01-安装Jupyter Notebook
安装Jupyter Notebook的前提是Python的版本在3.3以上(或2.7版本)
通过安装Anaconda,来解决安装Jupyter Notebook的问题。
安装Anaconda
官网:https://www.anaconda.com/download/
清华镜像(推荐使用):https://mirrors.tuna.tsinghua.edu.cn/anaconda/archive/
使用介绍:
运行Jupyter Notebook
jupyter notebook
使用介绍: 快捷键: b: 向下插入一个cell a: 向上插入一个cell m: 将cell的类型切换成 makedown 类型 y: 将cell的类型切换成 code类型 shift+enter: 执行cell shit+tab: 查看模块的帮助文档 tab: 自动补全
02-urllib模块
Python中自带的一个基于爬虫的模块。作用:可以是用代码模拟浏览器发起请求。
使用流程:
指定URL
发起请求
获取页面数据
持久存储
urllib第一个爬虫程序
# 需求:爬去搜狗首页的页数据 import urllib.request # 1.指定url url = "https://www.sogou.com/" # 2.发起请求:urlopen可以根据指定的url发起请求,并返回一个相应对象 response = urllib.request.urlopen(url=url) # 3.获取页面数据:read函数返回的是响应对象中存储的页面数据 page_text = response.read() # 4.持久化存储 with open('./sougou.html', 'wb') as f: f.write(page_text) print('写入数据成功')
# 需求:爬取指定词条所对应的页面数据 import urllib.request import urllib.parse url = "https://www.sogou.com/web?query=" # url特性:url不可以存在非ASCII编码的字符数据 world = urllib.parse.quote("人民币") # 有效的url url += world response = urllib.request.urlopen(url=url) page_text = response.read() with open('./renminbi.html', 'wb') as f: f.write(page_text) print('写入数据成功')
03-反爬机制


import urllib.request import urllib.parse url = 'https://www.sogou.com/web?' #将get请求中url携带的参数封装至字典中 param = { 'query':'周杰伦' } #对url中的非ascii进行编码 param = urllib.parse.urlencode(param) #将编码后的数据值拼接回url中 url += param #封装自定义的请求头信息的字典: #将浏览器的UA数据获取,封装到一个字典中。该UA值可以通过抓包工具或者浏览器自带的开发者工具中获取某请求,从中获取UA的值 #注意:在headers字典中可以封装任意的请求头信息 headers={ 'User-Agent' : 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36' } #自定义请求对象,可以在该请求对象中添加自定义的请求头信息 request = urllib.request.Request(url=url,headers=headers) #使用自定义请求对象发起请求 response = urllib.request.urlopen(request) data = response.read() with open('./周杰伦.html','wb') as fp: fp.write(data) print('写入文件完毕')
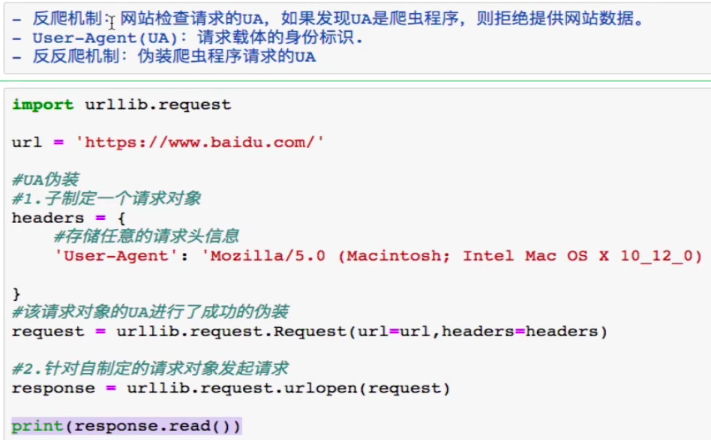
04-urllib模块发起的post请求
# 需求:百度翻译发post请求 import urllib.request import urllib.parse #通过抓包工具抓取post请求的url post_url='https://fanyi.baidu.com/sug' #封装post请求参数 data={ "kw":"dog" } data=urllib.parse.urlencode(data) #自定义请求头信息字典 headers={ "User-Agent": "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.87 Safari/537.36" } #自定义请求对象,然后将封装好的post请求参数赋值给Requst方法的data参数。 #data参数:用来存储post请求的参数 request=urllib.request.Request(post_url,data=data.encode(),headers=headers) #自定义的请求对象中的参数(data必须为bytes类型) response=urllib.request.urlopen(request) response.read()
05-urllib的高级操作
1.代理
- 什么是代理:代理就是第三方代替本体处理相关事务。例如:生活中的代理:代购,中介,微商......
- 爬虫中为什么需要使用代理?
一些网站会有相应的反爬虫措施,例如很多网站会检测某一段时间某个IP的访问次数,如果访问频率太快以至于看起来不像正常访客,它可能就会会禁止这个IP的访问。所以我们需要设置一些代理IP,每隔一段时间换一个代理IP,就算IP被禁止,依然可以换个IP继续爬取。
- 代理的分类:
正向代理:代理客户端获取数据。正向代理是为了保护客户端防止被追究责任。
反向代理:代理服务器提供数据。反向代理是为了保护服务器或负责负载均衡。
import urllib.request import urllib.parse #1.创建处理器对象,在其内部封装代理ip和端口 handler=urllib.request.ProxyHandler(proxies={'http':'95.172.58.224:52608'}) #2.创建opener对象,然后使用该对象发起一个请求 opener=urllib.request.build_opener(handler) url='http://www.baidu.com/s?ie=UTF-8&wd=ip' headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.181 Safari/537.36', } request = urllib.request.Request(url, headers=headers) #使用opener对象发起请求,该请求对应的ip即为我们设置的代理ip response = opener.open(request) with open('./daili.html','wb') as fp: fp.write(response.read())
06-requests模块
1.基于requests模块发起get请求
# 需求:爬取搜狗首页的页面数据 import requests #指定url url = 'https://www.sogou.com/' #发起get请求:get方法会返回请求成功的相应对象 response = requests.get(url=url) #获取响应中的数据值:text可以获取响应对象中字符串形式的页面数据 page_data = response.text print(page_data) #持久化操作 with open('./sougou.html','w',encoding='utf-8') as fp: fp.write(page_data)
2.response中重要的属性
#response对象中其他重要的属性 import requests #指定url url = 'https://www.sogou.com/' #发起get请求:get方法会返回请求成功的相应对象 response = requests.get(url=url) #content获取的是response对象中二进制(byte)类型的页面数据 #print(response.content) #返回一个响应状态码 #print(response.status_code) #返回响应头信息 #print(response.headers) #获取请求的url #print(response.url)
3.requests模块如何处理携带参数的get请求
# 需求:指定一个词条,获取搜狗搜索结果所对应的页面数据 import requests url = 'https://www.sogou.com/web?query=周杰伦&ie=utf-8' response = requests.get(url=url) page_text = response.text with open('./zhou.html','w',encoding='utf-8') as fp: fp.write(page_text)
import requests #自定义请求头信息 headers={ 'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36', } #指定url url = 'https://www.sogou.com/web' #封装get请求参数 prams = { 'query':'周杰伦', 'ie':'utf-8' } #发起请求 response = requests.get(url=url,params=param) response.status_code
# 自定义请求头信息 import requests url = 'https://www.sogou.com/web' #将参数封装到字典中 params = { 'query':'周杰伦', 'ie':'utf-8' } #自定义请求头信息 headers = { 'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36', } response = requests.get(url=url,params=params,headers=headers) response.status_code
4.requests的post请求
# 需求:登录豆瓣网,获取登录成功后的页面数据 import requests #1.指定post请求的url url = 'https://accounts.douban.com/login' #封装post请求的参数 data = { "source": "movie", "redir": "https://movie.douban.com/", "form_email": "15027900535", "form_password": "bobo@15027900535", "login": "登录", } #自定义请求头信息 headers = { 'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36', } #2.发起post请求 response = requests.post(url=url,data=data,headers=headers) #3.获取响应对象中的页面数据 page_text = response.text #4.持久化操作 with open('./douban.html','w',encoding='utf-8') as fp: fp.write(page_text)
5.基于ajax的get请求
# 需求:抓取豆瓣电影上电影详情的数据 import requests url = 'https://movie.douban.com/j/chart/top_list?' #封装ajax的get请求中携带的参数 params = { 'type':'5', 'interval_id':'100:90', 'action':'', 'start':'100', 'limit':'20' } #自定义请求头信息 headers = { 'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36', } response = requests.get(url=url,params=params,headers=headers) print(response.text)
6.基于ajax的post请求
# 需求:爬去肯德基城市餐厅位置数据 import requests #1指定url post_url = 'http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=keyword' #处理post请求的参数 data = { "cname": "", "pid": "", "keyword": "上海", "pageIndex": "1", "pageSize": "10", } #自定义请求头信息 headers = { 'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36', } #2发起基于ajax的post请求 response = requests.post(url=post_url,headers=headers,data=data) response.text
7.综合项目实战
# 需求:爬取搜狗知乎某一个词条对应一定范围页码表示的页面数据 #前三页页面数据(1,2,3) import requests import os #创建一个文件夹 if not os.path.exists('./pages'): os.mkdir('./pages') word = input('enter a word:') #动态指定页码的范围 start_pageNum = int(input('enter a start pageNum:')) end_pageNum = int(input('enter a end pageNum:')) #自定义请求头信息 headers = { 'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36', } #1.指定url:设计成一个具有通用的url url = 'https://zhihu.sogou.com/zhihu' for page in range(start_pageNum,end_pageNum+1): param = { 'query':word, 'page':page, 'ie':'utf-8' } response = requests.get(url=url,params=param,headers=headers) #获取响应中的页面数据(指定页码(page)) page_text = response.text #进行持久化存储 fileName = word+str(page)+'.html' filePath = 'pages/'+fileName with open(filePath,'w',encoding='utf-8') as fp: fp.write(page_text) print('第%d页数据写入成功'%page)
8.高级
requests模块高级: - cookie: 基于用户的用户数据 - 需求:爬取张三用户的豆瓣网的个人主页页面数据 - cookie作用:服务器端使用cookie来记录客户端的状态信息。 实现流程: 1.执行登录操作(获取cookie) 2.在发起个人主页请求时,需要将cookie携带到该请求中 注意:session对象:发送请求(会将cookie对象进行自动存储)
import requests session = requests.session() #1.发起登录请求:将cookie获取,切存储到session对象中 login_url = 'https://accounts.douban.com/login' data = { "source": "None", "redir": "https://www.douban.com/people/185687620/", "form_email": "15027900535", "form_password": "bobo@15027900535", "login": "登录", } headers={ 'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36', } #使用session发起post请求 login_response = session.post(url=login_url,data=data,headers=headers) #2.对个人主页发起请求(session(cookie)),获取响应页面数据 url = 'https://www.douban.com/people/185687620/' response = session.get(url=url,headers=headers) page_text = response.text with open('./douban110.html','w',encoding='utf-8') as fp: fp.write(page_text)
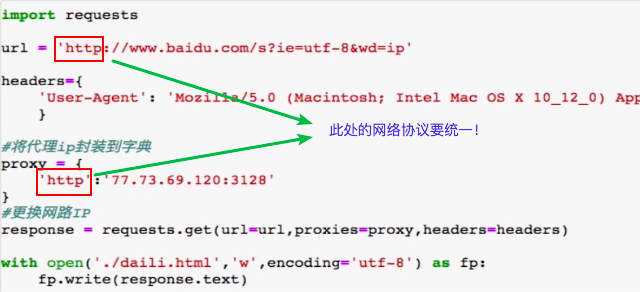
9.代理操作
代理操作: - 1.代理:第三方代理本体执行相关的事物。生活:代购,微商,中介 - 2.为什么要使用代理? - 反爬操作。 - 反反爬手段 - 3.分类: - 正向代理:代替客户端获取数据 - 反向代理:代理服务器端提供数据 - 4.免费代理ip的网站提供商: - www.goubanjia.com - 快代理 - 西祠代理 - 5.代码:
import requests url = 'http://www.baidu.com/s?ie=utf-8&wd=ip' headers={ 'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36', } #将代理ip封装到字典 proxy = { 'http':'77.73.69.120:3128' } #更换网路IP response = requests.get(url=url,proxies=proxy,headers=headers) with open('./daili.html','w',encoding='utf-8') as fp: fp.write(response.text)
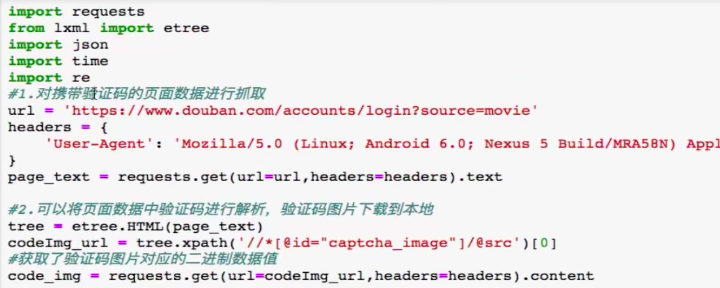
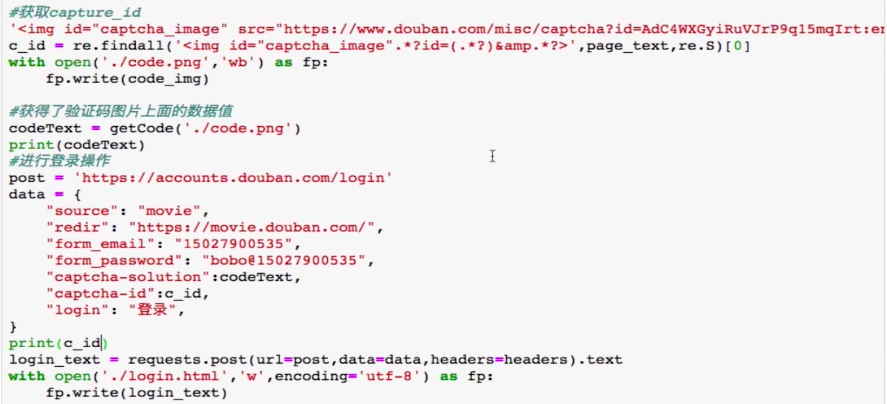
07-验证码的处理

- 主代码
- 识别验证码的函数


# 验证码类型:在此查询所有类型的网址: http://www.yundama.com/price.html # 验证码图片文件 filename = codeImg # 不定长字符 codetype = 3000 # 超时时间 timeout = 20
08-三种数据解析的方式
1.正则回顾
import re #提取出python key="javapythonc++php" re.findall('python',key)[0] # 结果:'python' #提取出hello world key="<html><h1>hello world<h1></html>" re.findall('<h1>hello world<h1>',key)[0] # 结果:'<h1>hello world<h1>' #提取170 string = '我喜欢身高为170的女孩' re.findall('d+',string) # 结果:['170'] #提取出http://和https:// key='http://www.baidu.com and https://boob.com' re.findall('https{0,1}',key) # 结果:['http', 'https'] #提取出hit. key='bobo@hit.edu.com' re.findall('h.*?.',key) #贪婪模式:根据正则表达式尽可能多的提取出数据 # 结果:['hit.'] #匹配sas和saas key='saas and sas and saaas' re.findall('sa{1,2}s',key) # 结果:['saas', 'sas'] #匹配出i开头的行 re.S(基于单行) re.M(基于多行) string = '''fall in love with you i love you very much i love she i love her''' re.findall('^i.*',string,re.M) # 结果:['i love you very much', 'i love she', 'i love her'] #匹配全部行 string = """<div>静夜思 窗前明月光 疑是地上霜 举头望明月 低头思故乡 </div>""" re.findall('<div>.*</div>',string,re.S) # 结果:['<div>静夜思 窗前明月光 疑是地上霜 举头望明月 低头思故乡 </div>']
2.正则演练
# 需求:使用正则对糗事百科中的图片数据进行解析和下载 ''' <div class="thumb"> <a href="/article/121159481" target="_blank"> <img src="//pic.qiushibaike.com/system/pictures/12115/121159481/medium/CIYK4P1D4DKSBY4L.jpg" alt="不是臭咸鱼吗"> </a> </div> ''' import requests import re import os #指定url url = 'https://www.qiushibaike.com/pic/' headers={ 'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36', } #发起请求 response = requests.get(url=url,headers=headers) #获取页面数据 page_text = response.text #数据解析(该列表中存储的就是当前页面源码中所有的图片链接) img_list = re.findall('<div class="thumb">.*?<img src="(.*?)".*?>.*?</div>',page_text,re.S) #创建一个存储图片数据的文件夹 if not os.path.exists('./imgs'): os.mkdir('imgs') for url in img_list: #将图片的url进行拼接,拼接成一个完成的url img_url = 'https:' + url #持久化存储:存储的是图片的数据,并不是url。 #获取图片二进制的数据值 img_data = requests.get(url=img_url,headers=headers).content imgName = url.split('/')[-1] imgPath = 'imgs/'+imgName with open(imgPath,'wb') as fp: fp.write(img_data) print(imgName+'写入成功')
# 爬去指定页码的图片数据
3.xpath
xpath在爬虫中的使用流程: - 1.下载:pip install lxml - 2.导包:from lxml import etree - 3.创建etree对象进行指定数据的解析 - 本地:etree=etree.parse('本地文件路径') etree.xpath('xpath表达式') - 网络:etree=etree.HTML('网络请求到的页面数据') etree.xpath('xpath表达式')
常用的xpath表达式: 属性定位: # 找到class属性值为song的div标签 //div[@class="song"]
层级&索引定位: # 找到class属性值为tang的div的直系子标签ul下的第二个子标签li下的直系子标签a //div[@class="tang"]/ul/li[2]/a
逻辑运算: # 找到href属性值为空且class属性值为du的a标签 //a[@href="" and @class="du"]
模糊匹配: //div[contains(@class, "ng")] //div[starts-with(@class, "ta")] 取文本: # /表示获取某个标签下的文本内容 # //表示获取某个标签下的文本内容和所有子标签下的文本内容 //div[@class="song"]/p[1]/text() //div[@class="tang"]//text()
取属性: //div[@class="tang"]//li[2]/a/@href
from lxml import etree #xpath函数返回的总是一个列表 #创建etree对象进行指定数据解析 tree = etree.parse('./test.html') #属性定位:根据指定的属性定位到指定的节点标签 #tree.xpath('//div[@class="song"] ') #层级索引定位 #tree.xpath('//div[@class="tang"]/ul/li[2]/a') #逻辑定位 #tree.xpath('//a[@href="" and @class="du"]') #模糊查询 #tree.xpath('//div[contains(@class, "ng")]') #tree.xpath('//div[starts-with(@class, "ta")]') #取文本 #tree.xpath('//div[@class="song"]/p[1]/text()') #/text()获取当前标签中直系存储的文本数据 #tree.xpath('//div[@class="tang"]//text()') #//text()获取某一个标签下所有子标签中存储的文本数据 #取属性 tree.xpath('//div[@class="tang"]//li[2]/a/@href') # 结果:['http://www.163.com']
xpath插件:就可以直接将xpath表达式作用于浏览器的网页当中 安装:更多工具-》扩展程序-》开启右上角的开发者模式-》xpath插件拖动到页面即可 快捷键: 开启和关闭xpath插件:ctrol+shitf+x
4.bs4
Beautiful解析: - python独有。简单便捷和高效。 环境安装: 需要将pip源设置为国内源,阿里源、豆瓣源、网易源等 windows (1)打开文件资源管理器(文件夹地址栏中) (2)地址栏上面输入 %appdata% (3)在这里面新建一个文件夹 pip (4)在pip文件夹里面新建一个文件叫做 pip.ini ,内容写如下即可 [global] timeout = 6000 index-url = https://mirrors.aliyun.com/pypi/simple/ trusted-host = mirrors.aliyun.com
-------------------------分割线---------------------------- linux (1)cd ~ (2)mkdir ~/.pip (3)vi ~/.pip/pip.conf (4)编辑内容,和windows一模一样
需要安装:
pip install bs4 bs4在使用时候需要一个第三方库,把这个库也安装一下 pip install lxml
代码的使用流程: 核心思想:将html文档转换成Beautiful对象,然后调用该对象中的属性和方法进行html文档指定内容的定位查找。 导包:
from bs4 import BeautifulSoup 创建Beautiful对象: - 如果html文档的来源是来源于本地: Beautiful('open('本地的html文件')','lxml') - 如果html是来源于网络 Beautiful(‘网络请求到的页面数据’,‘lxml’) 属性和方法:
(1)根据标签名查找 - soup.a 只能找到第一个符合要求的标签
(2)获取属性 - soup.a.attrs 获取a所有的属性和属性值,返回一个字典 - soup.a.attrs['href'] 获取href属性 - soup.a['href'] 也可简写为这种形式
(3)获取内容 - soup.a.string 相当于xpath里的/text() - soup.a.text //text() - soup.a.get_text() //text() 【注意】如果标签还有标签,那么string获取到的结果为None,而其它两个,可以获取文本内容
(4)find:找到第一个符合要求的标签 - soup.find('a') 找到第一个符合要求的 - soup.find('a', title="xxx") - soup.find('a', alt="xxx") - soup.find('a', class_="xxx") - soup.find('a', id="xxx")
(5)find_All:找到所有符合要求的标签 - soup.find_All('a') - soup.find_All(['a','b']) 找到所有的a和b标签 - soup.find_All('a', limit=2) 限制前两个
(6)根据选择器选择指定的内容 select:soup.select('#feng') - 常见的选择器:标签选择器(a)、类选择器(.)、id选择器(#)、层级选择器 - 层级选择器: div .dudu #lala .meme .xixi 下面好多级 div//img div > p > a > .lala 只能是下面一级 div/img 【注意】select选择器返回永远是列表,需要通过下标提取指定的对象
项目实战:
# 需求:爬取古诗文网中三国小说里的标题和内容 import requests from bs4 import BeautifulSoup url = 'http://www.shicimingju.com/book/sanguoyanyi.html' headers = { 'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36', } # 根据url获取页面指定标题所对应的内容 def get_content(currents_url): content_page = requests.get(url=currents_url, headers=headers).text soup1 = BeautifulSoup(content_page, 'lxml') div = soup1.find('div', class_='chapter_content') return div.text page_text = requests.get(url=url, headers=headers).text # 数据解析 soup = BeautifulSoup(page_text, 'lxml') # a_list 存储的是一系列的a标签对象 a_list = soup.select('.book-mulu > ul > li > a') print(a_list[0], type(a_list[0])) # type(a_list[0])的类型是 <class 'bs4.element.Tag'> # 注意:Tag类型的对象可以继续调用相应的属性和方法进行局部数据的解析 for a in a_list: # 获取章节的标题 title = a.string # print(title) # 获取章节内容的url current_url = 'http://www.shicimingju.com' + a['href'] # 获取章节内容 content = get_content(current_url) # print(content) # fp = open('./sanguo/%s%s' % (title, '.txt'), 'w', encoding='utf-8') with open('./sanguo/%s' % title, 'w', encoding='utf-8') as e: e.write(title + ':' + content) print('%s' % title, "写入成功!")
09-selenium的使用
1.selenum:三方库。可以实现让浏览器完成自动化的操作。 2.环境搭建 2.1 安装:pip install selenium 2.2 获取浏览器的驱动程序 下载地址: http://chromedriver.storage.googleapis.com/index.html 浏览器版本和驱动版本的对应关系表:
https://blog.csdn.net/huilan_same/article/details/51896672
#使用下面的方法,查找指定的元素进行操作即可 find_element_by_id 根据id找节点 find_elements_by_name 根据name找 find_elements_by_xpath 根据xpath查找 find_elements_by_tag_name 根据标签名找 find_elements_by_class_name 根据class名字查找
import time from selenium import webdriver # 创建一个浏览器对象, 参数 executable_path 驱动路径 bro = webdriver.Chrome(executable_path='./chromedriver.exe') # get 方法可以指定一个url, 让浏览器进行请求 bro.get('https://www.baidu.com') # time.sleep(2) # 让百度进行指定词条的搜索 text = bro.find_element_by_id(id_='kw') # 定位到text文本框 # send_keys表示向文本框中输入内容 text.send_keys('人民币') # time.sleep(2) # 进行搜索操作 button = bro.find_element_by_id('su') # 点击搜索按钮 button.click() # 关闭浏览器 bro.quit()
10-phantomJs的使用
# phantomJs: 无界面浏览器,其自动化流程同上述的谷歌自动化流程一致。 from selenium import webdriver # 创建浏览器 bro = webdriver.PhantomJS(executable_path='./phantomjs') # 打开浏览器 bro.get('https://www.baidu.com') # 截屏操作 bro.save_screenshot('./1.png') # 让百度进行指定词条的搜索 text = bro.find_element_by_id(id_='kw') # 定位到text文本框 # send_keys表示向文本框中输入内容 text.send_keys('人民币') # 进行搜索操作 button = bro.find_element_by_id('su') # 点击搜索按钮 button.click() # 截屏操作 bro.save_screenshot('./2.png') bro.quit()
项目实战:使用selenium+phantomJs处理页面动态加载数据的爬取
# 需求:获取豆瓣电影中动态加载出更多电影详情数据 from selenium import webdriver from time import sleep bro = webdriver.PhantomJS(executable_path='./phantomjs') url = 'https://movie.douban.com/typerank?type_name=%E5%96%9C%E5%89%A7&type=24&interval_id=100:90&action=' bro.get(url) sleep(1) # 截屏 bro.save_screenshot('./1.png') # 编写js代码:让页面中的滚轮向下滑动(底部) js = 'window.scrollTo(0,document.body.scrollHeight)' # 如何让浏览器对象执行js代码 bro.execute_script(js) sleep(1) # 截屏 bro.save_screenshot('./2.png') bro.execute_script(js) bro.save_screenshot('./3.png') # 获取加载数据后的页面:page_sourse获取浏览器当前的页面数据 page_text = bro.page_source print(page_text)