写这篇博文的目的是想把单例模式在自己目前的理解程度上解释明白,话不多说,进入正题。
什么样的对象适合做成单例?我看到最经典的回答是,能做成单例的类,在整个应用中,同一时刻,有且只能有一种状态。换句话说,这些类无论是实例化多少个,其实都是一样的,而且更重要的一点是,这个类如果有两个或者两个以上的实例的话,我的程序竟然会产生程序错误。
最原始的单例模式长这样,
public class Singleton { //一个静态的实例 private static Singleton singleton; //私有化构造函数 private Singleton(){} //给出一个公共的静态方法返回一个单一实例 public static Singleton getInstance(){ if (singleton == null) { singleton = new Singleton(); } return singleton; } }
这是在不考虑并发的情况下单例模式的写法,有几个关键点:
- 静态实例,带有static关键字的属性在每一个类中都是唯一的。
- 限制客户端随意创造实例,即私有化构造方法,此为保证单例的最重要的一步。
- 给一个公共的获取实例的静态方法,注意,是静态方法,因为这个方法是在我们未获取到实例的时候就要提供给客户端调用的,所以如果是非静态的话,那就变成一个矛盾体了,因为非静态的方法必须要拥有实例才可以调用。
- 判断只有持有的静态实例为null时才调用构造方法创造一个实例,否则直接返回。
假如你面试一家公司,让你写出单例模式的例子,你按上面的写了,那么如果你刚毕业,可能这道题就过了,但是如果你已经有两年工作经验了,那这道题肯定不及格。为什么呢,因为没有考虑并发。像上面这种写法,在并发环境中是不正确的,线程A进入getInstance方法,判断了静态实例为空,准备创建实例,这时线程B入场,在线程A没有实例化完成对象前又判断对象为空,就会再次实例化对象,导致两个线程得到两个不同实例,这是错的。
为了证明在并发条件下这样写是错误的,我写了一个例子,其中用到了两个闭锁startGate和endGate,startGate是让多个线程同时执行,endGate是等待最慢的线程执行完毕。闭锁包括一个计数器,该计数器被初始化为一个正数,表示需要等待的事件数量。countDown方法递减计数器,表示有一个事件已经发生了,而await方法等待计数器达到零,这表示所有需要等待的事件都已经发生。如果计数器的值非零,那么await会一直阻塞直到计数器为零,或等待中的线程中断,或等待超时。countDown和await方法是配合使用的。
import java.util.Collections; import java.util.HashSet; import java.util.Set; import java.util.concurrent.CountDownLatch; import java.util.concurrent.ExecutorService; import java.util.concurrent.Executors; public class TestSingleton { public static void main(String[] args) throws InterruptedException { final Set<String> instanceSet = Collections.synchronizedSet(new HashSet<String>()); final Runnable task = new Runnable() { @Override public void run() { Singleton singleton = Singleton.getInstance(); instanceSet.add(singleton.toString()); } }; long time = timeTasks(100,task); System.out.println("耗时:"+time+"纳秒"); for (String instance : instanceSet) { System.out.println(instance); } } /** * 并发nThreads个线程一起执行,并等待最慢的线程执行完成,返回执行时间(纳秒) * @param nThreads 线程数 * @param task 任务 * @return 执行时间(纳秒) * @throws InterruptedException */ public static long timeTasks(int nThreads,final Runnable task) throws InterruptedException { final CountDownLatch startGate = new CountDownLatch(1); final CountDownLatch endGate = new CountDownLatch(nThreads); ExecutorService executorService = Executors.newCachedThreadPool(); for (int i = 0; i < nThreads; i++) { executorService.execute(new Runnable() { @Override public void run() { try { startGate.await(); try { task.run(); } finally { endGate.countDown(); } } catch(InterruptedException e){} } }); } long startTime = System.nanoTime(); startGate.countDown(); endGate.await(); long endTime = System.nanoTime(); return endTime - startTime; } }
LZ并发100个线程,第一次执行得到的结果就是集合中有两个不同实例。

怎么解决呢,最容易想到的方案是将getInstance做成同步方法,同一时刻只有一个线程能执行该方法。
public class BadSynchronizedSingleton { //一个静态的实例 private static BadSynchronizedSingleton synchronizedSingleton; //私有化构造函数 private BadSynchronizedSingleton(){} //给出一个公共的静态方法返回一个单一实例 public synchronized static BadSynchronizedSingleton getInstance(){ if (synchronizedSingleton == null) { synchronizedSingleton = new BadSynchronizedSingleton(); } return synchronizedSingleton; } }
直接将整个方法同步,是一种很无脑的做法,synchronized将导致性能开销,如果getInstance()方法被多个线程频繁调用,将会导致程序执行性能的下降。
在早期的JVM中,synchronized存在巨大的性能开销。因此,人们想出了一个“聪明”的技巧:双重检查锁定,也就是双重加锁,相比之下,我觉得双重检查锁定这个词表达更直接一点。我们看实现。
public class DoubleCheckedLocking { // 1 private static Instance instance; // 2 public static Instance getInstance() { // 3 if (instance == null) { // 4:第一次检查 synchronized (DoubleCheckedLocking.class) { // 5:加锁 if (instance == null) // 6:第二次检查 instance = new Instance(); // 7:问题的根源出在这里 } // 8 } // 9 return instance; // 10 } // 11 private DoubleCheckedLocking(){} }
如上面代码所示,如果第一次检查instance不为null,那么就不需要执行下面的加锁和初始化操作,因为,第一次检查可以大幅度降低synchronized带来的性能开销。有疑问的地方可能在于第二次检查的意义在哪里,不是只对对象的实例化过程加锁吗,用同步代码块将instance = new Instance();包起来就可以了吧。我们想象这样一个情况,假设A线程和B线程都在同步块外面判断了synchronizedSingleton为null,结果A线程首先获得了线程锁,进入了同步块,然后A线程会创造一个实例,此时synchronizedSingleton已经被赋予了实例,A线程退出同步块,直接返回了第一个创造的实例,此时B线程获得线程锁,也进入同步块,此时A线程其实已经创造好了实例,B线程正常情况应该直接返回的,但是因为同步块里没有判断是否为null,直接就是一条创建实例的语句,所以B线程也会创造一个实例返回,此时就造成创造了多个实例的情况。
双重检查锁定看起来似乎很完美,但是这是一个错误的优化!在线程执行到第4行,代码读到instance不为null时,instance引用的对象有可能还没有实例化完成。问题的根源在第7行(instance = new Instance();),JVM创建对象的时候大概分3步:
- 分配空间
- 初始化对象
- 设置instance指向刚分配的内存地址
上面2和3之间,可能会被重排序也就是先设置instance指向刚分配的内存地址,然后再初始化对象,这种重排序是真实存在的,JVM这样做的目的是提高程序的执行性能,这块内容以后再整理,假如线程A在2和3之间发生重排序,另一个并发执行的线程B就有可能在第4行判断instance不为null。线程B接下来将访问instance所引用的对象,但此时这个对象可能还没有被A线程初始化,问题的根源就在这里。
在了解了问题的根源后,可以想到两个办法来解决这个问题。
- 不允许2和3重排序
- 允许2和3重排序,但不允许其他线程“看到”这个重排序。
1、基于volatile的解决方案
对于上面的基于双重检查锁定来实现延迟初始化的方案,只需要做一点小的修改,把instance声明为volatile类型,就可以实现线程安全的延迟初始化。
public class SafeDoubleCheckedLocking { private volatile static Instance instance; public static Instance getInstance() { if (instance == null) { synchronized (SafeDoubleCheckedLocking.class) { if (instance == null) instance = new Instance(); // instance为volatile,现在没问题了 } } return instance; } private SafeDoubleCheckedLocking(){} }
当声明对象的引用为volatile后,2和3的重排序,在多线程环境中将会被禁止。注意,这个解决方案需要JDK5或更高版本。(因为从JDK5开始使用新的JSR-133内存模型规范,这个规范增强了volatile的语义)。
2、基于类初始化的解决方案
JVM在类的初始化阶段(即在Class被加载后,且被线程使用之前),会执行类的初始化。在执行类的初始化期间,JVM会去获得一个锁。这个锁可以同步多个线程对同一个类的初始化。
基于这个特性,可以实现另一种线程安全的单例模式(这个方案被称为Initialization On Demand Holder idiom)。
public class Singleton { private Singleton(){} public static Singleton getInstance(){ return InstanceHolder.instance; } private static class InstanceHolder{ static Singleton instance = new Singleton(); } }
假设两个线程并发执行getInstance()方法,下面是执行的示意图。
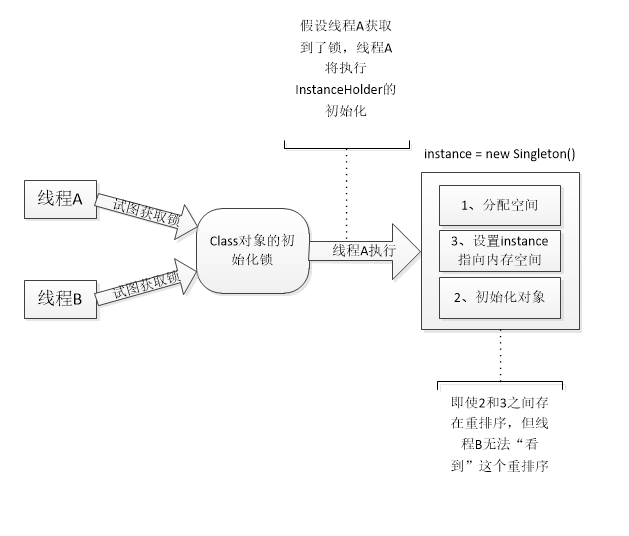
到这里,单例模式的最终版本终于浮出水面,也就是基于类初始化的解决方案。这种写法不依赖JDK版本,在并发环境下保证万无一失。它保证了以下几点。
1.Singleton最多只有一个实例,在不考虑反射强行突破访问限制的情况下。
2.保证了并发访问的情况下,不会发生由于并发而产生多个实例。
3.保证了并发访问的情况下,不会由于初始化动作未完全完成而造成使用了尚未正确初始化的实例。
如果面试官再次问到单例模式,按这样的思路回答,有时间的话将每个版本写出来,优劣一一讲出来,应该可以过关。
===============2019.12.07补充================
单例模式中的饿汉式是线程安全的,饿汉式是在类加载的时候创建对象,只创建一次。
//饿汉式单例 // 它是在类加载的时候就立即初始化,并且创建单例对象 //优点:没有加任何的锁、执行效率比较高, //在用户体验上来说,比懒汉式更好 //缺点:类加载的时候就初始化,不管你用还是不用,我都占着空间 //浪费了内存,有可能占着茅坑不拉屎 //绝对线程安全,在线程还没出现以前就是实例化了,不可能存在访问安全问题 public class HungrySingleton { private static final HungrySingleton hungrySingleton = new HungrySingleton(); private HungrySingleton(){} public static HungrySingleton getInstance(){ return hungrySingleton; } }
再提供饿汉式另外一种等效写法。
//饿汉式静态块单例 public class HungryStaticSingleton { private static final HungryStaticSingleton hungrySingleton; static { hungrySingleton = new HungryStaticSingleton(); } private HungryStaticSingleton(){} public static HungryStaticSingleton getInstance(){ return hungrySingleton; } }
一.反射暴力攻击单例解决方案及原理分析
单例模式还可以继续扩展讨论,既然是单例,在一个进程中有且只有一种状态,也就是唯一一个实例。那么,如果我用反射强行突破访问呢?要知道反射是有这个本事的,我们来举一个例子,假如,我的单例模式按照上文的最终版本这么去写的,我这里为了连贯性再写一遍。
//懒汉式单例 //这种形式兼顾饿汉式的内存浪费,也兼顾synchronized性能问题 //完美地屏蔽了这两个缺点 //史上最牛B的单例模式的实现方式 public class LazyInnerClassSingleton { //默认使用LazyInnerClassGeneral的时候,会先初始化内部类 //如果没使用的话,内部类是不加载的 private LazyInnerClassSingleton(){} //每一个关键字都不是多余的 //static 是为了使单例的空间共享 //final 保证这个方法不会被重写,重载 public static final LazyInnerClassSingleton getInstance(){ //在返回结果以前,一定会先加载内部类 return LazyHolder.LAZY; } //默认不加载 private static class LazyHolder{ private static final LazyInnerClassSingleton LAZY = new LazyInnerClassSingleton(); } }
史上最牛B是吧,好,那么来了,我就不走寻常路,我就要装B,我用反射强行突破你的封装,看能不能拿到两个实例。
import java.lang.reflect.Constructor; public class LazyInnerClassSingletonTest { public static void main(String[] args) { try{ //很无聊的情况下,进行破坏 Class<?> clazz = LazyInnerClassSingleton.class; //通过反射拿到私有的构造方法 Constructor c = clazz.getDeclaredConstructor(null); //强制访问,强吻,不愿意也要吻 c.setAccessible(true); //暴力初始化 Object o1 = c.newInstance(); //调用了两次构造方法,相当于new了两次 //犯了原则性问题, LazyInnerClassSingleton o2 = LazyInnerClassSingleton.getInstance(); System.out.println(o1 == o2); }catch (Exception e){ e.printStackTrace(); } } }
好了,看运行结果。
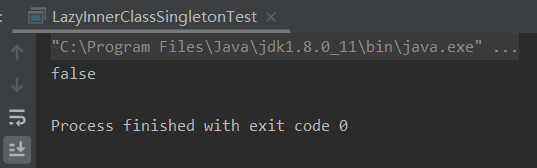
完美翻车,那么有什么解决办法吗?办法肯定是有的,问题的本质是反射是强行调用了我们私有的构造方法,如果在构造方法里加入判断,如果静态类内部的LAZY对象已经被实例化过了,就抛出一个运行时异常,不允许再次实例化就可以了,其实就两行代码。
//懒汉式单例 //这种形式兼顾饿汉式的内存浪费,也兼顾synchronized性能问题 //完美地屏蔽了这两个缺点 //史上最牛B的单例模式的实现方式 public class LazyInnerClassSingleton { //默认使用LazyInnerClassGeneral的时候,会先初始化内部类 //如果没使用的话,内部类是不加载的 private LazyInnerClassSingleton(){ if(LazyHolder.LAZY != null){ throw new RuntimeException("不允许创建多个实例"); } } //每一个关键字都不是多余的 //static 是为了使单例的空间共享 //final 保证这个方法不会被重写,重载 public static final LazyInnerClassSingleton getInstance(){ //在返回结果以前,一定会先加载内部类 return LazyHolder.LAZY; } //默认不加载 private static class LazyHolder{ private static final LazyInnerClassSingleton LAZY = new LazyInnerClassSingleton(); } }
我们再运行上边的测试用例,就不会出现这个问题。
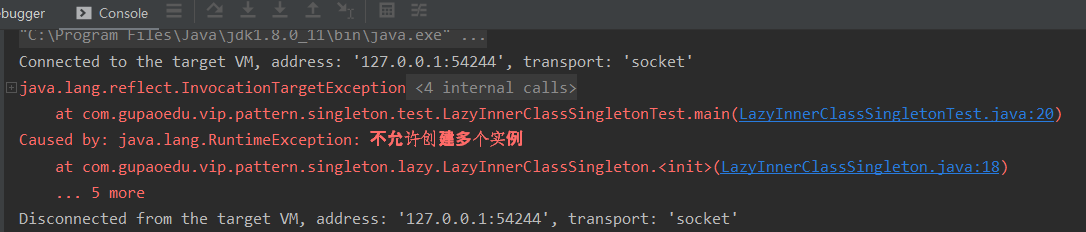
这样就保证了,我们的单例模式,只能通过LazyInnerClassSingleton.getInstance()的方式调用,再想用反射装B,就没戏了。
二.序列化破坏单例的原理及解决方案
装B这件事一旦上瘾,便是一去不回的,有什么办法能继续突破你的封装呢,是有的,我们用序列化和反序列化来试一下。这里我们用饿汉式举例,饿汉式号称绝对不会出现线程安全问题。我们先把饿汉式列举一下。
import java.io.Serializable; //反序列化时导致单例破坏 public class SeriableSingleton implements Serializable { //序列化就是说把内存中的状态通过转换成字节码的形式 //从而转换一个IO流,写入到其他地方(可以是磁盘、网络IO) //内存中状态给永久保存下来了 //反序列化 //讲已经持久化的字节码内容,转换为IO流 //通过IO流的读取,进而将读取的内容转换为Java对象 //在转换过程中会重新创建对象new public final static SeriableSingleton INSTANCE = new SeriableSingleton(); private SeriableSingleton(){} public static SeriableSingleton getInstance(){ return INSTANCE; } }
我现在写一个例子来对SeriableSingleton进行序列化和反序列化。
import java.io.FileInputStream; import java.io.FileOutputStream; import java.io.ObjectInputStream; import java.io.ObjectOutputStream; public class SeriableSingletonTest { public static void main(String[] args) { SeriableSingleton s1 = null; SeriableSingleton s2 = SeriableSingleton.getInstance(); FileOutputStream fos = null; try { fos = new FileOutputStream("SeriableSingleton.obj"); ObjectOutputStream oos = new ObjectOutputStream(fos); oos.writeObject(s2); oos.flush(); oos.close(); FileInputStream fis = new FileInputStream("SeriableSingleton.obj"); ObjectInputStream ois = new ObjectInputStream(fis); s1 = (SeriableSingleton)ois.readObject(); ois.close(); System.out.println(s1); System.out.println(s2); System.out.println(s1 == s2); } catch (Exception e) { e.printStackTrace(); } } }
我序列化到磁盘后,再反序列化回来,还是那个对象吗?我觉得应该不是,JDK应该是在反序列化的时候重新调用了构造方法,给我们重新创建了一个对象。因为原来的对象状态是不是变了,是不是被GC回收了,这都不可预知,重新创建应该是最保险的。我们运行一下。

果然如此,再次翻车,有没有解决办法,其实是有的,我这里先公布答案,我们再来分析为什么,其实只有给我们的饿汉式加一个readResolve方法就可以了。
import java.io.Serializable; //反序列化时导致单例破坏 public class SeriableSingleton implements Serializable { //序列化就是说把内存中的状态通过转换成字节码的形式 //从而转换一个IO流,写入到其他地方(可以是磁盘、网络IO) //内存中状态给永久保存下来了 //反序列化 //讲已经持久化的字节码内容,转换为IO流 //通过IO流的读取,进而将读取的内容转换为Java对象 //在转换过程中会重新创建对象new public final static SeriableSingleton INSTANCE = new SeriableSingleton(); private SeriableSingleton(){} public static SeriableSingleton getInstance(){ return INSTANCE; } //添加这个方法,序列化就不会再生成一个新对象 private Object readResolve(){ return INSTANCE; } }
运行一下。

这是为什么呢,我们很容易能想到,创建新对象,调用构造方法的地方应该是反序列化回来的时候,也就是ois.readObject()的时候,我们点进去看JDK源码,这里多一句嘴,千万不要排斥源码,千万千万。。。
1 public final Object readObject() 2 throws IOException, ClassNotFoundException 3 { 4 if (enableOverride) { 5 return readObjectOverride(); 6 } 7 8 // if nested read, passHandle contains handle of enclosing object 9 int outerHandle = passHandle; 10 try { 11 Object obj = readObject0(false); 12 handles.markDependency(outerHandle, passHandle); 13 ClassNotFoundException ex = handles.lookupException(passHandle); 14 if (ex != null) { 15 throw ex; 16 } 17 if (depth == 0) { 18 vlist.doCallbacks(); 19 } 20 return obj; 21 } finally { 22 passHandle = outerHandle; 23 if (closed && depth == 0) { 24 clear(); 25 } 26 } 27 }
核心方法是11行的readObject0方法,我们跟进去。篇幅问题不一一列举了,我们可以看到最后有一个swtch,如果序列化的事Object对象(1350行 jdk1.8),就执行。
private Object readObject0(boolean unshared) throws IOException { ... case TC_OBJECT: return checkResolve(readOrdinaryObject(unshared)); ... }
checkResolve方法不是重点,只是做一个校验,readOrdinaryObject方法才是,我们点进去,在1783行。
Object obj; try { obj = desc.isInstantiable() ? desc.newInstance() : null; } catch (Exception ex) { throw (IOException) new InvalidClassException( desc.forClass().getName(), "unable to create instance").initCause(ex); }
看到了反射的实例化操作了,印证了之前想法,如果有构造器,就用反射调用,创建一个新的对象出来。别急往下看。在1806行,有这么一段。
if (obj != null && handles.lookupException(passHandle) == null && desc.hasReadResolveMethod()) { Object rep = desc.invokeReadResolve(obj); if (unshared && rep.getClass().isArray()) { rep = cloneArray(rep); } if (rep != obj) { handles.setObject(passHandle, obj = rep); } }
desc.hasReadResolveMethod看到了吧,在这里,如果有readSolve方法,就去执行下面的逻辑,也就是执行readResolve方法。说到这里明白了吧,JDK源码就是这么写的,那JDK为什么要这么写呢,其实就是JDK的设计者当初已经想到序列化技术能穿透单例模式,在这里做的一种预防,我听课听到这里的时候鸡皮疙瘩起来了,真的。
第一次看源码,很不适应,如果看不懂,就多看几遍源码吧,我目前只能解释到这里。