01-scrapy介绍
02-项目的目录结构:
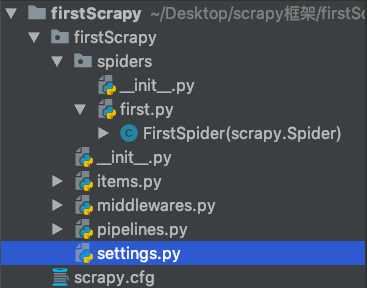
scrapy.cfg 项目的主配置信息。(真正爬虫相关的配置信息在settings.py 文件中)
items.py 设置数据存储模板,用于结构化数据,如:Django的model
pipelines 数据持久化处理
settings.py 配置文件
spiders 爬虫目录,如:创建文件,编写爬虫解析规则
03-配置文件settings.py的配置
# 建议修改:
ROBOTSTXT_OBEY = False # 默认为True
# 进行身份伪装
USER_AGENT = "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.87 Safari/537.36"
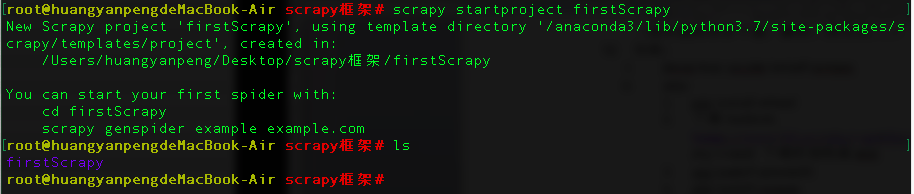
04-创建项目和爬虫文件
# 创建项目
scrapy startproject firstScrapy
# 先切换到项目文件里
cd firstScrapy/
# 然后执行创建
scrapy genspider first www.qiushibaike.com
05-执行
# 执行爬取程序, first 为爬虫文件名称
scrapy crawl first
# 此方式是阻止日志信息的输出
scrapy crawl first --nolog
06-基于终端指令的持久化存储
持久化存储操作:
a.磁盘文件
a)基于终端指令
i.保证parse方法返回一个可迭代类型的对象(存储解析到的页面内容)
ii.使用终端指令完成数据存储到制定磁盘文件中的操作
1.scrapy crawl 爬虫文件名称 –o 磁盘文件.后缀
b)基于管道
i.items:存储解析到的页面数据
ii.pipelines:处理持久化存储的相关操作
iii.代码实现流程:
1.将解析到的页面数据存储到items对象
2.使用yield关键字将items提交给管道文件进行处理
3.在管道文件中编写代码完成数据存储的操作
4.在配置文件中开启管道操作
b.数据库
a)mysql
b)redis
c)编码流程:
1.将解析到的页面数据存储到items对象
2.使用yield关键字将items提交给管道文件进行处理
3.在管道文件中编写代码完成数据存储的操作
4.在配置文件中开启管道操作
需求:将爬取到的数据值分别存储到本地磁盘、redis数据库、mysql数据。
1.需要在管道文件中编写对应平台的管道类
2.在配置文件中对自定义的管道类进行生效操
# 案例:
# firstScrapy/spiders/first.py
# -*- coding: utf-8 -*-
import scrapy
class FirstSpider(scrapy.Spider):
# 爬虫文件的名称name
name = 'first'
# 允许的域名:只允许爬取当前域名下的页面数据
# allowed_domains = ['www.qiushibaike.com/text/']
# 起始的url:当前工程所要爬取的页面所对应的url
# 注意:start_urls 是 allowed_domains 下的页面的url
start_urls = ['https://www.qiushibaike.com/text/']
# 解析方法:对获取的页面数据进行指定内容的解析
# response:请求成功后返回的响应对象
# parse 方法的返回值,必须为迭代器 或者为 空None
def parse(self, response):
# 建议大家用xpath 进行指定内容的解析(框架集成了xpath解析的接口)
# 获取段子的内容和作者
div_list = response.xpath('//div[@id="content-left"]/div')
# 存储解析到的页面数据
data_list = []
for div in div_list:
# xpath解析到的指定内容被存储到 Selector对象
# extract() 该方法可以将 Selector对象 中存储的数据值拿到
# author = div.xpath('./div/a[2]/h2/text()').extract()[0]
# extract_first() == extract()[0]
author = div.xpath('./div/a[2]/h2/text()').extract_first()
content = div.xpath('.//div[@class="content"]/span/text()').extract_first()
dict_data = {
'author': author,
'content': content
}
data_list.append(dict_data)
return data_list
# 在终端执行命令:(在first爬虫文件下)
scrapy crawl first -o qiubai.csv --nolog
07-基于管道的持久化存储
# 修改配置文件settings.py
# 打开注释
ITEM_PIPELINES = {
'firstScrapy.pipelines.FirstscrapyPipeline': 300,
}
# firstScrapy/first.py
# -*- coding: utf-8 -*-
import scrapy
from firstScrapy.items import FirstscrapyItem
class FirstSpider(scrapy.Spider):
# 爬虫文件的名称name
name = 'first'
start_urls = ['https://www.qiushibaike.com/text/']
def parse(self, response):
# 获取段子的内容和作者
div_list = response.xpath('//div[@id="content-left"]/div')
for div in div_list:
author = div.xpath('./div/a[2]/h2/text()').extract_first()
content = div.xpath('.//div[@class="content"]/span/text()').extract_first()
# 1.将解析到的数据值(author和content)存储到items对象中
item = FirstscrapyItem()
item['author'] = author
item['content'] = content
# 2.将item对象提交给管道
yield item
# firstScrapy/items.py
import scrapy
class FirstscrapyItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
author = scrapy.Field()
content = scrapy.Field()
# firstScrapy/pipelines.py
class FirstscrapyPipeline(object):
fp = None
# open_spider 在整个爬虫过程中,该方法只会在开始爬虫的时候,被调用一次!
def open_spider(self, spider):
print("开始爬虫")
self.fp = open('./qiubai_pipe.txt', 'w', encoding='utf-8')
# 3.在管道文件中编写代码完成数据储存的操作
# process_item 该方法就可以接受爬虫文件中提交过来的item对象,并且对item对象中存储的页面数据进行持久化存储
# 参数:item 表示的是 接收到的item对象
# 每当爬虫文件向管道提交一次item,则该方法就会被执行一次!
def process_item(self, item, spider):
# 取出item对象中存储的数据值
author = item['author']
content = item['content']
# 持久化存储
self.fp.write(author + ':' + content + '
')
return item
# 只会在爬虫结束的时候,被调用一次!
def close_spider(self, spider):
print('爬虫结束!')
self.fp.close()
08-基于MySQL的持久化存储
# pipelines.py
import pymysql
class FirstscrapyPipeline(object):
conn = None
cursor = None
def open_spider(self, spider):
print("爬虫开始!")
# 链接数据库
self.conn = pymysql.Connect(host='127.0.0.1', port=3306, user='root', passwd='123456', db='qiubai')
# 编写向数据库中存储数据的相关代码
def process_item(self, item, spider):
# 1.连接数据库
# 2.执行sql语句
sql = 'insert into qiubai values("%s", "%s")' % (item['author'], item['content'])
self.cursor = self.conn.cursor()
try:
self.cursor.execute(sql)
# 3.提交事务
self.conn.commit()
except Exception as e:
print(e)
self.conn.rollback()
# 取出item对象中存储的数据值
author = item['author']
content = item['content']
return item
def close_spider(self, spider):
print("爬虫结束!")
self.cursor.close()
self.conn.close()
09-基于redis的持久化存储
# pipelines.py
import redis
class FirstscrapyPipeline(object):
conn = None
cursor = None
def open_spider(self, spider):
print("爬虫开始!")
# 链接redis数据库
self.conn = redis.Redis(host='127.0.0.1', port=6379)
# 编写向数据库中存储数据的相关代码
def process_item(self, item, spider):
dict_data = {
'author': item['author'],
'content': item['content'],
}
self.conn.lpush('data', dict_data)
return item
10-管道的高级操作
# 修改配置文件settings.py
ITEM_PIPELINES = {
'firstScrapy.pipelines.FirstscrapyPipeline': 300,
'firstScrapy.pipelines.FirstByFiles': 200,
'firstScrapy.pipelines.FirstByMysql': 400,
}
# 需求:将爬取到的数据值分别存储到本地磁盘、redis数据库、mysql数据。
1.需要在管道文件中编写对应平台的管道类
2.在配置文件中对自定义的管道类进行生效操作
# pipelines.py
import redis
import pymysql
class FirstscrapyPipeline(object):
conn = None
cursor = None
def open_spider(self, spider):
print("爬虫开始!")
# 链接redis数据库
self.conn = redis.Redis(host='127.0.0.1', port=6379)
# 编写向数据库中存储数据的相关代码
def process_item(self, item, spider):
dict_data = {
'author': item['author'],
'content': item['content'],
}
self.conn.lpush('data', dict_data)
return item
# 实现将数据值存储到本地磁盘中
class FirstByFiles(object):
def process_item(self, item, spider):
print('数据已经写入指定的磁盘文件中')
return item
class FirstByMysql(object):
def process_item(self, item, spider):
print('数据已经写入到MySQL数据库中')
return item
11-就多个url的数据爬取
# 解决方案:请求的手动发送
# spider.py/qiubai.py
# -*- coding: utf-8 -*-
import scrapy
from qiubaiByPages.items import QiubaibypagesItem
class QiubaiSpider(scrapy.Spider):
name = 'qiubai'
# allowed_domains = ['www.qiushibaike.com/text']
start_urls = ['https://www.qiushibaike.com/text/']
# 设计一个通用的url模板
url = 'https://www.qiushibaike.com/text/page/%d/'
pageNum = 1
def parse(self, response):
div_list = response.xpath('//*[@id="content-left"]/div')
for div in div_list:
author = div.xpath('./div[@class="author clearfix"]/a[2]/h2/text()').extract_first()
content = div.xpath('.//div[@class="content"]/span/text()').extract_first()
item = QiubaibypagesItem()
item['author'] = author
item['content'] = content
yield item
# 请求的手动发送
if self.pageNum <= 13:
print('爬取了第%s的页面数据!' % self.pageNum)
self.pageNum += 1
new_url = format(self.url % self.pageNum)
# callback 将请求获取的页面数据进行解析
yield scrapy.Request(url=new_url, callback=self.parse)