更新语句的整体流程
-
连接数据库
-
清空当前表对应的所有缓存
-
分析器分析词法和语法
-
优化器决定使用什么索引
-
执行器负责具体执行
重要的日志模块:redo log
MySQL的WAL技术
- 全称是Write-Ahead Logging
- InnoDB 引擎特有的日志
- 先写日志,再写磁盘
- 详解如下:
1、当有一条记录需要更新的时候,InnoDB引擎就会把记录写到redo log里面,并且更新内存
2、InnoDB引擎会在适当的时候,将这个操作记录更新到磁盘里面
redo log存储在哪里?
InnoDB引擎先把记录写到redo log 中,redo log 在哪,它也是在磁盘上,这也是一个写磁盘的过程, 但是与更新过程不一样的是,更新过程是在磁盘上随机IO,费时。 而写redo log 是在磁盘上顺序IO。效率要高。
如果redo log满了怎么办?
InnoDB 的 redo log 是固定大小的,比如可以配置为一组 4 个文件,每个文件的大小是 1GB,那么总共就可以记录 4GB 的操作。从头开始写,写到末尾就又回到开头循环写。
重要的日志模块:binlog
- Mysql自带的日志模块
- 单独的binlog没有crash-safe的能力,只能用于归档
redo log和binlog的不同
- redo log 是 InnoDB 引擎特有的;binlog 是 MySQL 的 Server 层实现的,所有引擎都可以使用。
- redo log 是物理日志,记录的是“在某个数据页上做了什么修改”;binlog 是逻辑日志,记录的是这个语句的原始逻辑,比如“给 ID=2 这一行的 c 字段加 1 ”。
- redo log 是循环写的,空间固定会用完;binlog 是可以追加写入的。“追加写”是指 binlog 文件写到一定大小后会切换到下一个,并不会覆盖以前的日志。
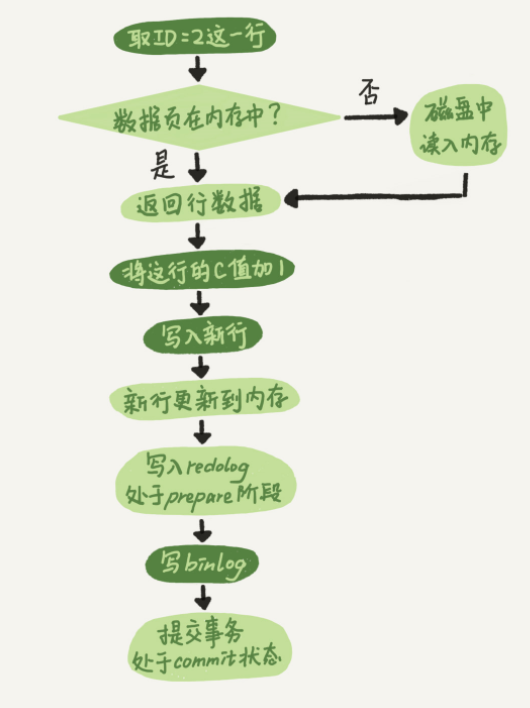
InnoDB引擎部分在执行这个简单的update语句的时候的内部流程
- mysql> update T set c=c+1 where ID=2;
- 执行器先找引擎取ID=2这一行。ID是主键,引擎直接用树搜索找到这一行。如果ID=2这一行所在的数据页本来就在内存中,就直接返回给执行器;否则,需要先从磁盘读入内存,然后再返回。
- 执行器拿到引擎给的行数据,把这个值加上1,比如原来是 N,现在就是 N+1,得到新的一行数据,再调用引擎接口写入这行新数据。
- 引擎将这行新数据更新到内存中,同时将这个更新操作记录到 redo log 里面,此时 redo log 处于 prepare 状态。然后告知执行器执行完成了,随时可以提交事务。
- 执行器生成这个操作的 binlog,并把 binlog 写入磁盘。
- 执行器调用引擎的提交事务接口,引擎把刚刚写入的 redo log 改成提交(commit)状态,更新完成。
两阶段提交
为什么必须有“两阶段提交”呢?这是为了让两份日志之间的逻辑一致
答:用反证法。
1、先写 redo log 后写 binlog。假设在 redo log 写完,binlog 还没有写完的时候,MySQL 进程异常重启。 由于我们前面说过的,redo log 写完之后,系统即使崩溃,仍然能够把数据恢复回来,所以恢复后这一行 c 的值是 1。 但是由于 binlog 没写完就 crash 了,这时候 binlog 里面就没有记录这个语句。因此,之后备份日志的时候, 存起来的 binlog 里面就没有这条语句。然后你会发现,如果需要用这个 binlog 来恢复临时库的话, 由于这个语句的 binlog 丢失,这个临时库就会少了这一次更新,恢复出来的这一行 c 的值就是 0,与原库的值不同。
2、先写 binlog 后写 redo log。如果在 binlog 写完之后 crash,由于 redo log 还没写,崩溃恢复以后这个事务无效, 所以这一行 c 的值是 0。但是 binlog 里面已经记录了“把 c 从 0 改成 1”这个日志。所以, 在之后用 binlog 来恢复的时候就多了一个事务出来,恢复出来的这一行 c 的值就是 1,与原库的值不同。
redo log 和 binlog 都可以用于表示事务的提交状态,而两阶段提交就是让这两个状态保持逻辑上的一致。