3 个节点的 ZooKeeper,在 3 个节点执行:zkServer.sh stop;
以后以上启动方式可以简化为,
zk:zkServer.sh start
hadoop:start-all.sh
5.安装主备切换软件
在 nna和 nns安装用于实现主备切换的软件:yum -y install psmisc。
三、HA 的使用
1 启动
启动 3 个节点的 ZooKeeper,在 3 个节点执行:zkServer.sh start;
启动 HDFS,在 nna执行:start-dfs.sh;
2 验证
在浏览器分别使用:nna-ip:50070 和 nns-ip:50070 查看两个 NameNode 状态,是否一个处于 Active,一个处于 Standby;
在处于Active状态下的节点上上传文件到hdfs,并查看是否成功
[root@nna lyz]# hadoop fs -put /etc/profile /profile
[root@nna lyz]# hadoop fs -ls /
Found 1 items
-rw-r--r-- 3 root supergroup 2070 2019-01-16 13:40 /profile
成功之后,使用 jps 命令查看 Active NameNode 的进程 ID;
使用 kill -9 ID 杀死 Active NameNode,验证能否切换 Standby 为 Active;
[root@nna lyz]# jps
4019 NameNode
4517 Jps
1478 QuorumPeerMain
4318 DFSZKFailoverController
[root@nna lyz]# kill -9 4019
再次在杀死的那个节点(nna)查询你上传到hdfs上的文件,还可以查到。 hadoop fs -ls /

此时在开启此节点的NameNode进程:hadoop-daemon.sh start namenode

进入web页面查看节点的状态:nnx-ip:50070
nna一开始是我的Action状态
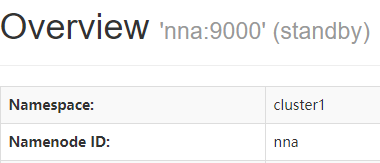
nns开始是standby状态
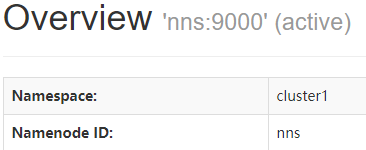
以上表明:HA集群的Action与Standby替换成功
3关闭
关闭 HDFS,在 master 执行:stop-dfs.sh;
关闭 3 个节点的 ZooKeeper,在 3 个节点执行:zkServer.sh stop;
四、注意事项
1.集群启动之前启动zk,zk启动时,注意是按照myid中数字的大小依次启动
2.在启动集群时出现异常如下:
Java HotSpot(TM) 64-Bit Server VM warning: You have loaded library /usr/local/hadoop-2.2.0/lib/native/libhadoop.so.1.0.0 which might have disabled stack guard. The VM will try to fix the stack guard now.
原因与解决:这个问题的错误原因会发生在64位的操作系统上,原因是从官方下载的hadoop使用的本地库文件(例如lib/native/libhadoop.so.1.0.0)都是基于32位编译的,运行在64位系统上就会出现上述错误。解决方法之一是在64位系统上重新编译hadoop,另一种方法是在hadoop-env.sh和yarn-env.sh中添加如下两行:
export HADOOP_COMMON_LIB_NATIVE_DIR=${HADOOP_PREFIX}/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_PREFIX/lib"
添加之后又发现了新问题
WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
解决方法:
问题在哪里?有人说这是hadoop的预编译包是32bit的,运行在64bit上就会有问题。但是这个答案大多数时候都是错的。
如何验证64bit还是32bit?
进入hadoop安装目录
/usr/local/hadoop-2.5.2/lib/native
用ldd命令查看依赖库
ldd libhadoop.so.1.0.0
会输出如下信息:
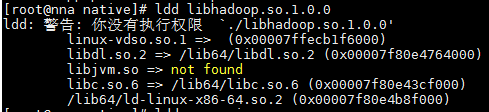
可以看到依赖的都是/lib64/的动态库,所以不是64位/32位问题。但是看到报错,GLIBC_2.14找不到,现在检查系统的glibc库, ldd --version即可检查。
输入命令:
ldd --version
会输出如下信息:

原来系统预装的glibc库是2.12版本,而hadoop期望是2.14版本,所以打印警告信息。
现在有两个办法,重新编译glibc.2.14版本,安装后专门给hadoop使用,这个有点危险。
第二个办法直接在log4j日志中去除告警信息。在/usr/local/hadoop-2.5.2/etc/hadoop/log4j.properties文件中添加
log4j.logger.org.apache.hadoop.util.NativeCodeLoader=ERROR
3.问题三:
hadoop错误INFO ipc.Client: Retrying connect to server: localhost/127.0.0.1
问题解析与方案:
hadoop安装完成后,必须要用haddop namenode format格式化后,才能使用,如果重启机器
在启动hadoop后,用hadoop fs -ls命令老是报 10/09/25 18:35:29 INFO ipc.Client: Retrying connect to server: localhost/127.0.0.1:9000. Already tried 0 time(s).的错误,
用jps命令,也看不不到namenode的进程, 必须再用命令hadoop namenode format格式化后,才能再使用
原因是:hadoop默认配置是把一些tmp文件放在/tmp目录下,重启系统后,tmp目录下的东西被清除,所以报错
解决方法:在conf/core-site.xml (0.19.2版本的为conf/hadoop-site.xml)中增加以下内容
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/tmp</value>
</property>
重启hadoop后,格式化namenode即可
问题四:格式化hdfs,多次格式化失败。
问题解析与方案:每次格式化都会生成一个类似于id的东西,多次格式化导致ID值不一样。需要删除core-site.xml与hdfs-site.xml中配置的文件
1.core-site.xml中hadoop.tmp.dir配置的目录下的文件
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/tmp</value>
</property>
2.hdfs-site.xml中dfs.namenode.name.dir与dfs.datanode.data.dir配置下的目录文件
<property>
<name>dfs.namenode.name.dir</name>
<value>/home/hadoop/data/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/home/hadoop/data/dfs/data</value>
</property>
删除之后,再执行格式化:hdfs name format
HA已经搭建完成,接下来开始搭建分布式Hbase、hive、kafka、flume…