1. Breakfast Dataset
The breakfast video dataset consists of 10 cooking activities performed by 52 different actors in multiple kitchen locations Cooking activities included the preparation of coffee, orange juice , chocolate milk, tea, a bowl of cereals, fried eggs, pancakes, a fruit salad, a sandwich and scrambled eggs. All videos were manually labeled based on 48 different action units with 11,267 samples.
2. PKUMMD
PKU-MMD is a large-scale dataset focusing on long continuous sequences action detection and multi-modality action analysis. The dataset is captured via the Kinect v2 sensor. There are 364x3(view) long action sequences, each of which lasts about 3∼4 minutes (recording ratio set to 30FPS) and contains approximately 20 action instances. The total scale of the dataset is 5,312,580 frames of 3,000 minutes with 21,545 temporally localized actions.
可视化链接:PKU-MMD骨架数据可视化程序,动态图,python
3. something-something Dataset
The 20BN-SOMETHING-SOMETHING dataset is a large collection of densely-labeled video clips that show humans performing pre-defined basic actions with everyday objects. The dataset was created by a large number of crowd workers. It allows machine learning models to develop fine-grained understanding of basic actions that occur in the physical world.
4. UCF101

5. HDMB-51
- General facial actions smile, laugh, chew, talk.
- Facial actions with object manipulation: smoke, eat, drink.
- General body movements: cartwheel, clap hands, climb, climb stairs, dive, fall on the floor, backhand flip, handstand, jump, pull up, push up, run, sit down, sit up, somersault, stand up, turn, walk, wave.
- Body movements with object interaction: brush hair, catch, draw sword, dribble, golf, hit something, kick ball, pick, pour, push something, ride bike, ride horse, shoot ball, shoot bow, shoot gun, swing baseball bat, sword exercise, throw.
- Body movements for human interaction: fencing, hug, kick someone, kiss, punch, shake hands, sword fight.

6. SBU Kinect Interaction dataset
The SBU Kinect Interaction dataset is a Kinect captured human activity recognition dataset depicting two person interaction. It contains 282 skeleton sequences and 6822 frames of 8 classes. There are 15 joints for each skeleton.

7. NTU RGB+D
"NTU RGB+D" contains 60 action classes and 56,880 video samples.
"NTU RGB+D 120" extends "NTU RGB+D" by adding another 60 classes and another 57,600 video samples, i.e., "NTU RGB+D 120" has 120 classes and 114,480 samples in total.
These two datasets both contain RGB videos, depth map sequences, 3D skeletal data, and infrared (IR) videos for each sample. Each dataset is captured by three Kinect V2 cameras concurrently.
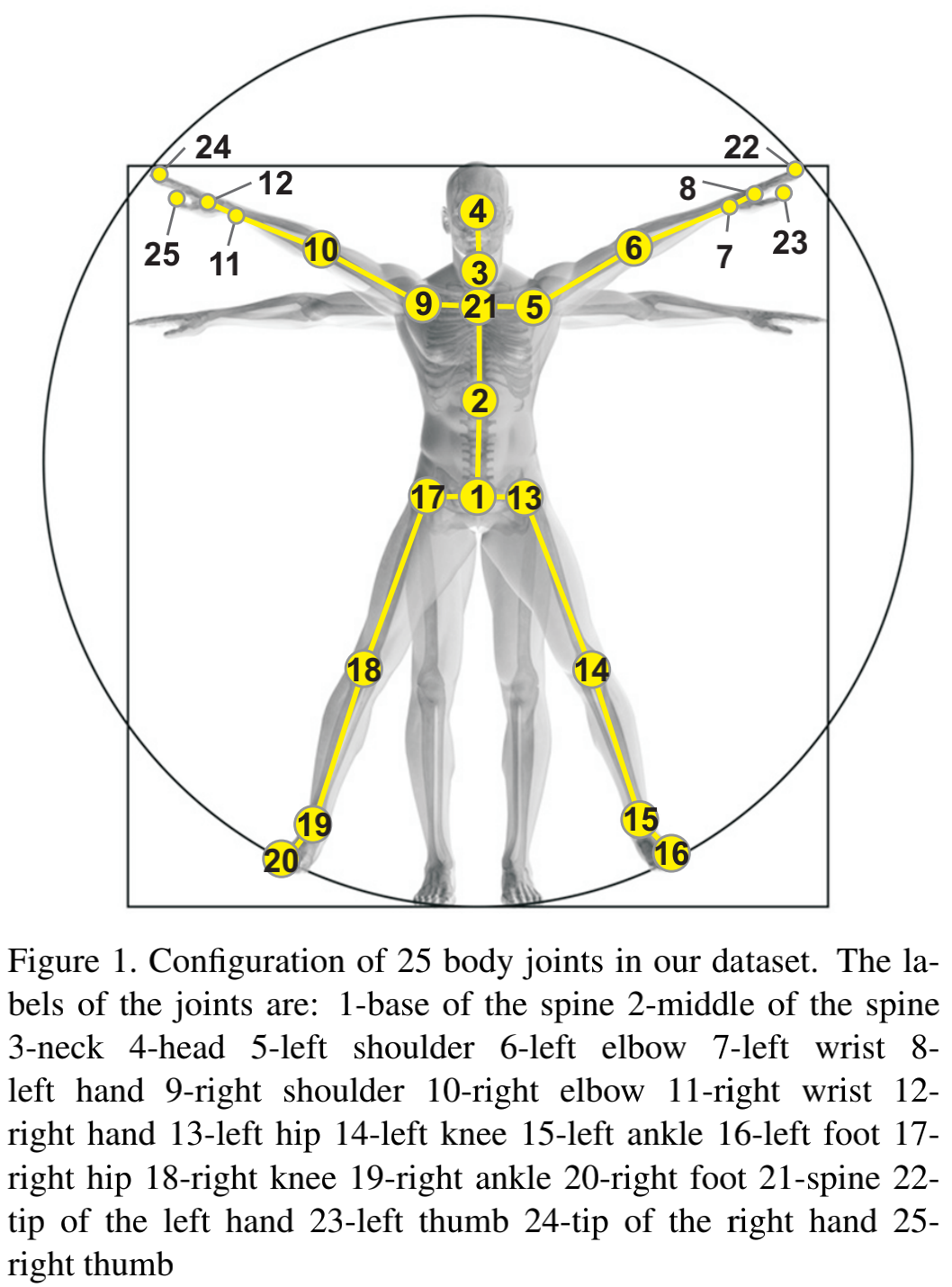
The resolutions of RGB videos are 1920x1080, depth maps and IR videos are all in 512x424, and 3D skeletal data contains the 3D coordinates of 25 body joints at each frame.
可视化程序:NTU RGB+D数据集,骨架数据可视化

8. CMU Mocap
9. N-UCLA



2017PR-Enhanced skeleton visualization for view invariant human action recognition:

