任务
action recognition
对骨架节点坐标进行视角不变预处理
We align the action sequences by implementing a view-invariant transformation which transforms keypoints coordinates from original coordinate system into a view-invariant coordinate
system。
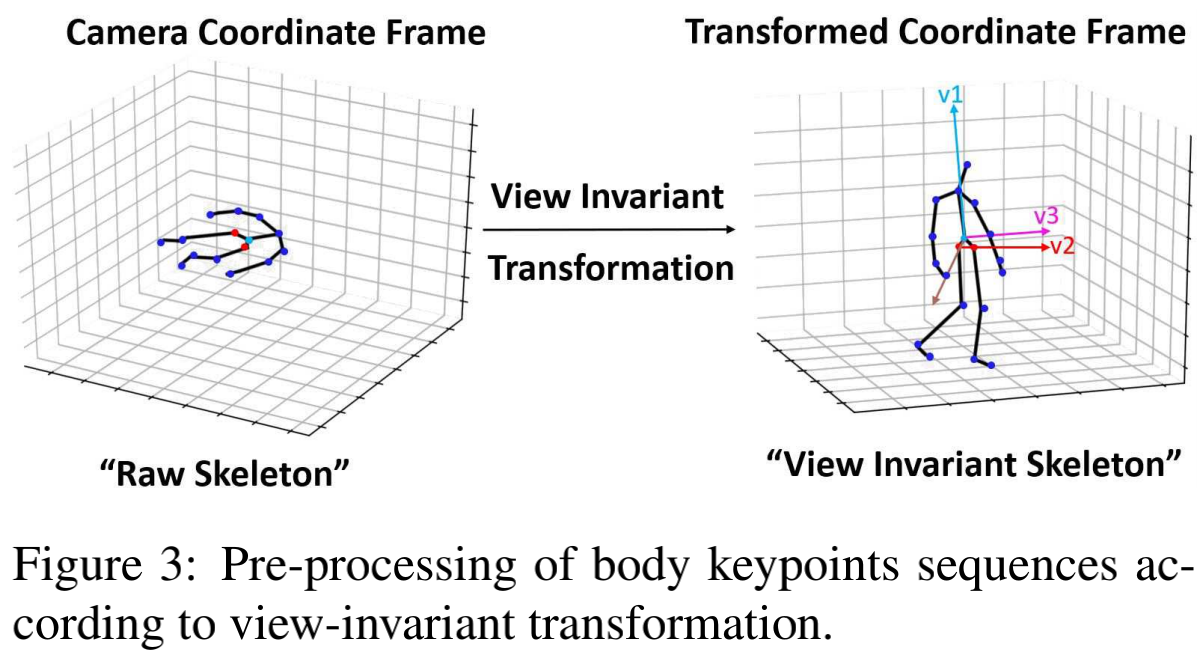
基本流程
先训练出一个encoder-decoder,这个encoder是双向GRU,decoder是单向GRU。把encoder得到的特征叫做high dimensional feature。如下图:
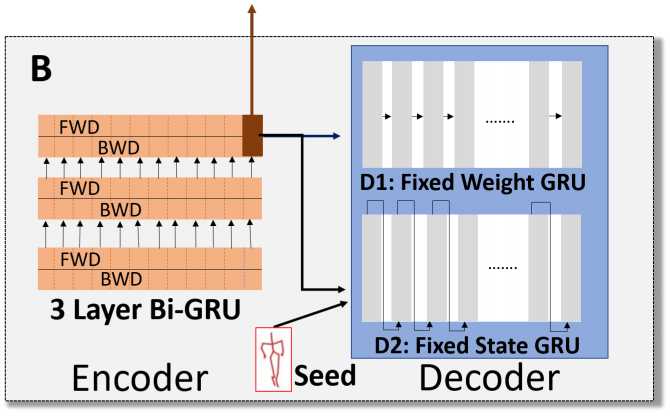
再把high-dimensional feature送进另一个encoder-decoder,这里的encoder和decoder都是全连接层,激活函数是tanh,如下图所示。把这个encoder得到的特征叫做low dimensional feature。用这个low dimensional feature做KNN聚类。

数据集
North-Western UCLA (NW-UCLA) dataset
UWA3D Multiview Activity II (UWA3D) dataset
NTU RGB+D dataset